
Cours
Détection de fraude en Python
4 h
22K
Facilitez la prise de décision basée sur les données avec DataCamp for Business. Des cours complets, des missions et un suivi des performances adaptés à votre équipe de 2 personnes ou plus.

Dans cette section, nous explorons les grandes catégories de transactions frauduleuses, examinons des exemples courants de fraude dans chaque catégorie et expliquons comment utiliser les outils d'analyse pour les détecter et les prévenir.
La fraude financière est peut-être la forme de fraude la plus connue et la plus répandue. Les victimes sont généralement des institutions financières et leurs clients. Les coupables sont généralement des fraudeurs qui se font passer pour des clients ou des représentants d'institutions financières.
La fraude à la carte de crédit est l'utilisation non autorisée d'une carte pour acheter des biens ou retirer de l'argent à un distributeur automatique de billets. Dans la plupart des cas, cela se fait en utilisant les données d'une carte volée. L'analyse des fraudes peut aider à détecter les fraudes à la carte en recherchant des schémas communs tels que :
Le vol d'identité se produit lorsque les informations personnelles d'une personne (comme les numéros de compte bancaire, les numéros de carte d'identité délivrée par l'État, les mots de passe de la messagerie électronique, etc. Ces informations peuvent être utilisées pour usurper l'identité de la personne afin de contracter des prêts, d'ouvrir des comptes à découvert et d'effectuer d'autres transactions financières importantes. L'analyse des fraudes est utile dans de telles situations en signalant les comportements suspects :
La fraude au paiement est l'utilisation de moyens trompeurs pour convaincre une personne ou une entreprise d'effectuer un paiement pour quelque chose qu'elle n'achète pas. Il comprend
L'analyse peut aider à lutter contre la fraude aux paiements en surveillant et en signalant les transactions qui.. :
La fraude à l'assurance consiste à réclamer des indemnités importantes pour des incidents mineurs et à payer de petites primes pour des polices risquées. La victime est généralement la compagnie d'assurance, tandis que les coupables se font passer pour des clients ou des agents d'assurance.
Les demandes d'indemnisation frauduleuses concernent des accidents qui n'ont jamais eu lieu. Pour détecter de telles allégations, des outils d'analyse sont nécessaires :
Demandes d'indemnisation gonflées exagère les dommages subis et le montant de l'indemnité d'assurance demandée pour des incidents mineurs. Les outils d'analyse de la fraude peuvent contribuer à atténuer les demandes d'indemnisation gonflées :
Les experts en assurance vérifient manuellement les demandes d'indemnisation potentiellement gonflées.
La fraude à la prime consiste à donner de fausses informations à la compagnie d'assurance afin de réduire artificiellement le profil de risque et de payer des primes moins élevées pour une police donnée. Les outils d'analyse de la fraude peuvent aider à :
Fausses polices sont de fausses polices créées et vendues par des escrocs qui se font passer pour des agents d'assurance. Le client s'en aperçoit lorsqu'il fait une réclamation. Le logiciel d'analyse des fraudes détecte les fausses polices d'assurance :
Les compagnies d'assurance ont également le devoir, vis-à-vis de la société, d'identifier les schémas de fausses polices émises en leur nom. La présentation de ces analyses aux forces de l'ordre permet de démasquer les fausses politiques.
La fraude aux soins de santé peut se produire dans n'importe quelle partie du système de soins de santé, y compris les assureurs de santé publique. La victime est le payeur, qui peut être un ou plusieurs groupes :
Les coupables sont souvent les prestataires de services de santé ou les patients. La fraude dans le domaine de la santé est généralement commise par le biais de fausses demandes de remboursement, y compris la facturation de services non rendus et l'établissement d'un code supérieur (upcoding).
Facturation de services non rendus désigne le fait de facturer aux payeurs des services (tels que des tests et des traitements) qui n'ont pas été effectués sur le patient. Pour détecter ce type de fraude, les outils d'analyse peuvent :
Upcoding se réfère à la mauvaise pratique consistant à facturer une catégorie de services plus coûteuse que celle qui a été fournie. Les outils d'analyse de la fraude emploient diverses méthodes pour détecter la codification ascendante :
De nombreux vendeurs en ligne sont des petites et moyennes entreprises qui ne sont pas nécessairement à l'aise avec la technologie. Il incombe donc aux plateformes de commerce électronique de détecter les activités frauduleuses et d'y mettre un terme. La fraude dans le domaine du commerce électronique et de la vente au détail peut prendre différentes formes :
Les prises de contrôle de comptes font référence à un utilisateur qui perd le contrôle de son compte au profit de fraudeurs qui en abusent en effectuant des achats non autorisés. Cela est généralement dû à une erreur de l'utilisateur ou à un manque d'attention à l'égard de considérations de sécurité telles que les mots de passe et les escroqueries par hameçonnage.
Les plateformes de commerce électronique peuvent détecter la prise de contrôle d'un compte à l'aide de techniques telles que :
Les faux retours se produisent lorsque des acteurs malveillants retournent des articles différents de ceux qui ont été achetés, par exemple lorsqu'ils commandent un article coûteux et qu'ils retournent une contrefaçon. Il s'agit également de renvoyer les produits usagés qui ne peuvent pas être revendus. Pour vous protéger contre les faux retours, l'analyse des fraudes peut.. :
Les achats frauduleux impliquent des transactions non autorisées utilisant des informations de paiement volées ou falsifiées et des comptes compromis. Ils peuvent entraîner des pertes tant pour les vendeurs que pour les acheteurs qui ne se doutent de rien. L'analyse des fraudes peut aider à repérer les achats potentiellement frauduleux en surveillant les transactions afin d'identifier des schémas tels que :
La fraude par rétrofacturation consiste à abuser de la politique de rétrofacturation de la carte de crédit pour demander le remboursement d'achats légitimes. L'analyse des fraudes peut contribuer à la protection contre les fraudes à l'imputation en utilisant :
Les outils d'analyse de la fraude utilisent une gamme commune de techniques en les adaptant aux différents contextes, ensembles de données et comportements des fraudeurs dans ce domaine.
Toutes les méthodes d'analyse de la fraude ont deux objectifs principaux :
Les fraudeurs ont souvent un comportement très différent de celui des clients légitimes. La détection des anomalies permet d'identifier les comportements inhabituels qui indiquent une activité potentiellement frauduleuse. Elle englobe une série de méthodes :
Consultez le cours Détection d'anomalie en Python pour mieux comprendre cette technique.
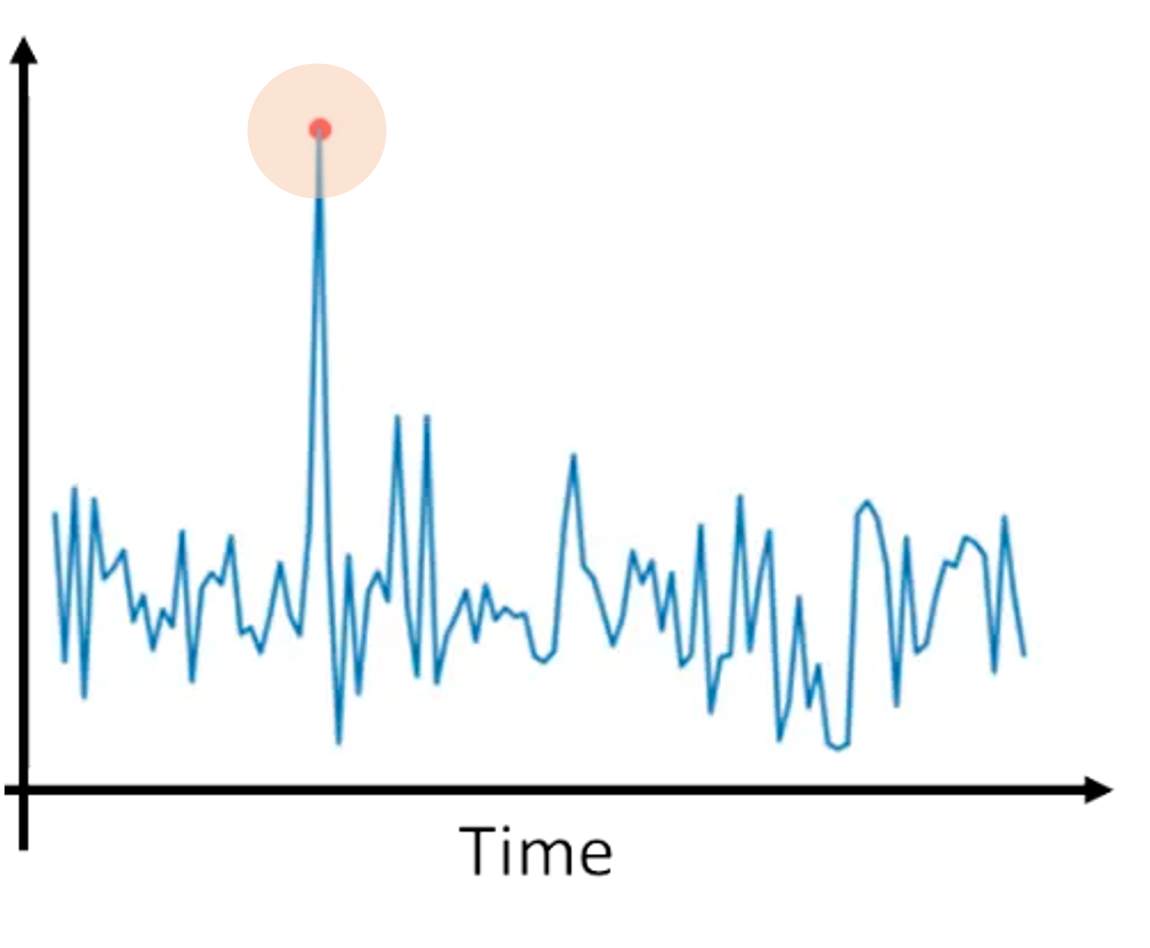
Illustration de la détection d'anomalies. Source de l'image : Comprendre l'IA
L'apprentissage automatique supervisé est une méthode éprouvée de détection des anomalies. Les humains étiquettent les ensembles de données sur la base d'exemples connus de comportements frauduleux antérieurs. Des algorithmes d'apprentissage automatique sont ensuite formés sur des ensembles de données étiquetées pour prédire la probabilité qu'une nouvelle transaction soit frauduleuse.
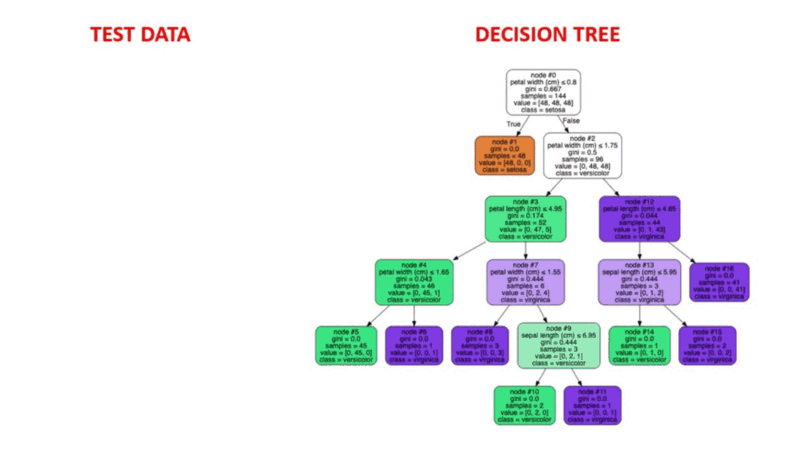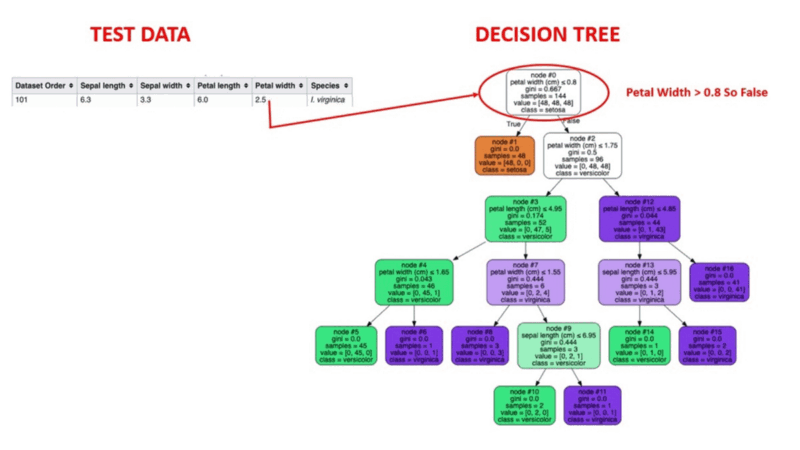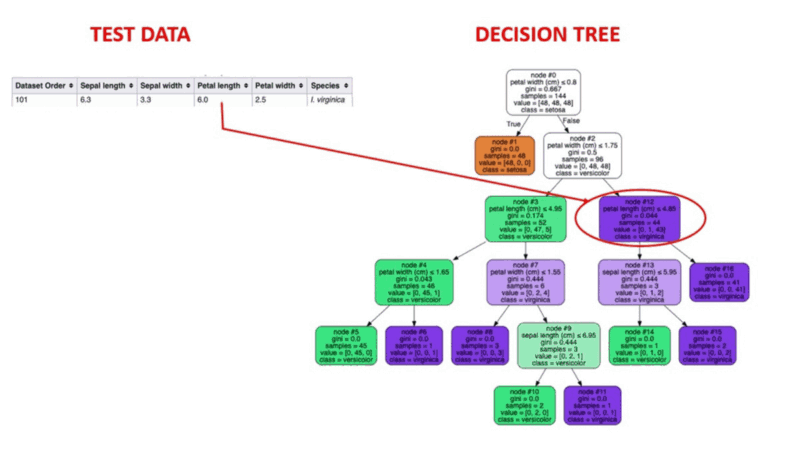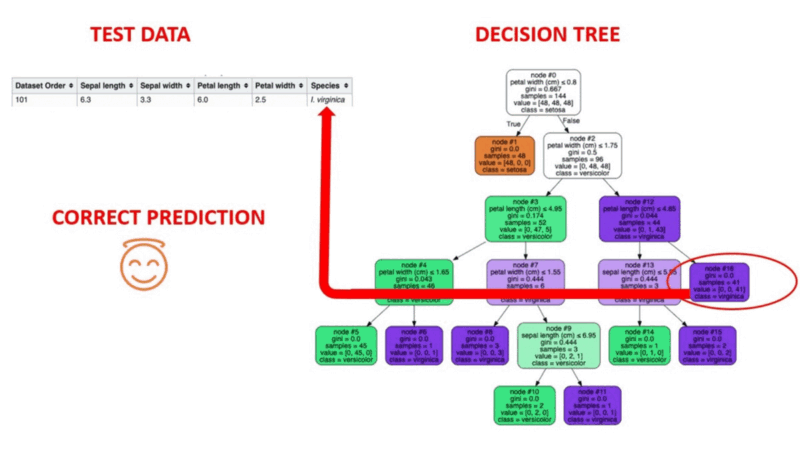
Illustration animée du fonctionnement des arbres de décision. Source de l'image : Apprentissage automatique supervisé
Consultez la piste de cours Apprentissage automatique supervisé en Python pour en savoir plus sur ces techniques.
Les algorithmes d'apprentissage automatique supervisés, qui prédisent en fonction des comportements antérieurs, deviennent moins efficaces à mesure que les fraudeurs adoptent de nouvelles méthodes.
