
Curso
Inferencia para la regresión lineal en R
4 h
15.9K
La suma de cuadrados es una medida estadística compleja que desempeña un papel esencial en el análisis de regresión. Describe la variabilidad de la variable dependiente y puede descomponerse en tres componentes -la suma de cuadrados total (SST), la suma de cuadrados de regresión (SSR) y la suma de cuadrados de error (SSE)- que en conjunto ayudan a evaluar el rendimiento de un modelo de regresión.
En este artículo hablaremos de los tres componentes de la suma de cuadrados, así como de la R-cuadrado. Primero daremos una visión general de cada suma de cuadrados por separado. A continuación, consideraremos la relación matemática entre ellos. Por último, exploraremos la conexión del SST, SSR y SSE con el R-cuadrado, una métrica clave de evaluación de modelos.
Empecemos definiendo qué son la TSM, la TSS y la TSE, cómo refleja cada medida la variabilidad total y cómo ayuda cada una de ellas a evaluar la bondad de ajuste de un modelo de regresión. Además, veremos qué aspecto tiene cada suma de cuadrados en una regresión lineal simple con una variable dependiente y una independiente.
Si, mientras repasamos las definiciones, quieres repasar estadística sin codificación de por medio, consulta nuestro curso Introducción a la Estadística. Para cursos introductorios de estadística anclados en una tecnología específica, tenemos opciones, como Introducción a la Estadística en Google Sheets, Introducción a la Estadística en Python e Introducción a la Estadística en R.
La suma de cuadrados totales (SST) es la suma de las diferencias al cuadrado entre cada valor de la variable dependiente observada y la media de esa variable. También se conoce como suma total de cuadrados (SCT).
La suma de cuadrados total representa la variabilidad total de la variable dependiente, incluidas las partes de variabilidad explicadas y no explicadas por el modelo de regresión. Por su naturaleza, la TSM refleja la dispersión global de los valores individuales de la variable dependiente observada respecto a su valor medio.
A continuación se muestra la fórmula matemática para calcular la TSM:
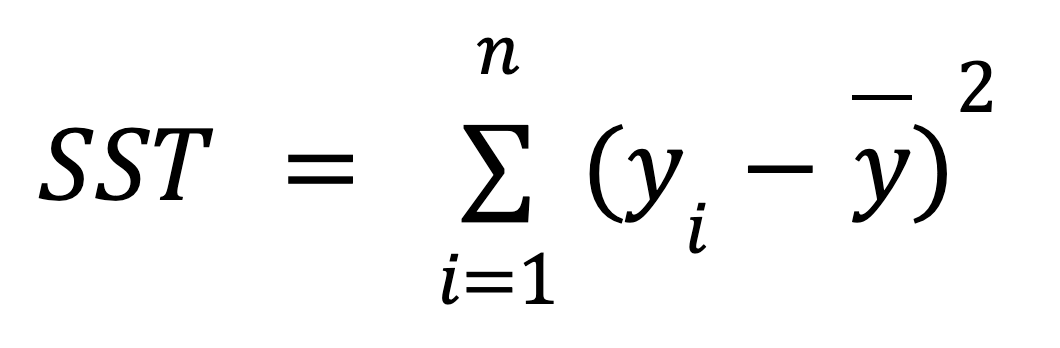
donde:
El siguiente gráfico de una regresión lineal simple muestra gráficamente el significado de la fórmula anterior:
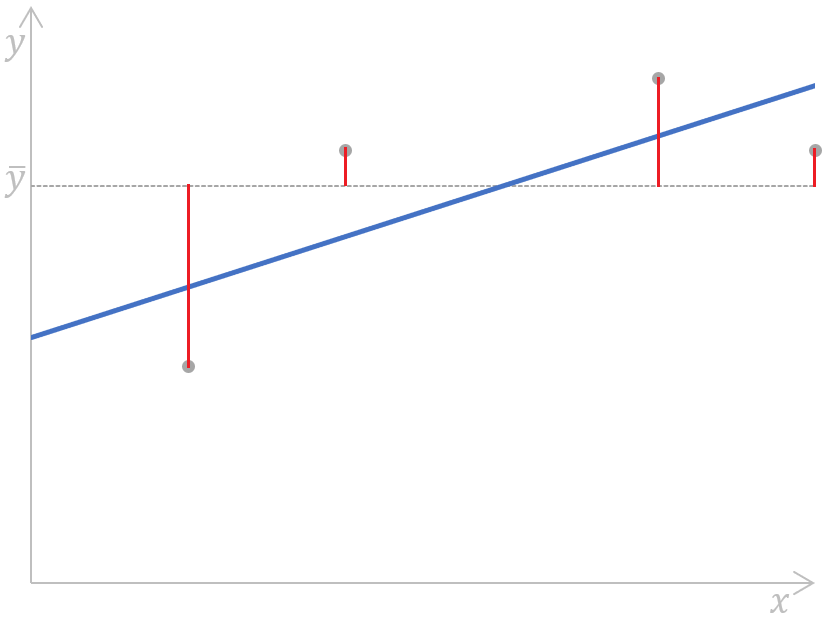
Calcular la suma de cuadrados totales de una regresión lineal simple. Imagen del autor
Como vemos, se miden las distancias (los segmentos rojos del gráfico) entre el valor medio (la línea discontinua gris) de la variable dependiente observada y cada valor (los puntos grises) de esa variable, se elevan al cuadrado y se suman. Además, este gráfico muestra claramente que la TSM no depende del modelo de regresión; sólo depende de los valores y observados y de la media de la variable dependiente observada.
La suma de cuadrados de regresión (SSR) es la suma de las diferencias al cuadrado entre cada valor de la variable dependiente predicho por un modelo de regresión para cada punto de datos de la variable independiente y la media de la variable dependiente observada. Otros términos para esta métrica son: suma de cuadrados de regresión, suma de cuadrados debida a la regresión y suma de cuadrados explicada. Incluso hay otra abreviatura para ello: ESS.
La regresión de lasuma decuadrados capta la parte de la variabilidad total de la variable dependiente explicada por el modelo de regresión (de ahí uno de sus términos alternativos:suma de cuadradosexplicada). También podemos considerarlo como el error reducido debido al modelo de regresión.
Para calcular el SSR, utilizamos la siguiente fórmula:
donde:
Podemos ilustrar esta fórmula en el siguiente gráfico de regresión lineal simple:
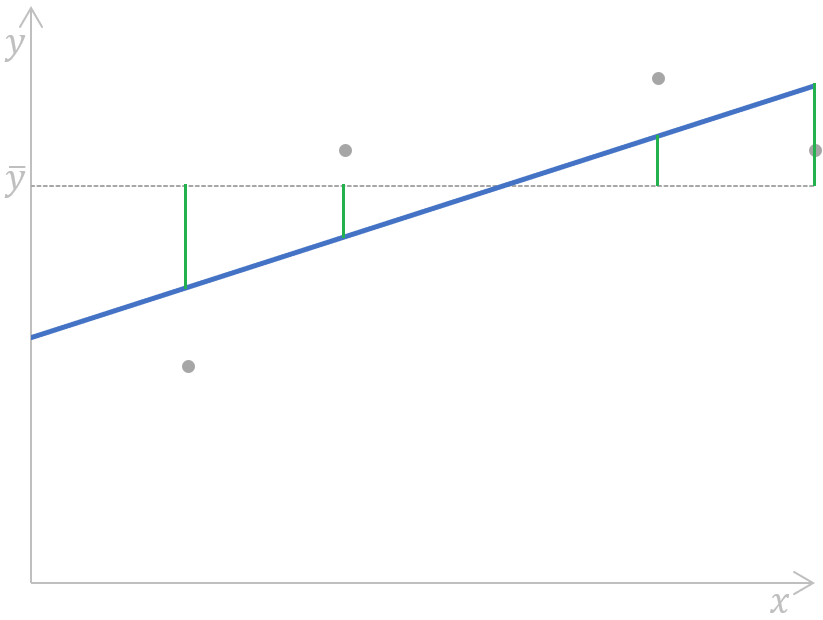 de la regresión de suma de cuadrados para una regresión lineal simpleCálculo de la regresión de la suma de cuadrados para una regresión lineal simple. Imagen del autor
de la regresión de suma de cuadrados para una regresión lineal simpleCálculo de la regresión de la suma de cuadrados para una regresión lineal simple. Imagen del autor
En pocas palabras, se miden, se elevan al cuadrado y se suman las distancias (los segmentos verdes del gráfico) entre el valor medio (la línea discontinua gris) de la variable dependiente observada y cada valor de la variable dependiente predicho por un modelo de regresión (la línea azul) para cada punto de datos de la variable independiente.
