Data science has been hailed as the 'sexiest job of the 21st century', and this is not just a hyperbolic claim. The US Bureau of Labor Statistics predicts the number of data scientist roles to grow 36% between 2023 and 2033, a clear testament to the growing significance of this field.
But what exactly is data science, and why is it so important? This article will walk you through the world of data science. From the data science lifecycle, its applications across different industries, the skills needed to break into data science, and more. We’ll provide a deep look into why and how data science has risen to prominence as one of the most dynamic industries today.
What is Data Science?
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. In simpler terms, data science is about obtaining, processing, and analyzing data to gain insights for many purposes.
The data science lifecycle
The data science lifecycle refers to the various stages a data science project generally undergoes, from initial conception and data collection to communicating results and insights.
Despite every data science project being unique—depending on the problem, the industry it's applied in, and the data involved—most projects follow a similar lifecycle.
This lifecycle provides a structured approach for handling complex data, drawing accurate conclusions, and making data-driven decisions.
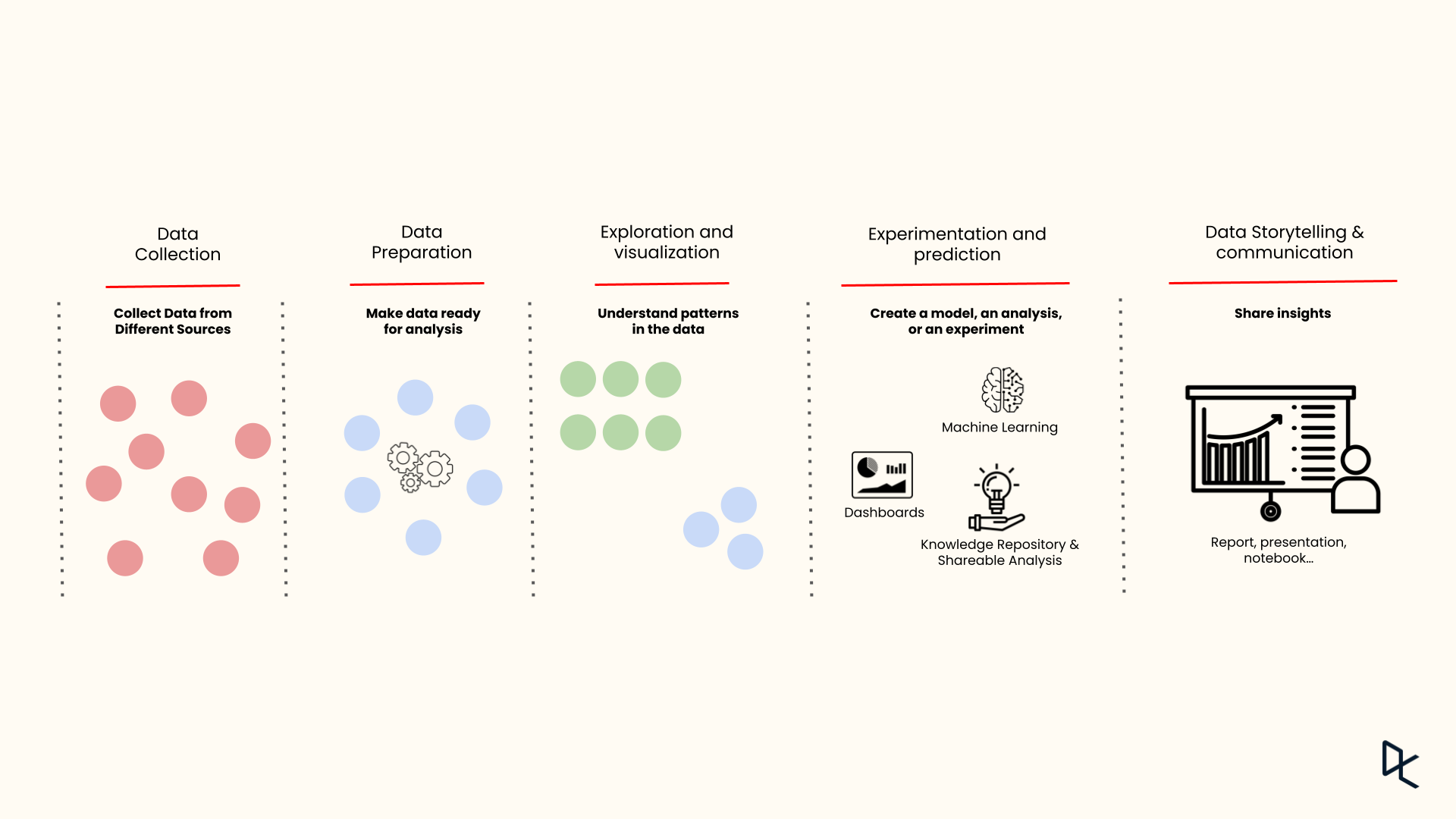
The data science lifecycle
Here are the five main phases that structure the data science lifecycle:
Data collection and storage
This initial phase involves collecting data from various sources, such as databases, Excel files, text files, APIs, web scraping, or even real-time data streams. The type and volume of data collected largely depend on the problem you’re addressing.
Once collected, this data is stored in an appropriate format ready for further processing. Storing the data securely and efficiently is important to allow quick retrieval and processing.
Data preparation
Often considered the most time-consuming phase, data preparation involves cleaning and transforming raw data into a suitable format for analysis. This phase includes handling missing or inconsistent data, removing duplicates, normalization, and data type conversions. The objective is to create a clean, high-quality dataset that can yield accurate and reliable analytical results.
Exploration and visualization
During this phase, data scientists explore the prepared data to understand its patterns, characteristics, and potential anomalies. Techniques like statistical analysis and data visualization summarize the data's main characteristics, often with visual methods.
Visualization tools, such as charts and graphs, make the data more understandable, enabling stakeholders to comprehend the data trends and patterns better.
Experimentation and prediction
Data scientists use machine learning algorithms and statistical models to identify patterns, make predictions, or discover insights in this phase. The goal here is to derive something significant from the data that aligns with the project's objectives, whether predicting future outcomes, classifying data, or uncovering hidden patterns.
Data Storytelling and communication
The final phase involves interpreting and communicating the results derived from the data analysis. It's not enough to have insights; you must communicate them effectively, using clear, concise language and compelling visuals. The goal is to convey these findings to non-technical stakeholders in a way that influences decision-making or drives strategic initiatives.
Understanding and implementing this lifecycle allows for a more systematic and successful approach to data science projects. Let's now delve into why data science is so important.
Why is Data Science Important?
Data science has emerged as a revolutionary field that is crucial in generating insights from data and transforming businesses. It's not an overstatement to say that data science is the backbone of modern industries. But why has it gained so much significance?
- Data volume. Firstly, the rise of digital technologies has led to an explosion of data. Every online transaction, social media interaction, and digital process generates data. However, this data is valuable only if we can extract meaningful insights from it. And that's precisely where data science comes in.
- Value-creation. Secondly, data science is not just about analyzing data; it's about interpreting and using this data to make informed business decisions, predict future trends, understand customer behavior, and drive operational efficiency. This ability to drive decision-making based on data is what makes data science so essential to organizations.
- Career options. Lastly, the field of data science offers lucrative career opportunities. With the increasing demand for professionals who can work with data, jobs in data science are among the highest paying in the industry. As per Glassdoor, the average salary for a data scientist in the United States is $116,000 base pay, making it a rewarding career choice.
What is Data Science Used For?
Data science is used for an array of applications, from predicting customer behavior to optimizing business processes. The scope of data science is vast and encompasses various types of analytics.
- Descriptive analytics. Analyzes past data to understand current state and trend identification. For instance, a retail store might use it to analyze last quarter's sales or identify best-selling products.
- Diagnostic analytics. Explores data to understand why certain events occurred, identifying patterns and anomalies. If a company's sales fall, it would identify whether poor product quality, increased competition, or other factors caused it.
- Predictive analytics. Uses statistical models to forecast future outcomes based on past data, used widely in finance, healthcare, and marketing. A credit card company may employ it to predict customer default risks.
- Prescriptive analytics. Suggests actions based on results from other types of analytics to mitigate future problems or leverage promising trends. For example, a navigation app advising the fastest route based on current traffic conditions.
The increasing sophistication from descriptive to diagnostic to predictive to prescriptive analytics can provide companies with valuable insights to guide decision-making and strategic planning. You can read more about the four types of analytics in a separate article.
What are the Benefits of Data Science?
Data science can add value to any business that uses its data. From statistics to predictions, effective data-driven practices can put a company on the fast track to success. Here are some ways in which data science is used:
Optimize business processes
Data Science can significantly improve a company's operations in various departments, from logistics and supply chain to human resources and beyond. It can help in resource allocation, performance evaluation, and process automation. For example, a logistics company can use data science to optimize routes, reduce delivery times, save fuel costs, and improve customer satisfaction.