L'apprentissage automatique non supervisé est utile pour prédire des modèles inconnus dans les données. L'autre avantage des méthodes non supervisées est qu'il n'est pas nécessaire de consacrer des ressources humaines à l'étiquetage de vastes ensembles de données. L'algorithme détecte des modèles par lui-même.
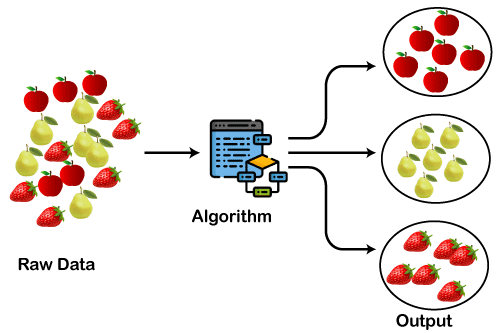
Comment fonctionne la mise en grappe. Source de l'image : Le clustering dans l'apprentissage automatique
Consultez l'apprentissage non supervisé en Python pour en savoir plus sur les techniques mentionnées.
Les méthodes traditionnelles de détection des fraudes par la recherche de comportements suspects sont efficaces pour les comptes individuels. Cependant, les fraudeurs opèrent souvent en tant que groupes d'individus utilisant un ensemble d'appareils, de comptes de messagerie et d'adresses physiques, ce qui rend difficile le cursus d'un comportement suspect lorsque ce compte est considéré de manière isolée.
Consultez le cours Introduction à l'analyse de réseaux en Python pour une compréhension plus approfondie de ces techniques.
De nombreuses formes de fraude, comme les fausses déclarations d'assurance, les faux avis de clients, les courriels d'hameçonnage et autres, reposent sur des blocs de texte. L'analyse de leur contenu textuel fournit souvent des indices permettant de distinguer les activités authentiques des clients des tentatives de fraude.
Consultez le parcours de compétences Traitement du langage naturel en Python pour une compréhension plus approfondie du sujet.