En el análisis de regresión, el SSR contribuye a medir el ajuste de un modelo de regresión, ayudando a determinar lo bien que el modelo predice los puntos de datos. Tendremos una idea más clara de cómo ocurre más adelante en este tutorial, cuando hablemos de la relación entre las tres métricas de la suma de cuadrados.
La suma del error cuadrático (SSE) es la suma de las diferencias al cuadrado entre cada valor de la variable dependiente observada y el valor de la variable dependiente predicho por un modelo de regresión para el mismo punto de datos de la variable independiente. En otras palabras, esta métrica mide la diferencia entre los valores reales y previstos de la variable dependiente.
El error de la suma de cuadrados también se llama suma de cuadrados de error, suma de cuadrados residual, suma de cuadrados residual o suma de cuadrados inexplicada. Además de SSE, también puede abreviarse como RSS, ESS o incluso SSR; en este último caso, puede confundirse fácilmente con la anteriormente comentada SSR, que significa regresión de la suma de cuadrados.
El error de la suma de cuadrados refleja el error restante, o variabilidad no explicada, que es la parte de la variabilidad total de la variable dependiente que no puede ser explicada por el modelo de regresión (por eso también se llama suma de cuadrados no explicada). suma de cuadrados no explicada).
Podemos utilizar la siguiente fórmula para calcular el SSE:
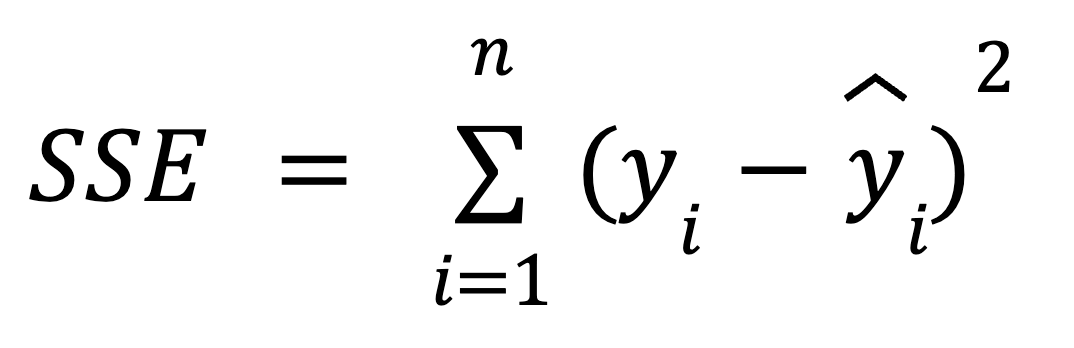
donde:
Gráficamente, esta fórmula puede mostrarse como:
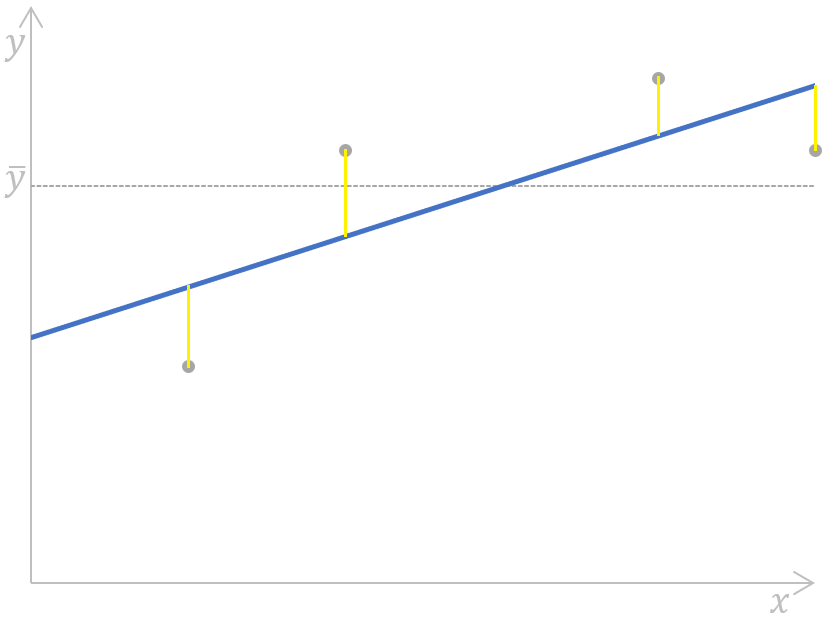 suma del error cuadrático de una regresión lineal simpleCómo calcular la suma del error cuadrático de una regresión lineal simple. Imagen del autor
suma del error cuadrático de una regresión lineal simpleCómo calcular la suma del error cuadrático de una regresión lineal simple. Imagen del autor
Aquí, las distancias (los segmentos amarillos del gráfico) para cada par de valores reales-predichos de la variable dependiente se miden, se elevan al cuadrado y se suman.
