Cursus
Les fondamentaux du lama
4 h
En 2017, Google a secoué la communauté de l'IA en publiant un article révolutionnaire intitulé "L'attention est tout ce dont vous avez besoin". Cet article a présenté l'architecture Transformer, qui a révolutionné la modélisation des séquences en utilisant des mécanismes d'auto-attention.
Récemment, Google a publié un nouveau document intitulé "Titans" : Learning to Memorize at Test Time ",, dans lequel ils proposent une nouvelle architecture de mémoire conçue pour améliorer la façon dont les systèmes d'intelligence artificielle stockent et utilisent les informations.
S'inspirant des subtilités de la mémoire humaine, cette recherche vise à surmonter les limites des systèmes de mémoire existants dans les modèles d'IA, en particulier la fenêtre contextuelle restreinte de Transformers.
L'architecture Titans introduit une approche sophistiquée pour intégrer différents types de mémoire - à court terme, à long terme et persistante - dans les modèles d'IA, ce qui leur permet d'apprendre et de mémoriser dynamiquement pendant les tests.
Le mécanisme de "surprise" est essentiel à cet égard, car il s'appuie sur la tendance du cerveau humain à se souvenir d'événements inattendus. Cette architecture permet aux modèles de gérer efficacement la mémoire en incorporant les surprises du moment et du passé, garantissant ainsi une mémorisation et une récupération efficaces des données.
Dans cet article, je vais simplifier les concepts et les mécanismes introduits dans le document de Titans et explorer l'impact potentiel de cette nouvelle architecture sur l'avenir de l'IA.
Les transformateurs constituent l'architecture utilisée dans la plupart des LLM aujourd'hui. Ils sont connus pour leur capacité à traiter des séquences de données, comme les mots d'une phrase. Ils fonctionnent très efficacement en utilisant ce que l'on appelle l'"attention".attention"qui les aide à se concentrer sur les parties pertinentes des données. Cependant, ils sont confrontés à un problème majeur : la taille de leur fenêtre contextuelle.
La fenêtre contextuelle représente essentiellement la quantité d'informations qu'un transformateur peut prendre en compte en même temps. Considérez-le comme une fenêtre qui court le long d'une phrase, capturant un segment de mots pour en comprendre le sens dans son contexte.
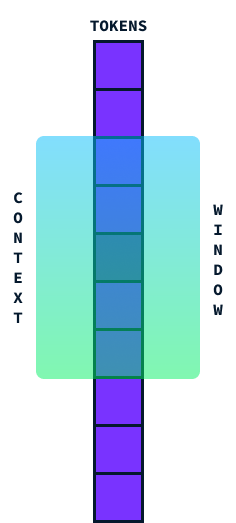
Idéalement, nous aimerions que cette fenêtre soit aussi grande que possible afin de pouvoir traiter de grandes sections de texte en une seule fois, mais il y a un problème. Lorsque nous essayons d'agrandir cette fenêtre contextuelle, la quantité de calcul nécessaire augmente de manière significative en raison de la complexité quadratique en termes de temps et d'espace. complexité quadratique en temps et en espace de l'architecture du transformateur.
Cela signifie que si nous doublons la taille de la fenêtre contextuelle, le calcul ne fait pas que doubler, il devient quatre fois plus exigeant ! Cela est dû au fait que chaque mot de la fenêtre doit être comparé à tous les autres mots, ce qui fait que les calculs augmentent rapidement.
Les modèles de pointe actuels (SOTA) comportent 2 millions de fenêtres contextuelles de jetons. Cependant, leur traitement est assez coûteux et certaines applications, telles que la compréhension de vidéos, nécessitent des fenêtres contextuelles plus larges. Le fait de disposer d'une fenêtre contextuelle plus longue sans augmentation considérable des coûts de calcul permettrait aux LLM de traiter des séquences plus longues de manière plus efficace, ce qui améliorerait leurs performances dans les tâches qui nécessitent la compréhension de plus grands ensembles de données en une seule fois. C'est pourquoi la résolution du problème du coût quadratique est une priorité majeure dans l'évolution de ces modèles.