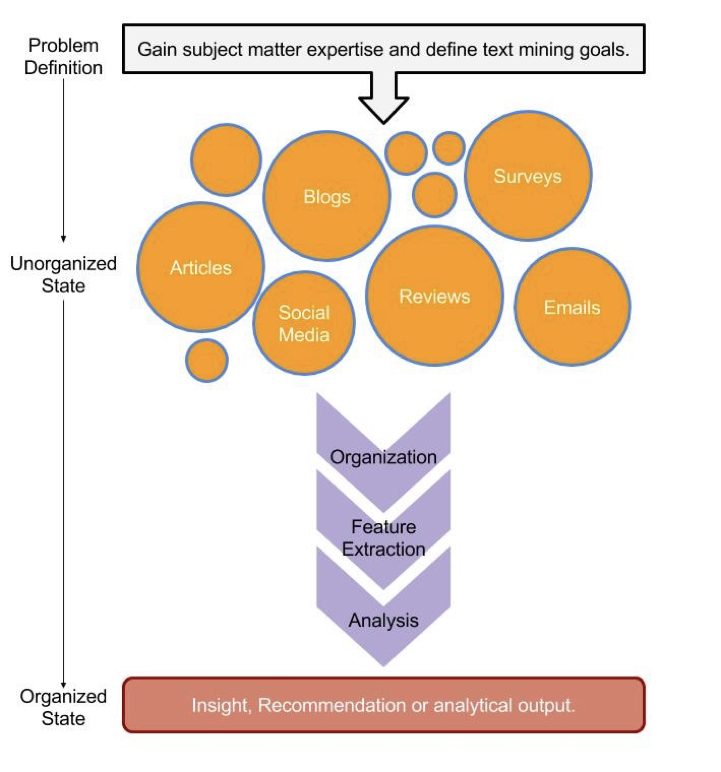
Illustration du flux de travail de l'exploration de texte. Source de l'image : Text Mining avec Bag-of-Words en R
Dans cette section, nous donnons un aperçu général des principes pratiques de la mise en œuvre des flux de travail de détection de la fraude.
Tous les algorithmes de détection des fraudes sont basés sur l'analyse et l'identification de modèles observés dans de vastes ensembles de données. Il est donc essentiel de disposer d'ensembles de données de haute qualité, pertinents et conservés, tels que des journaux de transactions et des profils de clients, pour former ces algorithmes.
Après la collecte des données, l'étape suivante consiste logiquement à les utiliser pour former des modèles de détection de la fraude. Les données brutes ne conviennent généralement pas à la formation des modèles. Il est donc nécessaire de nettoyer et de normaliser les données avant de les utiliser comme ensemble de données de formation. Le prétraitement des données, ainsi que l'ingénierie des caractéristiques, couvrent ces étapes.
Les algorithmes d'analyse de la fraude reposent essentiellement sur des techniques d'apprentissage automatique. Les données historiques constituent la base de la formation des algorithmes d'apprentissage automatique. Après la collecte et le nettoyage des données, l'étape suivante consiste à former les modèles. Au cours de la formation, le modèle apprend à prédire quelles transactions ou quels profils d'utilisateurs sont les plus susceptibles d'être frauduleux.
En plus de signaler les comportements potentiellement frauduleux, il est tout aussi important de ne pas gêner les utilisateurs réguliers. Un faux positif se produit lorsque le modèle identifie une transaction authentique comme frauduleuse. Il est important de minimiser les faux positifs pour maintenir une bonne expérience client. Pour ce faire, le modèle formé est évalué à l'aide de différentes mesures.
Après avoir commis une fraude, il devient de plus en plus difficile de récupérer les fonds ou les biens volés auprès du fraudeur. L'objectif est donc de détecter et de prévenir la fraude en temps réel, avant l'exécution de la transaction. L'intégration de l'analyse des fraudes dans le pipeline de traitement des transactions permet une détection en temps réel. Il y a deux façons de procéder :
Les parties prenantes telles que la direction de l'entreprise, les scientifiques des données, les responsables de la conformité, les analystes de la fraude et les équipes de sécurité surveillent les résultats des efforts de détection de la fraude en cours. Des outils tels que des tableaux de bord, des alertes en temps réel et des rapports automatisés facilitent le suivi et la supervision.
Validez vos compétences professionnelles de data scientist.

Apprenez-en plus sur l'analyse et l'apprentissage automatique grâce à ces cours !
Cours
Cours
Cours