Unearth new insights
Data Science can uncover hidden patterns and insights that might not be evident at first glance. These insights can provide companies with a competitive edge and help them understand their business better. For instance, a company can use customer data to identify trends and preferences, enabling them to tailor their products or services accordingly.
Create innovative products and solutions
Companies can use data science to innovate and create new products or services based on customer needs and preferences. It also allows businesses to predict market trends and stay ahead of the competition. For example, streaming services like Netflix use data science to understand viewer preferences and create personalized recommendations, enhancing user experience.
Which Industries Use Data Science?
The implications of data science span across all industries, fundamentally changing how organizations operate and make decisions. While every industry stands to gain from implementing data science, it's especially influential in data-rich sectors.
Let's delve deeper into how data science is revolutionizing these key industries:
Data science applications in finance
The finance sector has been quick to harness the power of data science. From fraud detection and algorithmic trading to portfolio management and risk assessment, data science has made complex financial operations more efficient and precise. For instance, credit card companies utilize data science techniques to detect and prevent fraudulent transactions, saving billions of dollars annually.
Learn more about the finance fundamentals in Python and how you can make data-driven financial decisions with our skill track.
Data science applications in healthcare
Healthcare is another industry where data science has a profound impact. Applications range from predicting disease outbreaks and improving patient care quality to enhancing hospital management and drug discovery. Predictive models help doctors diagnose diseases early, and treatment plans can be customized according to the patient's specific needs, leading to improved patient outcomes.
You can discover more about how data science is transforming healthcare in a DataFramed Podcast episode.
Data science applications in marketing
Marketing is a field that has been significantly transformed by the advent of data science. The applications in this industry are diverse, ranging from customer segmentation and targeted advertising to sales forecasting and sentiment analysis. Data science allows marketers to understand consumer behavior in unprecedented detail, enabling them to create more effective campaigns. Predictive analytics can also help businesses identify potential market trends, giving them a competitive edge. Personalization algorithms can tailor product recommendations to individual customers, thereby increasing sales and customer satisfaction.
We have a separate blog post on five ways to use data science in marketing, exploring some of the methods used in the industry. You can also learn more in our Marketing Analytics with Python skill track.
Data science applications in technology
Technology companies are perhaps the most significant beneficiaries of data science. From powering recommendation engines to enhancing image and speech recognition, data science finds applications in diverse areas. Ride-hailing platforms, for example, rely on data science for connecting drivers with ride hailers and optimizing the supply of drivers depending on the time of day.
How is Data Science Different from Other Data-Related Fields?
While data science overlaps with many fields that also work with data, it carries a unique blend of principles, tools, and techniques designed to extract insightful patterns from data.
Distinguishing between data science and these related fields can give a better understanding of the landscape and help in setting the right career path. Let's demystify these differences.
Data science vs data analytics
Data science and data analytics both serve crucial roles in extracting value from data, but their focuses differ. Data science is an overarching field that uses methods including machine learning and predictive analytics, to draw insights from data. In contrast, data analytics concentrates on processing and performing statistical analysis on existing datasets to answer specific questions.
Data science vs business analytics
While business analytics also deals with data analysis, it is more centered on leveraging data for strategic business decisions. It is generally less technical and more business-focused than data science. Data science, though it can inform business strategies, often dives deeper into the technical aspects, like programming and machine learning.
Data science vs data engineering
Data engineering focuses on building and maintaining the infrastructure for data collection, storage, and processing, ensuring data is clean and accessible. Data science, on the other hand, analyzes this data, using statistical and machine learning models to extract valuable insights that influence business decisions. In essence, data engineers create the data 'roads', while data scientists 'drive' on them to derive meaningful insights. Both roles are vital in a data-driven organization.
Data science vs machine learning
Machine learning is a subset of data science, concentrating on creating and implementing algorithms that let machines learn from and make decisions based on data. Data science, however, is broader and incorporates many techniques, including machine learning, to extract meaningful information from data.
Data Science vs Statistics
Statistics, a mathematical discipline dealing with data collection, analysis, interpretation, and organization, is a key component of data science. However, data science integrates statistics with other methods to extract insights from data, making it a more multidisciplinary field.
|
Industry |
Focus |
Technical Emphasis |
|
Data Science |
Driving value with data across the 4 levels of analytics |
Programming, ML, Statistics |
|
Data Analytics |
Perform statistical analysis on existing datasets |
Statistical analysis |
|
Business Analytics |
Leverage data for strategic business decisions |
Business strategies, data analysis |
|
Data Engineering |
Build and maintain data infrastructure |
Data collection, storage, processing |
|
Machine Learning |
Creating and implementing algorithms for machine learning |
Algorithm development, model implementation |
|
Statistics |
Data collection, analysis, interpretation, and organization |
Statistical analysis, mathematical principles |
Having understood these distinctions, we can now delve into the key concepts every data scientist needs to master.
Key Data Science Concepts
A successful data scientist doesn't just need technical skills but also an understanding of core concepts that form the foundation of the field. Here are some key concepts to grasp:
Statistics and probability
These are the bedrock of data science. Statistics is used to derive meaningful insights from data, while probability allows us to make predictions about future events based on available data. Understanding distributions, statistical tests, and probability theories is essential for any data scientist.
Resources to get you started
- Introduction to Statistics Course
- Statistics Fundamentals with Python Skill Track
- Descriptive Statistics Cheat Sheet
Programming
Programming is the tool that allows data scientists to work with data. Languages like Python and R are particularly popular due to their ease of use and powerful data handling libraries. Familiarity with these languages allows a data scientist to clean, process, and analyze data effectively.
Resources to get you started
- Python Programming Skill Track
- Python Programmer Career Track
- R Programming Skill Track
- R Programmer Career Track
- How to Become a Programmer in 2023: A Step-By-Step Guide
Data visualization
Data visualization is the art of representing complex data in a visual and easily comprehensible format. It helps to communicate findings and makes it easier to understand complex data sets. Tools like Tableau, Matplotlib, and Seaborn are commonly used in this field.
Resources to get you started
- Understanding Data Visualization Course
- Data Visualization with Python Skill Track
- Data Visualization with R Skill Track
- Data Visualization Cheat Sheet
Machine learning
Machine Learning, a subset of artificial intelligence, involves training a model on data to make predictions or decisions without being explicitly programmed. It is at the heart of many modern data science applications, from recommendation systems to predictive analytics.
Resources to get you started
- Understanding Machine Learning Course
- Machine Learning Fundamentals with Python Skill Track
- Machine Learning Scientist with Python Career Track
- What is Machine Learning?
Data engineering
Data engineering is concerned with the design and construction of systems for collecting, storing, and processing data. It forms the basis on which data analysis and machine learning models are built.
Resources to get you started
- Data Engineering for Everyone Course
- Introduction to Data Engineering Course
- What is Data Engineering?
- How to Become a Data Engineer in 2023: 5 Steps for Career Success
- Building Data Engineering Pipelines in Python Course
Key Data Science Tools
Data scientists need a set of tools to carry out their tasks effectively. These tools can range from programming languages to software for data visualization. Here are some essential data science tools.
Programming languages
In the realm of data science, programming languages are the tools of the trade. They provide a framework for instructing a computer to perform specific tasks, such as data manipulation, statistical analysis, and machine learning. Here are some key languages that every data scientist should consider mastering:
- Python. Known for its simplicity and powerful libraries like pandas and NumPy.
- R. Great for statistical analysis and visualization.
- Julia. Recognized for its high performance and speed, ideal for numerical and scientific computing.
Resources to get you started
- Python Fundamentals Skill Track
- Introduction to R Programming Course
- Introduction to Julia Course
- Python vs R for Data Science: Which Should You Learn?
- Python Cheat Sheet for Beginners
Business intelligence tools
Business Intelligence (BI) tools are software applications used to analyze an organization's raw data. They aid in the visualization, reporting, and sharing of data insights, allowing companies to make data-driven decisions. Here are some essential BI tools for data science:
- Tableau. For creating interactive data visualization.
- Power BI. Microsoft's suite of business analytics tools.
- QlikView. Combines ETL, data storage, and visualization.
Resources to get you started
- Tableau Fundamentals Skill Track
- Introduction to Power BI Course
- Power BI vs Tableau: Which Should You Choose in 2023?
- Power BI Cheat Sheet
- Tableau Cheat Sheet
Machine learning libraries
Machine learning libraries are a collection of pre-written code that data scientists can use to save time. They provide pre-packaged algorithms and learning routines that can be integrated into programs. Here are some key libraries that streamline machine learning tasks:
- Scikit-learn. Offers various algorithms for classification, regression, clustering, etc.
- TensorFlow. Developed by Google for building neural networks.
- PyTorch. Known for its dynamic computation graph.
aResources to get you started
- Machine Learning Fundamentals with Python
- What is Machine Learning? Blog Post
- Introduction to Machine Learning in Python Tutorial
- Machine Learning with scikit-learn Course
- Introduction to TensorFlow in Python Course
Database management systems
Database Management Systems (DBMS) are software applications that interact with the user, other applications, and the database to capture and analyze data. A DBMS allows for a systematic way to create, retrieve, update, and manage data. Here are some popular DBMS used in data science:
- MySQL. An open-source relational database system.
- PostgreSQL. Offers advanced features such as Multi-Version Concurrency Control.
- MongoDB. A popular NoSQL database.
Resources to get you started
- Database Design Course
- Introduction to SQL Course
- SQL Database Overview Tutorial
- Beginner's Guide to PostgreSQL
Top Data Science Jobs
Data Science is a vast field with many specialized roles, each carrying its unique responsibilities, skill requirements, and salary expectations. Here are some of the most sought-after job titles in the realm of data science:
Data analyst
Data analysts play a crucial role in interpreting an organization's data. They possess expertise in mathematical and statistical analysis, enabling them to transform complex datasets into actionable insights that drive business decisions. Employing data visualization tools, they effectively communicate their findings to both technical and non-technical stakeholders.
Data analysts dive into data, providing reports and visualizations to reveal hidden insights. While not necessarily involved in developing advanced algorithms, they utilize a range of tools to make sense of data. Their responsibilities may also encompass SQL queries, data cleaning, and data management. Read more about how to become a data analyst in a separate article.
Key skills:
- Proficiency in SQL, Python, or R
- Strong understanding of statistical analysis
- Ability to create compelling data visualizations and reports
- Proficient in data cleaning and management
- Effective communication skills
Essential tools:
- SQL for database querying
- Programming languages such as Python or R for data manipulation
- Data visualization tools like Tableau or PowerBI
- Spreadsheet tools like MS Excel or Google Sheets
- Statistical software like SPSS or SAS
Data scientist
Data scientists delve into an organization's data to extract and communicate meaningful insights. They possess a deep understanding of machine learning workflows and how to apply them to real-world business applications. Data Scientists predominantly work with coding tools, conducting thorough analysis and frequently engaging with big data tools.
Data scientists are akin to detectives within the data realm. They are responsible for unearthing and interpreting rich data sources, managing large datasets, and identifying trends by merging data points. Leveraging analytical, statistical, and programming skills, they collect, analyze, and interpret extensive datasets. These insights drive the development of data-driven solutions to complex business problems, often involving the creation of machine learning algorithms to generate new insights, automate processes, or deliver enhanced value to customers.
We have a full guide on how to become a data scientist, which outlines some of the key steps you need to take to get started in this role.
Key skills:
- Strong command of Python, R, and SQL
- Understanding of Machine Learning and AI concepts
- Proficiency in statistical analysis, quantitative analytics, and predictive modeling
- Ability to visualize and report data effectively
- Excellent communication and presentation skills
Essential tools:
- Data analysis tools like Pandas and NumPy
- Machine learning libraries such as Scikit-learn
- Data visualization tools like Matplotlib and Tableau
- Big data frameworks like Airflow and Spark
- Command line tools like Git and Bash
Data engineer
Data engineers are the architects of the data science realm. They design, construct, and manage data infrastructure, enabling Data Scientists to analyze data efficiently. Data Engineers focus on data collection, storage, and processing, establishing data pipelines that streamline the analytical process.
Data engineers often tackle algorithm design for information extraction and create database systems. They ensure optimal performance by managing data architecture, databases, and processing systems. This role requires a comprehensive understanding of programming languages and experience with relational and non-relational databases. Read more about becoming a data engineer in a separate post.
Key Skills:
- Expertise in SQL and database design
- Proficiency in programming languages such as Python or Java
- Knowledge of big data technologies like Hadoop or Spark
- Familiarity with data modeling and data warehousing principles
- Strong problem-solving and communication skills
Tools:
- SQL for database management
- Programming languages for building data pipelines (e.g., Python, Java)
- Big data platforms like Hadoop and Spark
- ETL (Extract, Transform, Load) tools such as Informatica or Talend
- NoSQL databases like MongoDB or Cassandra
Machine learning engineer
Machine Learning Engineers are the architects of the AI world. They design and implement machine learning systems that leverage organizational data to make predictions. Their responsibilities also include addressing challenges like customer churn prediction and lifetime value estimation, and deploying models for organizational use. Machine Learning Engineers primarily work with coding-based tools.
Check out our full guide on how to become a machine learning engineer in a separate article.
Key Skills:
- Deep understanding of Python, Java, and Scala
- Familiarity with machine learning frameworks like Scikit-learn, Keras, or PyTorch
- Understanding of data structures, data modeling, and software architecture
- Advanced mathematical skills encompassing linear algebra, calculus, and statistics
- Strong teamwork and exceptional problem-solving abilities
Tools:
- Machine learning libraries and algorithms (e.g., Scikit-learn, TensorFlow)
- Data science libraries like Pandas and NumPy
- Cloud platforms such as AWS or Google Cloud Platform
- Version control systems like Git
AI research scientist
AI Research Scientists focus on advancing artificial intelligence by creating and improving algorithms and models. They tackle complex challenges like teaching computers to understand language, recognize images, or learn from experience. Their work often bridges academic research and practical applications, driving innovations in AI.
For example, they might develop smarter chatbots, improve self-driving car systems, or design AI models for healthcare. This role requires both technical expertise and creative problem-solving.
Key Skills:
- Strong knowledge of machine learning and AI techniques
- Experience with neural networks, natural language processing, or computer vision
- Proficiency in Python and tools like TensorFlow or PyTorch
- Solid math skills in areas like linear algebra and probability
- Ability to turn theoretical ideas into real-world solutions
Essential Tools:
- Deep learning frameworks (e.g., TensorFlow, PyTorch)
- Cloud platforms like AWS or Google Cloud
- Version control tools like Git
- Research tools like Jupyter Notebooks
- High-performance hardware like GPUs
AI Research Scientists play a key role in shaping the future of AI, creating technologies that power smarter applications, enhance automation, and solve real-world problems.
|
Role |
Responsibilities |
Key Skills |
Essential Tools |
|
Data Analyst |
Extract and report insights from data for business problem-solving |
SQL, Python, or R |
SQL, Python or R, Data visualization tools (e.g., Tableau, PowerBI), Statistical software (e.g., SPSS, SAS), Spreadsheet tools |
|
Data Scientist |
Unearth meaningful insights, develop data-driven solutions using machine learning, communicate findings |
Python, R, SQL, Machine Learning and AI concepts, Statistical analysis, Data visualization, Communication and presentation skills |
Pandas, NumPy, Scikit-learn, Matplotlib, Tableau, Airflow, Spark, Git, Bash |
|
Data Engineer |
Design, build, and manage data infrastructure, create data pipelines, ensure optimal performance |
SQL, Python, Java, Database design, Big data technologies, Data modeling, Problem-solving, Communication skills |
SQL, Python, Java, Hadoop, Spark, ETL tools, NoSQL databases |
|
Machine Learning Engineer |
Design and deploy machine learning systems, solve complex problems using ML, collaborate with teams |
Python, Java, Scala, Machine learning frameworks, Data structures, Software architecture, Mathematics, Teamwork, Problem-solving skills |
Scikit-learn, TensorFlow, Pandas, NumPy, Cloud platforms (e.g., AWS, Google Cloud Platform), Version control systems (e.g., Git) |
|
AI Research Scientist |
Develop advanced AI models, improve algorithms, and solve complex problems like NLP or computer vision |
Machine learning, neural networks, natural language processing, computer vision, Python, TensorFlow, PyTorch, math skills |
TensorFlow, PyTorch, Jupyter Notebooks, cloud platforms (e.g., AWS, Google Cloud), GPUs for high-performance computing |
How to Get Started with Data Science
Data science is an interdisciplinary field, and to get started, you'll need to acquire a mix of skills from mathematics, statistics, computer science, and domain-specific knowledge. Let's look at a possible roadmap to kickstart your journey in data science.
Data science is a fascinating field; it's where curiosity meets technology. The first step may seem intimidating, but remember, it's not about knowing all the algorithms, but asking the right questions and learning to decipher meaningful insights from the data. Just dive in, start exploring, and the rest will follow.
Richie Cotton, Data Evangelist at DataCamp
What is the difference between data science, data analysis, and machine learning?
Is data science hard?
Is data science a good career?
Why study data science?
Why is data science a growing career field?
How can I prepare for a data scientist job interview?
How can I prove my data analysis skills to employers?


Topics

