
Course
Recurrent Neural Networks (RNNs) for Language Modeling with Keras
4 hr
16.3K
Activation functions like the Rectified Linear Unit (ReLU) are a cornerstone of modern neural networks. Without them, many real-world AI applications—from image recognition to recommendation systems—wouldn't be possible. This guide explores the basics of ReLU, its advantages, limitations, and implementation.
Some of the most powerful applications of AI wouldn’t be possible without artificial neural networks. Neural networks are computational models inspired by the human brain. These networks consist of interconnected nodes, or "neurons," that work together to process information and make decisions. What makes a neural network "deep" is the number of layers between the input and output. A deep neural network has multiple layers, allowing it to learn more complex features and make more accurate predictions.
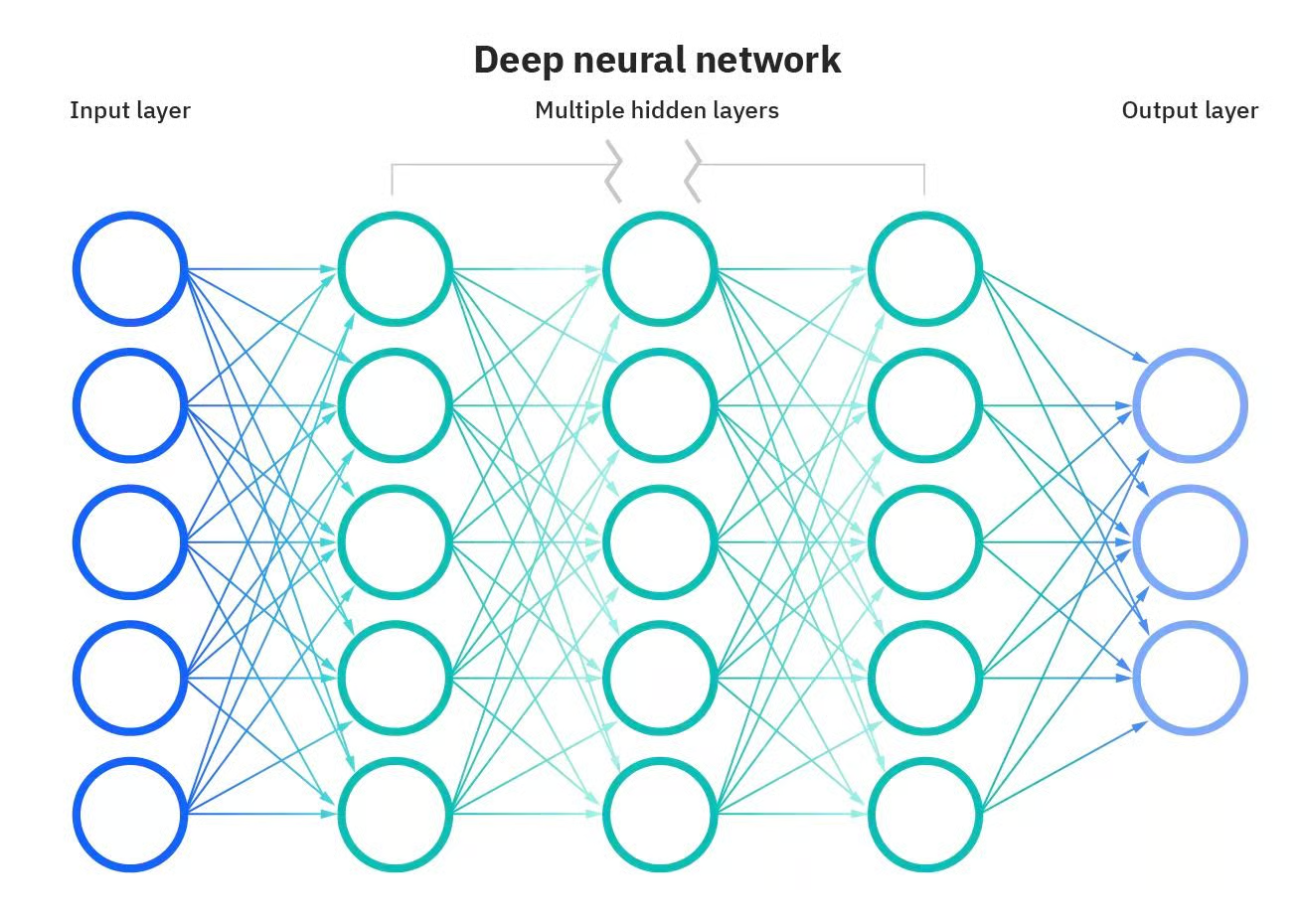
Deep Neural Network. Source: DataCamp
However, these models are much more than simple layers. Other components are also critical for neural networks to make their magic.