Titans est une nouvelle architecture qui améliore la capacité des modèles d'IA à stocker et à récupérer des informations de manière efficace, en particulier lorsqu'il s'agit de données volumineuses et complexes, en s'inspirant des subtilités de la mémoire humaine.
La mémoire joue un rôle crucial dans l'apprentissage et le comportement humains. Elle nous aide à retenir les informations issues de nos expériences passées, que nous utilisons pour prendre des décisions, nous adapter à de nouvelles situations et résoudre des problèmes. La mémoire humaine peut être classée en trois catégories :
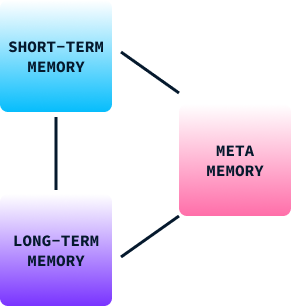
Dans le comportement humain, ces types de mémoire fonctionnent ensemble pour nous permettre d'apprendre de nos environnements, d'adapter nos stratégies et d'améliorer nos comportements au fil du temps. Sans elle, nous serions limités à des réflexes de base et à des comportements stéréotypés.
Tout comme le modèle de mémoire humaine, la structure de la mémoire de Titan est composée de trois parties :
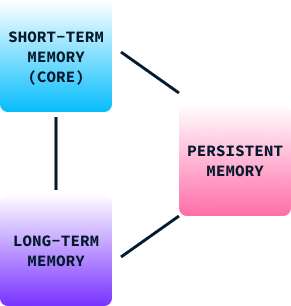
En intégrant ces trois types de mémoire, l'architecture Titans permet aux modèles d'IA de gérer dynamiquement les informations, à l'instar de notre cerveau, en combinant le traitement immédiat avec la rétention des expériences et des connaissances passées.
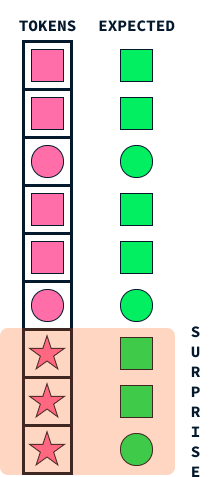
Le mécanisme de "surprise" chez les Titans imite un aspect fondamental de la mémoire humaine : notre tendance à nous souvenir plus intensément d'événements surprenants ou inattendus. Cette approche aide les modèles d'IA à décider des informations à stocker en identifiant les données qui se distinguent de celles auxquelles le modèle s'attend.
Imaginez que vous marchez dans la rue et que tout vous semble ordinaire et routinier. Vous ne vous souviendrez peut-être pas de cette promenade quotidienne quelques semaines plus tard. En revanche, si un événement inattendu se produit, comme le passage d'un défilé coloré ou la réception d'un appel téléphonique annonçant une nouvelle passionnante, ces éléments surprenants attirent votre attention, ce qui les rend plus mémorables.
De la même manière, les Titans utilisent cette idée de surprise pour hiérarchiser les informations à mémoriser. Lorsque le modèle rencontre des données qui diffèrent sensiblement de ce qu'il avait prévu (un peu comme notre défilé coloré), il signale ces informations comme surprenantes. Le système de mémoire de Titans donne alors la priorité au stockage de ces événements inattendus, en veillant à ce que les données importantes mais inhabituelles ne soient pas négligées.
Ce mécanisme permet aux Titans de gérer efficacement les ressources de leur mémoire en se concentrant sur les informations significatives et aberrantes au lieu d'essayer de retenir chaque détail. Tout comme les humains sont plus enclins à se souvenir de l'inattendu, les Titans appliquent cette stratégie naturelle pour traiter et retenir efficacement les informations vitales, ce qui leur permet d'être plus performants dans les tâches complexes qui impliquent de trier de grandes quantités de données.
Formellement, le concept de surprise est défini comme le gradient de la fonction de perte par rapport à l'entrée. Il s'agit essentiellement de mesurer l'ampleur de la modification des paramètres du modèle en réponse à la nouvelle entrée afin de minimiser la perte.
L'intuition qui sous-tend l'utilisation du gradient comme mesure de la surprise est qu'un gradient important implique que des changements significatifs sont nécessaires dans le modèle pour s'adapter à la nouvelle entrée, ce qui indique que l'entrée est très différente de ce que le modèle a vu auparavant ou qu'elle est inattendue et, par conséquent, surprenante.
Le mécanisme d'oubli dans l'architecture de Titans est un élément essentiel conçu pour gérer efficacement la mémoire neuronale à long terme, en veillant à ce que le modèle conserve les informations pertinentes tout en éliminant ce qui n'est plus nécessaire.
Ce mécanisme est vital lorsqu'il s'agit de traiter de grandes quantités de données, où la mémoire pourrait être submergée par des informations obsolètes ou non pertinentes. Dans la pratique, le mécanisme d'oubli fonctionne en ajustant la règle de mise à jour de la mémoire pour effacer sélectivement les informations en fonction de leur facteur de surprise et de leur pertinence, qui est évaluée de manière dynamique pendant l'inférence.
Plus précisément, un paramètre de déclenchement adaptatif détermine la quantité de l'état antérieur de la mémoire à conserver, ce qui permet au modèle d'effacer ou de préserver le contenu de la mémoire de manière adaptative. Un tel mécanisme empêche le débordement de la mémoire et favorise une utilisation efficace de l'espace mémoire, améliorant ainsi la capacité du modèle à se concentrer sur les données critiques et nouvelles sans être encombré par une accumulation de données inutiles.
Cette approche reflète étroitement les processus cognitifs humains, dans lesquels les souvenirs sans importance ou périmés s'estompent avec le temps, ce qui permet un traitement cognitif et une récupération des informations plus efficaces.
Dans le cadre de l'apprentissage automatique modèles traditionnels d'apprentissage automatique traditionnels, l'apprentissage a lieu pendant la phase de formation. Une fois le modèle formé, il est déployé pour effectuer des inférences, c'est-à-dire des prédictions basées sur de nouvelles données inédites, sans autre modification des paramètres qu'il a appris.
L'architecture Titans introduit un changement révolutionnaire dans ce paradigme en permettant aux modèles d'apprendre dynamiquement pendant l'inférence, également connue sous le nom de temps de test. Cette capacité permet aux Titans de mettre à jour leur mémoire et leurs paramètres en fonction de la surprise et de l'importance des données reçues tout en les traitant.
La possibilité d'apprendre au moment de l'inférence offre plusieurs avantages significatifs :
L'architecture de Titans intègre la mémoire de trois manières distinctes, chacune inspirée de différents aspects de la cognition humaine. Décortiquons chaque mode de mémoire à l'aide d'analogies simples.
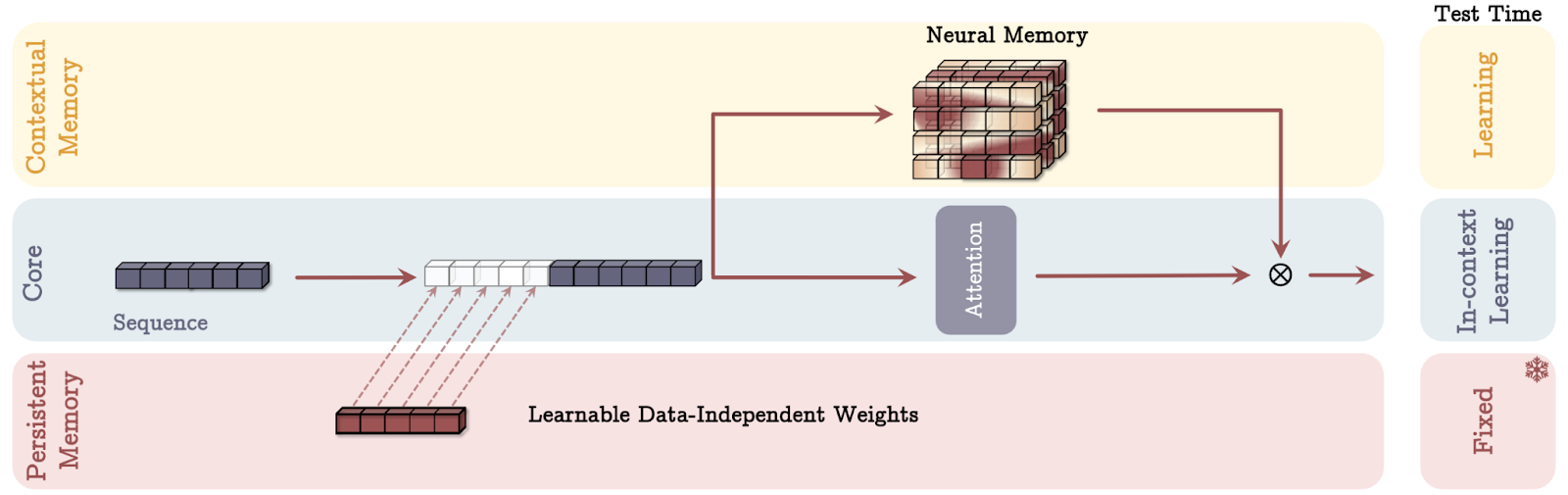
Source : Behrouz et. al, 2024
Imaginez que vous ayez un assistant personnel pendant une réunion. Cet assistant prend des notes détaillées des conversations précédentes (mémoire à long terme) et vous chuchote des informations pertinentes à l'oreille en cas de besoin (récupération).
En mode MAC, le modèle AI fonctionne de la même manière. Il conserve un historique détaillé des données passées et les intègre aux données actuelles pour prendre des décisions éclairées. Tout comme votre assistant vous aide à combiner les connaissances passées avec les discussions présentes pour améliorer votre prise de décision, le MAC utilise la mémoire à long terme pour fournir un contexte à l'information immédiate en cours de traitement.
Imaginez que vous ayez deux conseillers en tête. La première se concentre uniquement sur ce qui se passe dans l'instant, ce qui permet d'obtenir des informations sur les tâches immédiates (attention à court terme). L'autre s'appuie sur des années d'expérience et de sagesse accumulées (mémoire à long terme).
Le mode MAG agit comme un gardien qui décide de l'attention à accorder à chaque conseiller, en ajustant dynamiquement l'attention en fonction des besoins actuels par rapport à l'apprentissage passé. Cela garantit une approche équilibrée, permettant à l'IA de s'adapter, que la tâche à accomplir exige une précision immédiate ou des connaissances tirées des expériences passées.
Considérez ce mode comme de multiples couches de compréhension, où chaque couche traite l'information de manière unique :
Ce traitement en couches reflète la manière dont nous assimilons souvent des informations complexes par étapes, en construisant et en affinant notre compréhension pas à pas. Chaque mode offre des atouts uniques, permettant aux Titans de traiter efficacement des tâches variées en imitant les différents aspects de la façon dont les humains traitent et retiennent les informations.
Les résultats expérimentaux mettent en évidence la supériorité de l'architecture Titans par rapport aux transformateurs traditionnels et aux modèles modernes dans diverses tâches. Voici un aperçu des principaux résultats :
Dans l'ensemble, les Titans exploitent une nouvelle approche de gestion de la mémoire qui leur permet de traiter plus efficacement les tâches complexes à contexte long, établissant ainsi une nouvelle norme pour les modèles d'IA en termes d'évolutivité et de précision.
L'architecture actuelle de Transformer, bien que puissante, a du mal à gérer des contextes extrêmement longs en raison de problèmes de mise à l'échelle. L'architecture innovante de Titans, inspirée de la mémoire humaine, surmonte ces limites en gérant dynamiquement la mémoire à court terme, la mémoire à long terme et la mémoire persistante.
Je pense que la capacité des Titans à apprendre au moment de l'inférence, à s'adapter aux nouvelles données et à hiérarchiser la mémoire sur la base d'un mécanisme de "surprise" a le potentiel de créer des systèmes d'IA qui ressemblent davantage à l'homme dans leur traitement de l'information. Cela pourrait améliorer les performances des systèmes d'IA dans des environnements complexes et dynamiques, ce qui pourrait changer la donne pour les agents d'IA tels que l'Opérateur de l'OpenAI. l'opérateur d'OpenAI.
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach