Kurs
Einführung in LLMs mit Python
3 Std.
33.6K
Im Bereich der Künstlichen Intelligenz (KI) werden die Fähigkeiten von Large Language Models (LLMs) explosionsartig erweitert, die zunehmend Aufgaben bewältigen, die ein anspruchsvolles Verständnis und die Generierung menschlicher Sprache erfordern. Da diese Modelle immer leistungsfähiger werden, werden robuste Bewertungsmethoden benötigt.
An dieser Stelle kommt der MMLU-Benchmark (Massive Multitask Language Understanding) ins Spiel. Es ist ein umfassender und anspruchsvoller Test für die modernsten KI-Systeme von heute. Die MMLU-Punktzahl ist zu einem wichtigen Indikator für den Fortschritt eines Modells geworden und eine treibende Kraft in dem ständigen Bestreben, intelligentere Maschinen zu bauen.
Die Bedeutung der MMLU und ihre Rolle zu verstehen, ist für alle wichtig, die sich mit Data Science oder KI beschäftigen, denn sie bietet eine standardisierte Möglichkeit, das allgemeine Wissen und die Denkfähigkeiten dieser Modelle in einer Vielzahl von Themen zu messen. Diese Fähigkeiten sind für die Entwicklung großer Sprachmodelle von zentraler Bedeutung.
In diesem Artikel werden wir uns ansehen, was die MMLU ist, was der MMLU-Evaluierungsprozess beinhaltet, wie der umfangreiche MMLU-Datensatz aufgebaut ist und warum dieser Benchmark so wichtig für die Weiterentwicklung der KI ist.
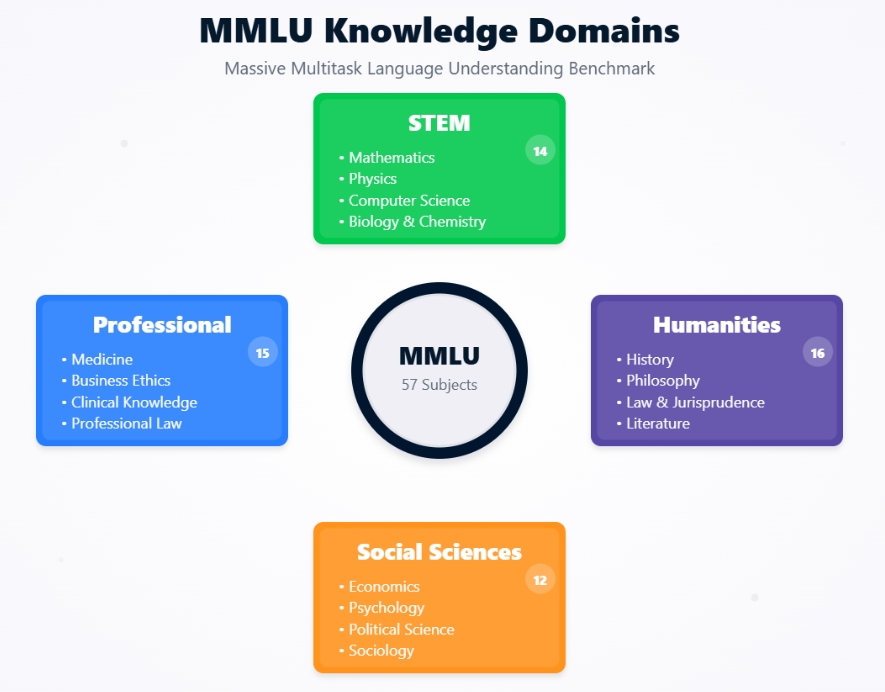
Massive Multitask Language Understanding (MMLU) ist ein umfassender Benchmark, der entwickelt wurde, um das Wissen und die Problemlösungsfähigkeiten von großen Sprachmodellen (LLMs) in einer großen und vielfältigen Bandbreite von Themen zu bewerten. Er besteht aus Multiple-Choice-Fragen, die 57 verschiedene Aufgaben umfassen, darunter elementare Mathematik, US-Geschichte, Informatik, Recht und mehr.
