
Cours
Réseaux de neurones récurrents (RNN) pour la modélisation du langage avec Keras
4 h
16.3K
Les fonctions d'activation telles que l'unité linéaire rectifiée (ReLU) sont la pierre angulaire des réseaux neuronaux modernes. Sans eux, de nombreuses applications d'IA dans le monde réel - de la reconnaissance d'images aux systèmes de recommandation - ne seraient pas possibles. Ce guide présente les bases de ReLU, ses avantages, ses limites et sa mise en œuvre.
Certaines des applications les plus puissantes de l'IA ne seraient pas possibles sans les réseaux neuronaux artificiels. Les réseaux neuronaux sont des modèles informatiques inspirés du cerveau humain. Ces réseaux sont constitués de nœuds interconnectés, ou "neurones", qui travaillent ensemble pour traiter les informations et prendre des décisions. Ce qui rend un réseau neuronal "profond", c'est le nombre de couches entre l'entrée et la sortie. Un réseau neuronal profond comporte plusieurs couches, ce qui lui permet d'apprendre des caractéristiques plus complexes et de faire des prédictions plus précises.
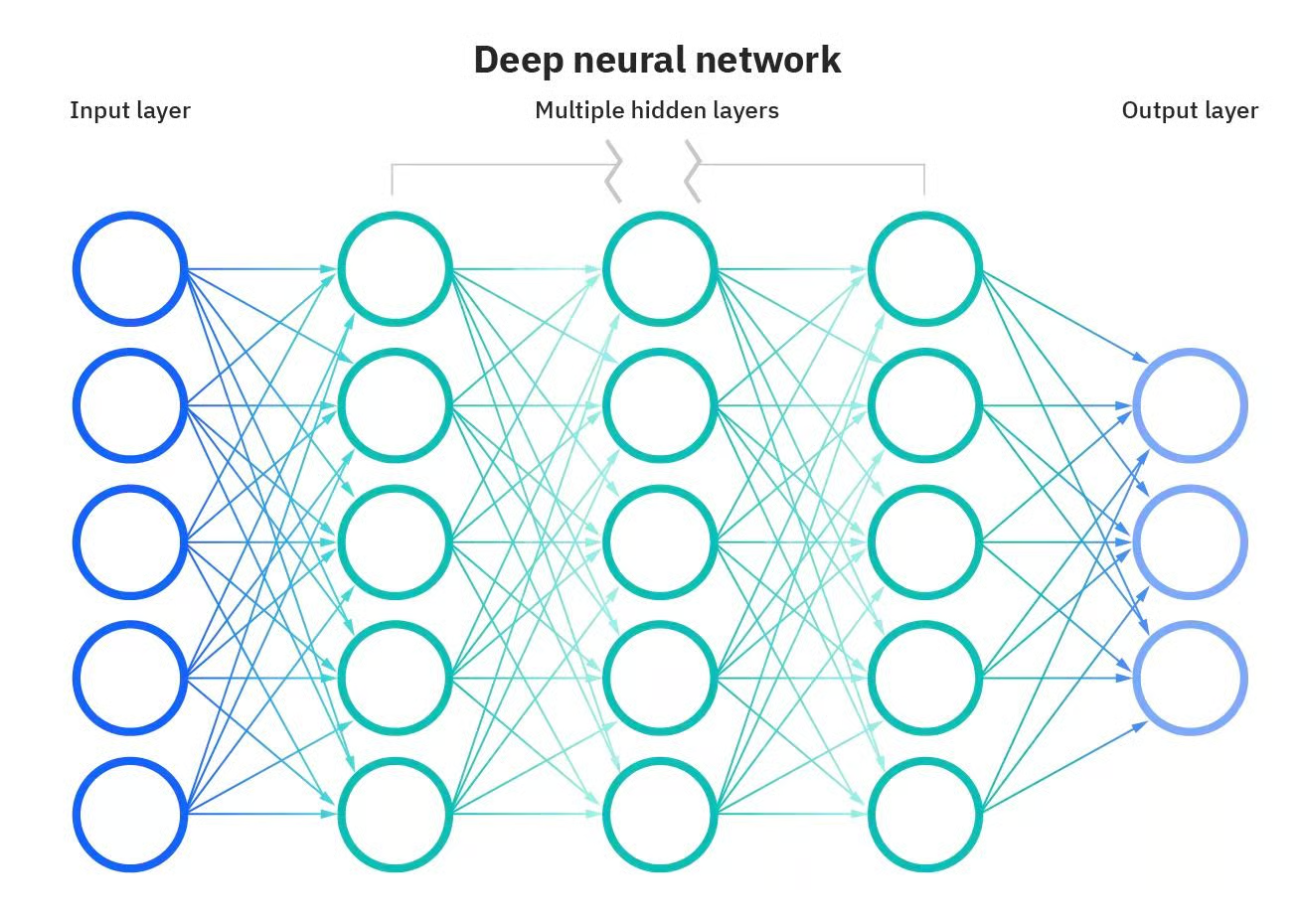
Réseau neuronal profond. Source : DataCamp
Cependant, ces modèles sont bien plus que de simples couches. D'autres composants sont également essentiels pour que les réseaux neuronaux puissent opérer leur magie.
