Curso
Fundamentos de Probabilidade em R
4 h
42.2K
Imagine que você está desenvolvendo um sistema de detecção de spam para e-mail. Inicialmente, você pode marcar um e-mail como suspeito se ele contiver determinadas palavras-chave. Mas e se você descobrir que esse e-mail veio de um remetente confiável? Ou se ela foi enviada em um horário incomum? Cada nova informação altera a probabilidade de o e-mail ser spam. Essa atualização dinâmica das probabilidades com base em novas evidências está no cerne da probabilidade condicional, um conceito que impulsiona muitos aplicativos modernos de ciência de dados, desde a filtragem de e-mails até a detecção de fraudes.
Para aqueles que estão iniciando sua jornada com os conceitos de probabilidade, a Folha de dicas de introdução às regras de probabilidade oferece uma referência útil para os princípios e fórmulas fundamentais. O curso de Introdução à Estatística constrói uma base sólida ao explorar as distribuições de probabilidade e suas propriedades, que formam a base para você entender como a probabilidade condicional funciona na prática. Esses recursos oferecem um caminho estruturado para que você desenvolva fundamentos sólidos nos conceitos que exploraremos neste artigo.
A probabilidade condicional mede a probabilidade de um evento ocorrer quando sabemos que outro evento já ocorreu. Quando recebemos novas informações sobre um evento, ajustamos nossos cálculos de probabilidade de acordo.
Para entender esse conceito, vamos explorar um exemplo com cartas de baralho. Quando você tira uma carta de um baralho padrão, há 52 resultados possíveis. Se você quiser tirar um rei, sua probabilidade inicial é de 4/52 (cerca de 7,7%), pois há quatro reis no baralho. Mas o que acontece se alguém lhe disser que a carta que você tirou é uma carta com cara? Essa nova informação muda tudo - a probabilidade de você ter um rei agora é muito maior, 4/12 (cerca de 33,3%), já que há apenas doze cartas com figuras no total.
Essa relação entre as probabilidades tem uma definição matemática precisa:
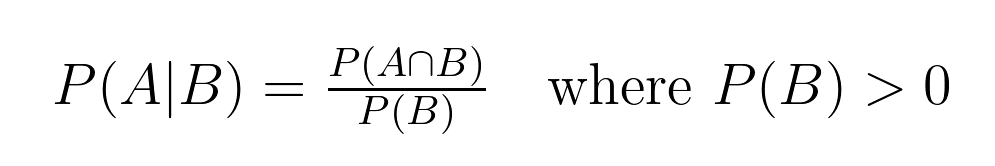
Essa fórmula nos ajuda a calcular a probabilidade condicional, em que:
Em nosso exemplo de cartão:
Para entender melhor como a probabilidade condicional funciona na prática, podemos usar um diagrama de árvore. Os diagramas de árvore são particularmente úteis porque mostram como cada nova informação altera nossas probabilidades:
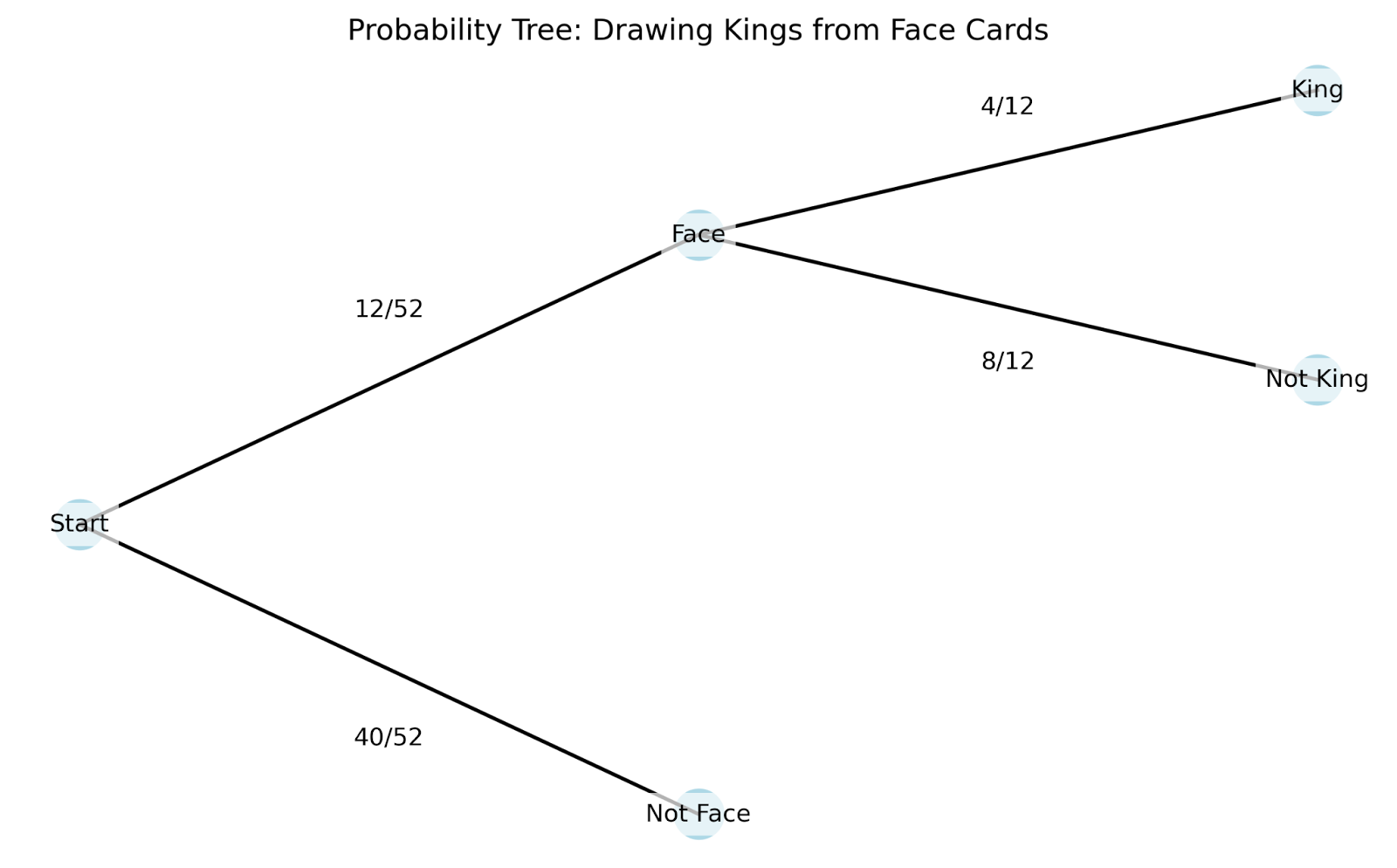
Vamos ver como esse diagrama de árvore funciona:
O diagrama de árvore nos ajuda a entender vários conceitos-chave da probabilidade condicional:
A beleza da probabilidade condicional é que ela nos permite atualizar nossas probabilidades à medida que obtemos novas informações. Da mesma forma que ajustamos nossa probabilidade de ter um rei de 7,7% para 33,3% quando soubemos que tínhamos uma carta de face, a probabilidade condicional nos dá uma maneira formal de recalcular as probabilidades com base em novas evidências.
A estrutura matemática da probabilidade condicional nos fornece ferramentas para analisar cenários complexos que envolvem vários eventos. Vamos explorar as principais propriedades.
Essas propriedades matemáticas nos ajudam a resolver problemas complexos com mais eficiência:
Quando dois eventos A e B são independentes, sabemos que a ocorrência de um não afeta a probabilidade do outro. Matematicamente, isso é: P(A|B) = P(A), que é lido como: "a probabilidade de A dado B é igual à probabilidade de A".
Por exemplo, se lançarmos um dado e jogarmos uma moeda, o fato de você tirar cara na moeda não altera a probabilidade de tirar um seis. A fórmula nos mostra: P(Six|Heads) = P(Six) = 1/6
Para qualquer evento A dada a condição B, as probabilidades de A e seu complemento A' (leia-se "A prime") devem somar 1. Matematicamente, isso é: P(A|B) + P(A'|B) = 1, que é lido como: "A probabilidade de A dado B mais a probabilidade de um complemento de A dado B é igual a 1."
Em nosso exemplo anterior de cartão: P(Rei|Cartão de face) + P(Não Rei|Cartão de face) = 4/12 + 8/12 = 1
A regra de multiplicação vincula as probabilidades conjuntas às probabilidades condicionais: P(A ∩ B) = P(A|B) × P(B). Dizemos: "A probabilidade de A interseção B é igual à probabilidade de A dada B vezes a probabilidade de B".
Isso se estende a vários eventos por meio da regra da cadeia. Para três eventos A, B e C: P(A ∩ B ∩ C) = P(A|B ∩ C) × P(B|C) × P(C). Ou seja, "A probabilidade de A interseção B interseção C é igual à probabilidade de A dada B interseção C vezes a probabilidade de B dada C vezes a probabilidade de C".
Vamos ver isso em ação com uma sequência de sorteio de cartas:
P(K ∩ Q ∩ A) = P(A|K ∩ Q) × P(Q|K) × P(K) = (4/50) × (4/51) × (4/52)
A regra da cadeia torna-se particularmente valiosa no aprendizado de máquina, especialmente em redes bayesianas, onde precisamos modelar dependências complexas entre várias variáveis. Ao analisar dados, frequentemente nos deparamos com situações em que os eventos seguem uma sequência natural, e a regra da cadeia nos ajuda a decompor esses cenários complexos em cálculos mais simples e gerenciáveis.
Vamos analisar dois dos exemplos mais comuns e pensar também em como a probabilidade condicional pode aparecer em seu trabalho.
Esses dois exemplos são muito comuns e vale a pena estudá-los, especialmente se você estiver fazendo uma entrevista:
Quando lançamos um dado, nosso espaço amostral começa com seis possibilidades: {1, 2, 3, 4, 5, 6}. O conhecimento de informações parciais sobre o lançamento altera nossos cálculos de probabilidade de uma maneira específica. Vamos ver como:
Probabilidade inicial de rolar um 6: P(6) = 1/6
Se soubermos que a rolagem foi par, nosso espaço amostral se reduzirá a {2, 4, 6}: P(6 | par) = 1/3
Uma sacola contém 5 bolinhas de gude azuis e 3 bolinhas de gude vermelhas. Quando sorteamos bolinhas de gude sem reposição, cada sorteio afeta as probabilidades dos sorteios subsequentes.
Primeiro sorteio - probabilidade de azul: P(blue₁) = 5/8
Segundo sorteio, já que o primeiro foi azul: P(azul₂ | azul₁) = 4/7
Esse exemplo complementa nosso exemplo anterior de cartão, destacando as dependências sequenciais.
Os exames médicos oferecem uma aplicação perfeita da probabilidade condicional na avaliação da precisão do teste. Para qualquer teste de diagnóstico, precisamos entender quatro probabilidades condicionais principais:
Ao avaliar o desempenho desse teste, os profissionais médicos usam essas probabilidades condicionais para:
Por exemplo, se testarmos 1.000 pacientes e obtivermos 100 resultados positivos, poderemos usar essas probabilidades condicionais para estimar quantos são verdadeiros positivos e quantos são falsos positivos. Essa análise ajuda os profissionais da área médica a equilibrar os riscos de perder um diagnóstico com os custos e a ansiedade dos alarmes falsos.
As empresas de investimento usam a probabilidade condicional para avaliar os riscos de mercado. Considere um gerente de portfólio que acompanha a volatilidade do mercado:
A volatilidade diária do mercado pode ser Baixa (L), Média (M) ou Alta (H).
Os dados históricos mostram:
Essas informações ajudam os gerentes:
Nossa exploração dos testes médicos destacou uma distinção importante: A probabilidade de ter uma doença com um teste positivo é diferente da probabilidade de ter um teste positivo com a doença. O Teorema de Bayes fornece uma estrutura formal para navegar nessa relação, permitindo-nos atualizar nossas estimativas de probabilidade à medida que surgem novas evidências.
O Teorema de Bayes expressa a relação entre duas probabilidades condicionais: P(A|B) = [P(B|A) × P(A)] / P(B). Você pode ler essa equação da seguinte forma: "A probabilidade de A dado B é igual à probabilidade de B dado A vezes a probabilidade de A, dividida pela probabilidade de B."
Cada componente desempenha uma função:
Vamos ver como isso funciona na prática com nosso cenário de testes médicos, agora expandido para mostrar a análise bayesiana completa.
Considere uma condição médica que afeta 2% da população. Um novo teste de diagnóstico:
Quando o teste de um paciente é positivo, como devemos atualizar nossa crença sobre sua condição?
Vamos resolver isso passo a passo:
Essa análise revela que, mesmo com um teste positivo, a probabilidade de você ter a doença é de apenas 16,2% - muito maior do que os 2% iniciais, mas talvez menor do que a intuição possa sugerir.
O Teorema de Bayes se destaca quando recebemos várias evidências. A probabilidade posterior de cada cálculo torna-se a probabilidade anterior para a próxima atualização. Por exemplo, se nosso paciente tiver um segundo teste positivo:
Essa atualização sequencial fornece uma estrutura matemática para incorporar novas evidências em nossas estimativas de probabilidade. A beleza da inferência bayesiana está em sua capacidade de quantificar como nossas crenças devem mudar à medida que coletamos novas informações, fornecendo um método formal para atualizar as probabilidades à luz das evidências.
Vamos ver como a probabilidade condicional aparece na ciência de dados.
O classificador Naive Bayes, uma das ferramentas mais simples e poderosas do aprendizado de máquina, aplica o Teorema de Bayes para prever categorias com base nas probabilidades de recursos. Ao classificar um e-mail como spam ou não spam, por exemplo, o algoritmo calcula a probabilidade condicional de um e-mail ser spam com base nas palavras que ele contém. Embora você faça a suposição "ingênua" de que os recursos são independentes, essa simplificação costuma funcionar surpreendentemente bem na prática.
As árvores de decisão adotam uma abordagem diferente para a probabilidade condicional, dividindo os dados com base nos valores dos recursos para criar subconjuntos condicionais. Em cada nó, a árvore faz perguntas como: "Qual é a probabilidade de nossa variável-alvo com esse valor específico de recurso?" Essas divisões continuam até atingirmos subconjuntos puros ou quase puros, essencialmente criando um mapa de probabilidades condicionais que orientam nossas previsões.
Os sistemas de pontuação de crédito usam probabilidades condicionais para avaliar a probabilidade de inadimplência do empréstimo com base em várias características do cliente. Por exemplo, um banco pode calcular a probabilidade de inadimplência com base no nível de renda, no histórico de crédito e na situação empregatícia. Esses cálculos se tornam mais sofisticados quando se consideram vários riscos dependentes, por exemplo, como a probabilidade de inadimplência hipotecária pode mudar em função de uma recessão e do aumento das taxas de juros. Os modelos de risco de investimento usam probabilidades condicionais para estimar o valor em risco (VaR), calculando a probabilidade de níveis específicos de perda, dadas as condições atuais do mercado. Os gerentes de portfólio usam essas probabilidades condicionais para ajustar as alocações de ativos, entendendo como o risco de um investimento pode mudar em função do desempenho de outros no portfólio.
As redes bayesianas representam a aplicação mais direta da probabilidade condicional no aprendizado de máquina, modelando as relações entre as variáveis como um gráfico direcionado em que o estado de cada nó depende de seus pais. Essas redes são excelentes em tarefas como diagnóstico médico, em que a probabilidade de várias condições depende de vários sintomas interconectados e resultados de testes.
Os modelos gráficos probabilísticos usam dependências condicionais para representar relações complexas nos dados, o que os torna valiosos para tarefas como reconhecimento de imagens e processamento de linguagem natural. Mesmo os modelos de aprendizagem profunda, embora não sejam explicitamente probabilísticos, geram probabilidades condicionais em suas camadas finais ao fazer classificações. A função softmax, comumente usada em redes neurais, transforma as pontuações brutas em probabilidades condicionais, informando a probabilidade de cada classe possível com base nos dados de entrada.
Ao trabalhar com probabilidade condicional, três equívocos principais geralmente levam a conclusões incorretas.
Por fim, vamos analisar algumas ideias mais complicadas que se baseiam no que temos praticado.
Quando passamos de distribuições de probabilidade discretas para contínuas, nos deparamos com um desafio interessante: pontos específicos em uma distribuição contínua têm probabilidade zero. Considere a medição da altura exata de uma pessoa - embora possamos dizer que a probabilidade de alguém ter entre 170 e 171 centímetros é significativa, a probabilidade de alguém ter exatamente 170,5432... centímetros é tecnicamente zero. No entanto, muitas vezes queremos nos condicionar a essas medidas precisas. A probabilidade condicional regular fornece uma estrutura matemática para lidar com essas situações, estendendo nossos conceitos básicos a casos contínuos por meio do uso de funções de densidade e teoria de medidas. Essa extensão nos permite entender afirmações como "a distribuição de probabilidade do peso de uma pessoa, considerando que ela tem exatamente 170,5 centímetros de altura".
A condicionalização de Jeffrey expande a probabilidade condicional tradicional para situações em que nossa nova evidência não é certa, mas tem sua própria probabilidade. Diferentemente do condicionamento padrão, em que assumimos certeza absoluta sobre nossas novas informações, a regra de Jeffrey nos permite atualizar nossas crenças com base em evidências incertas. Isso corresponde melhor aos cenários do mundo real, em que as novas informações geralmente vêm com algum grau de incerteza. Por exemplo, em vez de saber com certeza que um exame médico é positivo, podemos saber que a probabilidade de ser positivo é de 80%. A regra de Jeffrey oferece um método formal para atualizar as probabilidades nessas situações mais complexas.
A probabilidade condicional fornece uma estrutura matemática para atualizar nossas crenças à medida que surgem novas informações. Ao longo deste artigo, vimos como esse conceito se aplica a vários campos, desde o diagnóstico médico até a avaliação de riscos financeiros. Os princípios que exploramos nos ajudam a entender como a probabilidade muda com novas evidências, permitindo decisões mais informadas em aplicativos de ciência de dados. Esse entendimento torna-se particularmente valioso quando se trabalha com algoritmos de classificação, modelos de risco e sistemas de aprendizado de máquina em que as atualizações de probabilidade ocorrem continuamente.
À medida que você continua a desenvolver sua experiência em probabilidade e inferência estatística, vários cursos podem aumentar sua compreensão desses conceitos por meio de uma lente bayesiana. Nosso curso Fundamentals of Bayesian Data Analysis in R apresenta os princípios fundamentais e suas aplicações práticas, enquanto nosso curso Bayesian Modeling with RJAGS mostra como implementar esses conceitos usando ferramentas estatísticas poderosas. Para usuários de Python, nosso curso Bayesian Data Analysis in Python oferece experiência prática na aplicação desses métodos a problemas do mundo real. Cada curso oferece um caminho para você expandir seu conhecimento sobre probabilidade e suas aplicações na ciência de dados moderna.
Aprenda com a DataCamp
Curso
Curso
blog
Arun Nanda
15 min
blog
Abid Ali Awan
7 min
Tutorial
Tutorial
Bex Tuychiev
Tutorial
Travis Tang
Tutorial
Zoumana Keita