Die Kernidee hinter dem MMLU-Benchmark ist es, das erworbene Wissen und die Argumentationsfähigkeit eines Modells in einer Zero-Shot- oder Little-Shot-Situation zu testen, d.h. das Modell muss Fragen mit wenigen oder gar keinen aufgabenspezifischen Beispielen beantworten.
Dieser Ansatz zielt darauf ab, zu messen, wie gut die Modelle das Wissen aus ihrer Vor-Trainings-Phase verstehen und auf Aufgaben anwenden können, für die sie nicht explizit abgestimmt wurden. Dies spiegelt eine allgemeinere und robustere Form der Intelligenz wider. Die Leistung eines Modells wird in der Regel durch seine MMLU-Punktzahl zusammengefasst, die seine Genauigkeit in diesen verschiedenen Bereichen angibt.
Der MMLU-Bewertungsrahmen ist für die KI-Forschung und -Entwicklung aus mehreren wichtigen Gründen von großer Bedeutung, z. B:
MMLU Wissensdomänen
Die Entstehung der MMLU lässt sich am besten verstehen, wenn man sich die Entwicklung der Sprachmodellbewertung und die Beweggründe für ihre Entstehung ansieht.
MMLU wurde von Dan Hendrycks und einem Team von Forschern in ihrem Papier "Measuring Massive Multitask Language Understanding" aus dem Jahr 2020 vorgestellt. Die Hauptmotivation war die Beobachtung, dass die bestehenden Benchmarks durch die sich schnell verbessernden LLMs gesättigt wurden.
Die Modelle erreichten bei Benchmarks wie GLUE und SuperGLUE fast menschliche oder sogar übermenschliche Leistungen, aber es war nicht immer klar, ob dies auch zu einem umfassenden, menschenähnlichen Verständnis der Welt führte.
Die Entwickler von MMLU wollten einen anspruchsvolleren und umfassenderen Test entwickeln, der es ermöglicht:
Ziel war es, eine Bewertung zu erstellen, mit der die Fähigkeiten von immer leistungsfähigeren LLMs besser unterschieden werden können und die einen klareren Weg zu allgemein intelligenteren Systemen aufzeigt.
MMLU ist ein wichtiger Schritt in der Entwicklung von Benchmarks für das Verstehen natürlicher Sprache (NLU).
Frühe NLU-Evaluierungen konzentrierten sich oft auf einzelne Aufgaben wie Sentiment-Analyse, Named-Entity-Recognition oder maschinelle Übersetzung, jeweils mit eigenem Datensatz und eigenen Metriken.
Die 2018 eingeführte GLUE (General Language Understanding Evaluation) war eine Sammlung von neun verschiedenen NLU-Aufgaben, die eine einheitliche Kennzahl für die Gesamtleistung des Modells liefern sollten. Er wurde eine Zeit lang zum Standard, wurde aber bald von anderen Modellen überholt.
SuperGLUE wurde 2019 als anspruchsvollerer Nachfolger von GLUE entwickelt und enthielt schwierigere Aufgaben und eine umfassendere menschliche Basis. Aber auch bei SuperGLUE kamen die Modelle schnell an die menschliche Leistung heran.
Das MMLU hat diese früheren Benchmarks in mehreren entscheidenden Punkten verbessert. Mit 57 Aufgaben ist der MMLU-Datensatz viel umfangreicher und deckt ein viel breiteres Spektrum an schulischen und beruflichen Themen ab als GLUE (9 Aufgaben) oder SuperGLUE (8 Aufgaben + ein Diagnosedatensatz). Diese Breite macht es den Modellen schwerer, sich zu spezialisieren und fördert ein allgemeines Wissen.
Während GLUE/SuperGLUE verschiedene sprachliche Phänomene getestet hat, bewertet MMLU direkt das Wissen in bestimmten Bereichen wie Recht, Medizin und Ethik, die mehr als nur Sprachverarbeitung erfordern.
MMLU priorisiert die Bewertung von Modellen mit minimalen aufgabenspezifischen Beispielen. Dies steht im Gegensatz zu vielen Aufgaben in GLUE/SuperGLUE, bei denen die Modelle oft anhand aufgabenspezifischer Trainingssätze feinabgestimmt wurden. Dadurch ist die MMLU-Bewertung ein besserer Test für die Generalisierungsfähigkeit eines Modells gegenüber dem Vortraining.
Die Fragen in MMLU sind oft so gestaltet, dass sie selbst für Menschen anspruchsvoll sind, besonders in speziellen Bereichen, so dass der Fortschritt der KI auf einer längeren Strecke gemessen werden kann.
Durch die Berücksichtigung dieser Aspekte hat das MMLU einen neuen, anspruchsvolleren Standard dafür geschaffen, was es für einen LLM bedeutet, Sprache und die Welt zu "verstehen".
Um den MMLU-Benchmark richtig einschätzen zu können, ist es wichtig zu verstehen, wie er aufgebaut ist und wie er die Sprachmodelle bewertet. Werfen wir einen Blick auf die Zusammensetzung des MMLU-Datensatzes, die Breite der Themen, die er abdeckt, und die spezifischen Bewertungsmethoden, die ihn zu einem robusten Test der KI-Fähigkeiten machen.
Die Stärke der MMLU-Bewertung liegt in ihrem sorgfältig kuratierten Datensatz, der sowohl breit als auch tief angelegt ist.
Der MMLU-Datensatz ist kein monolithisches Gebilde, sondern eine Sammlung von 57 verschiedenen Aufgaben, die jeweils einem bestimmten Themenbereich entsprechen. Diese Themen sind absichtlich vielfältig und umfassen mehrere große Kategorien:
Jede Aufgabe im MMLU-Datensatz besteht aus Multiple-Choice-Fragen. In der Regel stellt jede Frage ein Problem oder eine Frage dar, gefolgt von vier möglichen Antworten, von denen eine richtig ist. Die Fragen sind so gestaltet, dass sie das Wissen auf verschiedenen Schwierigkeitsstufen testen, von der High School über das College bis hin zu professionellen Experten.
Eine Frage im Fach "Professionelle Medizin" würde zum Beispiel ein Wissensniveau erfordern, das von einem Mediziner erwartet wird, was die Prüfung selbst für sehr fähige LLMs zu einer Herausforderung macht.
Die schiere Menge und die Vielfalt der Fragen sorgen dafür, dass sich die Modelle nicht einfach darauf verlassen können, die Antworten auswendig zu lernen, sondern ein echtes Verständnis des Themas haben müssen, um eine hohe MMLU-Punktzahl zu erreichen.
Die Fragen im MMLU-Datensatz stammen aus einer Vielzahl von realen Materialien, um ihre Relevanz und Schwierigkeit sicherzustellen. Zu diesen Quellen gehören:
Diese Beschaffungsstrategie stellt sicher, dass die Fragen die Art von Wissens- und Argumentationsproblemen widerspiegeln, die in akademischen und beruflichen Kontexten auftreten.
Das Ziel ist es, die Fähigkeit eines Modells zu bewerten, Wissen in ähnlichen Kontexten zu verstehen und anzuwenden, wie sie gebildete Menschen haben.
Ein entscheidender Aspekt der Bedeutung des MMLU und seiner Bewertungskraft liegt in der Verwendung von Zero-Shot- und Little-Shot-Lernparadigmen. Diese Methoden sind wichtig, um die Fähigkeit eines Modells zu testen, sein Wissen ohne umfangreiches aufgabenspezifisches Training zu verallgemeinern.
In einer Zero-Shot-Situation werden dem LLM Fragen aus einer bestimmten MMLU-Aufgabe (z. B. "Abstrakte Algebra" oder "Moralische Szenarien") vorgelegt, ohne dass er zuvor irgendwelche Beispiele aus dieser Aufgabe in der Feinabstimmungsphase oder in der Aufforderung selbst gesehen zu haben.
Das Modell muss die Frage verstehen und die richtige Multiple-Choice-Antwort allein auf der Grundlage seines vortrainierten Wissens auswählen.
Die Aufforderung könnte zum Beispiel einfach lauten:
Im Folgenden findest du Multiple-Choice-Fragen (mit Antworten) zu [Name des Fachs].
[Frage]
A) [Option A]
B) [Option B]
C) [Option C]
D) [Option D]
Antwort:
Das Modell soll dann den Buchstaben der richtigen Option angeben. Auf diese Weise wird die Fähigkeit des Modells, sein Verständnis auf völlig neue Bereiche und Fragestile zu verallgemeinern, gründlich getestet.
In einer "few-shot"-Einstellung wird dem Modell eine kleine Anzahl von Beispielen (normalerweise fünf, daher "5-shot") aus der spezifischen MMLU-Aufgabe direkt in der Eingabeaufforderung vorgelegt bevor bevor es auf die eigentliche Testfrage trifft.
Diese Beispiele bestehen aus einer Frage, den Multiple-Choice-Optionen und der richtigen Antwort.
Zum Beispiel:
Im Folgenden findest du Multiple-Choice-Fragen (mit Antworten) zu moralischen Streitigkeiten.
Frage: John Doe ist ein Software-Ingenieur, der für ein Unternehmen arbeitet, das autonome Waffen entwickelt. Er hat ernsthafte ethische Bedenken wegen des möglichen Missbrauchs dieser Technologie, der zu zivilen Opfern führen könnte. Aber er hat auch eine Familie zu versorgen und fürchtet, seinen Job zu verlieren, wenn er sich äußert. Was ist der wichtigste ethische Konflikt, mit dem John konfrontiert ist?
A) Interessenkonflikt
B) Das Dilemma des Whistleblowers
C) Berufliche Fahrlässigkeit
D) Rechte an geistigem Eigentum
Antwort: B
[... 4 weitere Beispiele ...]
Frage: [Tatsächliche Testfrage]
A) [Option A]
B) [Option B]
C) [Option C]
D) [Option D]
Antwort:
Das Modell nutzt diese wenigen Beispiele, um den Kontext, den Stil und die erwartete Argumentation für die Aufgabe zu verstehen, bevor es die neue, ungesehene Frage ausprobiert. Dadurch wird die Fähigkeit des Modells zum schnellen, kontextbezogenen Lernen und zur Anpassung getestet.
Die Bedeutung dieser Methoden für die MMLU-Bewertung liegt darin, dass sie widerspiegeln, wie Menschen oft an neue Probleme herangehen, indem sie entweder vorhandenes Wissen auf etwas völlig Neues anwenden (zero-shot) oder schnell aus wenigen Beispielen lernen (few-shot).
Diese Bewertungseinstellungen simulieren gängige Sprachverarbeitungsaufgaben aus der Praxis.
Zero-Shot-Szenarien sind vergleichbar mit einem Nutzer, der einer KI eine Frage zu einem Thema stellt, zu dem die KI vorher noch nicht gefragt wurde. Ein Nutzer kann einem KI-Assistenten zum Beispiel eine komplexe Rechtsfrage oder eine philosophische Frage stellen. Die Fähigkeit der KI, eine sinnvolle Antwort zu geben, beruht auf ihrem umfassenden, vortrainierten Wissen.
Few-Shot-Szenarien spiegeln Situationen wider, in denen ein Nutzer Kontext oder Beispiele liefert, um die KI zu leiten. Ein Nutzer könnte der KI zum Beispiel einige Beispiele für die Zusammenfassung von medizinischen Berichten zeigen, bevor er sie bittet, einen neuen Bericht zusammenzufassen, oder Beispiele für einen bestimmten poetischen Stil geben, bevor er die KI bittet, ein Gedicht in diesem Stil zu erstellen.
Indem die MMLU Modelle sowohl in Null- als auch in Wenig-Schuss-Situationen bewertet, vermittelt sie ein umfassenderes Bild ihrer Flexibilität und Lernfähigkeit, die für den Aufbau wirklich nützlicher und anpassungsfähiger KI-Systeme wichtig sind.
Die Fähigkeit, unter diesen Bedingungen gute Leistungen zu erbringen, ist ein starker Indikator für das Potenzial eines Modells, in der Praxis für eine Vielzahl von Aufgaben eingesetzt zu werden, ohne dass für jedes neue Problem ein umfangreiches, kostspieliges Neutraining erforderlich ist.
Die Entwicklung der Sprachmodelle im MMLU-Benchmark zeigt die rasante Entwicklung der KI. Schauen wir uns die anfängliche Leistung und die anschließenden Fortschritte bei den MMLU-Bewertungen an und vergleichen wir die KI-Fähigkeiten mit den Benchmarks der menschlichen Experten.