L'une de ces composantes est la fonction d'activation. Vous pouvez considérer les fonctions d'activation comme des décideurs ; elles déterminent quelles informations doivent être transmises à la couche suivante, offrant un nouveau niveau de complexité qui permet aux réseaux neuronaux de prendre des décisions nuancées.
Nous vous présentons ici l'une des fonctions d'activation les plus populaires et les plus utilisées : Unité linéaire rectifiée (ReLU). Nous expliquerons les bases de cette fonction d'activation et certaines de ses variantes, ses avantages et ses limites, et comment les mettre en œuvre avec Pytorch. Poursuivre la lecture ?
Les fonctions d'activation font partie intégrante des réseaux neuronaux. Ils transforment le signal d'entrée d'un nœud d'un réseau neuronal en un signal de sortie qui est ensuite transmis à la couche suivante. Sans fonctions d'activation, les réseaux neuronaux seraient limités à la modélisation de relations linéaires entre les entrées et les sorties, par exemple, par la multiplication de matrices.
Cependant, la plupart des données du monde réel ne peuvent pas être modélisées par des linéarités. Les non-linéarités permettent de saisir des schémas tels que le fait de passer d'aucun enfant à un enfant peut avoir un impact différent sur vos transactions bancaires que le fait de passer de trois enfants à quatre. Si les réseaux neuronaux n'avaient pas de fonctions d'activation, ils ne parviendraient pas à apprendre les modèles non linéaires complexes qui existent dans les événements du monde réel.
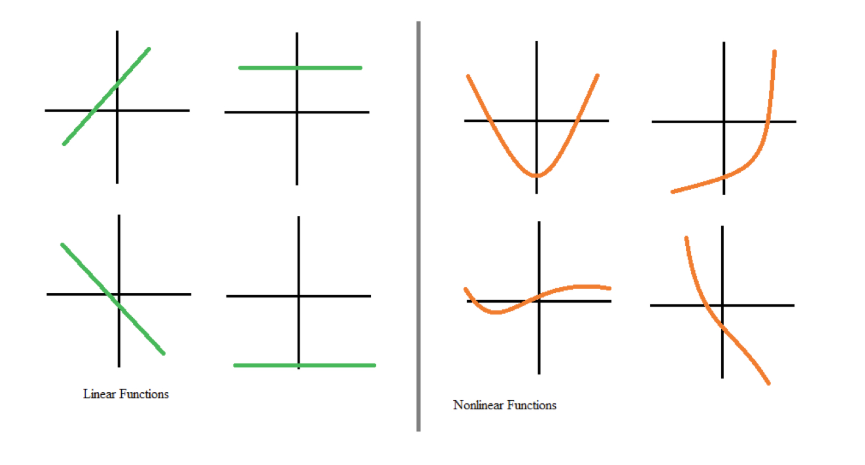
Fonctions linéaires et non linéaires. Source : DataCamp
Les fonctions d'activation permettent aux réseaux neuronaux d'apprendre des relations en introduisant des comportements non linéaires. En d'autres termes, les fonctions d'activation créent un seuil numérique pour décider d'activer ou non un neurone, ce qui introduit un degré de flexibilité essentiel pour que les réseaux neuronaux puissent modéliser des données complexes et nuancées.
L'une des fonctions d'activation les plus populaires et les plus utilisées est la ReLU (unité linéaire rectifiée). Comme d'autres fonctions d'activation, elle confère une non-linéarité au modèle afin d'améliorer les performances de calcul.
