
Kurs
Rekursive neuronale Netze (RNNs) für die Sprachmodellierung mit Keras
4 Std.
16.3K
Aktivierungsfunktionen wie die Rectified Linear Unit (ReLU) sind ein Eckpfeiler moderner neuronaler Netze. Ohne sie wären viele reale KI-Anwendungen - von der Bilderkennung bis zu Empfehlungssystemen - nicht möglich. In diesem Leitfaden werden die Grundlagen von ReLU, seine Vorteile, Grenzen und die Umsetzung erläutert.
Einige der leistungsfähigsten Anwendungen von KI wären ohne künstliche neuronale Netze nicht möglich. Neuronale Netze sind Computermodelle, die vom menschlichen Gehirn inspiriert sind. Diese Netzwerke bestehen aus miteinander verbundenen Knotenpunkten oder "Neuronen", die zusammenarbeiten, um Informationen zu verarbeiten und Entscheidungen zu treffen. Was ein neuronales Netzwerk "tief" macht, ist die Anzahl der Schichten zwischen dem Eingang und dem Ausgang. Ein tiefes neuronales Netzwerk hat mehrere Schichten, wodurch es komplexere Merkmale lernen und genauere Vorhersagen treffen kann.
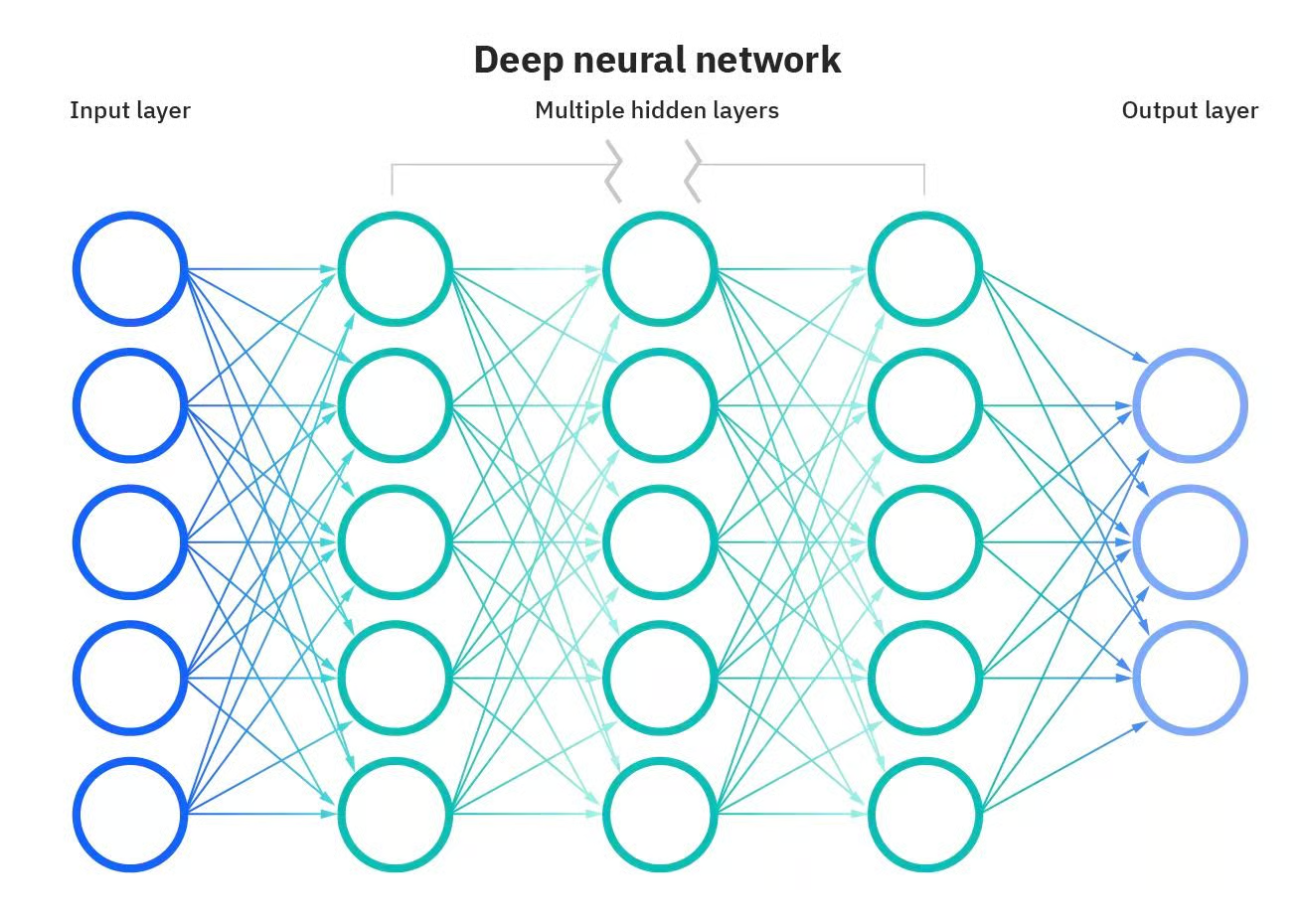
Tiefes neuronales Netzwerk. Quelle: DataCamp
Diese Modelle sind jedoch viel mehr als einfache Schichten. Auch andere Komponenten sind wichtig, damit neuronale Netze ihre Wirkung entfalten können.