En el análisis de regresión, minimizar la SSE es clave para mejorar la precisión del modelo de regresión, y vamos a construir una intuición en torno a ella en el próximo capítulo.
También tenemos una colección de tutoriales sobre tecnologías específicas para ayudarte a adquirir las habilidades necesarias para construir modelos sencillos de regresión lineal y logística, entre ellos Essentials of Linear Regression in Python, How to Do Linear Regression in R y Linear Regression in Excel: Guía completa para principiantes.
La relación matemática entre la SST, la SSR y la SSE se expresa mediante la siguiente fórmula:
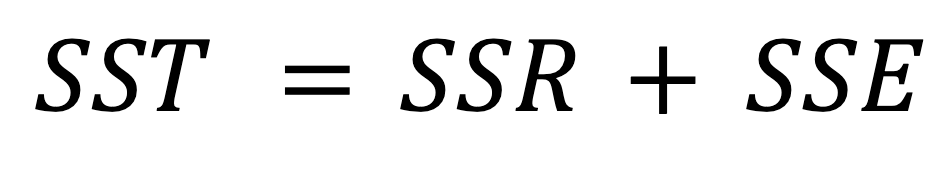
Antes hemos mencionado que la variabilidad total (SST) se compone tanto de la variabilidad explicada (SSR) como de la variabilidad no explicada (SSE), lo que se refleja en la fórmula anterior.
Como hemos visto antes, la TSM no depende del modelo de regresión, mientras que las otras dos métricas sí. Esto significa que la mejora de la precisión del modelo está relacionada con los cambios en el SSR o el SSE, en concreto, minimizando el SSE y, por tanto, maximizando el SSR. A partir de la fórmula anterior, podemos decir que cuanto menor sea el SSE, más se acercará el SSR al SST; por tanto, mejor se ajustará nuestro modelo de regresión a los valores observados de la variable dependiente.
Si el SSE fuera igual a 0, el SSR coincidiría con el SST, lo que significaría que todos los valores observados de la variable dependiente están perfectamente explicados por el modelo de regresión, es decir, todos ellos estarían situados exactamente en la recta de regresión. En el mundo real, esto no ocurrirá, pero debemos intentar minimizar el SSE para tener un modelo de regresión más fiable.
Como la TSM representa la variabilidad total de los datos, cuando ajustamos un modelo de regresión, descomponemos esta variabilidad total en dos partes: SSR y SSE. Esta descomposición es geométricamente interesante porque refleja el teorema de Pitágoras en un espacio de alta dimensión. Esto se debe a que la variabilidad total se divide en dos componentes ortogonales: la variabilidad explicada por el modelo y el error no explicado. Esta interpretación tiene sentido porque la regresión consiste esencialmente en proyectar los datos en un espacio de dimensiones inferiores, que es el espacio que abarcan nuestros predictores. Sigue nuestro curso de Álgebra Lineal para la Ciencia de Datos en R para aprender más sobre conceptos como los subespacios.
En la regresión ridge y la regresión lasso, la descomposición de la TSM en TSS y TSE no sigue la misma relación. Esto se debe a que tanto la cresta como el lazo añaden términos de regularización, o penalizaciones, a sus respectivas funciones de coste, lo que altera la relación. En el caso de las versiones regularizadas de la regresión, la TSM sigue estando bien definida, pero la variabilidad explicada y la variabilidad residual ya no suman la TSM debido al término de regularización. Lee nuestro tutorial Regularización en R: Ridge, Lasso y Elastic Net para saber más.
El R-cuadrado, también conocido como coeficiente de determinación, es una medida estadística importante para evaluar la calidad de ajuste de un modelo de regresión y, por tanto, su poder predictivo. Representa la proporción de la variabilidad de la variable dependiente que puede explicar la variable independiente. El R-cuadrado puede calcularse elevando al cuadrado el coeficiente de correlación r, y también puede calcularse según esta fórmula:
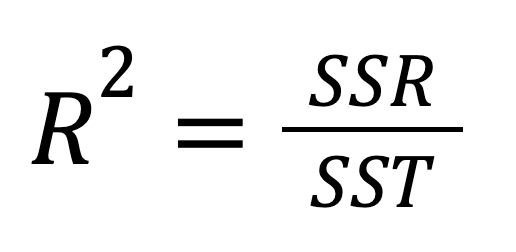
O, alternativamente:
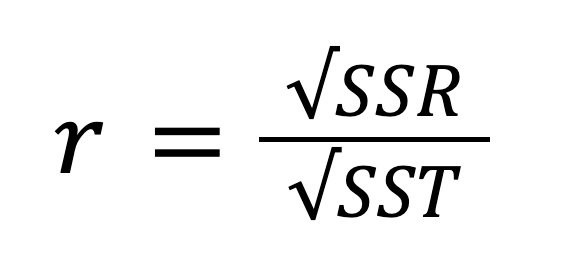
Teniendo en cuenta la relación entre la SST, la SSR y la SSE, la fórmula anterior puede reescribirse como:
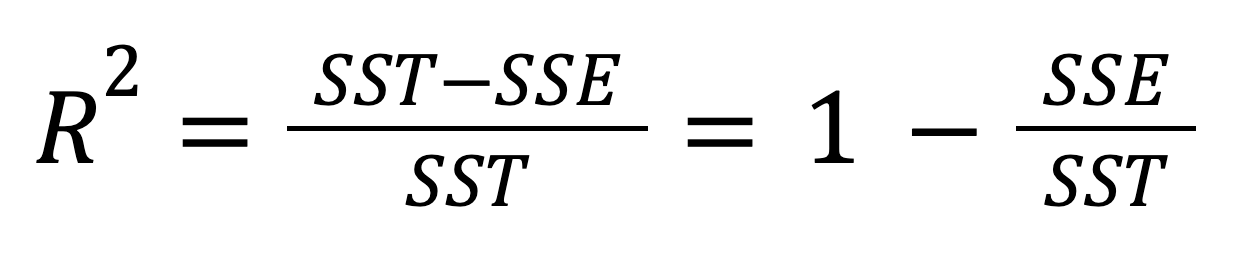
El valor del R-cuadrado puede ser de 0 a 1, ambos inclusive. Si R2 = 0, significa que nuestro modelo de regresión no explica en absoluto ninguna parte de la variabilidad de la variable dependiente. En cambio, si R2 = 1, significa que nuestro modelo de regresión explica perfectamente toda la variabilidad de la variable dependiente. En la práctica, es casi imposible encontrar estos valores extremos; lo más probable es que, en casos reales, veamos algo intermedio.
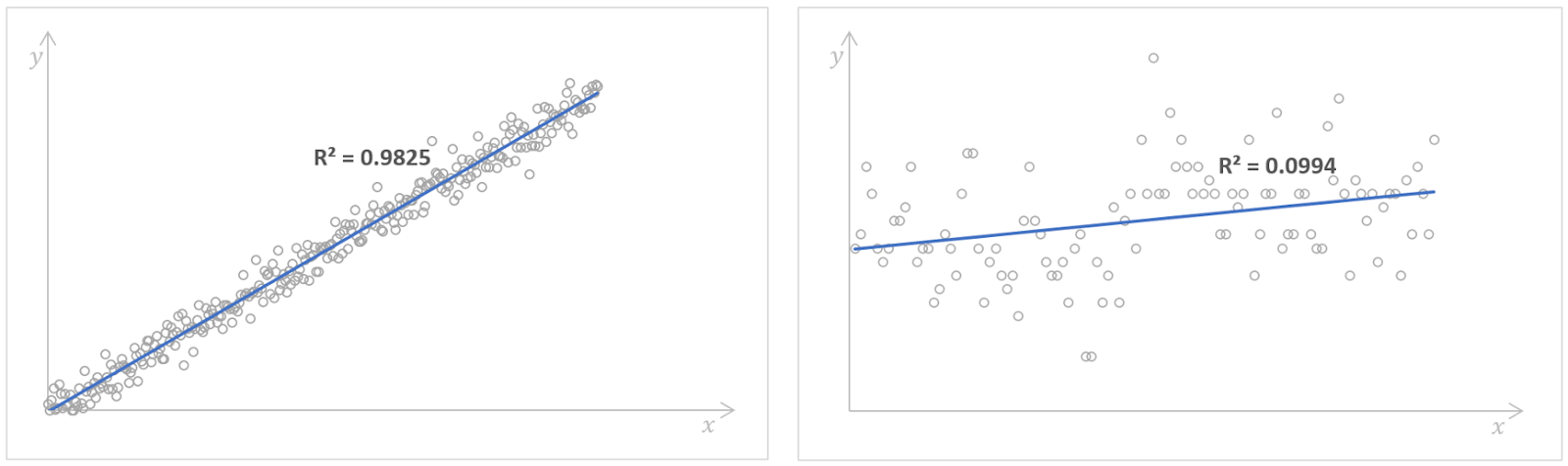
Modelos de regresión con valores altos (izquierda) y bajos (derecha) de la R-cuadrado. Fuente: KaggleNúmero de libros leídos y Kaggle Regresión de la zarigüeya. Imagen del autor.
Un valor elevado de la R-cuadrado indica un buen rendimiento del modelo, lo que significa que la variable dependiente puede predecirse mediante la variable independiente con una gran exactitud. Sin embargo, no existe una regla empírica sobre qué valor de la R-cuadrado debe considerarse suficientemente bueno. Depende de cada caso particular, de los requisitos de precisión de un modelo de regresión y de cuánta variabilidad esperemos ver en los datos. A menudo, también depende del ámbito con el que esté relacionado nuestro análisis de regresión. Por ejemplo, en los campos científicos, buscaríamos un valor de la R-cuadrado superior a 0,8, mientras que en las ciencias sociales, el valor de 0,3 podría ser ya suficientemente bueno.
Como nota final, debemos decir que en la regresión lineal múltiple, es decir, la regresión con más de una variable independiente, a menudo consideramos en su lugar el R-cuadrado ajustado, que es una extensión del R-cuadrado que tiene en cuenta el número de predictores y el tamaño de la muestra.
Aunque hoy en día podemos calcular fácil y rápidamente el SST, el SSR y el SSE en la mayoría de los programas estadísticos y lenguajes de programación, sigue mereciendo la pena comprender realmente lo que significan, su interconexión y, en particular, su importancia en el análisis de regresión. La comprensión de la relación entre los tres componentes de la variabilidad y la R-cuadrada ayuda a los analistas y científicos de datos a mejorar el rendimiento de los modelos minimizando la SSE y maximizando la SSR, para que puedan tomar decisiones informadas sobre sus modelos de regresión.
Para construir una base sólida en estadística y aprender potentes técnicas estadísticas trabajando con datos del mundo real, considera las siguientes pistas de habilidades exhaustivas y aptas para principiantes: Fundamentos deEstadística en Python y Fundamentos de Estadística en R. Por último, si te interesa saber cómo se calculan los coeficientes de regresión, consulta nuestro Tutorial de Ecuación Normal para Regresión Lineal y Descomposición QR en Aprendizaje Automático: Guía detallada.
Aprende con DataCamp
Curso
Curso
Curso
Tutorial
Eladio Montero Porras
Tutorial
Kurtis Pykes
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita

