
Curso
Redes neuronales recurrentes (RNN) para el modelado del lenguaje con Keras
4 h
16.3K
Las funciones de activación como la Unidad Lineal Rectificada (ReLU) son una piedra angular de las redes neuronales modernas. Sin ellas, muchas aplicaciones de IA del mundo real -desde el reconocimiento de imágenes hasta los sistemas de recomendación- no serían posibles. Esta guía explora los fundamentos de ReLU, sus ventajas, limitaciones y aplicación.
Algunas de las aplicaciones más potentes de la IA no serían posibles sin las redes neuronales artificiales. Las redes neuronales son modelos computacionales inspirados en el cerebro humano. Estas redes están formadas por nodos interconectados, o "neuronas", que trabajan juntas para procesar la información y tomar decisiones. Lo que hace que una red neuronal sea "profunda" es el número de capas entre la entrada y la salida. Una red neuronal profunda tiene múltiples capas, lo que le permite aprender características más complejas y hacer predicciones más precisas.
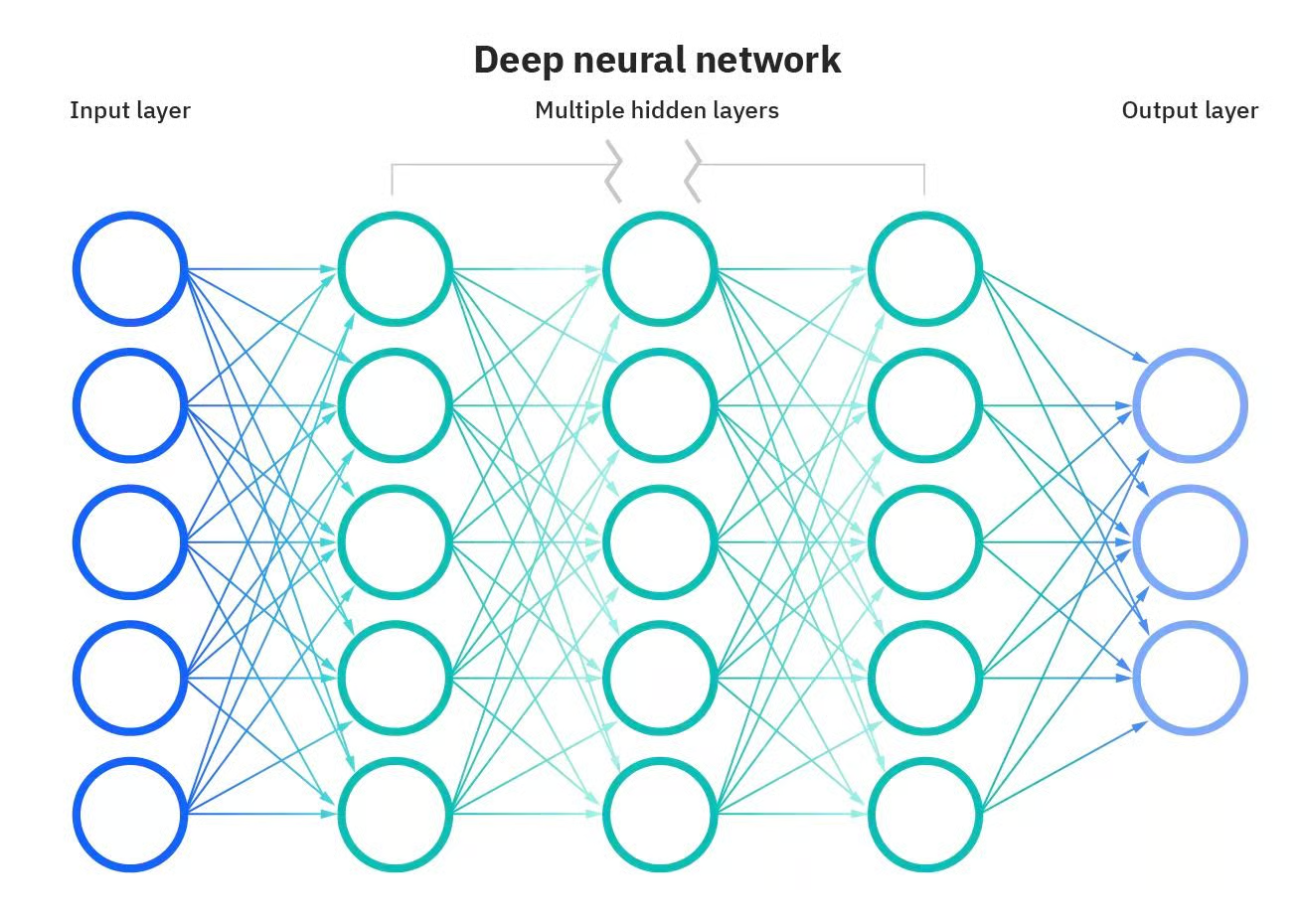
Red neuronal profunda. Fuente: DataCamp
Sin embargo, estos modelos son mucho más que simples capas. Otros componentes también son fundamentales para que las redes neuronales hagan su magia.