Eine dieser Komponenten sind Aktivierungsfunktionen. Du kannst Aktivierungsfunktionen als Entscheidungsträger sehen; sie bestimmen, welche Informationen an die nächste Schicht weitergegeben werden sollen, und sorgen so für eine neue Ebene der Komplexität, die es neuronalen Netzen ermöglicht, differenzierte Entscheidungen zu treffen.
Hier stellen wir eine der beliebtesten und am häufigsten verwendeten Aktivierungsfunktionen vor: Rectified Linear Unit (ReLU). Wir erklären die Grundlagen dieser Aktivierungsfunktion und einige ihrer Varianten, ihre Vorteile und Grenzen und wie man sie mit Pytorch implementiert. Weiter lesen?
Aktivierungsfunktionen sind ein wesentlicher Baustein neuronaler Netze. Sie wandeln das Eingangssignal eines Knotens in einem neuronalen Netz in ein Ausgangssignal um, das dann an die nächste Schicht weitergegeben wird. Ohne Aktivierungsfunktionen wären neuronale Netze darauf beschränkt, nur lineare Beziehungen zwischen Eingaben und Ausgaben zu modellieren, zum Beispiel durch Matrixmultiplikation.
Die meisten realen Daten können jedoch nicht mit linearen Werten modelliert werden. Nichtlinearitäten erfassen Muster, wie z. B., dass sich der Übergang von null auf ein Kind anders auf deine Bankgeschäfte auswirken kann als der Übergang von drei auf vier Kinder. Hätten neuronale Netze keine Aktivierungsfunktionen, könnten sie die komplexen nichtlinearen Muster, die in der realen Welt vorkommen, nicht lernen.
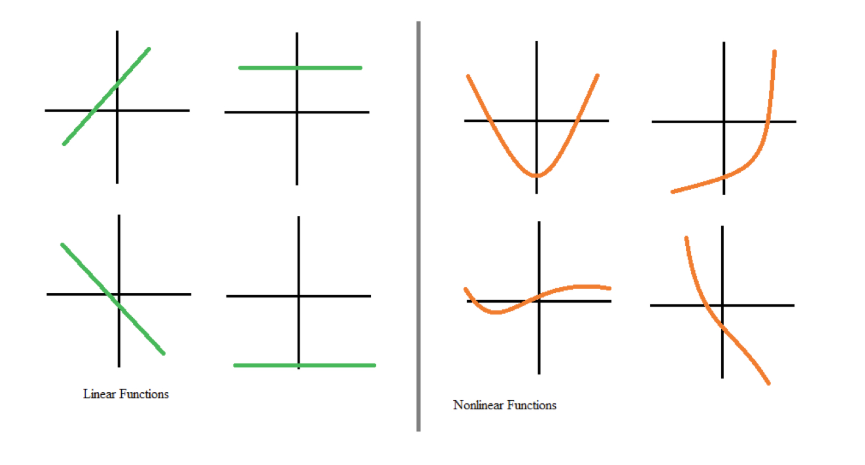
Lineare und nichtlineare Funktionen. Quelle: DataCamp
Aktivierungsfunktionen ermöglichen es neuronalen Netzen, Beziehungen zu lernen, indem sie nichtlineare Verhaltensweisen einführen. Mit anderen Worten: Aktivierungsfunktionen schaffen einen numerischen Schwellenwert, um zu entscheiden, ob ein Neuron aktiviert werden soll, und bieten damit ein Maß an Flexibilität, das für neuronale Netze zur Modellierung komplexer und differenzierter Daten entscheidend ist.
Eine der beliebtesten und am weitesten verbreiteten Aktivierungsfunktionen ist ReLU (rectified linear unit). Wie bei anderen Aktivierungsfunktionen sorgt sie für eine Nichtlinearität des Modells und damit für eine bessere Rechenleistung.
