
Curso
Redes Neurais Recorrentes (RNNs) para Modelagem de Linguagem com Keras
4 h
16.3K
As funções de ativação, como a Unidade Linear Retificada (ReLU), são a base das redes neurais modernas. Sem eles, muitos aplicativos de IA do mundo real - do reconhecimento de imagens aos sistemas de recomendação - não seriam possíveis. Este guia explora os conceitos básicos do ReLU, suas vantagens, limitações e implementação.
Algumas das aplicações mais poderosas da IA não seriam possíveis sem as redes neurais artificiais. As redes neurais são modelos computacionais inspirados no cérebro humano. Essas redes consistem em nós interconectados, ou "neurônios", que trabalham juntos para processar informações e tomar decisões. O que torna uma rede neural "profunda" é o número de camadas entre a entrada e a saída. Uma rede neural profunda tem várias camadas, o que permite que ela aprenda recursos mais complexos e faça previsões mais precisas.
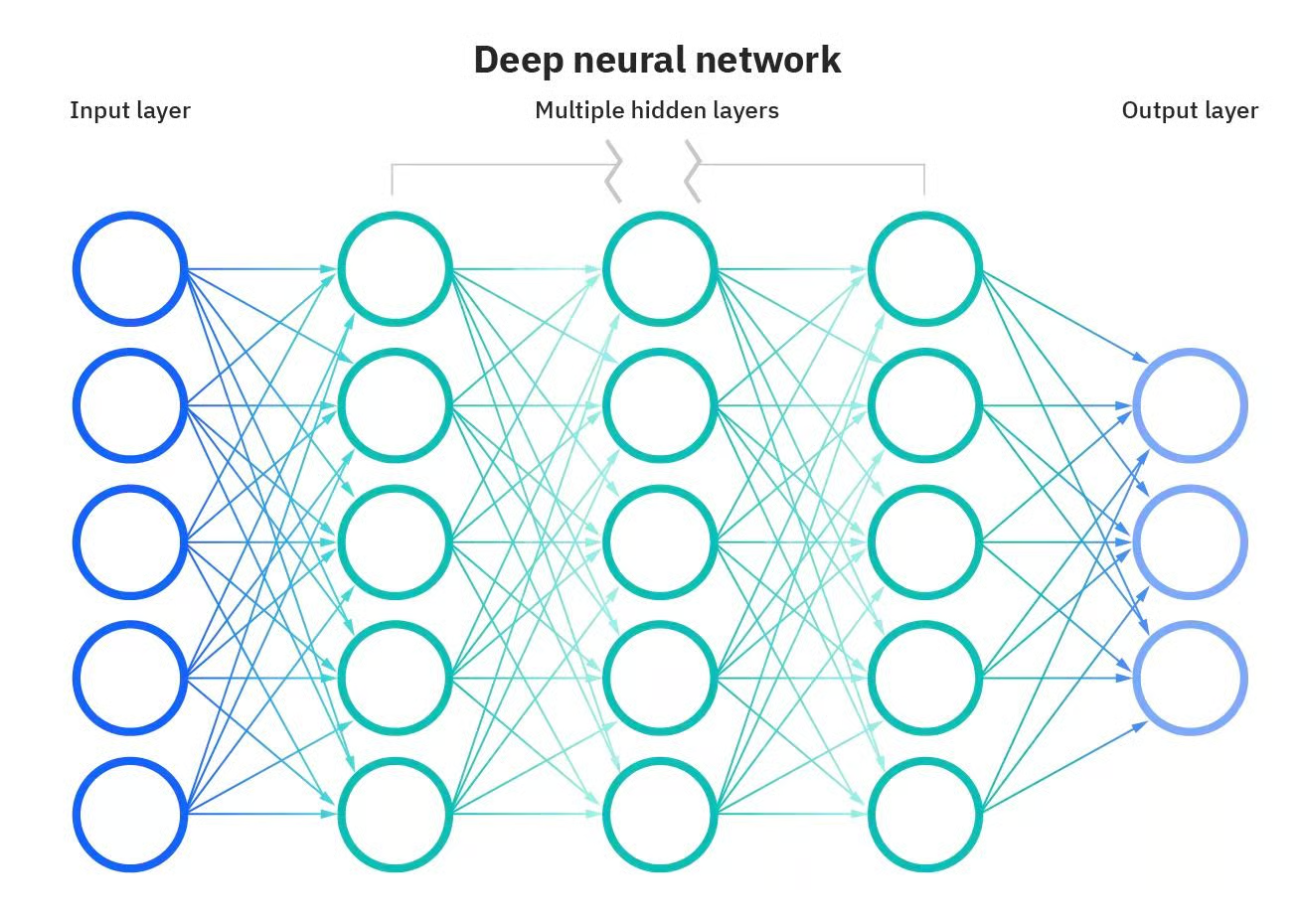
Rede neural profunda. Fonte: DataCamp
No entanto, esses modelos são muito mais do que simples camadas. Outros componentes também são essenciais para que as redes neurais façam sua mágica.
Um desses componentes são as funções de ativação. Você pode ver as funções de ativação como tomadores de decisão; elas determinam quais informações devem ser passadas para a próxima camada, fornecendo um novo nível de complexidade que permite que as redes neurais tomem decisões com nuances.
Aqui, apresentaremos uma das funções de ativação mais populares e amplamente usadas: Unidade Linear Retificada (ReLU). Explicaremos os conceitos básicos dessa função de ativação e algumas de suas variantes, suas vantagens e limitações e como implementá-las com o Pytorch. Você continua lendo?
As funções de ativação são um bloco de construção integral das redes neurais. Eles transformam o sinal de entrada de um nó em uma rede neural em um sinal de saída que é então passado para a próxima camada. Sem as funções de ativação, as redes neurais ficariam restritas à modelagem apenas de relações lineares entre entradas e saídas, por exemplo, por meio da multiplicação de matrizes.
No entanto, a maioria dos dados do mundo real não pode ser modelada com linearidades. As não linearidades capturam padrões como, por exemplo, o fato de que passar de nenhum filho para um filho pode afetar suas transações bancárias de forma diferente de passar de três para quatro filhos. Se as redes neurais não tivessem funções de ativação, elas não conseguiriam aprender os complexos padrões não lineares que existem nos eventos do mundo real.
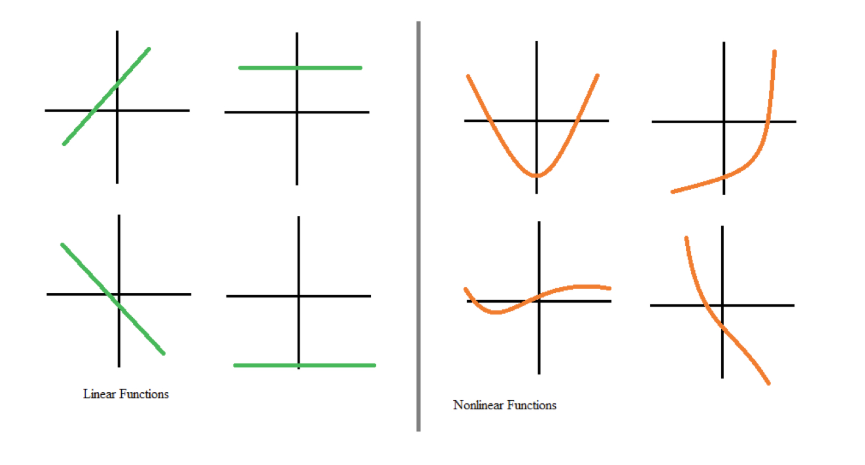
Funções lineares versus não lineares. Fonte: DataCamp
As funções de ativação permitem que as redes neurais aprendam relacionamentos introduzindo comportamentos não lineares. Em outras palavras, as funções de ativação criam um limite numérico para decidir se um neurônio deve ser ativado, introduzindo um grau de flexibilidade que é fundamental para que as redes neurais modelem dados complexos e diferenciados.
Uma das funções de ativação mais populares e amplamente utilizadas é a ReLU (unidade linear retificada). Assim como outras funções de ativação, ele fornece não linearidade ao modelo para melhorar o desempenho da computação.
A função de ativação ReLU tem a forma:
f(x) = max(0, x)
A função ReLU produz o máximo entre sua entrada e zero, conforme mostrado no gráfico. Para entradas positivas, a saída da função é igual à entrada. Para saídas estritamente negativas, a saída da função é igual a zero.
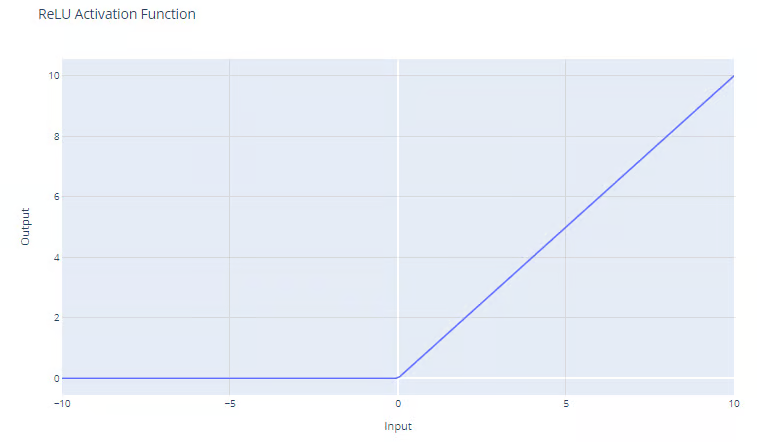
Função de ativação da Unidade Linear Retificada (ReLU). Fonte: DataCamp
Uma das vantagens mais significativas do ReLu é que ele ajuda a atenuar o problema do gradiente de desaparecimento. O problema do gradiente de desaparecimento é um desafio que ocorre durante o treinamento de redes neurais profundas usando a retropropagação. Isso acontece quando o gradiente usado para atualizar os pesos da rede se torna muito pequeno ou "desaparece" à medida que retorna à rede. Isso impede que os pesos sejam atualizados corretamente, o que pode retardar ou interromper o processo de aprendizado. Você pode ler uma explicação completa sobre os problemas de gradiente de fuga em nosso curso Introdução à aprendizagem profunda no PyTorch.
Como a função ReLU não tem um limite superior e os gradientes não convergem para zero para valores altos de x, a ReLU supera o problema do gradiente de desaparecimento, que é comum quando se usam as funções de ativação sigmoide e softmax. Consulte nosso artigo separado para descobrir outras funções de ativação populares .
Além disso, como o ReLU gera zero para todas as entradas negativas, ele naturalmente leva a ativações esparsas. Em outras palavras, como apenas um subconjunto de neurônios é ativado durante o treinamento, isso leva a uma computação mais eficiente.
Por fim, esse comportamento permite que as redes sejam dimensionadas para muitas camadas sem um aumento significativo na carga computacional, em comparação com funções mais complexas, como tanh ou sigmoide. Isso torna a ReLU a função de ativação padrão mais comum e geralmente é uma boa escolha se você não tiver certeza sobre a função de ativação a ser usada no seu modelo.
Implementar o ReLU no PyTorch é bastante fácil. Você só precisa usar a função nn.ReLU() para criar a função e adicioná-la ao seu modelo.
No exemplo a seguir, aplicamos uma função ReLU a um neurônio simples e calculamos o gradiente no caso de um valor negativo.
# Create a ReLU function with PyTorch
relu_pytorch = nn.ReLU()
# Apply your ReLU function on x, and calculate gradients
x = torch.tensor(-1.0, requires_grad=True)
y = relu_pytorch(x)
y.backward()
# Print the gradient of the ReLU function for x
gradient = x.grad
print(gradient)
>>> tensor(0.)Observe que o valor de entrada era -1 e a função ReLU retornou zero. Lembre-se de que, para valores negativos de x, a saída do ReLU é sempre zero e, de fato, o gradiente é zero em todos os lugares porque não há alteração na função para nenhum valor negativo de x.
A ReLU é, sem dúvida, a função de ativação mais usada, mas, às vezes, ela pode não funcionar para o problema que você está tentando resolver. Felizmente, os pesquisadores de aprendizagem profunda desenvolveram algumas variantes de ReLU que podem valer a pena testar em seus modelos. Aqui estão as alternativas mais populares
O Leaky ReLU tem o formulário:
f(x) = max(0,01x, x)
O objetivo do Leaky Relu é resolver o chamado problema do "ReLU moribundo". Já mencionamos que o ReLU sempre gera valores nulos para entradas negativas. Quando isso acontecer, os gradientes dos nós com valores negativos serão definidos como zero durante o restante do treinamento, o que impedirá o aprendizado desse parâmetro. Para superar esse desafio, o Leaky ReLU usa um fator de multiplicação para entradas negativas. Como resultado, a função não será zero, mas terá uma pequena inclinação negativa, conforme representado no gráfico a seguir:
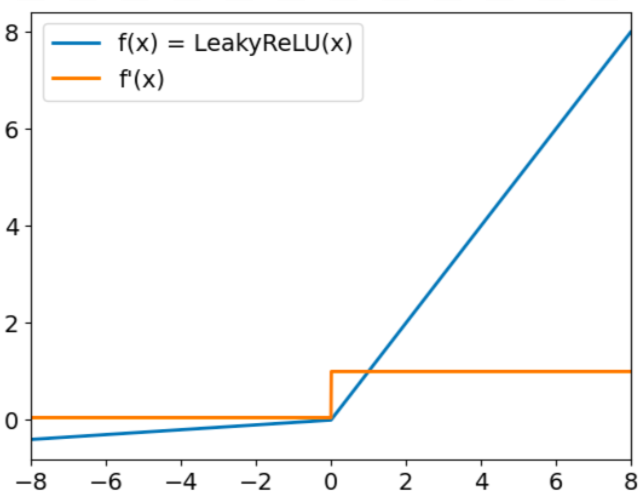
Função de ativação ReLU com vazamento. Fonte: DataCamp
O Leaky ReLU oferece um fator multiplicador para superar o problema do ReLU que está morrendo. O Parametric ReLU (PReLU) vai um passo adiante, oferecendo um parâmetro aprendível (a) em vez de uma simples constante para calcular o valor das entradas negativas:
f(x) = max(ax, x)
Embora o PReLU ofereça uma melhoria em comparação com o ReLU e o Leaky ReLU em termos de precisão e adaptabilidade (ele é particularmente adequado para capturar padrões em tarefas complexas, como visão computacional ou reconhecimento de fala), ele também acrescenta complexidade ao modelo. O treinamento desse parâmetro pode ser demorado e requer ajuste e regularização cuidadosos.
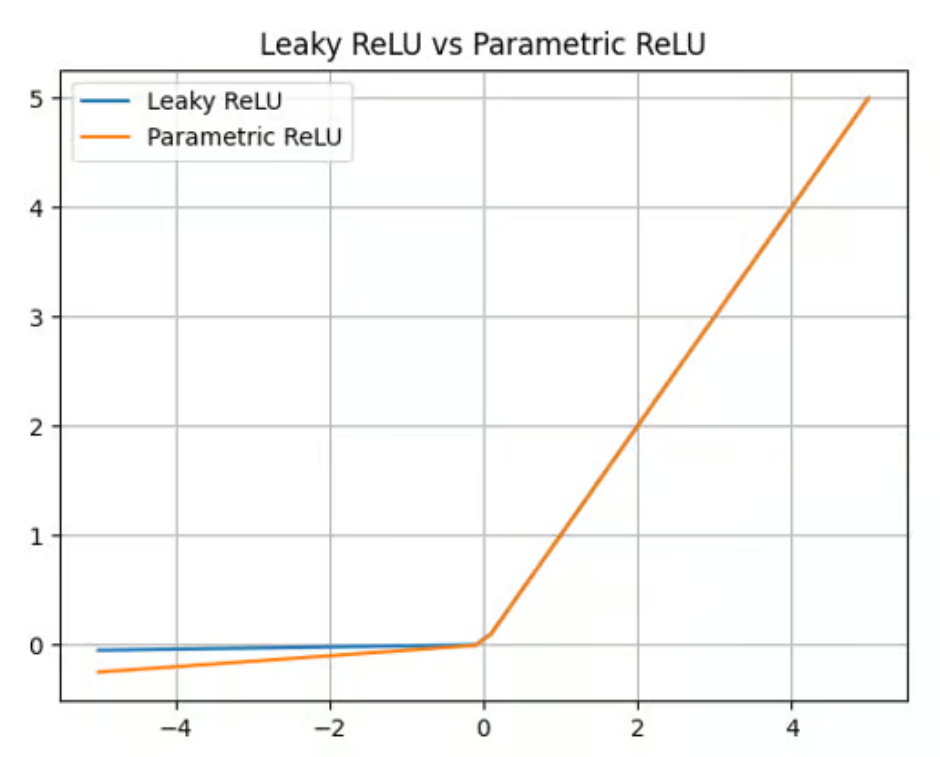
Função de ativação Parametric ReLU. Fonte: DataCamp
Outra ótima alternativa ao ReLU é a unidade linear exponencial (ELU), que vem com a seguinte fórmula:
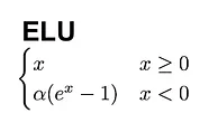
Em contraste com a ReLU, as ELUs têm valores negativos, o que permite que elas empurrem as ativações da unidade média para mais perto de zero, tornando-as, assim, menos propensas a gradientes que desaparecem. Além disso, ter ativações médias mais próximas de zero causa aprendizado e convergência mais rápidos.
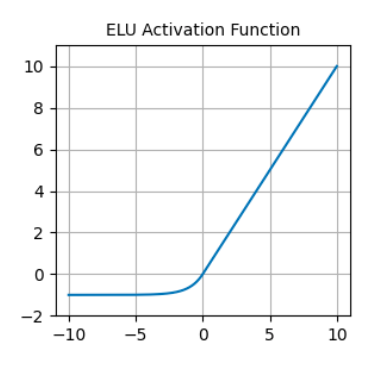
Função de ativação ELU. Fonte: DataCamp
A ReLU é uma excelente função de ativação, mas não é uma solução milagrosa. Em particular, o ReLU pode sofrer de dois problemas bem conhecidos.
O primeiro é o problema do ReLU em extinção. Como já mencionado, o ReLU sempre gera valores nulos para entradas negativas. Isso pode fazer com que os pesos sejam atualizados de tal forma que o neurônio nunca mais será ativado em nenhum ponto de dados.
Se isso acontecer, o gradiente que flui pela unidade será sempre zero a partir desse ponto, impedindo que esse parâmetro seja aprendido. As variantes do ReLU, como o Leaky ReLU e o PReLU, foram criadas para resolver esse problema.
Gradientes instáveis também podem ocorrer na outra extremidade. O problema da explosão de gradientes ocorre quando os gradientes se tornam cada vez maiores, levando a grandes atualizações de parâmetros e a um treinamento divergente.
Nesse caso, os gradientes de erro maiores se acumulam, e os pesos do modelo se tornam muito grandes. Esse problema pode causar tempos de treinamento mais longos e desempenho ruim do modelo. Há várias técnicas para resolver os problemas de gradiente explosivo, incluindo o recorte de gradiente e a normalização em lote.
Graças às suas propriedades exclusivas, a ReLU se tornou a função de ativação mais popular, sendo a opção padrão em estruturas como PyTorch e TensorFlow, e amplamente usada em muitos aplicativos de aprendizagem profunda, inclusive:
Exploramos o papel fundamental das funções de ativação ReLU durante o treinamento de redes neurais. Apesar de sua simplicidade, a ReLU é uma das funções de ativação mais eficazes que existem e, sem dúvida, a mais popular.
À medida que as redes neurais continuarem a evoluir, a exploração das funções de ativação sem dúvida se expandirá, possivelmente incluindo novas formas que abordem desafios específicos de arquiteturas emergentes.
A seleção cuidadosa das funções de ativação é um ato de equilíbrio - uma mistura de compreensão científica e intuição artística - que pode afetar significativamente o desempenho das redes neurais.
Você tem interesse em saber mais sobre aprendizagem profunda? Confira nossos materiais dedicados e prepare-se para uma das tecnologias mais transformadoras em IA:
Principais cursos da DataCamp
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Bharath K
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan



