
programa
Fundamentos del aprendizaje automático en Python
16 h
Los profesionales del machine learning deben evaluar tanto la calidad de sus datos como el rendimiento de tus modelos predictivos.
Existen diversas métricas que pueden resultar útiles, especialmente cuando se trata de tareas de clasificación binaria tareas de clasificación, aquellas en las que se predice que cada punto de datos pertenece a una de dos categorías posibles. Algunos ejemplos son la aprobación de créditos (aprobar/no aprobar), la clasificación de malware (malicioso/no malicioso), la selección de currículos (preseleccionar/no preseleccionar) y el diagnóstico de enfermedades (tiene la enfermedad/no tiene la enfermedad). Incluso las pruebas A/B están estrechamente relacionadas, ya que básicamente plantean la pregunta «¿Es la versión B mejor que la versión A?» (sí/no).
Aunque la precisión ofrece un resumen rápido del rendimiento, puede ocultar información crucial sobre la naturaleza de los errores de un modelo. Por ejemplo, un detector de fraude crediticio que clasifique todas las transacciones como legítimas podría alcanzar una precisión del 99 %, pero no detectar ningún fraude real. La sensibilidad y la especificidad ofrecen información más detallada, lo que te ayuda a comprender no solo la frecuencia con la que un modelo es correcto, sino también qué tipos de errores comete y si esos errores son aceptables en el contexto.
En esta guía, aprenderás qué significan realmente la sensibilidad y la especificidad, cuándo es más adecuado utilizar cada métrica, cómo se calculan y cómo aplicarlas de forma práctica en tu trabajo mediante ejemplos claros y reales.
La sensibilidad y la especificidad tienen su origen en la evaluación médica. Enmarcar estas métricas desde la perspectiva de las pruebas diagnósticas y la toma de decisiones clínicas ayuda a aclarar muchos de los conceptos de este artículo. Para ilustrarlo, utilizaremos dos ejemplos prácticos: la detección de enfermedades y el fraude con tarjetas de crédito.
Este artículo está dirigido a profesionales de los datos que utilizan inferencia estadística y desean comprender métricas más matizadas que la precisión para tomar mejores decisiones. Estas métricas ayudan a evaluar qué tipos de errores comete un modelo y si esos errores son aceptables en el contexto. Las aplicaciones incluyen el diagnóstico médico y la detección de fraudes, como hemos visto. Otras aplicaciones incluyen la detección de intrusiones, el control de calidad en la fabricación y el filtrado de spam.
Antes de interpretar o aplicar la sensibilidad y la especificidad, es esencial comprender los conceptos básicos que hay detrás de ellas. En esta sección, analizamos los orígenes históricos, las definiciones básicas, las derivaciones y los cálculos.
Los conceptos de sensibilidad y especificidad tienen su origen en la bioestadística. Aunque ya se utilizaba anteriormente en la literatura médica, el investigador en bioestadística Jacob Yerushlamy popularizó el término en su artículo «Problemas estadísticos en la evaluación de métodos de diagnóstico médico, con especial referencia a las técnicas de rayos X».
En la década de 1970, la curva característica operativa del receptor (ROC, por sus siglas en inglés) (que se describe más adelante) se convirtió en una herramienta para analizar visualmente la sensibilidad frente a la especificidad en las pruebas clínicas. En la década de 1990, el machine learning adaptó estos conceptos. Hoy en día, estos términos se utilizan ampliamente en el ámbito sanitario y en el machine learning para medir la capacidad de los sistemas para identificar verdaderos positivos y verdaderos negativos.
Supongamos que se utiliza un modelo de machine learning para detectar transacciones fraudulentas con tarjetas de crédito. De una muestra de 10 000 transacciones, hay 9800 transacciones legítimas y 200 casos de fraude.
Dado que nos interesan principalmente los casos de fraude, designaremos los casos fraudulentos como positivos y los no fraudulentos como negativos. (Los casos que se designan como «positivos» y «negativos» son algo arbitrarios; sin embargo, suele haber una forma obvia de etiquetarlos).
Tras ejecutar el modelo y comparar los casos de fraude previstos con los casos reales, hemos constatado que se han detectado correctamente 160 casos de fraude, se han identificado correctamente 9500 transacciones legítimas, se han detectado erróneamente como fraudulentas 300 transacciones legítimas y el modelo no ha detectado 40 casos de fraude.
Para mantener todos estos datos claros, se utiliza habitualmente la siguiente nomenclatura.
La segunda letra (P o N) se refiere a si se predijo que el caso era positivo o negativo, y la primera letra indica si esa predicción fue verdadera (T) o falsa (F).
Por lo tanto, un «falso positivo» indica que se predijo que el caso era positivo y que dicha predicción era falsa o, en otras palabras, que se predijo que el caso era positivo, pero en realidad era negativo. Del mismo modo, un falso negativo es un caso que se predijo como negativo, pero que en realidad es positivo.
Para mostrar esta información, solemos utilizar una «matriz de confusión, llamada así porque realiza un seguimiento de la frecuencia con la que el modelo confunde predicciones incorrectas con resultados reales (FN, FP). Aquí tienes un ejemplo:
|
Fraude real (positivo) |
Legítimo real (negativo) |
|
|
Fraude previsto (positivo previsto) |
160 (TP) |
300 (FP) |
|
Legítimo previsto (negativo previsto) |
40 (FN) |
9500 (TN) |
Ahora, echemos un vistazo a los totales de filas y columnas. Las sumas de las filas indican el total de casos previstos y las sumas de las columnas indican el total real.
|
Fraude real (positivo) |
Legítimo real (negativo) |
||
|
Fraude previsto (positivo previsto) |
160 (TP) |
300 (FP) |
460 (TP + FP) Total de positivos previstos |
|
Legítimo previsto (negativo previsto) |
40 (FN) |
9500 (TN) |
9540 (FN + TN) Total de negativos previstos |
|
200 (TP + FN) Total de positivos reales |
9800 (FP + TN) Total de negativos reales |
10 000 |
¿Qué representan estos totales?
La sensibilidad (también conocida como tasa de verdaderos positivos o recuperación) mide la capacidad del modelo para identificar correctamente los verdaderos positivos. Más precisamente, la sensibilidad es la proporción de verdaderos positivos respecto a los positivos reales, TP / (TP + FN).
Del mismo modo, la especificidad (tasa de negativos verdaderos) mide la capacidad del modelo para identificar los negativos verdaderos. Es la proporción de verdaderos negativos respecto a los negativos reales, VN / (FP + VN).
Desde un punto de vista probabilístico, la sensibilidad es la probabilidad de que una prueba dé positivo si el paciente tiene la enfermedad, y la especificidad es la probabilidad de que una prueba dé negativo si el paciente no tiene la enfermedad.
En nuestro ejemplo de fraude, la sensibilidad = TP / (TP + FN) = 160/200, o 80 %. La especificidad es de 9500/9800, o aproximadamente del 97 %.
A medida que cambian los umbrales del modelo, la sensibilidad y la especificidad suelen moverse en direcciones opuestas. El aumento de la sensibilidad suele reducir la especificidad, y viceversa. En esta sección, exploramos esta compensación inherente y analizamos cómo el análisis de la característica operativa del receptor (ROC) proporciona un enfoque visual y cuantitativo para evaluar el rendimiento del modelo en distintos umbrales.
Modifiquemos el ejemplo de fraude para que haya 20 falsos negativos más, FN = 60. Dado que el número total de casos de fraude reales sigue siendo 200, ahora debe haber 20 verdaderos positivos menos (VP = 140).
|
Fraude real (positivo) |
Legítimo real (negativo) |
||
|
Fraude previsto (positivo previsto) |
140 (TP) |
300 (FP) |
460 (TP + FP) Total de positivos previstos |
|
Legítimo previsto (negativo previsto) |
60 (FN) |
9500 (TN) |
9540 (FN + TN) Total de negativos previstos |
|
200 (TP + FN) Total de positivos reales |
9800 (FP + TN) Total de negativos reales |
10 000 |
La sensibilidad ha disminuido del 80 % al 140/200 = 70 %. A medida que aumenta el número de falsos negativos, la sensibilidad disminuye, y viceversa. Esto significa que una alta sensibilidad indica que el número de falsos negativos es bajo.
En términos médicos, una prueba con alta especificidad identifica correctamente a la mayoría de las personas que no padecen la enfermedad. En nuestro ejemplo sobre la detección del cáncer, una prueba con una alta especificidad garantiza que a las personas que no padecen cáncer no se les diagnostique erróneamente esta enfermedad.
Esto ilustra la relación entre sensibilidad y especificidad. Algunos pacientes pueden alarmarse cuando se les dice que tienen cáncer cuando en realidad no es así, pero las personas que realmente padecen la enfermedad son identificadas correctamente. En este caso, una alta especificidad es una mejor métrica. En un mundo imperfecto, debemos tomar decisiones adecuadas basándonos en una evaluación de las ventajas e inconvenientes de los distintos parámetros.