One of these components is activation functions. You can see activation functions as decision-makers; they determine what information should be passed along to the next layer, providing a new level of complexity that allows neural networks to make nuanced decisions.
Here, we will introduce one of the most popular and widely used activation functions: Rectified Linear Unit (ReLU). We will explain the basics of this activation function and some of its variants, its advantages and limitations, and how to implement them with Pytorch. Keep reading?
Activation functions are an integral building block of neural networks. They transform the input signal of a node in a neural network into an output signal that is then passed on to the next layer. Without activation functions, neural networks would be restricted to modeling only linear relationships between inputs and outputs, for example, through matrix multiplication.
However, most real-world data cannot be modeled with linearities. Non-linearities capture patterns like how going from no children to one child may impact your banking transactions differently than going from three children to four. If neural networks had no activation functions, they would fail to learn the complex non-linear patterns that exist in real-world events.
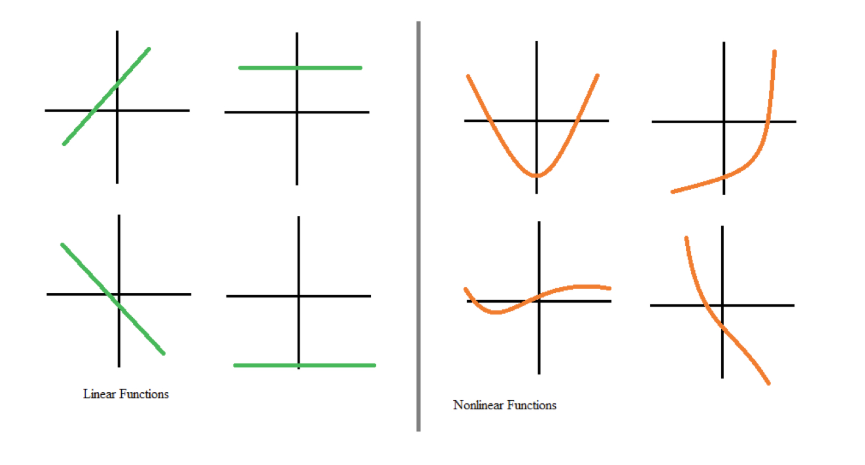
Linear vs nonlinear functions. Source: DataCamp
Activation functions enable neural networks to learn relationships by introducing non-linear behaviors. In other words, activation functions create a numerical threshold to decide whether to activate a neuron, introducing a degree of flexibility that is key for neural networks to model complex and nuanced data.
One of the most popular and widely-used activation functions is ReLU (rectified linear unit). As with other activation functions, it provides non-linearity to the model for better computation performance.
The ReLU activation function has the form:
f(x) = max(0, x)
The ReLU function outputs the maximum between its input and zero, as shown by the graph. For positive inputs, the output of the function is equal to the input. For strictly negative outputs, the output of the function is equal to zero.
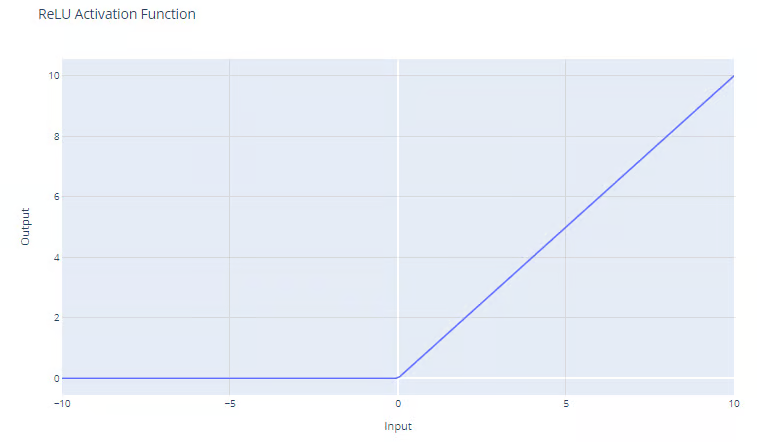
Rectified Linear Unit (ReLU) activation function. Source: DataCamp
One of the most significant advantages of ReLu is that it helps mitigate the vanishing gradient problem. The vanishing gradient problem is a challenge that occurs when training deep neural networks using backpropagation. It happens when the gradient used to update the network's weights becomes very small or "vanishes" as it moves back through the network. This prevents the weights from updating properly, which can slow down or stop the learning process. You can read a full explanation of the vanishing gradient problems in our Introduction to Deep Learning in PyTorch Course.
Since the ReLU function does not have an upper bound and the gradients do not converge to zero for high values of x, ReLU overcomes the vanishing gradient problem, which is common when using the sigmoid and softmax activation functions. Check our separate article to discover other popular activation functions.
Further, since ReLU outputs zero for all negative inputs, it naturally leads to sparse activations. In other words, since only a subset of neurons are activated during training, this leads to more efficient computation.
Finally, this behavior allows networks to scale to many layers without a significant increase in computational burden, compared to more complex functions like tanh or sigmoid. This makes ReLU the most common default activation function and is usually a good choice if you are unsure about the activation function to use in your model.
Implementing ReLU in PyTorch is fairly easy. You just have to use the nn.ReLU() function to create the function and add it to your model.
In the following example, we apply a ReLU function to a simple neuron and calculate the gradient in the case of a negative value.
# Create a ReLU function with PyTorch
relu_pytorch = nn.ReLU()
# Apply your ReLU function on x, and calculate gradients
x = torch.tensor(-1.0, requires_grad=True)
y = relu_pytorch(x)
y.backward()
# Print the gradient of the ReLU function for x
gradient = x.grad
print(gradient)
>>> tensor(0.)Notice that the input value was -1, and the ReLU function returned zero. Recall that for negative values of x, the output of ReLU is always zero, and indeed, the gradient is zero everywhere because there is no change in the function for any negative value of x.
ReLU is arguably the most used activation function, but sometimes, it may not work for the problem you’re trying to solve. Fortunately, deep learning researchers have developed some ReLU variants that may be worth testing in your models. Here are the most popular alternatives
Leaky ReLU has the form:
f(x) = max(0.01x, x)
The goal of Leaky Relu is to address the so-called "dying ReLU" problem. We have already mentioned that ReLU always outputs null values for negative inputs. When this happens, the gradients of nodes with negative values will be set to zero for the rest of the training, which will prevent this parameter from learning. To overcome this challenge, Leaky ReLU uses a multiplying factor for negative inputs. As a result, the function will not be zero but will instead have a small negative slope, as represented in the following graph:
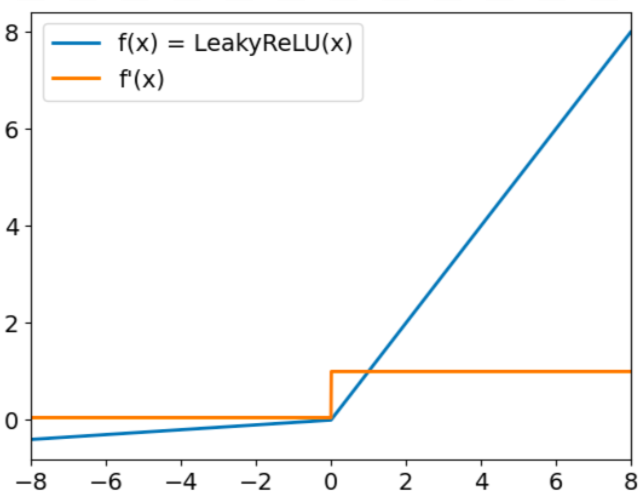
Leaky ReLU activation function. Source: DataCamp
Leaky ReLU offers a multiplying factor to overcome the dying ReLU problem. Parametric ReLU (PReLU) goes one step forward, offering a learnable parameter (a) instead of a simple constant to calculate the value of negative inputs:
f(x) = max(ax, x)
While PReLU offers an improvement compared to ReLU and Leaky ReLU in terms of accuracy and adaptability (it’s particularly well-suited for capturing patterns in complex tasks, such as computer vision or speech recognition), it also adds complexity to the model. Training this parameter can be time-consuming and requires careful tuning and regularization.