La fonction d'activation ReLU a la forme suivante :
f(x) = max(0, x)
La fonction ReLU produit le maximum entre son entrée et zéro, comme le montre le graphique. Pour les entrées positives, la sortie de la fonction est égale à l'entrée. Pour les sorties strictement négatives, la sortie de la fonction est égale à zéro.
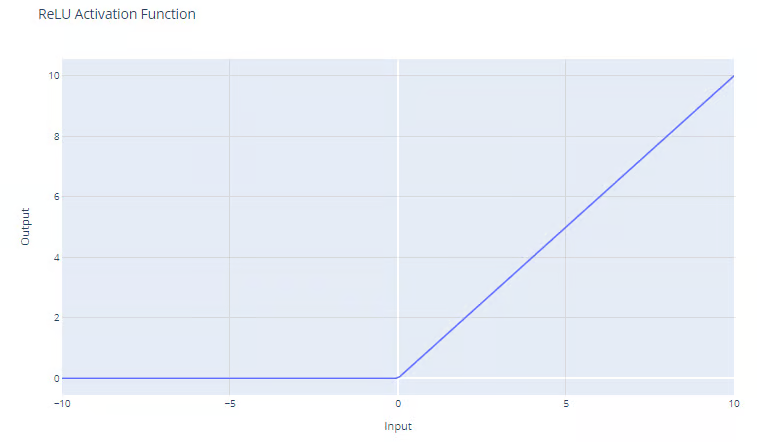
Fonction d'activation ReLU (Rectified Linear Unit). Source : DataCamp
L'un des principaux avantages de ReLu est qu'il permet d'atténuer le problème de la disparition du gradient. Le problème du gradient qui s'évanouit est un défi qui se pose lors de l'apprentissage de réseaux neuronaux profonds utilisant la rétropropagation. Cela se produit lorsque le gradient utilisé pour mettre à jour les poids du réseau devient très petit ou "disparaît" en remontant le réseau. Cela empêche la mise à jour correcte des poids, ce qui peut ralentir ou arrêter le processus d'apprentissage. Vous pouvez lire une explication complète des problèmes de gradient de fuite dans notre cours Introduction à l'apprentissage profond dans PyTorch.
Étant donné que la fonction ReLU n'a pas de limite supérieure et que les gradients ne convergent pas vers zéro pour des valeurs élevées de x, ReLU surmonte le problème de la disparition du gradient, qui est courant lors de l'utilisation des fonctions d'activation sigmoïde et softmax. Consultez notre article séparé pour découvrir d'autres fonctions d'activation populaires.
En outre, étant donné que la ReLU produit un résultat nul pour toutes les entrées négatives, elle conduit naturellement à des activations peu nombreuses. En d'autres termes, comme seul un sous-ensemble de neurones est activé pendant la formation, le calcul est plus efficace.
Enfin, ce comportement permet aux réseaux de s'étendre à de nombreuses couches sans augmentation significative de la charge de calcul, par rapport à des fonctions plus complexes telles que tanh ou sigmoïde. ReLU est donc la fonction d'activation par défaut la plus courante et constitue généralement un bon choix si vous n'êtes pas sûr de la fonction d'activation à utiliser dans votre modèle.
L'implémentation de ReLU dans PyTorch est assez facile. Il vous suffit d'utiliser la fonction nn.ReLU() pour créer la fonction et l'ajouter à votre modèle.
Dans l'exemple suivant, nous appliquons une fonction ReLU à un simple neurone et calculons le gradient dans le cas d'une valeur négative.
# Create a ReLU function with PyTorch
relu_pytorch = nn.ReLU()
# Apply your ReLU function on x, and calculate gradients
x = torch.tensor(-1.0, requires_grad=True)
y = relu_pytorch(x)
y.backward()
# Print the gradient of the ReLU function for x
gradient = x.grad
print(gradient)
>>> tensor(0.)Remarquez que la valeur d'entrée était -1 et que la fonction ReLU a renvoyé zéro. Rappelez-vous que pour les valeurs négatives de x, la sortie de la ReLU est toujours nulle, et en effet, le gradient est nul partout car il n'y a pas de changement dans la fonction pour toute valeur négative de x.
ReLU est sans doute la fonction d'activation la plus utilisée, mais il arrive qu'elle ne soit pas adaptée au problème que vous essayez de résoudre. Heureusement, les chercheurs en apprentissage profond ont mis au point des variantes de ReLU qu'il peut être intéressant de tester dans vos modèles. Voici les alternatives les plus populaires
Leaky ReLu a le formulaire :
f(x) = max(0.01x, x)
L'objectif de Leaky ReLu est de résoudre le problème de la "Leaky ReLu mourante". Nous avons déjà mentionné que ReLU produit toujours des valeurs nulles pour les entrées négatives. Dans ce cas, les gradients des nœuds ayant des valeurs négatives seront fixés à zéro pour le reste de la formation, ce qui empêchera ce paramètre d'apprendre. Pour surmonter cette difficulté, Leaky ReLu utilise un facteur multiplicateur pour les entrées négatives. Par conséquent, la fonction ne sera pas nulle mais aura une petite pente négative, comme le montre le graphique suivant :
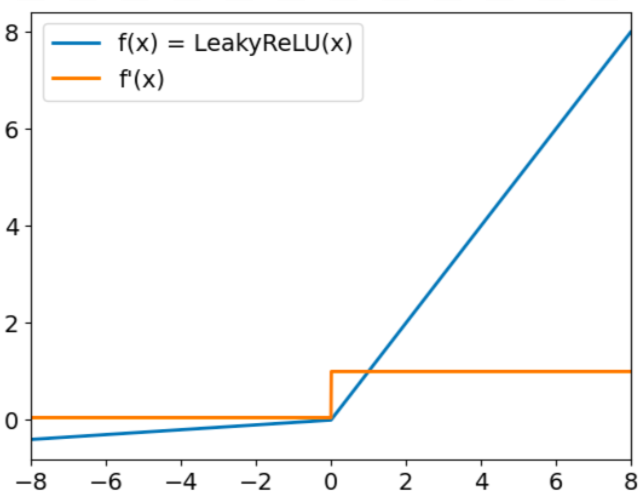
Fonction d'activation Leaky ReLu. Source : DataCamp
Leaky ReLu offre un facteur multiplicateur pour surmonter le problème du ReLU mourant. La ReLU paramétrique (PReLU) fait un pas en avant en proposant un paramètre (a) qui peut être appris au lieu d'une simple constante pour calculer la valeur des entrées négatives :
f(x) = max(ax, x)
Si PReLU offre une amélioration par rapport à ReLU et Leaky ReLU en termes de précision et d'adaptabilité (il est particulièrement bien adapté à la capture de modèles dans des tâches complexes, telles que la vision par ordinateur ou la reconnaissance vocale), il ajoute également de la complexité au modèle. L'apprentissage de ce paramètre peut prendre du temps et nécessite un réglage et une régularisation minutieux.
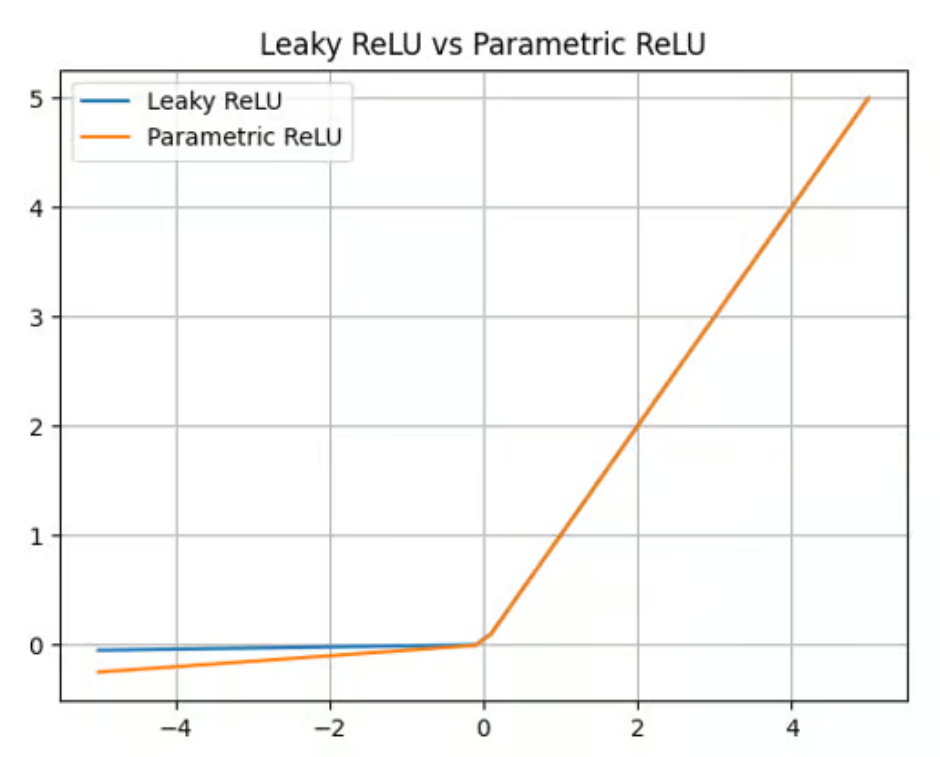
Fonction d'activation paramétrique ReLU. Source : DataCamp
L'unité linéaire exponentielle (ELU) est une autre alternative intéressante à la ReLU. Elle se présente sous la forme de la formule suivante :
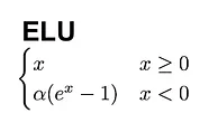
Contrairement à la ReLU, les ELU ont des valeurs négatives, ce qui leur permet de rapprocher les activations moyennes des unités de zéro, les rendant ainsi moins sujettes à la disparition des gradients. En outre, le fait que les activations moyennes soient plus proches de zéro accélère l'apprentissage et la convergence.
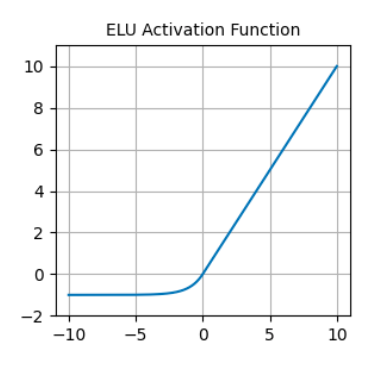
Fonction d'activation ELU. Source : DataCamp
ReLU est une excellente fonction d'activation, mais ce n'est pas une solution miracle. En particulier, ReLU peut souffrir de deux problèmes bien connus.
Le premier est le problème de la ReLU en voie d'extinction. Comme nous l'avons déjà mentionné, ReLU produit toujours des valeurs nulles pour les entrées négatives. Cela peut entraîner une mise à jour des poids de telle sorte que le neurone ne s'activera plus jamais sur aucun point de données.
Dans ce cas, le gradient qui traverse l'unité sera toujours nul à partir de ce moment-là, ce qui empêchera ce paramètre d'apprendre. Des variantes de ReLU, telles que Leaky ReLu et PReLU, ont été créées pour remédier à ce problème.
Des gradients instables peuvent également se produire à l'autre extrémité. Le problème de l'explosion des gradients se produit lorsque les gradients deviennent de plus en plus importants, ce qui entraîne des mises à jour de paramètres considérables et une formation divergente.
Dans ce cas, des gradients d'erreur plus importants s'accumulent et les poids du modèle deviennent trop importants. Ce problème peut entraîner des temps de formation plus longs et des performances médiocres du modèle. Il existe plusieurs techniques pour résoudre les problèmes d'explosion du gradient, notamment l'écrêtage du gradient et la normalisation des lots.
Grâce à ses propriétés uniques, ReLU est devenue la fonction d'activation la plus populaire, étant l'option par défaut dans des frameworks comme PyTorch et TensorFlow, et largement utilisée dans de nombreuses applications d'apprentissage profond, notamment :
Nous avons exploré le rôle central des fonctions d'activation ReLU lors de l'apprentissage des réseaux neuronaux. Malgré sa simplicité, ReLU est l'une des fonctions d'activation les plus efficaces, et sans doute la plus populaire.
Au fur et à mesure de l'évolution des réseaux neuronaux, l'exploration des fonctions d'activation s'étendra sans aucun doute, en incluant éventuellement de nouvelles formes qui répondent aux défis spécifiques des architectures émergentes.
La sélection minutieuse des fonctions d'activation est un exercice d'équilibre - un mélange de compréhension scientifique et d'intuition artistique - qui peut affecter de manière significative les performances des réseaux neuronaux.
Vous souhaitez en savoir plus sur l'apprentissage profond ? Consultez nos documents dédiés et préparez-vous à l'une des technologies les plus transformatrices de l'IA :
Les meilleurs cours de DataCamp
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min