Programa
Llama Fundamentals
4 h
Em 2017, o Google abalou a comunidade de IA com seu artigo inovador "Atenção é tudo o que você precisa". Este artigo apresentou a arquitetura Transformer, que revolucionou a modelagem de sequências usando mecanismos de autoatenção.
Recentemente, o Google divulgou um novo documento intitulado "Titans: Learning to Memorize at Test Time " (Aprendendo a memorizar na hora do teste),, no qual eles propõem uma nova arquitetura de memória projetada para aprimorar a forma como os sistemas de IA armazenam e utilizam as informações.
Inspirando-se nas complexidades da memória humana, esta pesquisa visa superar as limitações dos sistemas de memória existentes nos modelos de IA, especialmente a janela de contexto restrito dos Transformers.
A arquitetura Titans apresenta uma abordagem sofisticada para integrar diferentes tipos de memória - de curto prazo, de longo prazo e persistente - nos modelos de IA, permitindo que eles aprendam e memorizem dinamicamente durante o tempo de teste.
O mecanismo de "surpresa" é fundamental para isso, pois se baseia na tendência do cérebro humano de se lembrar de eventos inesperados. Essa arquitetura permite que os modelos gerenciem a memória de forma eficiente, incorporando surpresas momentâneas e passadas, garantindo a memorização e a recuperação eficazes dos dados.
Neste artigo, simplificarei os conceitos e mecanismos apresentados no documento Titans e explorarei o possível impacto que essa nova arquitetura poderá ter no futuro da IA.
Transformadores são a arquitetura usada na maioria dos LLMs atuais. Eles são conhecidos por sua capacidade de processar sequências de dados, como palavras em uma frase. Eles operam de forma muito eficaz usando algo chamado "atenção", que as ajuda a se concentrar em partes relevantes dos dados. No entanto, eles enfrentam um desafio importante: o tamanho de sua janela de contexto.
A janela de contexto é basicamente a quantidade de informações que um Transformer pode considerar de uma só vez. Pense nisso como uma janela que corre ao longo de uma frase, capturando um segmento de palavras para que você entenda seu significado no contexto.
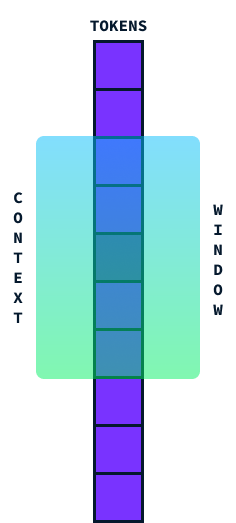
Idealmente, gostaríamos que essa janela fosse tão grande quanto possível para processar grandes seções de texto de uma só vez, mas há um problema. Quando tentamos aumentar essa janela de contexto, a quantidade de computação necessária aumenta significativamente devido à complexidade quadrática de tempo e espaço. complexidade quadrática de tempo e espaço da arquitetura do transformador.
Isso significa que, se dobrarmos o tamanho da janela de contexto, o cálculo não apenas dobrará, mas se tornará quatro vezes mais exigente! Isso acontece porque cada palavra na janela precisa ser comparada com todas as outras, de modo que os cálculos aumentam rapidamente.
Os modelos atuais de última geração (SOTA) têm 2 milhões de janelas de contexto de token. No entanto, seu processamento é bastante caro, e alguns aplicativos, como a compreensão de vídeo, exigem janelas de contexto maiores. Ter uma janela de contexto mais longa sem um grande aumento no custo computacional permitiria que os LLMs lidassem com sequências mais longas de forma mais eficaz, melhorando seu desempenho em tarefas que exigem a compreensão de grandes volumes de dados de uma só vez. É por isso que a superação do problema do custo quadrático é um dos principais focos do avanço desses modelos.
Titans é uma nova arquitetura que aprimora a capacidade dos modelos de IA de armazenar e recuperar informações de forma eficaz, especialmente ao lidar com dados grandes e complexos, inspirando-se nas complexidades da memória humana.