Uno de estos componentes son las funciones de activación. Puedes ver las funciones de activación como tomadoras de decisiones; determinan qué información debe pasarse a la capa siguiente, proporcionando un nuevo nivel de complejidad que permite a las redes neuronales tomar decisiones matizadas.
Aquí presentaremos una de las funciones de activación más populares y utilizadas: Unidad lineal rectificada (ReLU). Explicaremos los fundamentos de esta función de activación y algunas de sus variantes, sus ventajas y limitaciones, y cómo implementarlas con Pytorch. ¿Seguir leyendo?
Las funciones de activación son un componente esencial de las redes neuronales. Transforman la señal de entrada de un nodo de una red neuronal en una señal de salida que pasa a la capa siguiente. Sin funciones de activación, las redes neuronales se limitarían a modelar únicamente relaciones lineales entre entradas y salidas, por ejemplo, mediante la multiplicación de matrices.
Sin embargo, la mayoría de los datos del mundo real no pueden modelarse con linealidades. Las no linealidades captan patrones como el hecho de que pasar de no tener hijos a tener un hijo puede repercutir en tus transacciones bancarias de forma diferente que pasar de tres hijos a cuatro. Si las redes neuronales no tuvieran funciones de activación, no podrían aprender los complejos patrones no lineales que existen en los acontecimientos del mundo real.
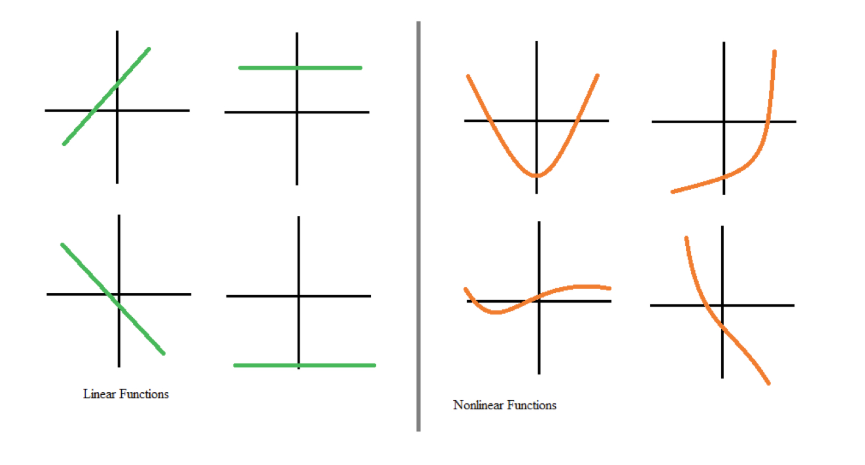
Funciones lineales frente a no lineales. Fuente: DataCamp
Las funciones de activación permiten a las redes neuronales aprender relaciones introduciendo comportamientos no lineales. En otras palabras, las funciones de activación crean un umbral numérico para decidir si se activa una neurona, introduciendo un grado de flexibilidad que es clave para que las redes neuronales modelen datos complejos y matizados.
Una de las funciones de activación más populares y utilizadas es la ReLU (unidad lineal rectificada). Al igual que otras funciones de activación, proporciona no linealidad al modelo para un mejor rendimiento de cálculo.
La función de activación ReLU tiene la forma
f(x) = max(0, x)
La función ReLU da como resultado el máximo entre su entrada y cero, como muestra el gráfico. Para entradas positivas, la salida de la función es igual a la entrada. Para salidas estrictamente negativas, la salida de la función es igual a cero.
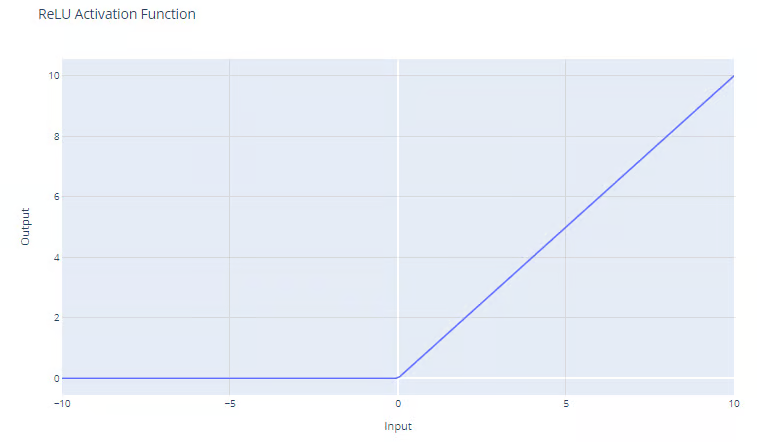
Función de activación Unidad Lineal Rectificada (ReLU). Fuente: DataCamp
Una de las ventajas más significativas de ReLu es que ayuda a mitigar el problema del gradiente evanescente. El problema del gradiente evanescente es un reto que se produce al entrenar redes neuronales profundas mediante retropropagación. Ocurre cuando el gradiente utilizado para actualizar los pesos de la red se hace muy pequeño o "desaparece" al retroceder por la red. Esto impide que los pesos se actualicen correctamente, lo que puede ralentizar o detener el proceso de aprendizaje. Puedes leer una explicación completa de los problemas de gradiente evanescente en nuestro Curso de Introducción al Aprendizaje Profundo en PyTorch.
Como la función ReLU no tiene un límite superior y los gradientes no convergen a cero para valores altos de x, ReLU supera el problema del gradiente evanescente, habitual cuando se utilizan las funciones de activación sigmoidea y softmax. Consulta nuestro artículo separado para descubrir otras funciones de activación populares .
Además, como ReLU produce cero para todas las entradas negativas, conduce naturalmente a activaciones dispersas. En otras palabras, como sólo se activa un subconjunto de neuronas durante el entrenamiento, se consigue un cálculo más eficaz.
Por último, este comportamiento permite a las redes escalar a muchas capas sin un aumento significativo de la carga computacional, en comparación con funciones más complejas como tanh o sigmoide. Esto hace que ReLU sea la función de activación por defecto más común y suele ser una buena elección si no estás seguro de la función de activación que debes utilizar en tu modelo.
Implementar ReLU en PyTorch es bastante fácil. Sólo tienes que utilizar la función nn.ReLU() para crear la función y añadirla a tu modelo.
En el ejemplo siguiente, aplicamos una función ReLU a una neurona simple y calculamos el gradiente en caso de valor negativo.
# Create a ReLU function with PyTorch
relu_pytorch = nn.ReLU()
# Apply your ReLU function on x, and calculate gradients
x = torch.tensor(-1.0, requires_grad=True)
y = relu_pytorch(x)
y.backward()
# Print the gradient of the ReLU function for x
gradient = x.grad
print(gradient)
>>> tensor(0.)Observa que el valor de entrada era -1, y la función ReLU devolvió cero. Recuerda que para valores negativos de x, la salida de ReLU es siempre cero, y de hecho, el gradiente es cero en todas partes porque no hay cambio en la función para ningún valor negativo de x.
