Cours
Machine Learning for Time Series Data in Python
4 h
53.3K
Le clustering est une technique d'apprentissage automatique non supervisée qui trouve de nombreuses applications dans les domaines de la reconnaissance des formes, de l'analyse d'images, de l'analyse de la clientèle, de la segmentation du marché, de l'analyse des réseaux sociaux, etc. Un grand nombre d'industries utilisent le regroupement, des compagnies aériennes aux soins de santé et bien plus encore.
Il s'agit d'un type d'apprentissage non supervisé, ce qui signifie que nous n'avons pas besoin de données étiquetées pour les algorithmes de regroupement ; c'est l'un des plus grands avantages du regroupement par rapport à d'autres types d'apprentissage supervisé comme la classification. Dans ce tutoriel sur les grappes, vous apprendrez :
Le regroupement est le processus qui consiste à organiser un groupe d'objets de manière à ce que les objets d'un même groupe (appelé regroupement) soient plus semblables les uns aux autres qu'aux objets de tout autre groupe. Les professionnels des données utilisent souvent le regroupement dans la phase d'analyse exploratoire des données pour découvrir de nouvelles informations et de nouveaux modèles dans les données. Le clustering étant un apprentissage automatique non supervisé, il ne nécessite pas d'ensemble de données étiquetées.
Le regroupement lui-même n'est pas un algorithme spécifique, mais la tâche générale à résoudre. Vous pouvez atteindre cet objectif à l'aide de divers algorithmes qui diffèrent considérablement dans leur compréhension de ce qui constitue un groupe et de la manière de les trouver efficacement.
Dans la suite de ce tutoriel, nous comparerons les résultats de différents algorithmes de clustering, puis nous discuterons en détail de 5 algorithmes de clustering essentiels et populaires utilisés aujourd'hui dans l'industrie. Bien que les algorithmes soient essentiellement mathématiques, ce tutoriel sur le clustering vise à développer une compréhension intuitive des algorithmes plutôt qu'une formulation mathématique.
Contrairement aux cas d'utilisation de l'apprentissage supervisé tels que la classification ou la régression, le clustering ne peut pas être complètement automatisé de bout en bout. Il s'agit plutôt d'un processus itératif de découverte d'informations qui nécessite une expertise dans le domaine et un jugement humain fréquemment utilisé pour ajuster les données et les paramètres du modèle afin d'obtenir le résultat souhaité.
Plus important encore, comme le clustering est un apprentissage non supervisé et qu'il n'utilise pas de données étiquetées, nous ne pouvons pas calculer des mesures de performance telles que la précision, l'AUC, la RMSE, etc. pour comparer différents algorithmes ou techniques de prétraitement des données. Par conséquent, il est très difficile et subjectif d'évaluer les performances des modèles de regroupement.
Les principaux critères de réussite des modèles de regroupement sont les suivants :
Avant d'entrer dans les détails de l'algorithme, nous allons développer l'intuition du regroupement à l'aide d'un exemple d'ensemble de données sur les fruits. Supposons que nous disposions d'une vaste collection d'images contenant trois fruits (i) des fraises, (ii) des poires et (iii) des pommes.
Dans l'ensemble de données, toutes les images sont mélangées et votre cas d'utilisation consiste à regrouper les fruits similaires, c'est-à-dire à créer trois groupes contenant chacun un type de fruit. C'est exactement ce que fait un algorithme de regroupement.
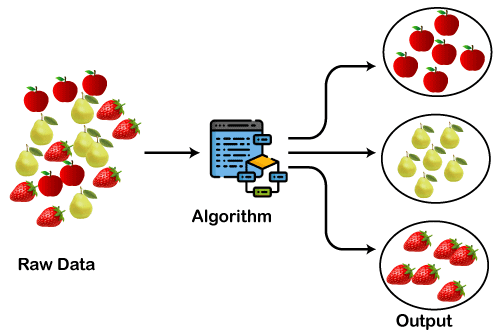
Source de l'image : https://static.javatpoint.com/tutorial/machine-learning/images/clustering-in-machine-learning.png
Le clustering est une technique très puissante qui trouve de nombreuses applications dans divers secteurs, des médias aux soins de santé, en passant par la fabrication et les services, et partout où vous disposez de grandes quantités de données. Examinons quelques cas d'utilisation pratiques :
Les clients sont classés à l'aide d'algorithmes de regroupement en fonction de leur comportement d'achat ou de leurs centres d'intérêt afin de mettre au point des campagnes de marketing ciblées.
Imaginez que vous ayez 10 millions de clients et que vous souhaitiez développer des campagnes de marketing personnalisées ou ciblées. Il est peu probable que vous développiez des campagnes de marketing de 10 millions d'euros, alors que faire ? Nous pourrions utiliser le clustering pour regrouper 10 millions de clients en 25 groupes et concevoir ensuite 25 campagnes de marketing au lieu de 10 millions.
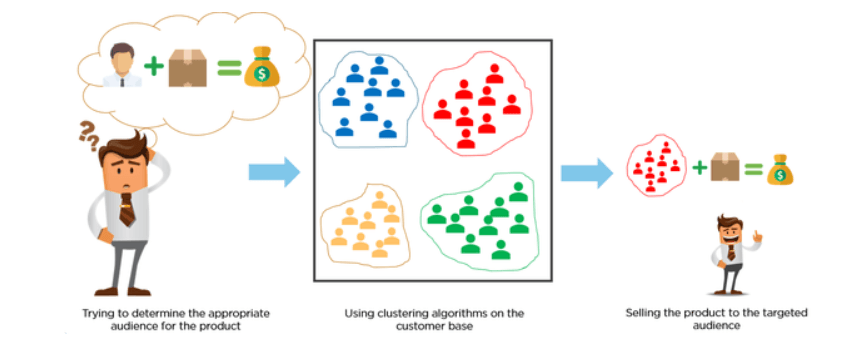
Image Source: https://miro.medium.com/max/845/1*rFATWK6tWBrDJ1o1rzEZ8w.png
Il existe de nombreuses possibilités de regroupement des commerces de détail. Par exemple, vous pouvez collecter des données sur chaque magasin et les regrouper au niveau du magasin pour générer des informations qui vous permettront de savoir quels sont les sites similaires les uns aux autres sur la base d'attributs tels que la fréquentation, les ventes moyennes du magasin, le nombre d'UGS, etc.
Un autre exemple pourrait être le regroupement au niveau d'une catégorie. Dans le diagramme ci-dessous, nous avons huit magasins. Des couleurs différentes représentent des groupes différents. Dans cet exemple, il y a quatre groupes.
Notez que la catégorie des déodorants dans le magasin 1 est représentée par le groupe rouge, tandis que la catégorie des déodorants dans le magasin 2 est représentée par le groupe bleu. Cela montre que le magasin 1 et le magasin 2 ont des marchés cibles complètement différents pour la catégorie des déodorants.
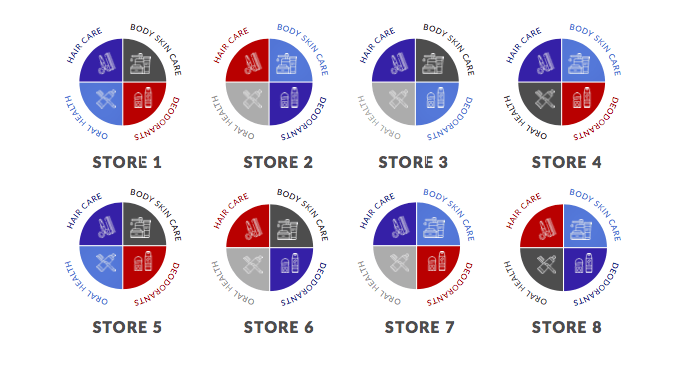
Source de l'image: https://www.dotactiv.com/hs-fs/hubfs/Category-based%20clustering.png?width=1038&height=557&name=Category-based%20clustering.png
Les soins de santé et les sciences cliniques sont à nouveau l'un des domaines qui offrent de nombreuses possibilités de regroupement ayant un impact considérable sur le terrain. Un exemple est la recherche publiée par Komaru & Yoshida et al. 2020, où ils ont recueilli les données démographiques et de laboratoire de 101 patients qu'ils ont ensuite répartis en trois groupes.
Chaque groupe a été représenté par des conditions différentes. Par exemple, le groupe 1 comprend des patients présentant une faible numération leucocytaire et un faible taux de CRP. Le groupe 2 comprend des patients dont le taux de BMP et de sérum est élevé, et le groupe 3, des patients dont le taux de sérum est faible. Chaque groupe représente une trajectoire de survie différente compte tenu de la mortalité à un an après l'hémodialyse.
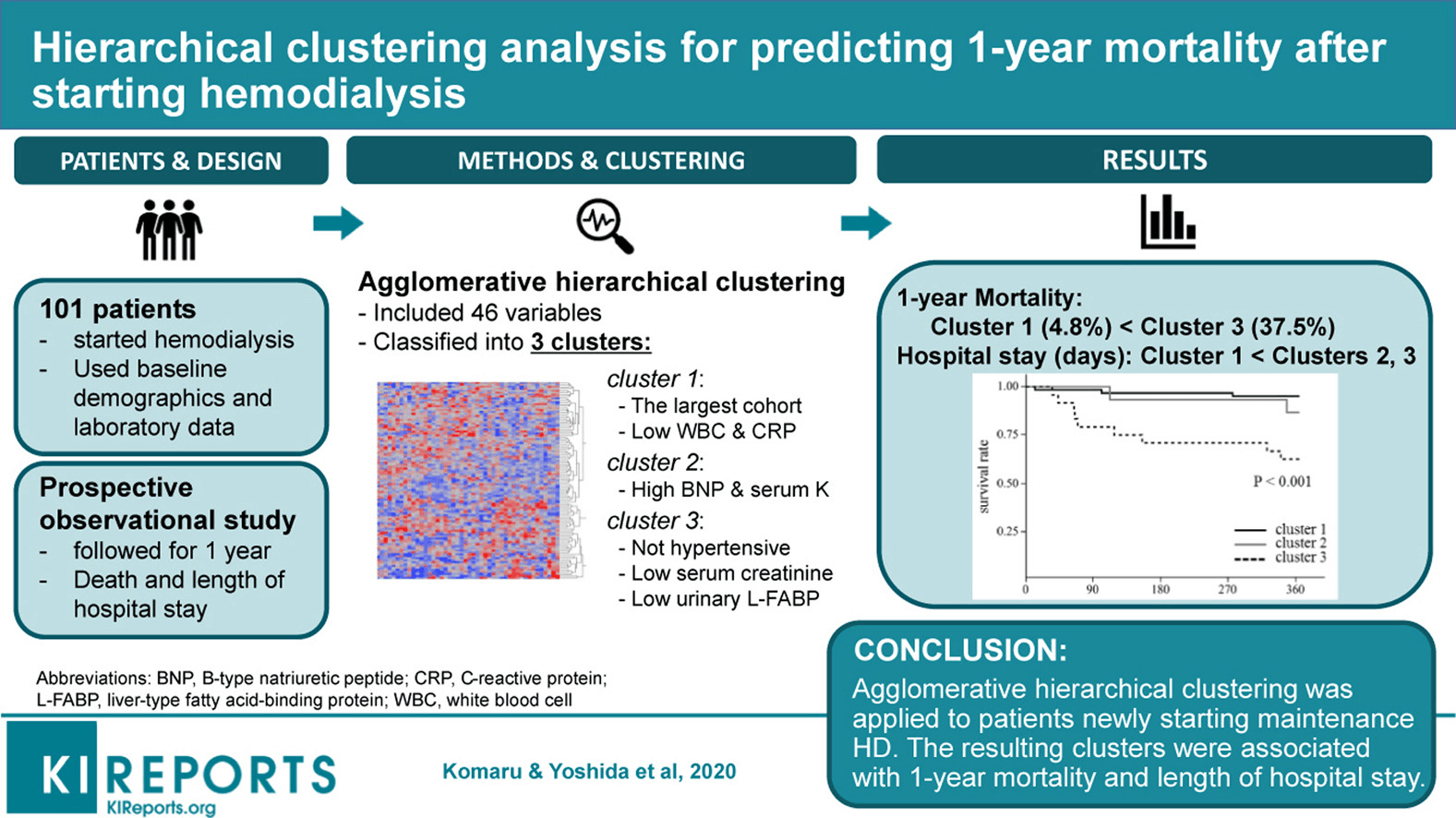
Source de l'image : https://els-jbs-prod-cdn.jbs.elsevierhealth.com/cms/attachment/da4cb0c9-0a86-4702-8a78-80ffffcf1f9c/fx1_lrg.jpg
La segmentation d'une image est la classification d'une image en différents groupes. De nombreuses recherches ont été effectuées dans le domaine de la segmentation d'images à l'aide du regroupement. Ce type de regroupement est utile si vous souhaitez isoler des objets dans une image afin d'analyser chaque objet individuellement pour en vérifier la nature.
Dans l'exemple ci-dessous, la partie gauche représente l'image originale et la partie droite est le résultat de l'algorithme de regroupement. Vous pouvez clairement voir qu'il y a 4 groupes qui correspondent à 4 objets différents dans l'image, déterminés sur la base des pixels (tigre, herbe, eau et sable).
|
Vous voulez démarrer votre carrière Maîtriser les compétences essentielles pour décrocher un emploi de scientifique spécialisé dans l'apprentissage automatique ? Découvrez ces cours incroyables de DataCamp Machine Learning Scientist with Python et Machine Learning Scientist with R. |
Il existe 10 algorithmes de clustering non supervisés mis en œuvre dans scikit-learn - une bibliothèque populaire d'apprentissage automatique en Python. Il existe des différences fondamentales sous-jacentes dans la manière dont chaque algorithme détermine et affecte les grappes dans l'ensemble de données.
Les différences sous-jacentes dans la modalité mathématique de ces algorithmes se résument à quatre aspects sur lesquels nous pouvons comparer et opposer ces algorithmes :
Concentrons-nous sur les résultats de ces algorithmes. Dans le diagramme ci-dessous, chaque colonne représente un résultat d'un algorithme de regroupement différent, tel que KMeans, Affinity Propagation, MeanShift, etc. Au total, 10 algorithmes sont formés sur le même ensemble de données.
Certains algorithmes ont donné le même résultat. Vous remarquerez que le regroupement agglomératif, DBSCAN, OPTICS et le regroupement spectral ont produit les mêmes grappes.
Toutefois, si vous comparez les résultats de KMeans avec ceux de l'algorithme MeanShift, vous remarquerez que les deux algorithmes donnent des résultats différents. Dans le cas de KMeans, il n'y a que deux groupes (clusters : bleu et orange), alors que dans le cas de MeanShift, il y en a trois : bleu, vert et orange.

Image Source: https://scikit-learn.org/stable/_images/sphx_glr_plot_cluster_comparison_001.png
Malheureusement (ou heureusement), il n'y a pas de bonne ou de mauvaise réponse en matière de regroupement. Il aurait été si simple de déterminer et de faire une déclaration telle que "L'algorithme X est le plus performant ici".
Cela n'est pas possible et c'est pour cette raison que le regroupement est une tâche très difficile.
En fin de compte, le choix de l'algorithme le plus performant ne dépend pas d'un paramètre facilement mesurable, mais plutôt de l'interprétation et de l'utilité des résultats pour le cas d'utilisation en question.
L'algorithme de regroupement K-Means est l'algorithme le plus populaire et le plus largement utilisé pour les tâches de regroupement. C'est principalement en raison de l'intuition et de la facilité de mise en œuvre. Il s'agit d'un algorithme basé sur le centroïde, dans lequel l'utilisateur doit définir le nombre de grappes qu'il souhaite créer.
Cela provient normalement d'un cas d'utilisation professionnelle ou de l'essai de différentes valeurs pour le nombre de grappes, puis de l'évaluation des résultats.
Le regroupement K-Means est un algorithme itératif qui crée des grappes qui ne se chevauchent pas, ce qui signifie que chaque instance de votre ensemble de données ne peut appartenir qu'à une seule grappe. La façon la plus simple de comprendre l'algorithme K-Means est d'en comprendre les étapes à l'aide de l'exemple de diagramme ci-dessous. Vous pouvez également obtenir une description détaillée du processus dans nos tutoriels K-Means Clustering in Python et K-Means Clustering in R.
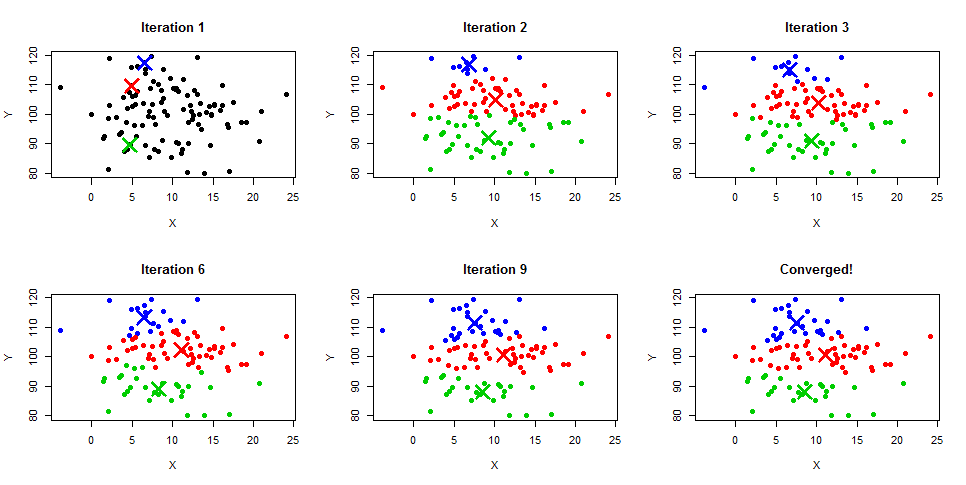
Source de l'image : https://www.learnbymarketing.com/wp-content/uploads/2015/01/method-k-means-steps-example.png
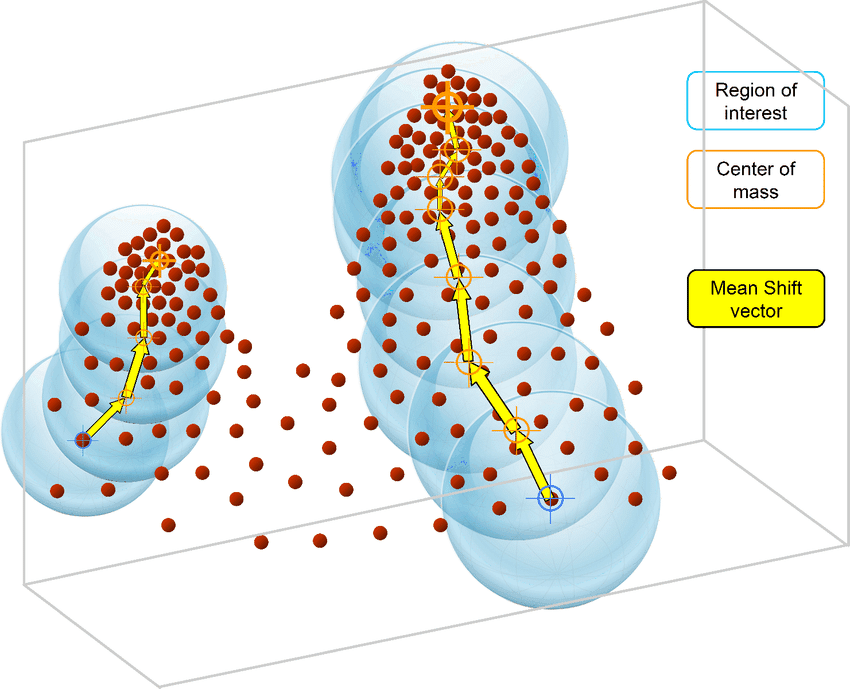
Contrairement à l'algorithme K-Means, l'algorithme MeanShift ne nécessite pas de spécifier le nombre de grappes. L'algorithme lui-même détermine automatiquement le nombre de grappes, ce qui constitue un avantage considérable par rapport à K-Means si vous n'êtes pas sûr de la structure des données.
MeanShift est également basé sur les centroïdes et affecte itérativement chaque point de données à des grappes. Le cas d'utilisation le plus courant du regroupement MeanShift est celui des tâches de segmentation d'images.
L'algorithme MeanShift est basé sur l'estimation de la densité du noyau. Comme l'algorithme K-Means, l'algorithme MeanShift assigne itérativement chaque point de données vers le centroïde de cluster le plus proche qui est initialisé de manière aléatoire et chaque point est déplacé itérativement dans l'espace en fonction de l'endroit où se trouvent le plus de points, c'est-à-dire le mode (le mode est la densité la plus élevée de points de données dans la région, dans le contexte du MeanShift).
C'est pourquoi l'algorithme MeanShift est également connu sous le nom d'algorithme de recherche de mode. Les étapes de l'algorithme MeanShift sont les suivantes :
DBSCAN (Density-Based Spatial Clusteringof Applicationswith Noise) est un algorithme de regroupement non supervisé qui part du principe que les regroupements sont des espaces denses dans la région, séparés par des régions de moindre densité.
Le plus grand avantage de cet algorithme par rapport à K-Means et MeanShift est qu'il est robuste aux valeurs aberrantes, ce qui signifie qu'il n'inclura pas les points de données aberrantes dans un groupe.
Les algorithmes DBSCAN ne nécessitent que deux paramètres de la part de l'utilisateur :
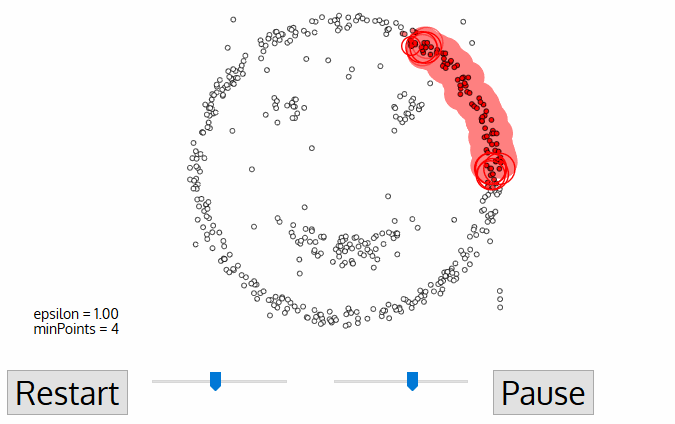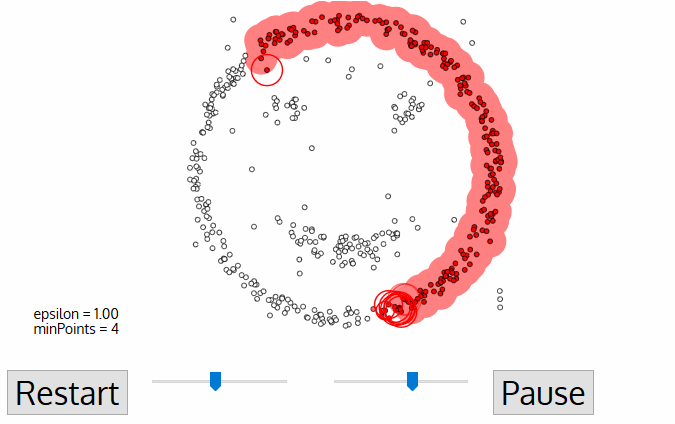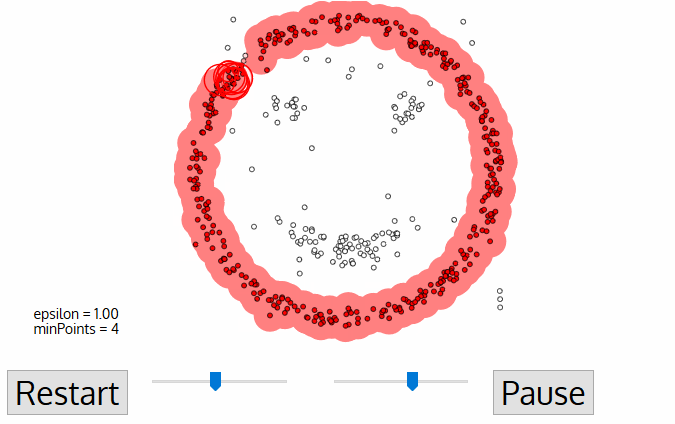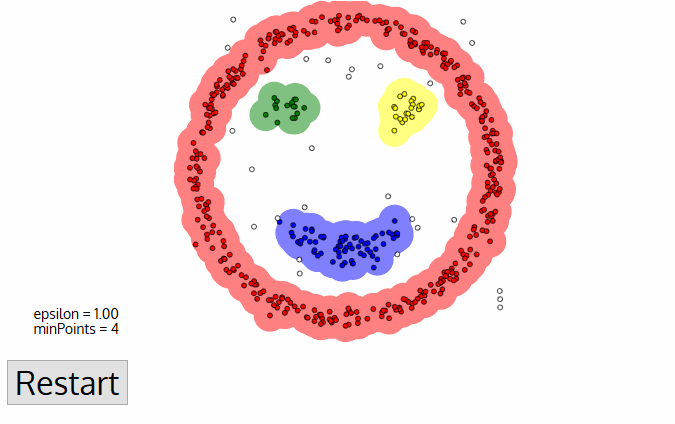
Chaque point de données est entouré d'un cercle d'un rayon de epsilon, et DBSCAN les identifie comme étant soit un point central, soit un point de bordure, soit un point de bruit. Un point de données est considéré comme un point central si le cercle qui l'entoure comporte un nombre minimum de points spécifié par le paramètre minPoints.
Il est considéré comme un point limite si le nombre de points est inférieur au minimum requis, et il est considéré comme bruyant s'il n'y a pas de points de données supplémentaires situés dans un rayon d'epsilon autour d'un point de données. Les points de données bruitées ne sont classés dans aucun groupe (il s'agit en fait de valeurs aberrantes).
Voici quelques-uns des cas d'utilisation courants de l'algorithme de regroupement DBSCAN :
Si l'on compare les algorithmes DBSCAN et K-Means, les différences les plus courantes sont les suivantes :
Vous pouvez en savoir plus sur DBSCAN en Python dans notre tutoriel.
Source de l'image : https://miro.medium.com/proxy/1*tc8UF-h0nQqUfLC8-0uInQ.gif
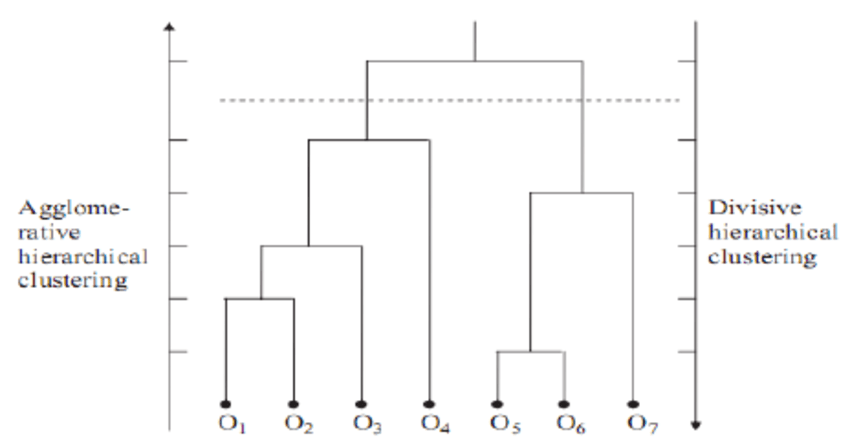
Le clustering hiérarchique est une méthode de clustering qui construit une hiérarchie de clusters. Il existe deux types de méthodes.
Lorsqu'il s'agit d'analyser des données provenant de réseaux sociaux, le regroupement hiérarchique est de loin la méthode de regroupement la plus courante et la plus populaire. Les nœuds (branches) du graphique sont comparés les uns aux autres en fonction du degré de similitude qui existe entre eux. En reliant de plus petits groupes de nœuds liés les uns aux autres, il est possible de créer des groupes plus importants.
Le principal avantage du regroupement hiérarchique est qu'il est facile à comprendre et à mettre en œuvre. En général, le résultat de cette méthode de regroupement est analysé sous la forme d'une image telle que celle présentée ci-dessous. Il s'agit d'un dendrogramme.
Vous pouvez en savoir plus sur le clustering hiérarchique et le clustering K-Means dans notre tutoriel sur le clustering hiérarchique en Python.
BIRCH signifie Balanced Iterative Hierarchical Based Clustering (groupement hiérarchique itératif équilibré). Il est utilisé sur de très grands ensembles de données pour lesquels K-Means ne peut pas s'adapter de manière pratique. L'algorithme BIRCH divise les données volumineuses en petits groupes et tente de conserver le maximum d'informations possible. Les petits groupes sont ensuite regroupés pour obtenir un résultat final au lieu de regrouper directement les grands ensembles de données.
BIRCH est souvent utilisé pour compléter d'autres algorithmes de regroupement en générant un résumé des informations que les autres algorithmes de regroupement peuvent utiliser. Les utilisateurs doivent définir le nombre de grappes pour l'entraînement de l'algorithme BIRCH, de la même manière que nous le définissons dans K-Means.
L'un des avantages de l'utilisation de BIRCH est qu'il permet de regrouper progressivement et dynamiquement des points de données multidimensionnels. Cela permet de créer des grappes de la plus haute qualité dans des conditions de mémoire et de temps données. Dans la plupart des cas, BIRCH n'a besoin d'effectuer qu'une seule recherche dans la base de données, ce qui rend BIRCH évolutif.
Le cas d'utilisation le plus courant de l'algorithme de regroupement BIRCH est qu'il s'agit d'une alternative à KMeans efficace en termes de mémoire qui peut être utilisée pour regrouper de grands ensembles de données qui ne peuvent pas être traités par KMeans en raison de limitations en termes de mémoire ou de calcul.
Le clustering est une technique d'apprentissage automatique très utile, mais elle n'est pas aussi simple que certains cas d'utilisation de l'apprentissage supervisé tels que la classification et la régression. Cela s'explique principalement par le fait que l'évaluation des performances et de la qualité du modèle est difficile et qu'il existe certains paramètres critiques, tels que le nombre de grappes, que l'utilisateur doit définir correctement pour obtenir des résultats significatifs.
Cependant, il existe des tonnes de cas d'utilisation du clustering dans un large éventail d'industries, et il s'agit d'une compétence importante même pour les data scientists, les ingénieurs en apprentissage automatique et les analystes de données.
Si vous souhaitez en savoir plus sur le Clustering et l'apprentissage automatique non supervisé et apprendre la mise en œuvre à l'aide des langages Python et R, les cours ci-dessous peuvent vous aider à progresser :
Cours pour l'apprentissage automatique
Cours
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
9 min
Tutoriel
Samuel Shaibu
Tutoriel
Tutoriel
Sejal Jaiswal