A memória desempenha um papel fundamental no aprendizado e no comportamento humano. Ela nos ajuda a reter informações de experiências passadas, que usamos para tomar decisões, adaptar-nos a novas situações e resolver problemas. A memória humana pode ser amplamente categorizada em três tipos:
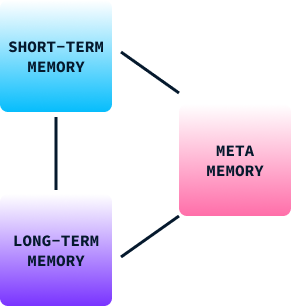
No comportamento humano, esses tipos de memória trabalham juntos para nos permitir aprender com nossos ambientes, adaptar estratégias e melhorar nossos comportamentos ao longo do tempo. Sem ele, ficaríamos restritos a reflexos básicos e comportamentos estereotipados.
Assim como o modelo de memória humana, a estrutura de memória do Titan é composta de três partes:
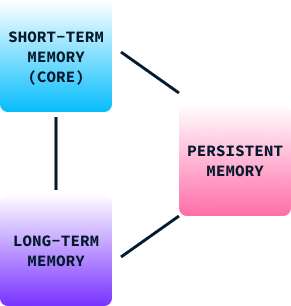
Ao integrar esses três tipos de memória, a arquitetura Titans permite que os modelos de IA gerenciem dinamicamente as informações de forma muito semelhante ao nosso cérebro, combinando o processamento imediato com a retenção de experiências e conhecimentos anteriores.
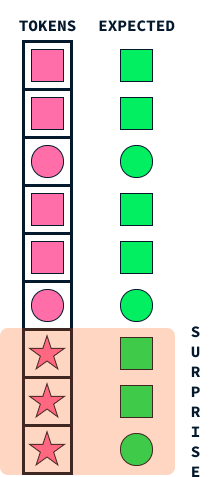
O mecanismo de "surpresa" dos Titãs imita um aspecto fundamental da memória humana: nossa tendência de lembrar eventos surpreendentes ou inesperados de forma mais vívida. Essa abordagem ajuda os modelos de IA a decidir quais informações armazenar, identificando dados que se destacam do que o modelo espera.
Imagine que você está andando pela rua e tudo parece comum e rotineiro. Talvez você não se lembre dessa caminhada diária algumas semanas depois. No entanto, se algo inesperado acontecer, como um desfile colorido passando ou um telefonema com notícias interessantes, esses elementos surpreendentes chamarão sua atenção, tornando-os mais memoráveis.
Da mesma forma, os Titãs empregam essa ideia de surpresa para priorizar quais informações devem ser memorizadas. Quando o modelo encontra dados que diferem significativamente do que ele previu (muito parecido com nosso desfile colorido), ele marca essas informações como surpreendentes. O sistema de memória do Titans prioriza o armazenamento desses eventos inesperados, garantindo que dados importantes, porém incomuns, não sejam esquecidos.
Esse mecanismo permite que o Titã gerencie de forma eficiente os recursos de memória, concentrando-se em informações significativas e discrepantes, em vez de tentar reter todos os detalhes. Assim como os seres humanos têm maior probabilidade de se lembrar do inesperado, os Titãs aplicam essa estratégia natural para processar e reter informações vitais de forma eficaz, permitindo que eles tenham um melhor desempenho em tarefas complexas que envolvem a classificação de grandes quantidades de dados.
Formalmente, o conceito de surpresa é definido como o gradiente da função de perda em relação à entrada. Essencialmente, isso mede o quanto os parâmetros do modelo precisariam ser alterados em resposta à nova entrada para minimizar a perda.
A intuição por trás do uso do gradiente como uma medida de surpresa é que um gradiente grande implica a necessidade de mudanças significativas no modelo para acomodar a nova entrada, indicando que a entrada é muito diferente do que o modelo já viu antes ou que é inesperada e, portanto, surpreendente.
O mecanismo de esquecimento na arquitetura dos Titãs é um componente essencial projetado para gerenciar a memória neural de longo prazo de forma eficaz, garantindo que o modelo retenha informações relevantes e, ao mesmo tempo, descarte o que não é mais necessário.
Esse mecanismo é vital ao lidar com grandes quantidades de dados, em que a memória pode ficar sobrecarregada com informações desatualizadas ou irrelevantes. Na prática, o mecanismo de esquecimento funciona ajustando a regra de atualização da memória para apagar seletivamente as informações com base em seu fator surpresa e relevância, que são avaliados dinamicamente durante a inferência.
Especificamente, um parâmetro de adaptação determina quanto do estado anterior da memória deve ser mantido, permitindo que o modelo limpe ou preserve o conteúdo da memória de forma adaptativa. Esse mecanismo evita o transbordamento da memória e promove a utilização eficiente do espaço de memória, melhorando, em última análise, a capacidade do modelo de se concentrar em entradas críticas e novas, sem ser sobrecarregado por um acúmulo de dados desnecessários.
Essa abordagem reflete de perto os processos cognitivos humanos, nos quais as memórias sem importância ou desatualizadas desaparecem com o tempo, permitindo um processamento cognitivo mais eficiente e a recuperação de informações.
Em aprendizado de máquina tradicional a aprendizagem ocorre durante a fase de treinamento. Depois que o modelo é treinado, ele é implantado para realizar previsões de inferência com base em dados novos e não vistos, sem modificações adicionais em seus parâmetros aprendidos.
A arquitetura Titans introduz uma mudança inovadora nesse paradigma, permitindo que os modelos aprendam dinamicamente durante a inferência, também conhecida como tempo de teste. Esse recurso permite que os Titãs atualizem sua memória e seus parâmetros com base na surpresa e na importância dos dados recebidos durante o processamento.
A capacidade de aprender no momento da inferência oferece várias vantagens significativas:
A arquitetura do Titans usa três maneiras distintas de incorporar a memória, cada uma inspirada em diferentes aspectos da cognição humana. Vamos detalhar cada modo de memória usando analogias simples.
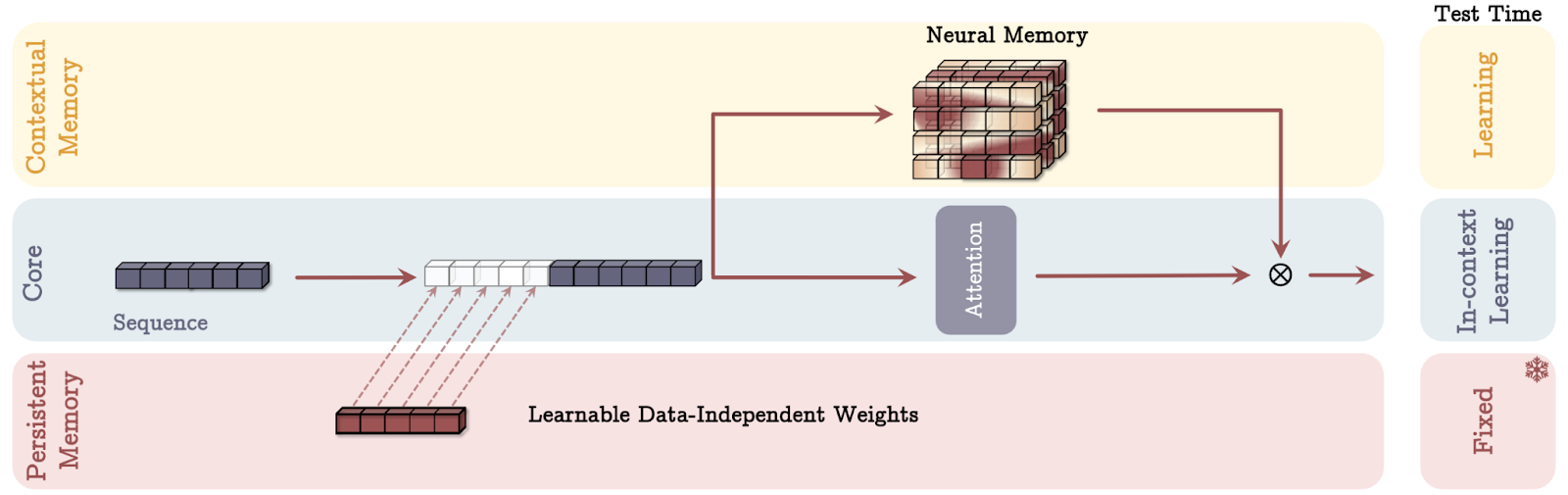
Fonte: Behrouz et. al, 2024
Imagine que você tenha um assistente pessoal durante uma reunião. Esse assistente faz anotações abrangentes de conversas anteriores (memória de longo prazo) e sussurra informações relevantes no seu ouvido conforme necessário (recuperação).
No modo MAC, o modelo de IA funciona de forma semelhante. Ele retém um histórico detalhado dos dados anteriores e os integra aos dados atuais para que você possa tomar decisões informadas. Assim como o seu assistente ajuda a combinar o conhecimento passado com as discussões atuais para aprimorar a tomada de decisões, o MAC usa a memória de longo prazo para fornecer contexto às informações imediatas que estão sendo processadas.
Imagine que você tenha dois consultores em sua mente. Uma se concentra apenas no que está acontecendo agora, fornecendo insights sobre tarefas imediatas (atenção de curto prazo). O outro se baseia em anos de experiência e sabedoria acumuladas (memória de longo prazo).
O modo MAG atua como um guardião que decide quanta atenção deve ser dada a cada consultor, ajustando dinamicamente o foco com base nas necessidades atuais em relação ao aprendizado anterior. Isso garante uma abordagem equilibrada, permitindo que a IA se adapte se a tarefa em questão exige precisão imediata ou insights de experiências anteriores.
Pense nesse modo como várias camadas de compreensão, em que cada camada processa as informações de forma exclusiva:
Esse processamento em camadas reflete a forma como geralmente digerimos informações complexas em etapas, construindo e refinando nosso entendimento passo a passo. Cada modo oferece pontos fortes exclusivos, permitindo que os Titãs lidem efetivamente com tarefas variadas, imitando diferentes aspectos de como os seres humanos processam e retêm informações.
Os resultados experimentais destacam a superioridade da arquitetura Titans em relação aos transformadores tradicionais e aos modelos modernos em várias tarefas. Aqui está um detalhamento das principais descobertas:
De modo geral, os Titãs utilizam uma nova abordagem de gerenciamento de memória que lhes permite lidar com tarefas complexas e de contexto longo com mais eficiência, definindo um novo padrão para modelos de IA em termos de escalabilidade e precisão.
A arquitetura atual do Transformer, embora eficiente, tem dificuldades para lidar com contextos extremamente longos devido a problemas de dimensionamento. A arquitetura inovadora do Titans, inspirada na memória humana, supera essas limitações gerenciando dinamicamente a memória de curto prazo, de longo prazo e persistente.
Acredito que a capacidade do Titans de aprender no momento da inferência, adaptar-se a novos dados e priorizar a memória com base em um mecanismo de "surpresa" tem o potencial de criar sistemas de IA mais semelhantes aos humanos em seu processamento de informações. Isso pode melhorar o desempenho dos sistemas de IA em ambientes complexos e dinâmicos, o que pode ser um divisor de águas para agentes de IA como o Operador da OpenAI.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Yuliya Melnik
15 min
blog
Richie Cotton
7 min
Tutorial
Arunn Thevapalan