Podría decirse que ReLU es la función de activación más utilizada, pero a veces puede no funcionar para el problema que intentas resolver. Afortunadamente, los investigadores del aprendizaje profundo han desarrollado algunas variantes de ReLU que puede merecer la pena probar en tus modelos. Estas son las alternativas más populares
Leaky ReLU tiene la forma:
f(x) = max(0,01x, x)
El objetivo de Leaky Relu es resolver el llamado problema del "ReLU moribundo". Ya hemos dicho que ReLU siempre da valores nulos para las entradas negativas. Cuando esto ocurra, los gradientes de los nodos con valores negativos se pondrán a cero durante el resto del entrenamiento, lo que impedirá que este parámetro aprenda. Para superar este reto, Leaky ReLU utiliza un factor multiplicador para las entradas negativas. Como resultado, la función no será cero, sino que tendrá una pequeña pendiente negativa, como se representa en la siguiente gráfica:
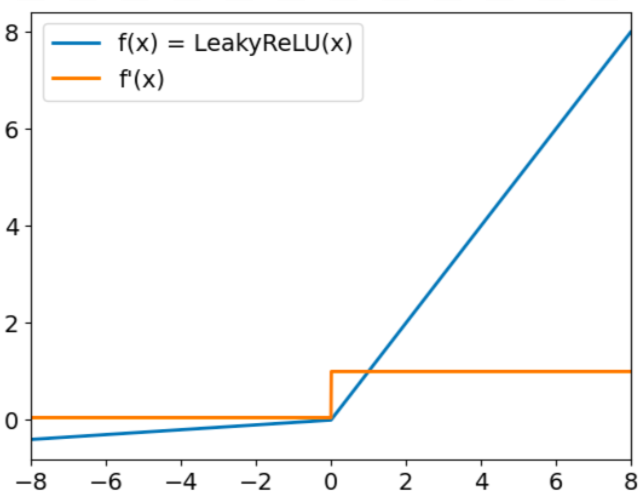
Función de activación ReLU con fugas. Fuente: DataCamp
El ReLU con fugas ofrece un factor multiplicador para superar el problema del ReLU moribundo. El ReLU paramétrico (PReLU) va un paso más allá, ofreciendo un parámetro aprendible (a) en lugar de una simple constante para calcular el valor de las entradas negativas:
f(x) = max(ax, x)
Aunque PReLU ofrece una mejora respecto a ReLU y Leaky ReLU en cuanto a precisión y adaptabilidad (es especialmente adecuado para capturar patrones en tareas complejas, como la visión por ordenador o el reconocimiento del habla), también añade complejidad al modelo. Entrenar este parámetro puede llevar mucho tiempo y requiere un ajuste y una regularización cuidadosos.
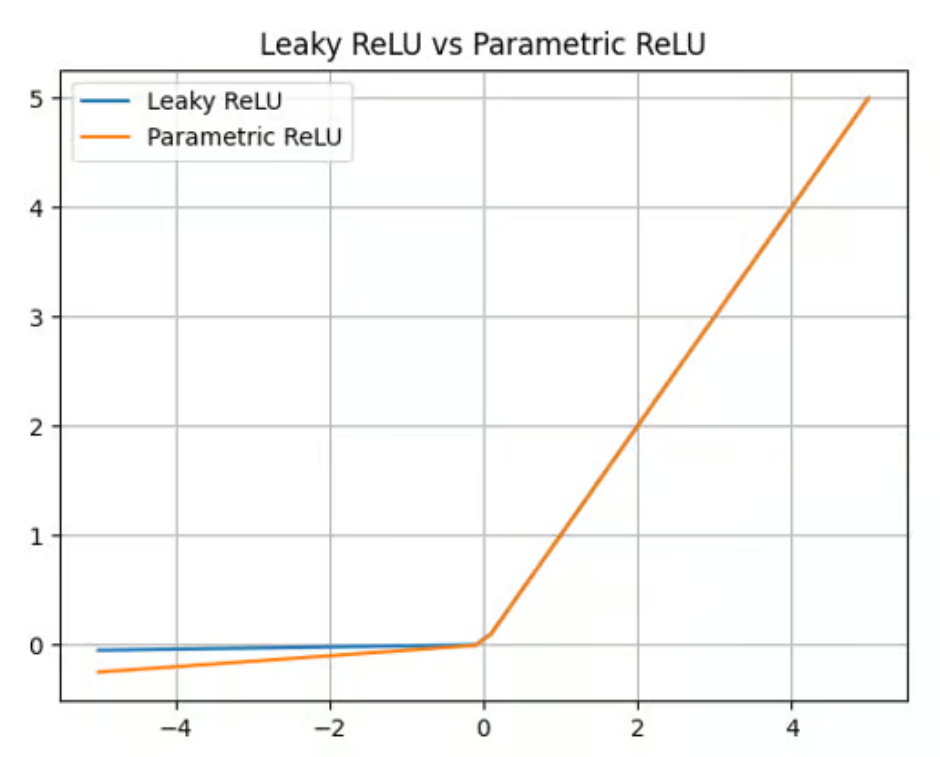
Función de activación paramétrica ReLU. Fuente: DataCamp
Otra gran alternativa a la ReLU es la unidad lineal exponencial (ELU), que tiene la siguiente fórmula:
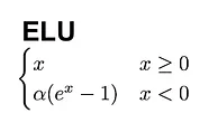
A diferencia de las ReLU, las ELU tienen valores negativos, lo que les permite acercar las activaciones de las unidades medias a cero, haciéndolas menos propensas a los gradientes evanescentes. Además, tener activaciones medias más cercanas a cero provoca un aprendizaje y una convergencia más rápidos.
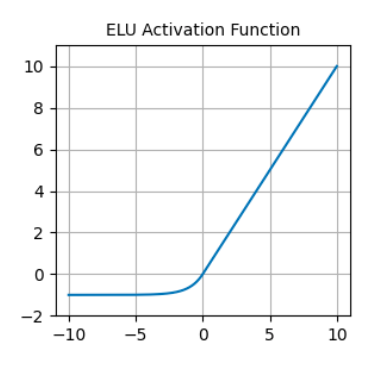
Función de activación ELU. Fuente: DataCamp
ReLU es una gran función de activación, pero no es una bala de plata. En concreto, ReLU puede adolecer de dos problemas bien conocidos.