Die ReLU-Aktivierungsfunktion hat die Form:
f(x) = max(0, x)
Die ReLU-Funktion gibt das Maximum zwischen ihrer Eingabe und Null aus, wie die Grafik zeigt. Bei positiven Eingaben ist die Ausgabe der Funktion gleich der Eingabe. Bei streng negativen Ausgaben ist die Ausgabe der Funktion gleich Null.
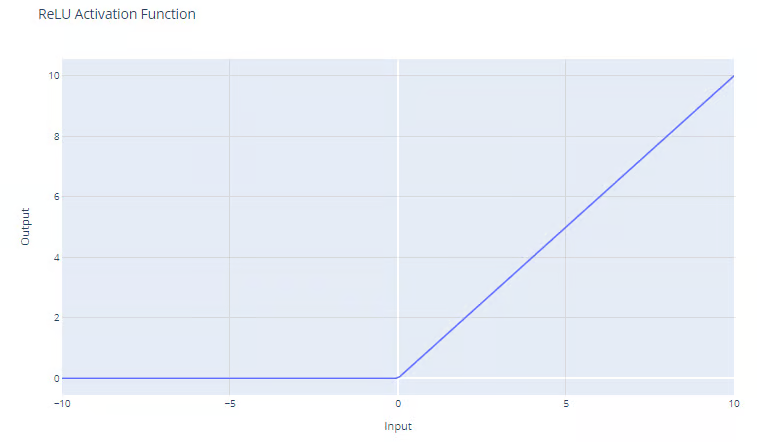
Rectified Linear Unit (ReLU) Aktivierungsfunktion. Quelle: DataCamp
Einer der wichtigsten Vorteile von ReLu ist, dass es hilft, das Problem des verschwindenden Gradienten zu entschärfen. Das Problem des verschwindenden Gradienten ist eine Herausforderung, die beim Training tiefer neuronaler Netze mit Backpropagation auftritt. Das passiert, wenn der Gradient, der zur Aktualisierung der Gewichte des Netzes verwendet wird, sehr klein wird oder "verschwindet", wenn er sich durch das Netz zurückbewegt. Dadurch werden die Gewichte nicht richtig aktualisiert, was den Lernprozess verlangsamen oder stoppen kann. Eine vollständige Erklärung der Probleme mit dem verschwindenden Gradienten findest du in unserem Kurs Einführung in Deep Learning in PyTorch.
Da die ReLU-Funktion keine Obergrenze hat und die Gradienten bei hohen Werten von x nicht gegen Null konvergieren, überwindet ReLU das Problem des verschwindenden Gradienten, das bei der Verwendung von Sigmoid- und Softmax-Aktivierungsfunktionen auftritt. In unserem separaten Artikel findest du weitere beliebte Aktivierungsfunktionen.
Da ReLU für alle negativen Eingaben den Wert Null ausgibt, führt es natürlich zu spärlichen Aktivierungen. Mit anderen Worten: Da beim Training nur eine Teilmenge der Neuronen aktiviert wird, führt dies zu einer effizienteren Berechnung.
Dieses Verhalten ermöglicht es den Netzwerken, auf viele Ebenen zu skalieren, ohne dass der Rechenaufwand im Vergleich zu komplexeren Funktionen wie tanh oder sigmoid erheblich steigt. Damit ist ReLU die häufigste Standardaktivierungsfunktion und in der Regel eine gute Wahl, wenn du dir nicht sicher bist, welche Aktivierungsfunktion du für dein Modell verwenden sollst.
Die Implementierung von ReLU in PyTorch ist ziemlich einfach. Du musst nur die Funktion nn.ReLU() verwenden, um die Funktion zu erstellen und sie zu deinem Modell hinzuzufügen.
Im folgenden Beispiel wenden wir eine ReLU-Funktion auf ein einfaches Neuron an und berechnen den Gradienten im Falle eines negativen Wertes.
# Create a ReLU function with PyTorch
relu_pytorch = nn.ReLU()
# Apply your ReLU function on x, and calculate gradients
x = torch.tensor(-1.0, requires_grad=True)
y = relu_pytorch(x)
y.backward()
# Print the gradient of the ReLU function for x
gradient = x.grad
print(gradient)
>>> tensor(0.)Beachte, dass der Eingabewert -1 war und die ReLU-Funktion Null zurückgegeben hat. Erinnere dich daran, dass für negative Werte von x die Ausgabe von ReLU immer Null ist und auch der Gradient überall Null ist, weil sich die Funktion für jeden negativen Wert von x nicht ändert.
