
Track
Llama Fundamentals
4 hr
In 2017, Google shook the AI community with its groundbreaking paper "Attention is All You Need." This paper introduced the Transformer architecture, which revolutionized sequence modeling by using self-attention mechanisms.
Recently, Google released a new paper titled "Titans: Learning to Memorize at Test Time," in which they propose a novel memory architecture designed to enhance how AI systems store and utilize information.
Drawing inspiration from the intricacies of human memory, this research aims to overcome the limitations of existing memory systems in AI models, particularly the constrained context window of Transformers.
The Titans architecture introduces a sophisticated approach to integrate different types of memory—short-term, long-term, and persistent—within AI models, enabling them to learn and memorize dynamically during test time.
The "surprise" mechanism is central to this, which draws from the human brain’s tendency to remember unexpected events. This architecture allows the models to efficiently manage memory by incorporating momentary and past surprises, ensuring effective data memorization and retrieval.
In this article, I’ll simplify the concepts and mechanisms introduced in the Titans paper and explore the potential impact this new architecture could have on the future of AI.
Transformers are the architecture used in most LLMs today. They are known for their ability to process sequences of data, like words in a sentence. They operate very effectively by using something called "attention", which helps them focus on relevant parts of the data. However, they face a key challenge: the size of their context window.
The context window is basically how much information a Transformer can consider at once. Think of it as a window running along a sentence, capturing a segment of words to understand their meaning in context.
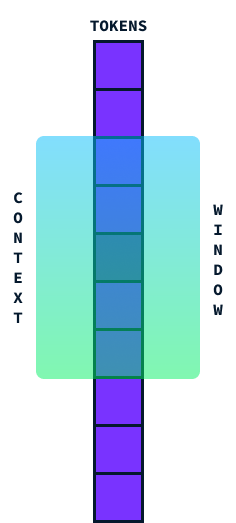
Ideally, we'd like this window to be as large as possible to process large sections of text at once, but there's a catch. As we try to make this context window larger, the amount of computation needed increases significantly due to the quadratic time and space complexity of the transformer architecture.
This means that if we double the size of the context window, the computation doesn't just double—it becomes four times more demanding! This happens because each word in the window needs to be compared with every other word, so the calculations grow rapidly.
Today's state-of-the-art (SOTA) models have 2 million token context windows. However, processing them is quite expensive, and some applications, such as video understanding, require larger context windows. Having a longer context window without a huge rise in computational cost would allow LLMs to handle longer sequences more effectively, improving their performance on tasks that require understanding larger chunks of data all at once. This is why overcoming the quadratic cost issue is a major focus in advancing these models.
Titans is a new architecture that enhances AI models' ability to store and retrieve information effectively, especially when dealing with large and complex data, by drawing inspiration from the intricacies of human memory.
Memory plays a crucial role in human learning and behavior. It helps us retain information from past experiences, which we use to make decisions, adapt to new situations, and solve problems. Human memory can be broadly categorized into three types:
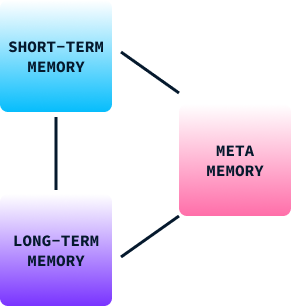
In human behavior, these memory types work together to allow us to learn from our environments, adapt strategies, and improve our behaviors over time. Without it, we would be restricted to basic reflexes and stereotyped behaviors.
Just like the human memory model, Titan's memory structure is composed of three parts:
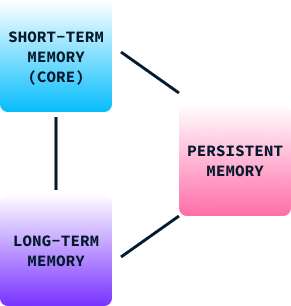
By integrating these three types of memory, the Titans architecture enables AI models to dynamically manage information much like our brains, blending immediate processing with the retention of past experiences and knowledge.
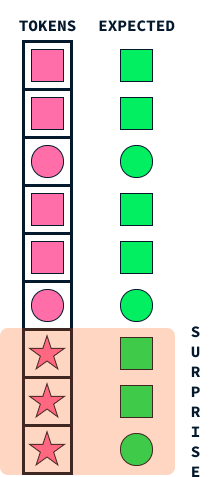
The "surprise" mechanism in Titans mimics a fundamental aspect of human memory: our tendency to remember surprising or unexpected events more vividly. This approach helps AI models decide what information to store by identifying data that stands out from what the model expects.
Imagine you're walking down the street, and everything seems ordinary and routine. You might not remember this everyday walk a few weeks later. However, if something unexpected happens, like a colorful parade passing by or receiving a phone call with exciting news, these surprising elements grab your attention, making them more memorable.
Similarly, Titans employ this idea of surprise to prioritize which information to memorize. When the model encounters data that differs significantly from what it anticipated (much like our colorful parade), it flags this information as surprising. The memory system in Titans then gives priority to storing these unexpected events, making sure that important but unusual data isn't overlooked.
This mechanism allows Titans to efficiently manage its memory resources by focusing on significant, outlier information instead of trying to retain every single detail. Just as humans are more likely to remember the unexpected, Titans apply this natural strategy to process and retain vital information effectively, enabling them to perform better on complex tasks that involve sorting through vast amounts of data.
Formally, the surprise concept is defined as the gradient of the loss function with respect to the input. This essentially measures how much the model’s parameters would need to change in response to the new input to minimize the loss.
The intuition behind using the gradient as a measure of surprise is that a large gradient implies significant changes are needed in the model to accommodate the new input, indicating that the input is quite different from what the model has seen before or that it is unexpected and, therefore, surprising.
The forgetting mechanism in the Titans architecture is a critical component designed to manage long-term neural memory effectively, ensuring that the model retains relevant information while discarding what is no longer needed.
This mechanism is vital when dealing with vast amounts of data, where memory could potentially become overwhelmed with outdated or irrelevant information. In practice, the forgetting mechanism operates by adjusting the memory update rule to selectively erase information based on its surprise factor and relevance, which is dynamically assessed during inference.
Specifically, an adaptive gating parameter determines how much of the previous memory state should be retained, allowing the model to clear or preserve memory content adaptively. Such a mechanism prevents memory overflow and promotes efficient memory space utilization, ultimately enhancing the model's ability to focus on critical and novel inputs without being bogged down by an accumulation of unnecessary data.
This approach closely mirrors human cognitive processes, in which unimportant or outdated memories fade over time, enabling more efficient cognitive processing and information retrieval.
In traditional machine learning models, learning occurs during the training phase. Once the model is trained, it is deployed to perform inference—making predictions based on new, unseen data—without further modification to its learned parameters.
The Titans architecture introduces a groundbreaking shift in this paradigm by enabling models to learn dynamically during inference, also known as test time. This capability allows Titans to update their memory and parameters based on the surprise and significance of incoming data while processing it.
The ability to learn at inference time provides several significant advantages:
The Titans architecture uses three distinct ways to incorporate memory, each inspired by different aspects of human cognition. Let's break down each memory mode using simple analogies.
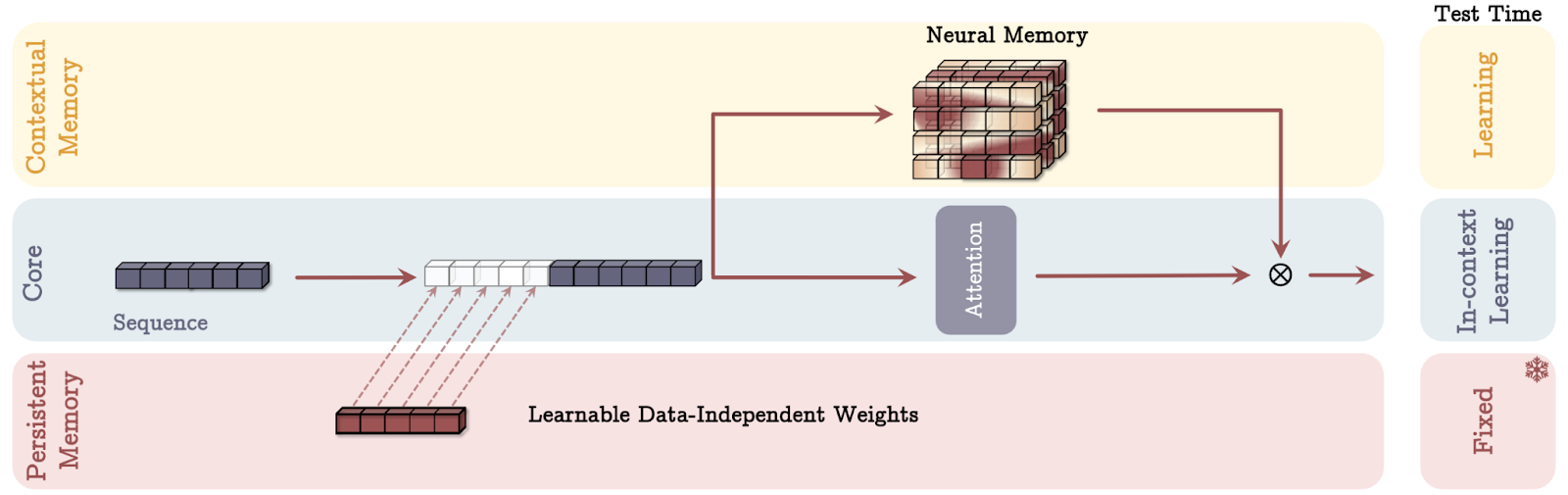
Source: Behrouz et. al, 2024
Imagine you have a personal assistant during a meeting. This assistant takes comprehensive notes of previous conversations (long-term memory) and whispers relevant pieces of information in your ear as needed (retrieval).
In the MAC mode, the AI model functions similarly. It retains a detailed history of past data and integrates it with current input to make informed decisions. Just like your assistant helps blend past knowledge with present discussions to enhance your decision-making, MAC uses long-term memory to provide context to the immediate information being processed.
Picture having two advisors in your mind. One focuses solely on what's happening now, providing insights on immediate tasks (short-term attention). The other draws from years of accumulated experience and wisdom (long-term memory).
The MAG mode acts like a gatekeeper that decides how much attention to give each advisor, dynamically adjusting focus based on present needs versus past learning. This ensures a balanced approach, allowing the AI to adapt whether the task at hand requires immediate precision or insights from past experiences.
Think of this mode as multiple layers of understanding, where each layer uniquely processes information:
This layered processing mirrors how we often digest complex information in stages, building and refining our understanding step by step. Each mode offers unique strengths, allowing Titans to effectively handle varying tasks by mimicking different aspects of how humans process and retain information.
The experimental results highlight the superiority of the Titans architecture over traditional Transformers and modern models in various tasks. Here's a breakdown of the key findings:
Overall, Titans leverage a novel memory management approach that allows them to handle complex, long-context tasks more effectively, setting a new standard for AI models in both scalability and accuracy.
The current Transformer architecture, while powerful, struggles with handling extremely long contexts due to scaling issues. Titans' innovative architecture, inspired by human memory, overcomes these limitations by dynamically managing short-term, long-term, and persistent memory.
I believe Titans' ability to learn at inference time, adapt to new data, and prioritize memory based on a "surprise" mechanism has the potential to create AI systems that are more human-like in their information processing. This could improve the performance of AI systems in complex and dynamic environments, which could be a game changer for AI agents like OpenAI’s Operator.
Learn AI with these courses!
Track
Course
Course
blog
Stanislav Karzhev
10 min
blog
Yesha Shastri
8 min
podcast
Tutorial
Josep Ferrer
Tutorial
Arjun Sarkar
code-along
Richie Cotton