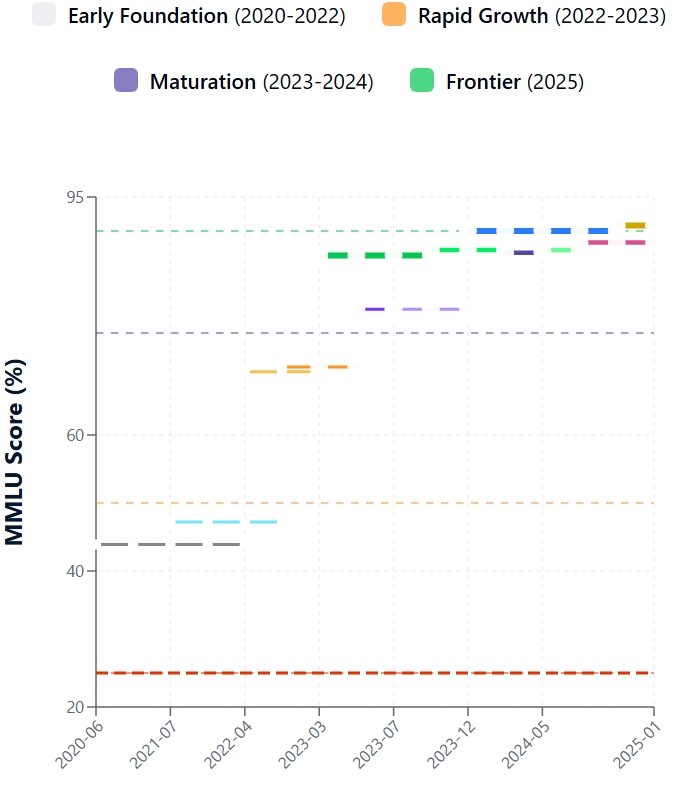
Das MMLU wurde Ende 2020 eingeführt und zeigte schnell die Grenzen der bestehenden modernen LLMs auf. Die ersten Begegnungen mit dem MMLU-Datensatz waren schwierig. Die anfänglichen MMLU-Werte für die meisten zeitgenössischen Modelle lagen bei etwa 25-30%, während das größte GPT-3 ~44% erreichte.
Wie du siehst, hatten selbst fähige Modelle wie die frühen GPT-3 Versionen Schwierigkeiten, was zeigt, dass ein umfassendes, menschenähnliches Verständnis in weiter Ferne lag.
Zu den größten Herausforderungen gehörten Defizite im Fachwissen (z. B. Recht, Medizin), begrenztes komplexes Denken, Anfälligkeit in Szenarien mit null oder wenigen Schüssen und Anfälligkeit für Ablenkungsmöglichkeiten in Fragen. Diese Ergebnisse unterstreichen den Wert der MMLU bei der Identifizierung von LLM-Grenzen.
Seit dem Start der MMLU ist die Leistung der LLM stark angestiegen. Dieser Fortschritt ist auf architektonische Innovationen, eine größere Modellgröße, bessere Trainingsdaten und verfeinerte Methoden wie die Feinabstimmung von Anweisungen und Reinforcement Learning from Human Feedback (RLHF) zurückzuführen. Infolgedessen sind die MMLU-Werte steil nach oben geklettert.
Zu den wichtigsten Faktoren gehören die Bestätigung der Skalierungsgesetze, architektonische Verfeinerungen bei den Transformatoren, fortschrittliche Trainingstechniken, die das Denken und die Ausrichtung verbessern, und das MMLU-eigene Design, das die Multitasking-Fähigkeit fördert. Die Entwicklung ausgefeilter MLOps-Praktiken hat ebenfalls eine entscheidende Rolle bei der Optimierung der Modellschulung und der Einsatzprozesse gespielt.
MMLU Punkteentwicklung
MMLU stellt die Leistung der KI dem menschlichen Intellekt gegenüber. In der ursprünglichen MMLU-Forschung lag die Genauigkeit der menschlichen Experten bei etwa 90 %. Anfänglich lagen die LLMs deutlich zurück. Die neuesten Modelle haben diese Lücke jedoch drastisch verkleinert.