ReLU ist wohl die am häufigsten verwendete Aktivierungsfunktion, aber manchmal funktioniert sie vielleicht nicht für das Problem, das du zu lösen versuchst. Zum Glück haben Deep-Learning-Forscher einige ReLU-Varianten entwickelt, die es wert sein könnten, in deinen Modellen getestet zu werden. Hier sind die beliebtesten Alternativen
Leaky ReLU hat die Form:
f(x) = max(0,01x, x)
Das Ziel von Leaky Relu ist es, das sogenannte "sterbende ReLU" Problem anzugehen. Wir haben bereits erwähnt, dass ReLU bei negativen Eingaben immer Nullwerte ausgibt. In diesem Fall werden die Gradienten von Knoten mit negativen Werten für den Rest des Trainings auf Null gesetzt, wodurch dieser Parameter nicht mehr lernen kann. Um diese Herausforderung zu meistern, verwendet Leaky ReLU einen Multiplikationsfaktor für negative Eingaben. Infolgedessen ist die Funktion nicht null, sondern hat eine kleine negative Steigung, wie in der folgenden Grafik dargestellt:
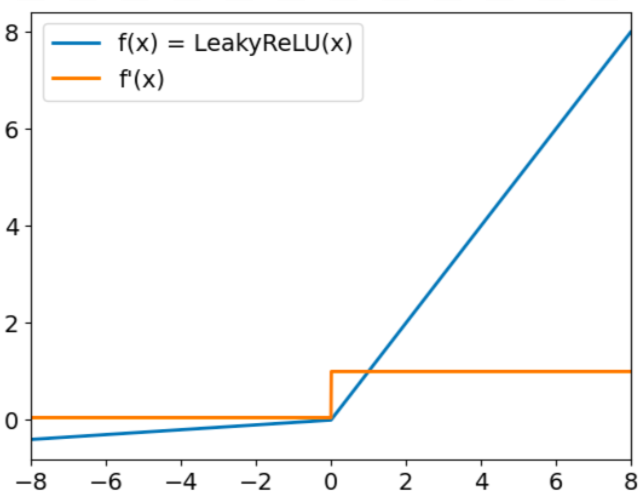
Leaky ReLU Aktivierungsfunktion. Quelle: DataCamp
Leaky ReLU bietet einen Multiplikationsfaktor, um das Problem des sterbenden ReLUs zu überwinden. Parametric ReLU (PReLU) geht einen Schritt weiter und bietet einen lernbaren Parameter (a) anstelle einer einfachen Konstante, um den Wert negativer Eingaben zu berechnen:
f(x) = max(ax, x)
PReLU bietet zwar eine Verbesserung gegenüber ReLU und Leaky ReLU in Bezug auf Genauigkeit und Anpassungsfähigkeit (es eignet sich besonders gut für die Erfassung von Mustern in komplexen Aufgaben wie Computer Vision oder Spracherkennung), aber es erhöht auch die Komplexität des Modells. Das Training dieses Parameters kann zeitaufwändig sein und erfordert eine sorgfältige Abstimmung und Regularisierung.
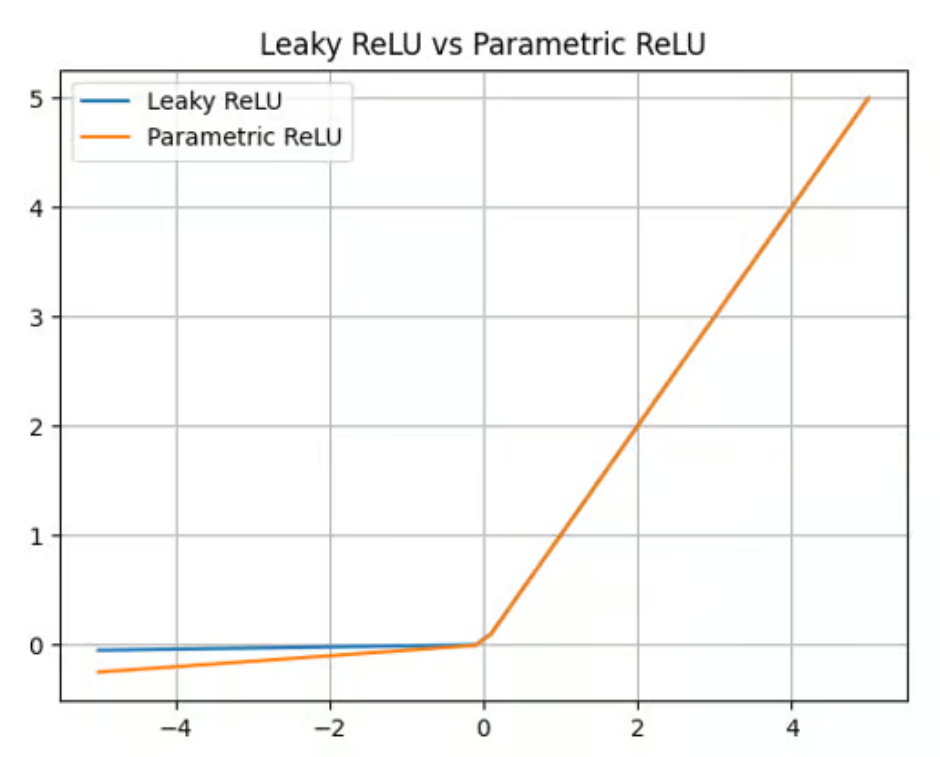
Parametrische ReLU-Aktivierungsfunktion. Quelle: DataCamp
Eine weitere gute Alternative zu ReLU ist die Exponential Linear Unit (ELU), die mit der folgenden Formel arbeitet:
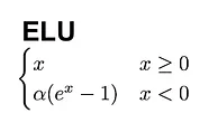
Im Gegensatz zu ReLU haben ELUs negative Werte, was es ihnen ermöglicht, die Aktivierungen der mittleren Einheiten näher an den Nullpunkt zu bringen, wodurch sie weniger anfällig für verschwindende Gradienten sind. Außerdem führen mittlere Aktivierungen, die näher bei Null liegen, zu schnellerem Lernen und Konvergenz.
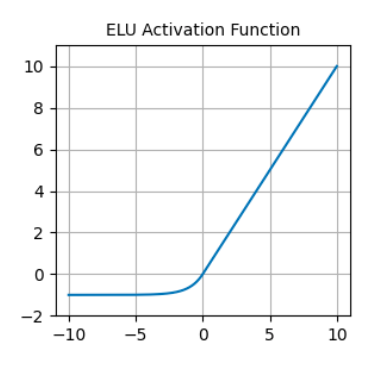
ELU-Aktivierungsfunktion. Quelle: DataCamp
ReLU ist eine großartige Aktivierungsfunktion, aber sie ist kein Allheilmittel. ReLU kann insbesondere unter zwei bekannten Problemen leiden.
Das erste ist das sterbende ReLU-Problem. Wie bereits erwähnt, gibt ReLU bei negativen Eingaben immer Nullwerte aus. Das kann dazu führen, dass die Gewichte so aktualisiert werden, dass das Neuron nie wieder bei einem Datenpunkt aktiviert wird.
Wenn das passiert, wird der Gradient, der durch die Einheit fließt, von diesem Punkt an für immer gleich Null sein, sodass dieser Parameter nicht mehr lernen kann. ReLU-Varianten, wie Leaky ReLU und PReLU, wurden entwickelt, um dieses Problem zu lösen.
Instabile Gefälle können auch auf der anderen Seite auftreten. Das Problem der explodierenden Gradienten tritt auf, wenn die Gradienten immer größer werden, was zu großen Parameteraktualisierungen und divergierendem Training führt.
In diesem Fall häufen sich größere Fehlergradienten an, und die Modellgewichte werden zu groß. Dieses Problem kann zu längeren Trainingszeiten und schlechter Modellleistung führen. Es gibt verschiedene Techniken, um das Problem der explodierenden Gradienten zu lösen, darunter Gradientenbeschneidung und Stapelnormalisierung.
Dank ihrer einzigartigen Eigenschaften ist ReLU zur beliebtesten Aktivierungsfunktion geworden. Sie ist die Standardoption in Frameworks wie PyTorch und TensorFlow und wird in vielen Deep-Learning-Anwendungen eingesetzt:
Wir haben die zentrale Rolle der ReLU-Aktivierungsfunktionen beim Training von neuronalen Netzen untersucht. Trotz ihrer Einfachheit ist ReLU eine der effektivsten Aktivierungsfunktionen, die es gibt, und wohl auch die beliebteste.
Mit der weiteren Entwicklung neuronaler Netze wird sich die Erforschung von Aktivierungsfunktionen zweifellos ausweiten und möglicherweise auch neue Formen umfassen, die spezifische Herausforderungen neuer Architekturen angehen.
Die sorgfältige Auswahl von Aktivierungsfunktionen ist ein Balanceakt - eine Mischung aus wissenschaftlichem Verständnis und künstlerischer Intuition - der die Leistung neuronaler Netze erheblich beeinflussen kann.
Möchtest du mehr über Deep Learning erfahren? Schau dir unsere speziellen Materialien an und mach dich bereit für eine der transformativsten Technologien in der KI:
Top DataCamp Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
