Cours
Fondamentaux de la probabilité en R
4 h
42.2K
Imaginez que vous développiez un système de détection de spam pour le courrier électronique. Dans un premier temps, vous pouvez signaler un courriel comme suspect s'il contient certains mots-clés. Mais que se passe-t-il si vous découvrez que cet e-mail provient d'un expéditeur de confiance ? Ou si elle a été envoyée à une heure inhabituelle ? Chaque nouvelle information modifie la probabilité que l'e-mail soit un spam. Cette mise à jour dynamique des probabilités sur la base de nouvelles preuves est au cœur de la probabilité conditionnelle, un concept qui alimente de nombreuses applications modernes de la science des données, du filtrage des courriers électroniques à la détection des fraudes.
Pour ceux qui débutent dans les concepts de probabilités, l'Aide-mémoire sur l'introduction aux règles de probabilités constitue une référence utile pour les principes et les formules de base. Le cours d'introduction aux statistiques construit une base solide en explorant les distributions de probabilité et leurs propriétés, qui constituent la base de la compréhension du fonctionnement des probabilités conditionnelles dans la pratique. Ces ressources offrent une voie structurée pour développer des bases solides dans les concepts que nous allons explorer dans cet article.
La probabilité conditionnelle mesure la probabilité qu'un événement se produise lorsque l'on sait qu'un autre événement a déjà eu lieu. Lorsque nous recevons de nouvelles informations sur un événement, nous ajustons nos calculs de probabilité en conséquence.
Pour comprendre ce concept, prenons un exemple avec des cartes à jouer. Lorsque vous tirez une carte d'un jeu standard, il y a 52 résultats possibles. Si vous voulez tirer un roi, votre probabilité initiale est de 4/52 (environ 7,7 %) puisqu'il y a quatre rois dans le jeu. Mais que se passe-t-il si quelqu'un vous dit que la carte que vous avez tirée est une carte cachée ? Cette nouvelle information change tout - votre probabilité d'avoir un roi est maintenant beaucoup plus élevée, à 4/12 (environ 33,3 %), puisqu'il n'y a que douze cartes faces au total.
Cette relation entre les probabilités a une définition mathématique précise :
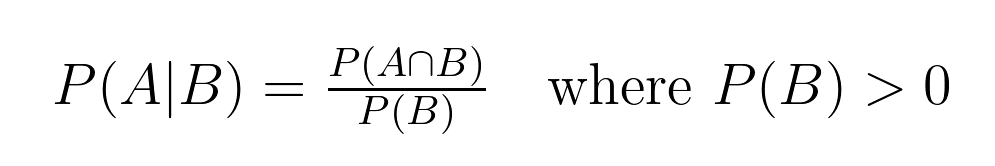
Cette formule nous aide à calculer la probabilité conditionnelle, où :
Dans notre exemple de carte :
Pour mieux comprendre le fonctionnement pratique des probabilités conditionnelles, nous pouvons utiliser un diagramme en arbre. Les diagrammes en arbre sont particulièrement utiles car ils montrent comment chaque nouvelle information modifie nos probabilités :
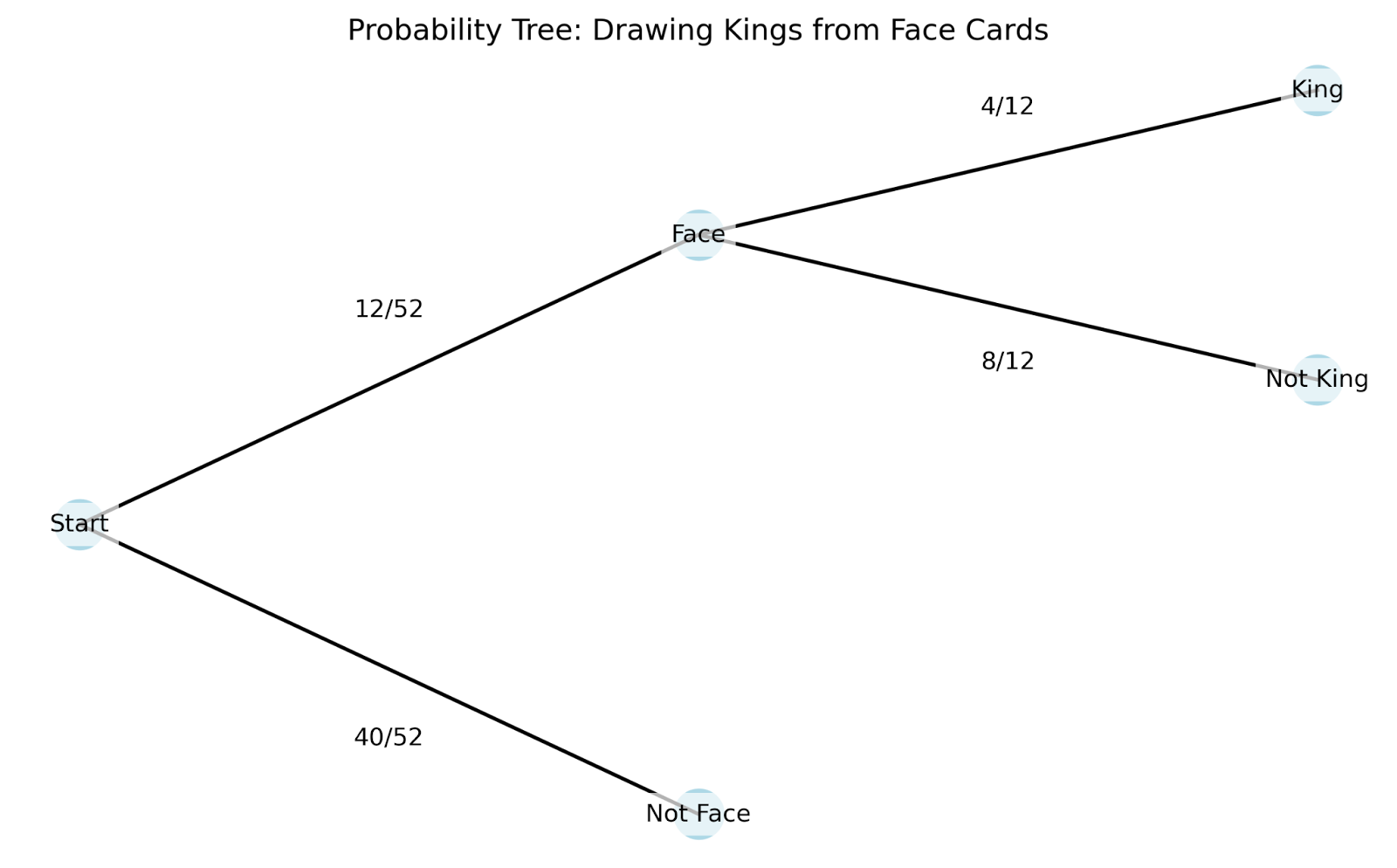
Voyons comment fonctionne ce diagramme en arbre :
Le diagramme en arbre nous aide à comprendre plusieurs concepts clés de la probabilité conditionnelle :
L'intérêt de la probabilité conditionnelle est qu'elle nous permet d'actualiser nos probabilités au fur et à mesure que nous obtenons de nouvelles informations. Tout comme nous avons ajusté notre probabilité d'avoir un roi de 7,7 % à 33,3 % lorsque nous avons appris que nous avions une carte visible, la probabilité conditionnelle nous donne un moyen formel de recalculer les probabilités sur la base de nouveaux éléments.
La structure mathématique de la probabilité conditionnelle nous fournit des outils pour analyser des scénarios complexes impliquant plusieurs événements. Examinons les principales propriétés.
Ces propriétés mathématiques nous aident à résoudre des problèmes complexes de manière plus efficace :
Lorsque deux événements A et B sont indépendants, nous savons que l'occurrence de l'un n'affecte pas la probabilité de l'autre. Mathématiquement, c'est le cas : P(A|B) = P(A), ce qui signifie : "la probabilité de A étant donné B est égale à la probabilité de A".
Par exemple, si nous lançons un dé et que nous tirons à pile ou face, le fait d'obtenir face ne change pas la probabilité d'obtenir un six. La formule nous l'indique : P(Six|Têtes) = P(Six) = 1/6
Pour tout événement A étant donné une condition B, la somme des probabilités de A et de son complément A' (lire "A premier") doit être égale à 1. Mathématiquement, c'est le cas : P(A|B) + P(A'|B) = 1, ce qui se lit comme suit : "La probabilité de A étant donné B plus la probabilité du complément de A étant donné B est égale à 1.
Dans notre exemple de carte précédent : P(Roi|Carte à face) + P(Pas Roi|Carte à face) = 4/12 + 8/12 = 1
La règle de multiplication relie les probabilités conjointes aux probabilités conditionnelles : P(A ∩ B) = P(A|B) × P(B). Nous disons : "La probabilité d'une intersection A-B est égale à la probabilité d'une intersection A-B multipliée par la probabilité d'une intersection B".
Cette règle s'étend à plusieurs événements par le biais de la règle de la chaîne. Pour trois événements A, B et C : P(A ∩ B ∩ C) = P(A|B ∩ C) × P(B|C) × P(C). En d'autres termes, "La probabilité de l'intersection A - B - C est égale à la probabilité de l'intersection A - B - C multipliée par la probabilité de l'intersection B - C multipliée par la probabilité de l'intersection C".
Voyons cela en action avec une séquence de tirage de cartes :
P(K ∩ Q ∩ A) = P(A|K ∩ Q) × P(Q|K) × P(K) = (4/50) × (4/51) × (4/52)
La règle de la chaîne est particulièrement utile dans l'apprentissage automatique, notamment dans les réseaux bayésiens où nous devons modéliser des dépendances complexes entre plusieurs variables. Lorsque nous analysons des données, nous rencontrons souvent des situations où les événements suivent une séquence naturelle, et la règle de la chaîne nous aide à décomposer ces scénarios complexes en calculs plus simples et plus faciles à gérer.
Passons en revue deux des exemples les plus courants et réfléchissons également à la manière dont les probabilités conditionnelles peuvent apparaître dans votre travail.
Ces deux exemples sont très courants et méritent d'être étudiés, surtout si vous passez un entretien :
Lorsque nous lançons un dé, notre espace d'échantillonnage commence par six possibilités : {1, 2, 3, 4, 5, 6}. Le fait d'apprendre des informations partielles sur le lancer modifie nos calculs de probabilité d'une manière spécifique. Voyons comment :
Probabilité initiale d'obtenir un 6 : P(6) = 1/6
Si nous apprenons que le résultat est pair, notre espace d'échantillonnage se réduit à {2, 4, 6} : P(6 | pair) = 1/3
Un sac contient 5 billes bleues et 3 billes rouges. Lorsque nous tirons des billes sans remplacement, chaque tirage affecte les probabilités des tirages suivants.
Premier tirage - probabilité de bleu : P(blue₁) = 5/8
Deuxième tirage, le premier étant bleu : P(bleu₂ | bleu₁) = 4/7
Cet exemple complète notre précédent exemple de carte en mettant en évidence les dépendances séquentielles.
Les tests médicaux constituent une application parfaite de la probabilité conditionnelle dans l'évaluation de la précision des tests. Pour tout test de diagnostic, nous devons comprendre quatre probabilités conditionnelles essentielles :
Lors de l'évaluation des performances de ce test, les professionnels de la santé utilisent ces probabilités conditionnelles pour.. :
Par exemple, si nous testons 1000 patients et obtenons 100 résultats positifs, nous pouvons utiliser ces probabilités conditionnelles pour estimer le nombre de vrais positifs par rapport aux faux positifs. Cette analyse aide les professionnels de la santé à mettre en balance les risques de passer à côté d'un diagnostic et les coûts et l'anxiété liés aux fausses alertes.
Les entreprises d'investissement utilisent la probabilité conditionnelle pour évaluer les risques du marché. Prenons le cas d'un gestionnaire de portefeuille qui suit la volatilité du marché :
La volatilité quotidienne du marché peut être faible (L), moyenne (M) ou élevée (H).
Les données historiques le montrent :
Ces informations aident les gestionnaires :
Notre exploration des tests médicaux a mis en évidence une distinction importante : La probabilité d'être atteint d'une maladie en cas de test positif diffère de la probabilité d'être testé positif en cas de maladie. Le théorème de Bayes fournit un cadre formel pour naviguer dans cette relation, ce qui nous permet de mettre à jour nos estimations de probabilité au fur et à mesure que de nouvelles preuves apparaissent.
Le théorème de Bayes exprime la relation entre deux probabilités conditionnelles : P(A|B) = [P(B|A) × P(A)] / P(B). Nous lisons cette équation de la manière suivante : "La probabilité de A étant donné B est égale à la probabilité de B étant donné A multipliée par la probabilité de A, divisée par la probabilité de B."
Chaque composant joue un rôle :
Voyons comment cela fonctionne en pratique avec notre scénario de test médical, maintenant élargi pour montrer l'analyse bayésienne complète.
Prenons l'exemple d'une maladie qui touche 2 % de la population. Un nouveau test de diagnostic a été mis au point :
Lorsqu'un patient est testé positif, comment devons-nous actualiser notre opinion sur son état de santé ?
Résolvons ce problème étape par étape :
Cette analyse révèle que même avec un test positif, la probabilité d'être atteint de la maladie n'est que d'environ 16,2 % - ce qui est beaucoup plus élevé que les 2 % initiaux, mais peut-être moins que ce que l'intuition pourrait suggérer.
Le théorème de Bayes s'impose lorsque nous recevons plusieurs éléments de preuve. La probabilité postérieure de chaque calcul devient la probabilité antérieure pour la prochaine mise à jour. Par exemple, si notre patient obtient un deuxième test positif :
Cette mise à jour séquentielle fournit un cadre mathématique pour l'intégration de nouvelles données dans nos estimations de probabilité. La beauté de l'inférence bayésienne réside dans sa capacité à quantifier l'évolution de nos croyances au fur et à mesure que nous recueillons de nouvelles informations, en fournissant une méthode formelle de mise à jour des probabilités à la lumière des preuves.
Voyons comment la probabilité conditionnelle apparaît dans la science des données.
Le classificateur Naive Bayes, l'un des outils les plus simples et les plus puissants de l'apprentissage automatique, applique le théorème de Bayes pour prédire les catégories sur la base des probabilités des caractéristiques. Lors de la classification d'un courrier électronique en tant que spam ou non, par exemple, l'algorithme calcule la probabilité conditionnelle qu'un courrier électronique soit un spam compte tenu des mots qu'il contient. Bien qu'elle repose sur l'hypothèse "naïve" que les caractéristiques sont indépendantes, cette simplification fonctionne souvent étonnamment bien dans la pratique.
Les arbres de décision adoptent une approche différente de la probabilité conditionnelle, en divisant les données sur la base des valeurs des caractéristiques pour créer des sous-ensembles conditionnels. À chaque nœud, l'arbre pose des questions telles que "Quelle est la probabilité de notre variable cible compte tenu de cette valeur de caractéristique spécifique ?" Ces divisions se poursuivent jusqu'à ce que nous atteignions des sous-ensembles purs ou presque purs, créant ainsi une carte de probabilités conditionnelles qui guide nos prédictions.
Les systèmes d'évaluation du crédit utilisent des probabilités conditionnelles pour évaluer la probabilité de défaillance d'un prêt en fonction de diverses caractéristiques du client. Par exemple, une banque peut calculer la probabilité d'un défaut de paiement en fonction du niveau de revenu, des antécédents de crédit et de la situation professionnelle. Ces calculs deviennent plus sophistiqués lorsque l'on considère des risques dépendants multiples, comme la manière dont la probabilité de défaut de paiement d'un prêt hypothécaire pourrait changer en cas de récession et de hausse des taux d'intérêt. Les modèles de risque d'investissement utilisent des probabilités conditionnelles pour estimer la valeur à risque (VaR), en calculant la probabilité de niveaux de perte spécifiques compte tenu des conditions actuelles du marché. Les gestionnaires de portefeuille utilisent ces probabilités conditionnelles pour ajuster la répartition des actifs, en comprenant comment le risque d'un investissement peut changer en fonction de la performance des autres investissements du portefeuille.
Les réseaux bayésiens représentent l'application la plus directe de la probabilité conditionnelle dans l'apprentissage automatique. Ils modélisent les relations entre les variables sous la forme d'un graphe orienté où l'état de chaque nœud dépend de ses parents. Ces réseaux excellent dans des tâches telles que le diagnostic médical, où la probabilité de diverses affections dépend de multiples symptômes et résultats de tests interconnectés.
Les modèles graphiques probabilistes utilisent des dépendances conditionnelles pour représenter des relations complexes dans les données, ce qui les rend précieux pour des tâches telles que la reconnaissance d'images et le traitement du langage naturel. Même les modèles d'apprentissage profond, bien qu'ils ne soient pas explicitement probabilistes, émettent des probabilités conditionnelles dans leurs couches finales lorsqu'ils effectuent des classifications. La fonction softmax, couramment utilisée dans les réseaux neuronaux, transforme les scores bruts en probabilités conditionnelles, nous indiquant la probabilité de chaque classe possible compte tenu des données d'entrée.
Lorsque l'on travaille sur les probabilités conditionnelles, trois idées fausses principales conduisent souvent à des conclusions erronées.
Enfin, examinons quelques idées plus complexes qui s'appuient sur ce que nous avons pratiqué.
Lorsque nous passons des distributions de probabilités discrètes aux distributions continues, nous rencontrons un défi intéressant : certains points d'une distribution continue ont une probabilité nulle. Prenons l'exemple de la mesure de la taille exacte d'une personne : alors que nous pourrions dire que la probabilité qu'une personne mesure entre 170 et 171 centimètres est significative, la probabilité qu'une personne mesure exactement 170,5432... centimètres est techniquement nulle. Pourtant, nous voulons souvent conditionner des mesures aussi précises. Les probabilités conditionnelles régulières fournissent un cadre mathématique pour traiter ces situations, en étendant nos concepts de base aux cas continus grâce à l'utilisation des fonctions de densité et de la théorie des mesures. Cette extension nous permet de donner un sens à des énoncés tels que "la distribution de probabilité du poids d'une personne, étant donné qu'elle mesure exactement 170,5 centimètres".
La conditionnalisation de Jeffrey étend la probabilité conditionnelle traditionnelle aux situations dans lesquelles notre nouvelle preuve n'est pas certaine mais s'accompagne de sa propre probabilité. Contrairement au conditionnement standard, qui suppose une certitude absolue quant aux nouvelles informations, la règle de Jeffrey nous permet d'actualiser nos croyances sur la base de preuves incertaines. Cela correspond mieux aux scénarios du monde réel où les nouvelles informations sont souvent accompagnées d'un certain degré d'incertitude. Par exemple, plutôt que de savoir avec certitude qu'un test médical est positif, nous pourrions apprendre qu'il a 80 % de chances d'être positif. La règle de Jeffrey fournit une méthode formelle pour mettre à jour les probabilités dans ces situations plus nuancées.
La probabilité conditionnelle fournit un cadre mathématique pour la mise à jour de nos croyances au fur et à mesure de l'apparition de nouvelles informations. Tout au long de cet article, nous avons vu comment ce concept s'applique à différents domaines, du diagnostic médical à l'évaluation des risques financiers. Les principes que nous avons explorés nous aident à comprendre comment les probabilités changent avec de nouvelles preuves, ce qui permet de prendre des décisions plus éclairées dans les applications de la science des données. Cette compréhension devient particulièrement précieuse lorsque vous travaillez avec des algorithmes de classification, des modèles de risque et des systèmes d'apprentissage automatique où les mises à jour des probabilités se font en continu.
Alors que vous continuez à développer votre expertise en matière de probabilités et d'inférence statistique, plusieurs cours peuvent améliorer votre compréhension de ces concepts dans une optique bayésienne. Notre cours Fundamentals of Bayesian Data Analysis in R présente les principes clés et leurs applications pratiques, tandis que notre cours Bayesian Modeling with RJAGS montre comment mettre en œuvre ces concepts à l'aide d'outils statistiques puissants. Pour les utilisateurs de Python, notre cours Analyse de données bayésiennes en Python offre une expérience pratique de l'application de ces méthodes à des problèmes réels. Chaque cours vous permet d'approfondir votre connaissance des probabilités et de leurs applications dans la science des données moderne.
Apprenez avec DataCamp
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min