Führende Modelle weisen inzwischen MMLU-Werte auf, die den durchschnittlichen Wert der menschlichen Experten erreichen oder leicht übertreffen. Es ist wichtig zu wissen, dass "menschlicher Experte" ein Bereich ist und die Leistung des Modells je nach Fach variiert. Das aktuelle Modell GPT-4.1 erreicht zum Beispiel 90,2 % beim MMLU-Test und Claude 4 Opus 88,8 %.
Es ist zwar beeindruckend, aber eine überdurchschnittliche Punktzahl ist nicht gleichbedeutend mit einem menschenähnlichen Verständnis, gesundem Menschenverstand oder Kreativität. Modelle können immer noch spröde sein oder sich mit neuen Argumenten schwer tun. Null-Schuss-Ergebnisse, ein reinerer Test der Generalisierung, haben sich ebenfalls verbessert, bleiben aber oft hinter den Ergebnissen von wenigen Schüssen zurück.
Das Erreichen und manchmal Übertreffen der MMLU-Werte von menschlichen Experten hat weitreichende Auswirkungen: Es bestätigt den Fortschritt der KI, erhöht den realen Nutzen in wissensintensiven Bereichen, katalysiert die Entwicklung von anspruchsvolleren Benchmarks (wie MMLU-Pro) und verstärkt den ethischen und gesellschaftlichen Dialog über die Rolle der KI. Während hohe MMLU-Werte wichtige Meilensteine sind, liegt der Schwerpunkt weiterhin auf der Entwicklung robuster, interpretierbarer und ethisch ausgerichteter KI.
Während der ursprüngliche MMLU-Benchmark die LLM-Evaluierung erheblich vorantrieb, wurden seine Grenzen mit dem schnellen Fortschritt der KI deutlich. Daraus entstanden Derivate wie MMLU-Pro und MMLU-CF, die auf eine strengere Bewertung abzielen.
Das ursprüngliche MMLU stand vor mehreren Herausforderungen, als die Modelle immer ausgefeilter wurden. Ein großes Problem ist, dass öffentlich verfügbare Fragen aus dem MMLU-Datensatz in den LLM-Trainingsdaten enthalten sein könnten, was die MMLU-Bewertungen aufbläht und nicht die wahre Generalisierung widerspiegelt.
Einige Fragen in jedem großen Benchmark können fehlerhaft, zweideutig oder veraltet sein, was die Zuverlässigkeit der MMLU-Bewertung beeinträchtigt. Als sich die Spitzenmodelle der perfekten Punktzahl näherten, nahm die Fähigkeit der MMLU, fortgeschrittene Denkfähigkeiten zu unterscheiden, ab, was den Ruf nach komplexeren Aufgaben laut werden ließ.
Sein fester Fragensatz entwickelt sich nicht mit den Fortschritten der Modelle oder neuen Wissensgebieten weiter. Da es sich um einen Multiple-Choice-Test handelt, prüft der MMLU nicht die entscheidenden generativen, erklärenden oder kreativen Fähigkeiten des LLM. Für eine aussagekräftige KI-Evaluierung ist es wichtig, diese Fragen zu klären.
MMLU-Pro wurde entwickelt, um mit anspruchsvolleren Fragen das logische Denken zu testen. MMLU-Pro erhöht den Schwierigkeitsgrad der Prüfung, indem es sich auf Fragen konzentriert, die ein tiefes Verständnis und eine anspruchsvolle Argumentation erfordern. Zu den wichtigsten Neuerungen gehören:
MMLU-Pro spiegelt die laufenden Bemühungen wider, Benchmarks für die Weiterentwicklung des KI-Verständnisses zu schaffen.
MMLU-CF (Contamination-Free) geht speziell gegen Datenverunreinigungen beim LLM-Benchmarking vor. MMLU-CF zielt darauf ab, eine MMLU-Bewertung mit Fragen zu erstellen, die mit hoher Wahrscheinlichkeit nicht in den Trainingsdaten des Modells enthalten sind. Zu den Strategien gehören:
MMLU-CF ist wichtig für die Integrität der Benchmarks. Eine hohe MMLU-Punktzahl bei einer kontaminationsfreien Version deutet zuverlässiger auf echte Verallgemeinerung und logisches Denken hin, nicht auf Auswendiglernen. Das ist wichtig, um die Fortschritte der KI genau zu verfolgen und die Modelle fair zu vergleichen.
Die Entwicklung des MMLU-Benchmarks und seine breite Akzeptanz haben die KI-Branche maßgeblich beeinflusst und sowohl die theoretischen Untersuchungen als auch die praktischen Anwendungen geprägt. Um ihre Bedeutung zu verstehen, ist es wichtig, ihre Auswirkungen zu kennen.
Das MMLU hat die Richtung der KI-Forschung maßgeblich geprägt. Indem sie einen hohen Standard für umfassendes Wissen und logisches Denken gesetzt hat, hat sie Innovationen in der Modellarchitektur und den Ausbildungsmethoden vorangetrieben.
Forscherinnen und Forscher suchen ständig nach neuen Wegen, um die MMLU-Bewertung ihrer Modelle zu verbessern, was zu Fortschritten in Bereichen wie
Die Integration von LLMOps-Methoden ist für das Management dieser zunehmend komplexen Modellentwicklungsprozesse unerlässlich geworden.
Darüber hinaus zeigt das Aufkommen innovativer Ansätze wie LMQL für strukturierte LLM-Interaktionen, wie sich das Feld erweitert, um mehr spezialisierte Werkzeuge für die Arbeit mit LLMs zu schaffen.
Die Fähigkeiten, die durch das Streben nach einer besseren MMLU-Bewertung erreicht werden, schlagen sich direkt in leistungsfähigeren und zuverlässigeren Anwendungen in der Praxis nieder.
Modelle, die bei MMLU gut abschneiden, sind in der Regel geschickter bei Aufgaben, die ein tiefes Verständnis und logisches Denken erfordern, was ihnen Türen in verschiedenen Branchen öffnet:
Der Fortschritt, der sich in den MMLU-Bewertungen widerspiegelt, unterstreicht den wachsenden Nutzen großer Sprachmodelle in diesen Bereichen.
Moderne Implementierungen wie Llama 3 zeigen, wie fortschrittliche LLMs effektiv in realen Szenarien eingesetzt werden können.
Die Reise der Sprachmodellbewertung ist noch lange nicht zu Ende. Die MMLU selbst und ihre Derivate weisen auf mehrere neue Trends und Herausforderungen hin.
Künftige Benchmarks werden wahrscheinlich vielfältigere Bewertungsformate einbeziehen, z. B. die Beantwortung offener Fragen, interaktive Dialoge und die Erfüllung von Aufgaben in simulierten Umgebungen, um ein breiteres Spektrum an KI-Fähigkeiten zu bewerten.
Da die KI immer mehr dazu übergeht, Inhalte aus Text, Bild, Audio und Video zu verstehen und zu generieren, müssen Benchmarks entwickelt werden, um diese multimodalen Fähigkeiten zu bewerten.
Es wird immer mehr Wert darauf gelegt, Benchmarks zu entwickeln, die die Sicherheit, Fairness, Voreingenommenheit und ethische Ausrichtung der Modelle streng prüfen. Die Implementierung automatisierter MLOps-Workflows ist entscheidend für die Wahrung der Integrität von Evaluierungen im großen Maßstab.
Die Sicherstellung der Benchmark-Integrität durch Methoden wie die des MMLU-CF wird eine zentrale Herausforderung bleiben, insbesondere wenn Unternehmen umfassende MLOps-Frameworks zur Verwaltung ihrer KI-Systeme einführen.
Der MMLU-Benchmark hat die Art und Weise, wie wir den Fortschritt bei großen Sprachmodellen messen und vorantreiben, unbestreitbar verändert. Von seinem umfassenden MMLU-Datensatz bis hin zu seinen anspruchsvollen MMLU-Bewertungsmethoden treibt es die KI zu einem breiteren Wissen und tieferen Schlussfolgerungen. Wenn sich die Modelle weiterentwickeln, werden auch die Maßstäbe, an denen sie sich orientieren, immer besser.
Bist du bereit, tiefer in die Welt der LLMs und MLOs einzutauchen? Erkunde den Kurs Large Language Models (LLMs) Concepts, um dein Fachwissen zu erweitern.
Top DataCamp Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
