Course
Introduction to LLMs in Python
3 hr
33.6K
The field of Artificial Intelligence (AI) is witnessing an explosion in the capabilities of Large Language Models (LLMs), which are increasingly adept at tasks requiring sophisticated understanding and generation of human language. As these models become more powerful, the need for robust evaluation methods becomes necessary.
This is where the MMLU benchmark (Massive Multitask Language Understanding) steps in. It is a comprehensive and challenging test for today's most advanced AI systems. The MMLU score has become a key indicator of a model's progress and a driving force in the ongoing quest to build more intelligent machines.
Understanding the MMLU meaning and its role is important for anyone involved in data science or AI, as it provides a standardized way to gauge the general knowledge and reasoning abilities of these models across a vast array of subjects. These capabilities are central to large language model development.
In this article, we will look into what the MMLU is, what the MMLU evaluation process entails, how the extensive MMLU dataset is structured, and why this benchmark is so significant for the advancement of AI.
Massive Multitask Language Understanding (MMLU) is a comprehensive benchmark designed to evaluate the knowledge and problem-solving abilities of large language models (LLMs) across a vast and diverse range of subjects. It consists of multiple-choice questions spanning 57 different tasks, including elementary mathematics, US history, computer science, law, and more.
The core idea behind the MMLU benchmark is to test a model's acquired knowledge and reasoning skills in a zero-shot or few-shot setting, meaning the model must answer questions with little to no task-specific examples.
This approach aims to measure how well models can understand and apply knowledge from their pre-training phase to tasks they haven't been explicitly fine-tuned for, reflecting a more general and robust form of intelligence. A model's performance is typically summarized by its MMLU score, indicating its accuracy across these varied domains.
The MMLU evaluation framework is profoundly significant for AI research and development for several key reasons, like:
MMLU Knowledge Domains
The emergence of MMLU is best understood by looking at the evolution of language model evaluation and the motivations that drove its creation.
MMLU was introduced by Dan Hendrycks and a team of researchers in their 2020 paper, "Measuring Massive Multitask Language Understanding." The primary motivation was the observation that existing benchmarks were becoming saturated by rapidly improving LLMs.
Models were achieving near-human or even superhuman performance on benchmarks like GLUE and SuperGLUE, but it wasn't always clear if this translated to a broad, human-like understanding of the world.
The creators of MMLU sought to develop a more challenging and comprehensive test that could:
The aim was to create an evaluation that could better differentiate the capabilities of increasingly powerful LLMs and provide a clearer path towards more generally intelligent systems.
MMLU represents a significant step in the evolution of benchmarks for natural language understanding (NLU).
Early NLU evaluations often focused on individual tasks like sentiment analysis, named entity recognition, or machine translation, each with its own dataset and metrics.
Introduced in 2018, GLUE (General Language Understanding Evaluation) was a collection of nine diverse NLU tasks, designed to provide a single-number metric for overall model performance. It became a standard for a while but was soon surpassed by models.
Developed in 2019 as a more challenging successor to GLUE, SuperGLUE featured more difficult tasks and a more comprehensive human baseline. However, even SuperGLUE saw models rapidly approaching human performance.
MMLU improved upon these previous benchmarks in several critical ways. With 57 tasks, the MMLU dataset is far more extensive and covers a much wider range of academic and professional subjects than GLUE (9 tasks) or SuperGLUE (8 tasks + a diagnostic dataset). This breadth makes it harder for models to specialize and encourages more general knowledge.
While GLUE/SuperGLUE tested various linguistic phenomena, MMLU directly assesses knowledge in specific domains like law, medicine, and ethics, requiring more than just language processing.
MMLU prioritizes evaluating models with minimal task-specific examples. This contrasts with many tasks in GLUE/SuperGLUE, where models were often fine-tuned on task-specific training sets. This makes the MMLU evaluation a better test of a model's ability to generalize from its pre-training.
The questions in MMLU are often designed to be challenging even for humans, particularly in specialized domains, providing a longer runway for measuring AI progress.
By addressing these aspects, MMLU established a new, more demanding standard for what it means for an LLM to "understand" language and the world.
To truly appreciate the MMLU benchmark, it's essential to understand its underlying structure and how it assesses language models. Let’s look at the composition of the MMLU dataset, the breadth of subjects it covers, and the specific evaluation methodologies that make it a robust test of AI capabilities.
The strength of the MMLU evaluation lies in its meticulously curated dataset, designed to be both broad and deep.