Un umbral de diagnóstico establece el valor límite que determina si el resultado de una prueba se considera positivo o negativo. Convierte un valor continuo, como una probabilidad, en un valor binario (sí/no). En términos cotidianos, determina dónde trazar la línea divisoria entre resultados positivos y negativos.
El umbral suele fijarse en el 50 %, o 0,50. Una probabilidad superior al 50 % se considera positiva, y una inferior al 50 % se considera negativa.
Cambiar los umbrales determina qué casos se consideran positivos y negativos. Este cambio afecta al equilibrio entre detectar verdaderos positivos y evitar falsos negativos.
Por ejemplo, consideremos un modelo que genera una probabilidad de cáncer. Si el umbral se establece en 0,3, el modelo clasifica a muchas personas como positivas. Este enfoque funciona bien para la detección porque reduce la probabilidad de pasar por alto casos.
Sin embargo, aumenta el riesgo de falsos positivos. Si el umbral es 0,8, el modelo clasifica a menos personas como positivas. Este enfoque reduce los falsos positivos, pero aumenta el riesgo de pasar por alto casos reales.
Cuando cambia el umbral, el modelo modifica la frecuencia con la que detecta los verdaderos positivos y la frecuencia con la que evita los falsos positivos. Los umbrales más bajos aumentan la sensibilidad, pero reducen la especificidad; los umbrales más altos reducen la sensibilidad, pero aumentan la especificidad.
Una curva característica operativa del receptor (ROC) es un gráfico común que se utiliza para comparar los umbrales de clasificación entre valores de sensibilidad y especificidad. La curva ROC grafica la sensibilidad frente a 1 - especificidad. Cada punto de la curva representa un umbral específico. A medida que cambia el umbral, la sensibilidad y la especificidad del modelo se ajustan en consecuencia, trazando la curva ROC.
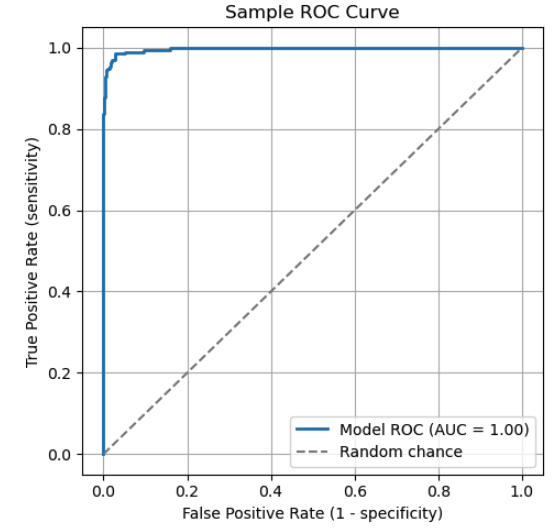
La curva ROC ilustra la relación entre sensibilidad y especificidad. Puntos clave de la curva:
La línea diagonal discontinua representa el azar. Un modelo que funciona según este principio no tiene un poder discriminatorio real.
Para evaluar un modelo utilizando una curva ROC, ten en cuenta el «área bajo la curva» (AUC). El AUC es el área total (integral) bajo la curva, que representa un promedio ponderado del rendimiento en todos los umbrales. Un AUC más alto indica una mejor capacidad general para distinguir entre clases positivas y negativas.
|
Puntuación AUC |
Interpretación |
|
1.0 |
Clasificador perfecto |
|
0,9 - 1,0 |
Excelente |
|
0,8 - 0,9 |
Bien |
|
0,7 - 0,8 |
Justo |
|
0,6 - 0,7 |
Pobre |
|
0,5 |
Sin discriminación (equivalente a una suposición aleatoria) |
|
< 0.5 |
Peor que al azar |
Valores predictivos y razones de probabilidad
En esta sección, exploramos cómo la prevalencia influye en la fiabilidad de los resultados de las pruebas. También analizamos cómo los índices de probabilidad combinan la sensibilidad y la especificidad en un solo número que permite a los médicos actualizar las probabilidades diagnósticas después de las pruebas.
El valor predictivo positivo (VPP), equivalente matemáticamente a la precisión en el machine learning, refleja la probabilidad de que una predicción positiva sea correcta. Mide la proporción de positivos previstos que son positivos verdaderos: PPV = TP / (TP + FP).
El valor predictivo negativo (VPN) refleja la fiabilidad de un resultado negativo. Mide la proporción de resultados negativos que son verdaderos negativos. Su fórmula es VAN = TN / (TN + FN).
Supongamos que realizamos pruebas a 1000 personas para detectar una enfermedad con esta matriz de confusión.
|
Positivo real (enfermo) |
Negativo real (saludable) |
||
|
Positivo previsto (enfermo) |
80 (TP) |
20 (FP) |
100 |
|
Negativo previsto (sano) |
10 (FN) |
890 (TN) |
900 |
|
90 |
910 |
1000 |
A modo de comparación, supongamos que hay más personas enfermas (300 en lugar de 90) y ajustamos la matriz de confusión en consecuencia.
|
Positivo real (enfermo) |
Negativo real (saludable) |
||
|
Positivo previsto (enfermo) |
270 (TP) |
70 (FP) |
340 |
|
Negativo previsto (sano) |
30 (FN) |
630 (TN) |
660 |
|
300 |
700 |
1000 |
A medida que aumenta la prevalencia, aumenta el número de casos verdaderos positivos.
Los índices de probabilidad combinan la sensibilidad y la especificidad en un solo número que ayuda a los médicos a actualizar su confianza en un diagnóstico basado en los resultados de las pruebas.
Antes de aplicar los coeficientes de verosimilitud, es importante distinguir entre probabilidad y probabilidades. La probabilidad es la posibilidad de que ocurra un evento, expresada mediante un valor entre 0 y 1. Las probabilidades representan la probabilidad de que un evento ocurra en relación con la probabilidad de que no ocurra.
Una probabilidad del 75 % significa que el evento ocurre 75 veces de cada 100. Las probabilidades correspondientesen del evento son 0,75 / (1 - 0,75) = 0,75 / 0,025 = 3. Esto significa que las probabilidades son de 3 a 1 a favor de que el evento ocurra.
En términos más generales, si p es la probabilidad de que se produzca un evento, entonces la probabilidad = p / (1 - p). Convirtiendo probabilidades en probabilidades, p = probabilidades / (1 + probabilidades).
El índice de probabilidad positiva (LR+) indica en qué medida un resultado positivo aumenta las probabilidades de padecer la enfermedad en comparación con alguien que no la padece. Los valores más altos (>10) sugieren que la prueba es muy eficaz para descartar la afección. La fórmula es LR+ = Sensibilidad / (1 - Especificidad).
El índice de probabilidad negativa (LR-) indica en qué medida un resultado negativo reduce las probabilidades de padecer la enfermedad en comparación con alguien que no la padece. Los valores más bajos (< 0,1) sugieren que la prueba es muy eficaz para descartar una afección. La fórmula es LR- = (1 - Sensibilidad) / Especificidad.
Para tomar decisiones, los médicos comienzan con una probabilidad previa a la prueba estimada en función de factores como los síntomas y el historial del paciente. Esta estimación se combina con la razón de verosimilitud para calcular la probabilidad posterior a la prueba.
El procedimiento es el siguiente.
Por ejemplo, supongamos que la probabilidad previa al test de padecer la enfermedad es del 30 % y LR+ = 10. ¿Cuál es la probabilidad posterior a la prueba?
Observamos que LR+ modificó significativamente la probabilidad y la confianza en un diagnóstico.
A medida que las pruebas de diagnóstico y los sistemas de clasificación se vuelven más complejos, surgen nuevas metodologías para superar los límites tradicionales del rendimiento. En esta sección, exploramos cómo los enfoques bayesianos permiten establecer umbrales de decisión personalizados y cómo tecnologías novedosas, como los diagnósticos basados en CRISPR, están ampliando las fronteras de la sensibilidad y la especificidad analíticas.
La idea de partir de una creencia previa y actualizarla en función de la información nueva es la base de la estadística bayesiana. Proporciona una forma formal de revisar las probabilidades a la luz de nuevos datos.
El razonamiento bayesiano se basa en tres componentes clave.
Esto se describe matemáticamente mediante el teorema de Bayes.
P(A|B) = P(B|A) x P(A) / P(B)
donde P(A|B) es la posterior (la probabilidad de A dado B), P(B|A) es la verosimilitud (la probabilidad de B dado que A es verdadero), P(A) es la a priori y P(B) es la evidencia.
Como hemos visto, los modelos de clasificación tradicionales suelen aplicar un umbral fijo, como 0,5, para determinar si un resultado debe etiquetarse como positivo o negativo. Los enfoques bayesianos, por el contrario, permiten que estos umbrales se adapten en función del contexto, incluyendo factores de riesgo individuales, datos demográficos, historial de comportamiento o datos en tiempo real. Esta flexibilidad permite a los sistemas ajustar los umbrales de forma dinámica, en lugar de depender de un umbral estático único para todos los casos.
Considera un modelo que predice la probabilidad de padecer una enfermedad cardíaca. Un modelo tradicional podría utilizar un umbral de 0,5. Los pacientes con una probabilidad superior al 50 % se consideran positivos, y los que están por debajo, negativos.
Ahora, consideremos un enfoque bayesiano con dos pacientes hipotéticos:
Ambos pacientes obtienen una probabilidad generada por la prueba de 0,45. Un modelo de umbral fijo con un umbral de 0,5 trataría a ambos pacientes como negativos.
Sin embargo, un modelo bayesiano incorpora información previa sobre el riesgo y puede utilizarse junto con intervalos de predicción. En el caso del paciente A, el sistema puede reducir el umbral de decisión y marcar el caso para que se evalúe más a fondo. En el caso del paciente B, puede mantenerse el umbral y no se recomienda ningún seguimiento.
De esta forma, los métodos bayesianos adaptan el umbral de clasificación al contexto de cada paciente, lo que permite tomar decisiones más adecuadas desde el punto de vista clínico.
Una tecnología emergente que amplía los límites de la sensibilidad y la especificidad analíticas es diagnóstico basado en CRISPR. Los científicos adaptaron CRISPR (repeticiones palindrómicas cortas agrupadas y espaciadas regularmente), una herramienta de edición genética, para detectar material genético. Utiliza proteínas Cas para detectar secuencias específicas de ácido nucleico con alta sensibilidad.
Los ensayos basados en CRISPR se han utilizado para la detección precoz del cáncer. Se están desarrollando herramientas portátiles para el diagnóstico del cáncer destinadas a su uso en entornos clínicos. Dos plataformas de diagnóstico importantes son SHERLOCK y DETECTR.
Los ensayos basados en CRISPR ofrecen muchas ventajas. Ofrecen una alta sensibilidad, por lo que pueden detectar cantidades mínimas de ADN o ARN.
Esto los hace valiosos para identificar infecciones en fase inicial, cáncer o mutaciones raras. También ofrecen una especificidad excepcional, lo que les permite distinguir entre secuencias genéticas muy similares para reducir los falsos positivos. Entre las ventajas adicionales se incluyen resultados rápidos y un equipo portátil y económico.
Estos ensayos admiten una amplia gama de aplicaciones, entre las que se incluyen la detección de enfermedades infecciosas, el diagnóstico del cáncer y el cribado de enfermedades genéticas. Los investigadores pueden utilizar el machine learning para optimizar el diseño del ARN guía y mejorar la precisión diagnóstica.
Los ensayos basados en CRISPR también se enfrentan a retos. La mayoría solo proporcionan un resultado binario (positivo o negativo). La estandarización y la reproducibilidad siguen siendo motivo de preocupación, ya que los resultados varían según los laboratorios y las condiciones de las pruebas.
Además, estos ensayos deben cumplir los requisitos normativos, incluidas las aprobaciones de la FDA y la CLIA, que exigen una validación, documentación y revisión exhaustivas. Por último, las cuestiones relacionadas con la propiedad intelectual complican la concesión de licencias y ralentizan la comercialización.
La sensibilidad y la especificidad desempeñan un papel fundamental en la evaluación de las pruebas diagnósticas y los modelos de clasificación. Pueden ser más reveladores que la precisión, especialmente en conjuntos de datos desequilibrados o cuando los falsos positivos o los falsos negativos conllevan costes diferentes. Junto con herramientas relacionadas, como los índices de verosimilitud y el análisis ROC, guían una interpretación perspicaz y una mejor toma de decisiones.
¿Quieres profundizar tus habilidades prácticas en la evaluación del rendimiento de los modelos? Asegúrate de explorar estos recursos de DataCamp:
Cursos más populares de DataCamp
programa
Curso
Curso
blog
Arun Nanda
15 min
blog
Zoumana Keita
14 min
blog
Matt Crabtree
10 min
blog
Natassha Selvaraj
15 min
blog
Tim Lu
12 min
Tutorial
Abid Ali Awan