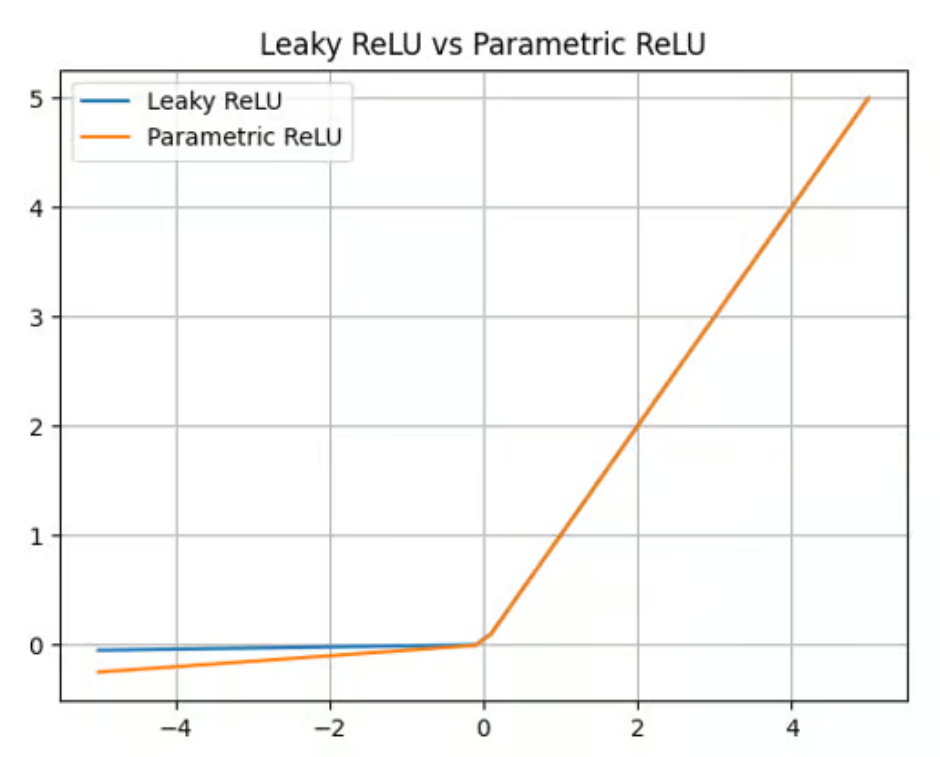
Parametric ReLU activation function. Source: DataCamp
Another great alternative to ReLU is the Exponential linear unit (ELU), which comes with the following formula:
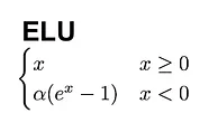
In contrast to ReLU, ELUs have negative values, which allows them to push mean unit activations closer to zero, thereby making them less prone to vanishing gradients. Also, having mean activations closer to zero causes faster learning and convergence.
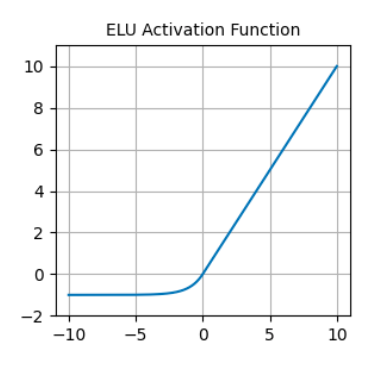
ELU activation function. Source: DataCamp
ReLU is a great activation function, but it’s not a silver bullet. In particular, ReLU may suffer from two well-known problems.
The first is the dying ReLU problem. As already mentioned, ReLU always outputs null values for negative inputs. This can cause the weights to update in such a way that the neuron will never activate on any data point again.
If this happens, then the gradient flowing through the unit will forever be zero from that point on, preventing this parameter from learning. ReLU variants, such as Leaky ReLU and PReLU, were created to address this problem.
Unstable gradients can also happen on the other end. The exploding gradients problem occurs when the gradients get increasingly large, leading to huge parameter updates and divergent training.
In this case, larger error gradients accumulate, and the model weights become too large. This issue can cause longer training times and poor model performance. There are several techniques to address the exploding gradient problems, including gradient clipping and batch normalization.
Thanks to its unique properties, ReLU has become the most popular activation function, being the default option in frameworks like PyTorch and TensorFlow, and widely used in many deep learning applications, including:
We have explored the pivotal role of ReLU activation functions during the training of neural networks. Despite its simplicity, ReLU is one of the most effective activation functions out there, and arguably the most popular one.
As neural networks continue to evolve, the exploration of activation functions will undoubtedly expand, possibly including new forms that address specific challenges of emerging architectures.
The careful selection of activation functions is a balancing act—a blend of scientific understanding and artful intuition—that can significantly affect the performance of neural networks.
Interested in learning more about deep learning? Check out our dedicated materials and get ready for one of the most transformative technologies in AI:
Top DataCamp Courses
Course
Course
Course
Tutorial
Moez Ali
Tutorial
Hadrien Jean
Tutorial
Sejal Jaiswal
Tutorial
Sayak Paul
Tutorial
Arun Nanda
Tutorial
Karlijn Willems