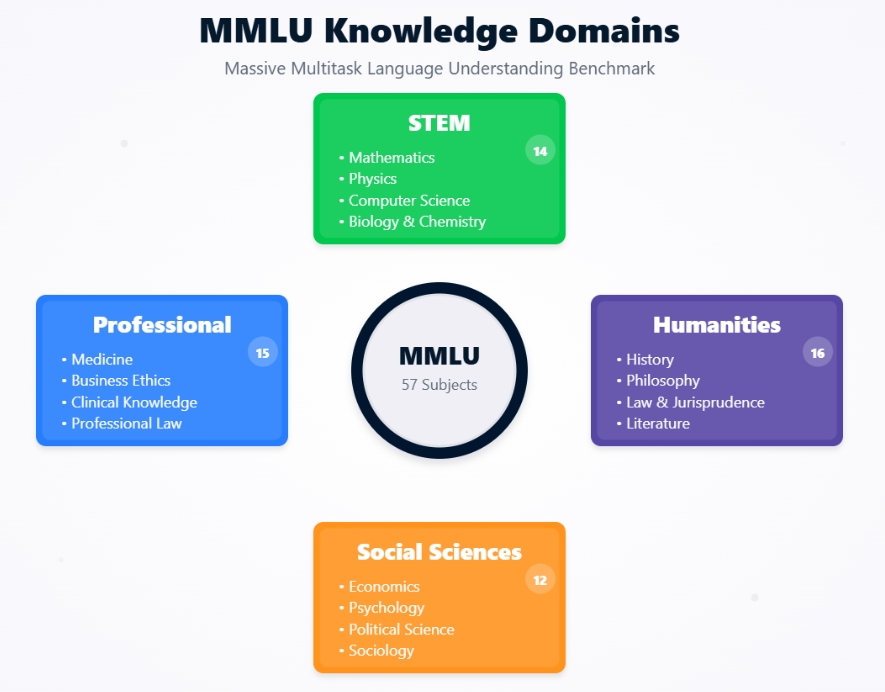
The MMLU dataset is not a monolithic entity but a collection of 57 distinct tasks, each corresponding to a specific subject area. These subjects are intentionally diverse, spanning several major categories:
Each task within the MMLU dataset consists of multiple-choice questions. Typically, each question presents a problem or query followed by four possible answers, one of which is correct. The questions are designed to test knowledge at various levels of difficulty, ranging from high school to college and even expert professional levels.
For example, a question in the "Professional Medicine" subject would require a level of knowledge expected from a medical professional, making it a challenging test even for highly capable LLMs.
The sheer volume and diversity of questions ensure that models cannot simply rely on memorizing answers but must possess a genuine understanding of the subject matter to achieve a high MMLU score.
The questions within the MMLU dataset are sourced from a variety of real-world materials to ensure their relevance and difficulty. These sources include:
This sourcing strategy ensures that the questions reflect the kind of knowledge and reasoning challenges encountered in academic and professional settings.
The goal is to assess a model's ability to understand and apply knowledge in contexts similar to those faced by educated humans.
A critical aspect of the MMLU's meaning and its evaluation power lies in its use of zero-shot and few-shot learning paradigms. These methodologies are important for testing a model's ability to generalize its knowledge without extensive task-specific training.
In a zero-shot setting, the LLM is presented with questions from a specific MMLU task (e.g., "Abstract Algebra" or "Moral Scenarios") without having seen any examples from that particular task during its fine-tuning phase or in the prompt itself.
The model must understand the question and select the correct multiple-choice answer based solely on its pre-trained knowledge.
For example, the prompt might simply be:
The following are multiple-choice questions (with answers) about [subject name].
[Question]
A) [Option A]
B) [Option B]
C) [Option C]
D) [Option D]
Answer:
The model is then expected to provide the letter of the correct option. This setup rigorously tests the model's ability to generalize its understanding to entirely new domains and question styles.
In a few-shot setting, the model is provided with a small number of examples (usually five, hence "5-shot") from the specific MMLU task directly in the prompt before it encounters the actual test question.
These examples consist of a question, the multiple-choice options, and the correct answer.
For instance:
The following are multiple-choice questions (with answers) about moral disputes.
Question: John Doe is a software engineer working for a company that develops autonomous weapons. He has serious ethical concerns about the potential misuse of this technology, which could lead to civilian casualties. However, he also has a family to support and fears losing his job if he speaks out. What is the primary ethical conflict John is facing?
A) Conflict of interest
B) Whistleblower's dilemma
C) Professional negligence
D) Intellectual property rights
Answer: B
[... 4 more examples ...]
Question: [Actual test question]
A) [Option A]
B) [Option B]
C) [Option C]
D) [Option D]
Answer:
The model uses these few examples to understand the context, style, and expected reasoning for the task before attempting the new, unseen question. This tests the model's ability for rapid, in-context learning and adaptation.
The importance of these methodologies in MMLU evaluation is that they reflect how humans often approach new problems, either by applying existing knowledge to something entirely new (zero-shot) or by quickly learning from a few examples (few-shot).
These evaluation settings simulate common real-world language processing tasks.
Zero-shot scenarios are akin to a user asking an AI a question about a topic the AI hasn't been specifically prompted on before. For example, a user might ask a general-purpose AI assistant a complex legal question or a nuanced philosophical query. The AI's ability to provide a sensible answer relies on its broad pre-trained knowledge.
Few-shot scenarios mirror situations where a user provides context or examples to guide the AI. For instance, a user might show an AI a few examples of how to summarize medical reports before asking it to summarize a new one, or provide examples of a specific poetic style before asking the AI to generate a poem in that style.
By evaluating models in both zero-shot and few-shot settings, MMLU provides a more comprehensive picture of their flexibility and learning capabilities, which are important for building truly useful and adaptable AI systems.
The ability to perform well under these conditions is a strong indicator of a model's potential for practical application across a wide range of tasks without requiring extensive, costly retraining for each new problem.
The evolution of language models on the MMLU benchmark highlights AI's rapid development. Let’s look at the initial performance, subsequent advancements in MMLU scores, and compare AI capabilities with human expert benchmarks.
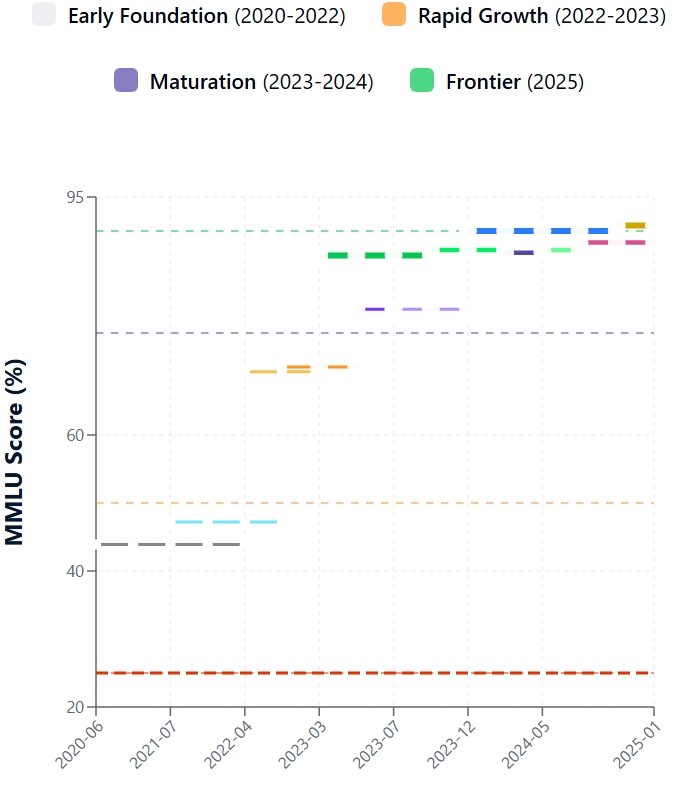
Introduced in late 2020, the MMLU quickly revealed limitations in existing state-of-the-art LLMs. Early encounters with the MMLU dataset were tough. Initial MMLU scores for most contemporary models were around 25–30%, while the largest GPT-3 reached ~44%.
As you can see, even capable models like early GPT-3 versions struggled, showing that broad, human-like understanding was distant.
Key challenges included deficits in specialized knowledge (e.g., law, medicine), limited complex reasoning, fragility in zero-shot/few-shot scenarios, and vulnerability to distractor options in questions. These findings underscored MMLU's value in identifying LLM frontiers.
Since MMLU's debut, LLM performance has surged. This progress stems from architectural innovations, increased model scale, better training data, and refined methods like instruction fine-tuning and Reinforcement Learning from Human Feedback (RLHF). Consequently, MMLU scores have climbed steeply.
Key drivers include confirmation of scaling laws, architectural refinements in Transformers, advanced training techniques enhancing reasoning and alignment, and MMLU's inherent design fostering multitask proficiency. The development of sophisticated MLOps practices has also played a crucial role in optimizing model training and deployment processes.
MMLU Score Evolution
MMLU crucially juxtaposes AI performance with human intellect. Original MMLU research set human expert accuracy around 90%. Initially, LLMs lagged significantly. However, the latest models have dramatically narrowed this gap.
Leading models now report MMLU scores meeting or slightly surpassing the average human expert benchmark. It's vital to note that "human expert" is a range, and model performance varies by subject. For example, the recent GPT-4.1 model reports a 90.2% score on the MMLU, and Claude 4 Opus hits 88.8%.
While impressive, exceeding average scores doesn't equate to human-like understanding, common sense, or creativity. Models can still be brittle or struggle with novel reasoning. Zero-shot scores, a purer test of generalization, have also improved but often trail few-shot results.
Achieving and sometimes surpassing human expert MMLU scores has profound implications: it validates AI progress, enhances real-world utility in knowledge-intensive fields, catalyzes the development of more challenging benchmarks (like MMLU-Pro), and heightens ethical and societal dialogues about AI's role. While high MMLU scores are key milestones, the focus remains on creating robust, interpretable, and ethically aligned AI.
While the original MMLU benchmark significantly advanced LLM evaluation, its limitations became apparent with AI's rapid progress. This led to derivatives like MMLU-Pro and MMLU-CF, aiming for more rigorous assessments.
The original MMLU faced several challenges as models grew more sophisticated. A major concern is that publicly available MMLU dataset questions might be in LLM training data, inflating MMLU scores and not reflecting true generalization.
Some questions in any large benchmark can be flawed, ambiguous, or outdated, affecting MMLU evaluation reliability. As top models neared perfect scores, MMLU's ability to differentiate advanced reasoning capabilities diminished, prompting calls for more complex tasks.
Its fixed question set doesn't evolve with model advancements or new knowledge areas. Being multiple-choice, MMLU doesn't test crucial generative, explanatory, or creative LLM capabilities. Addressing these is vital for meaningful AI evaluation.
MMLU-Pro was developed to test deeper reasoning with more challenging questions. MMLU-Pro increases evaluation difficulty by focusing on questions demanding profound understanding and sophisticated reasoning. Key enhancements include:
MMLU-Pro reflects ongoing efforts to ensure benchmarks drive AI reasoning advancements.
MMLU-CF (Contamination-Free) specifically tackles data contamination in LLM benchmarking. MMLU-CF aims to provide an MMLU evaluation with questions highly unlikely to be in model training data. Strategies include:
MMLU-CF is important for benchmark integrity. A high MMLU score on a contamination-free version more reliably indicates genuine generalization and reasoning, not memorization. This is vital for accurately tracking AI progress and fair model comparison.
The MMLU benchmark's creation and broad acceptance have significantly impacted the AI field, shaping both theoretical investigations and real-world uses. Understanding its implications is key to grasping its overall importance.
MMLU has significantly shaped the direction of AI research. By setting a high standard for broad knowledge and reasoning, it has driven innovations in model architecture and training methodologies.
Researchers are constantly exploring new ways to improve their models' MMLU score, leading to advancements in areas like:
The integration of LLMOps methodologies has become essential for managing these increasingly complex model development processes.
Additionally, the emergence of innovative approaches like LMQL for structured LLM interactions demonstrates how the field is expanding to create more specialized tools for working with LLMs.
The capabilities achieved by striving for better MMLU evaluation translate directly into more powerful and reliable real-world applications.
Models that perform well on MMLU are generally more adept at tasks requiring deep understanding and reasoning, opening doors in various industries like:
The progress reflected in MMLU scores underpins the growing utility of large language models in these fields.
Modern implementations like Llama 3 showcase how advanced LLMs can be deployed effectively in real-world scenarios.
The journey of language model evaluation is far from over. MMLU itself, along with its derivatives, points towards several emerging trends and challenges.
Future benchmarks will likely incorporate more diverse evaluation formats, including open-ended question answering, interactive dialogues, and task completion in simulated environments to assess a broader range of AI capabilities.
As AI moves towards understanding and generating content across text, images, audio, and video, benchmarks will need to evolve to evaluate these multimodal skills.
There's a growing emphasis on developing benchmarks that rigorously test for model safety, fairness, bias, and ethical alignment. The implementation of automated MLOps workflows will be crucial for maintaining evaluation integrity at scale.
Ensuring benchmark integrity through methods like those in MMLU-CF will remain a key challenge, particularly as organizations adopt comprehensive MLOps frameworks to manage their AI systems.
The MMLU benchmark has undeniably reshaped how we measure and drive progress in Large Language Models. From its comprehensive MMLU dataset to its challenging MMLU evaluation methods, it pushes AI towards broader knowledge and deeper reasoning. As models continue to evolve, so too will the benchmarks that guide them, ensuring a future of increasingly capable and versatile AI.
Ready to go deeper into the world of LLMs and MLOps? Explore the Large Language Models (LLMs) Concepts course to expand your expertise.
Top DataCamp Courses
Course
Course
Course
blog
Javier Canales Luna
12 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Maria Eugenia Inzaugarat
Tutorial
Abid Ali Awan