El primero es el moribundo problema ReLU. Como ya se ha dicho, ReLU siempre da valores nulos para las entradas negativas. Esto puede hacer que los pesos se actualicen de tal forma que la neurona no vuelva a activarse en ningún punto de datos.
Si esto ocurre, entonces el gradiente que fluye a través de la unidad será siempre cero a partir de ese punto, impidiendo que este parámetro aprenda. Las variantes de ReLU, como Leaky ReLU y PReLU, se crearon para solucionar este problema.
Los gradientes inestables también pueden darse en el otro extremo. El problema de los gradientes explosivos se produce cuando los gradientes se hacen cada vez más grandes, lo que provoca enormes actualizaciones de los parámetros y un entrenamiento divergente.
En este caso, se acumulan gradientes de error mayores, y las ponderaciones del modelo se hacen demasiado grandes. Este problema puede provocar tiempos de entrenamiento más largos y un rendimiento deficiente del modelo. Existen varias técnicas para abordar los problemas del gradiente explosivo, como el recorte del gradiente y la normalización por lotes.
Gracias a sus propiedades únicas, ReLU se ha convertido en la función de activación más popular, siendo la opción por defecto en frameworks como PyTorch y TensorFlow, y ampliamente utilizada en muchas aplicaciones de aprendizaje profundo, entre ellas:
Hemos explorado el papel fundamental de las funciones de activación ReLU durante el entrenamiento de las redes neuronales. A pesar de su sencillez, ReLU es una de las funciones de activación más eficaces que existen, y posiblemente la más popular.
A medida que las redes neuronales sigan evolucionando, la exploración de las funciones de activación se ampliará sin duda, incluyendo posiblemente nuevas formas que aborden retos específicos de las arquitecturas emergentes.
La selección cuidadosa de las funciones de activación es un acto de equilibrio -una mezcla de comprensión científica e intuición ingeniosa- que puede afectar significativamente al rendimiento de las redes neuronales.
¿Te interesa saber más sobre el aprendizaje profundo? Consulta nuestros materiales dedicados y prepárate para una de las tecnologías más transformadoras de la IA:
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Bharath K
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Eladio Montero Porras


