Kurs
Betrugserkennung mit Python
4 Std.
22K
Ermögliche datengesteuerte Entscheidungen mit DataCamp for Business. Umfassende Kurse, Aufgaben und Leistungsnachweise, die auf dein Team von 2 oder mehr Personen zugeschnitten sind.

In diesem Abschnitt gehen wir auf die großen Kategorien betrügerischer Transaktionen ein, erörtern gängige Betrugsbeispiele innerhalb jeder Kategorie und zeigen, wie man Analysetools einsetzt, um sie aufzudecken und zu verhindern.
Finanzbetrug ist vielleicht die bekannteste und am weitesten verbreitete Form des Betrugs. Die Opfer sind in der Regel Finanzinstitute und deren Kunden. Bei den Tätern handelt es sich meist um Betrüger, die sich als Kunden oder Vertreter von Finanzinstituten ausgeben.
Kreditkartenbetrug ist die unbefugte Verwendung einer Karte, um Waren zu kaufen oder Geld an einem Geldautomaten abzuheben. In den meisten Fällen wird dies mit gestohlenen Kartendaten gemacht. Betrugsanalysen können dabei helfen, Kartenbetrug aufzudecken, indem sie nach häufigen Mustern suchen, wie z. B.:
Identitätsdiebstahl liegt vor, wenn die persönlichen Daten einer Person (z. B. Bankkontonummern, staatliche Ausweisnummern, E-Mail-Passwörter usw.) gestohlen werden. Diese Informationen können dazu verwendet werden, sich als die betreffende Person auszugeben, um Kredite aufzunehmen, Überziehungskredite zu eröffnen und andere große Finanztransaktionen zu tätigen. Die Betrugsanalyse hilft in solchen Situationen, indem sie verdächtiges Verhalten wie z.B.:
Zahlungsbetrug ist der Einsatz betrügerischer Mittel, um eine Person oder ein Unternehmen zu überzeugen, eine Zahlung für etwas zu leisten, das sie nicht kaufen. Es beinhaltet:
Analysen können bei Zahlungsbetrug helfen, indem sie Transaktionen überwachen und markieren, die:
Der Versicherungsbetrug besteht darin, hohe Auszahlungen für geringfügige Vorfälle zu fordern und geringe Prämien für riskante Policen zu zahlen. Das Opfer ist in der Regel die Versicherungsgesellschaft, während die Täter vorgeben, Kunden oder Versicherungsagenten zu sein.
Bei betrügerischen Ansprüchen geht es um Unfälle, die nie passiert sind. Um solche Ansprüche zu erkennen, gibt es Analysetools:
Überhöhte Schadenersatzforderungen übertreiben den entstandenen Schaden und die geforderte Versicherungsleistung bei kleineren Vorfällen. Betrugsanalysetools können dabei helfen, überhöhte Forderungen einzudämmen:
Versicherungssachverständige überprüfen potenziell überhöhte Ansprüche manuell.
Bei der Prämienhinterziehung werden der Versicherungsgesellschaft falsche Angaben gemacht, um das Risikoprofil künstlich zu verringern und niedrigere Prämien für eine bestimmte Police zu zahlen. Betrugsanalysetools können dabei helfen:
Gefälschte Policen sind gefälschte Policen, die von Betrügern erstellt und verkauft werden, die sich als Versicherungsagenten ausgeben. Der Kunde erfährt es, wenn er eine Reklamation einreichen will. Betrugsanalysesoftware erkennt gefälschte Policen durch:
Versicherungsunternehmen sind auch der Gesellschaft gegenüber verpflichtet, Muster von gefälschten Policen, die in ihrem Namen ausgestellt wurden, zu erkennen. Die Vorlage dieser Analysen bei den Strafverfolgungsbehörden hilft dabei, gefälschte Policen aufzudecken.
Betrug im Gesundheitswesen kann in jedem Bereich des Gesundheitssystems vorkommen, auch bei den öffentlichen Krankenversicherungen. Das Opfer ist der Zahler, der aus einer oder mehreren Gruppen bestehen kann:
Die Schuldigen sind oft Gesundheitsdienstleister oder Patienten. Betrug im Gesundheitswesen wird in der Regel durch falsche Abrechnungen begangen, z. B. durch die Abrechnung von nicht erbrachten Leistungen und Upcoding.
Abrechnung von nicht erbrachten Leistungen bezeichnet die Abrechnung von Leistungen (wie Tests und Behandlungen), die nicht am Patienten durchgeführt wurden, mit den Kostenträgern. Um diese Art von Betrug aufzudecken, können Analysetools:
Upcoding bezeichnet das Fehlverhalten, eine teurere Leistungskategorie abzurechnen als erbracht wurde. Betrugsanalysetools verwenden verschiedene Methoden, um Upcoding zu erkennen, z. B:
Viele E-Commerce-Verkäufer/innen sind kleine und mittlere Unternehmen, die nicht unbedingt technikaffin sind. Es liegt also in der Verantwortung der E-Commerce-Plattformen, betrügerische Aktivitäten zu erkennen und zu unterbinden. Betrug im E-Commerce und im Einzelhandel kann in verschiedenen Formen auftreten:
Kontoübernahmen beziehen sich darauf, dass ein/e Nutzer/in die Kontrolle über sein/ihr Konto an Betrüger/innen verliert, die dieses missbrauchen, indem sie unberechtigte Einkäufe tätigen. Dies geschieht meist aufgrund von Benutzerfehlern oder Unachtsamkeit in Bezug auf Sicherheitsaspekte wie Passwörter und Phishing-Betrug.
E-Commerce-Plattformen können Kontoübernahmen mit Techniken wie diesen erkennen:
Gefälschte Rücksendungen treten auf, wenn böswillige Akteure Artikel zurücksenden, die sich vom gekauften Artikel unterscheiden, z. B. wenn sie einen teuren Artikel bestellen und eine Fälschung zurückschicken. Dazu gehört auch die Rückgabe gebrauchter Produkte, die nicht weiterverkauft werden können. Zum Schutz vor gefälschten Rücksendungen kann die Betrugsanalyse:
Betrügerische Einkäufe beinhalten nicht autorisierte Transaktionen mit gestohlenen oder gefälschten Zahlungsinformationen und kompromittierten Konten. Sie können sowohl für Verkäufer als auch für ahnungslose Käufer zu Verlusten führen. Betrugsanalysen können dabei helfen, potenziell betrügerische Einkäufe zu erkennen, indem sie Transaktionen überwachen, um Muster wie diese zu identifizieren:
Beim Rückbuchungsbetrug wird die Rückbuchungsrichtlinie der Kreditkarte missbraucht, um Rückerstattungen für rechtmäßige Einkäufe zu fordern. Betrugsanalysen können helfen, sich vor Rückbuchungsbetrug zu schützen, indem sie eingesetzt werden:
Betrugsanalysetools verwenden eine gemeinsame Palette von Techniken, indem sie an unterschiedliche Kontexte, Datensätze und Verhaltensweisen von Betrügern in diesem Bereich angepasst werden.
Alle Methoden zur Betrugsanalyse haben zwei Hauptziele:
Betrüger zeigen oft ein deutlich anderes Verhalten als legitime Kunden. Die Anomalieerkennung hilft dabei, ungewöhnliche Verhaltensweisen zu erkennen, die auf potenziell betrügerische Aktivitäten hindeuten. Sie umfasst eine Reihe von Methoden:
Schau dir den Kurs "Anomaly Detection in Python " an, um diese Technik besser zu verstehen.
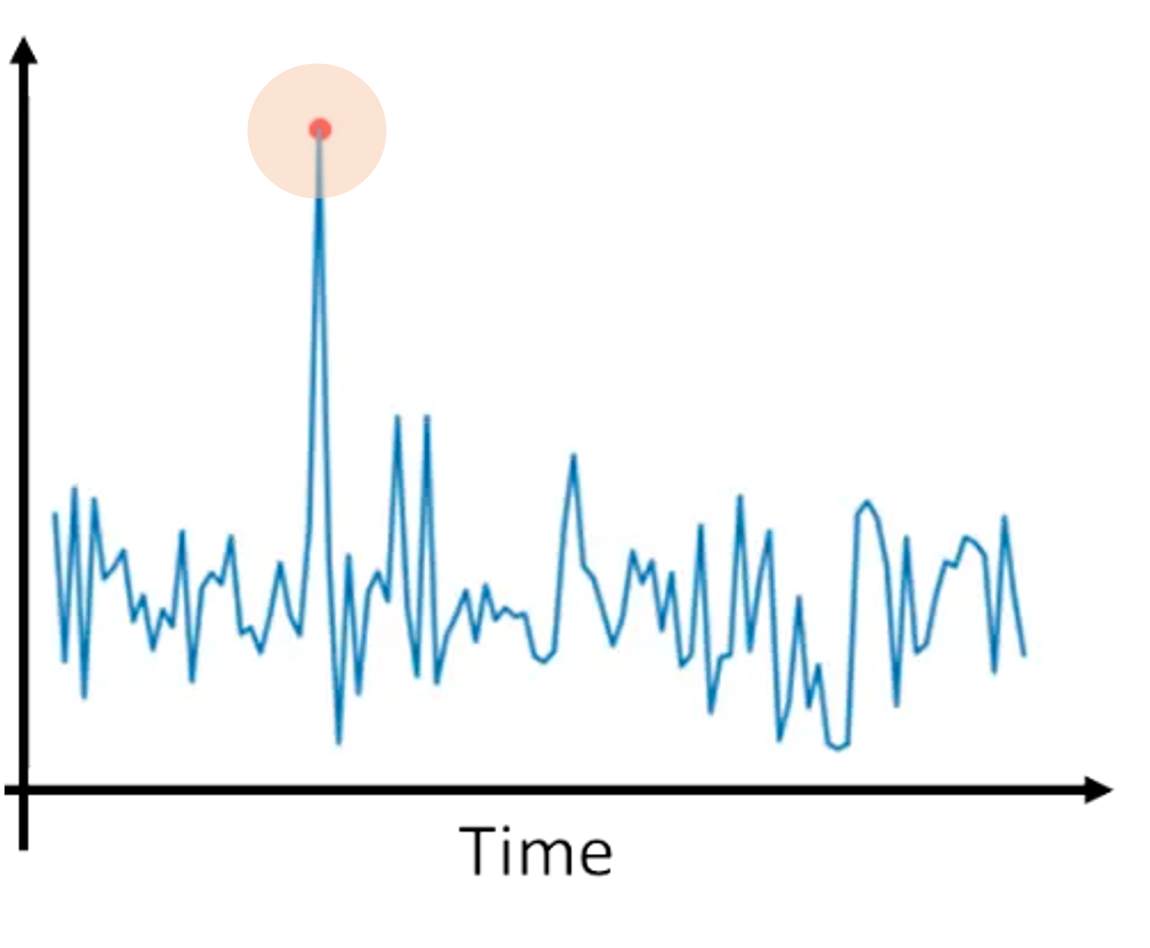
Illustration der Anomalieerkennung. Bildquelle: KI verstehen
Überwachtes maschinelles Lernen ist eine bewährte Methode zur Aufdeckung von Anomalien. Menschen kennzeichnen Datensätze auf der Grundlage bekannter Fälle von betrügerischem Verhalten in der Vergangenheit. Die Algorithmen des maschinellen Lernens werden dann auf markierten Datensätzen trainiert, um die Wahrscheinlichkeit einer neuen Transaktion als betrügerisch einzustufen.
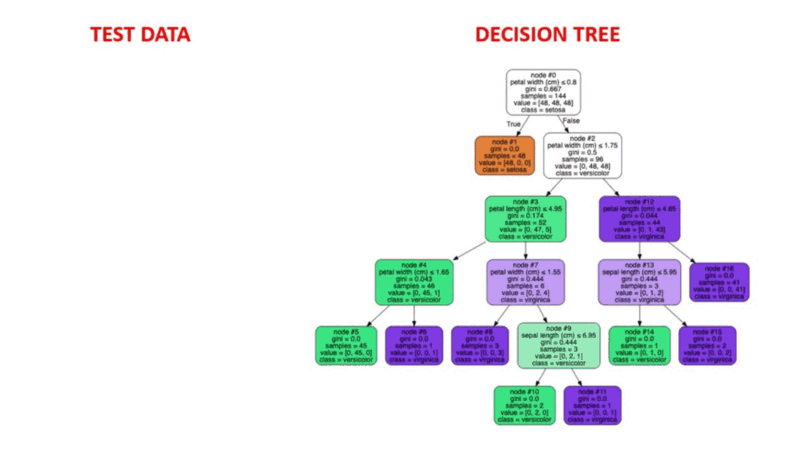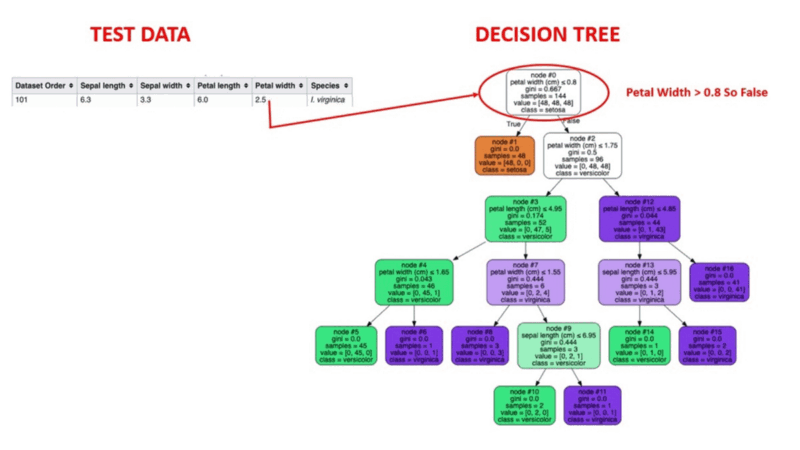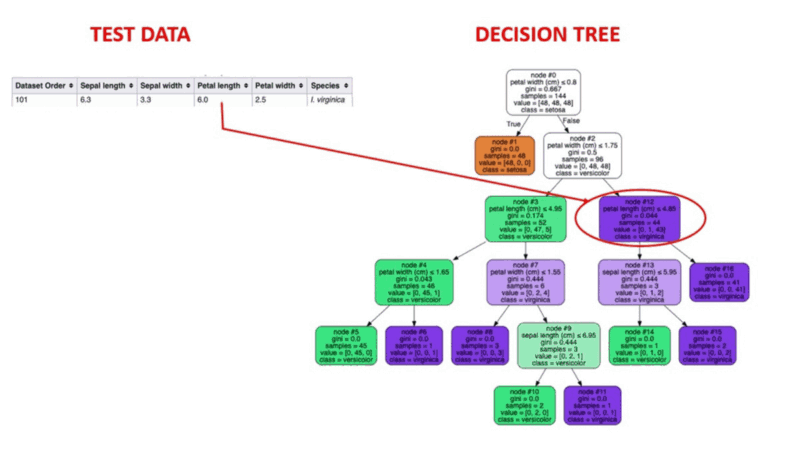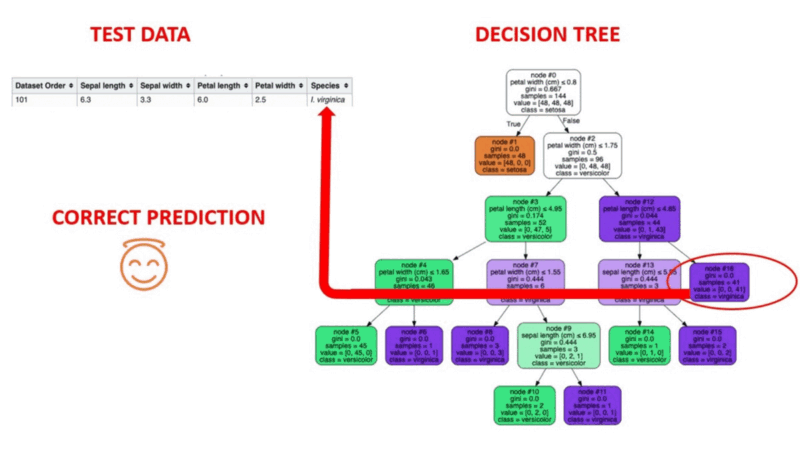
Animierte Illustration der Funktionsweise von Entscheidungsbäumen. Bildquelle: Überwachtes maschinelles Lernen
Schau dir den Kurs Supervised Machine Learning in Python an, um mehr über diese Techniken zu erfahren.
Überwachte Algorithmen des maschinellen Lernens, die Vorhersagen auf der Grundlage früheren Verhaltens treffen, werden immer weniger effektiv, wenn Betrüger neue Methoden anwenden.
Unüberwachtes maschinelles Lernen ist hilfreich bei der Vorhersage unbekannter Muster in den Daten. Ein weiterer Vorteil der unüberwachten Methoden ist, dass du keine personellen Ressourcen aufwenden musst, um große Datensätze zu beschriften. Der Algorithmus erkennt selbständig Muster.
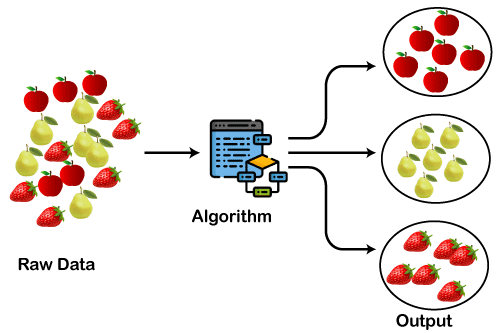
So funktioniert Clustering. Bildquelle: Clustering beim maschinellen Lernen
Schau dir den Artikel Unüberwachtes Lernen in Python an, um mehr über die genannten Techniken zu erfahren.
Herkömmliche Methoden der Betrugserkennung durch Musterabgleich für verdächtiges Verhalten sind für einzelne Konten wirksam. Allerdings agieren Betrüger oft als Gruppen von Einzelpersonen, die eine Reihe von Geräten, E-Mail-Konten und physischen Adressen nutzen, was es schwierig macht, verdächtiges Verhalten zu verfolgen, wenn ein Konto isoliert betrachtet wird.
Im Kurs Einführung in die Netzwerkanalyse mit Python erfährst du mehr über diese Techniken.
Viele Formen des Betrugs, wie falsche Versicherungsansprüche, gefälschte Kundenrezensionen, Phishing-E-Mails und Ähnliches, basieren auf Textblöcken. Die Analyse ihres Textinhalts führt oft zu Hinweisen, um echte Kundenaktivitäten von Betrugsversuchen zu unterscheiden.
Schau dir den Skill Track Natural Language Processing in Python an, um ein tieferes Verständnis für das Thema zu bekommen.
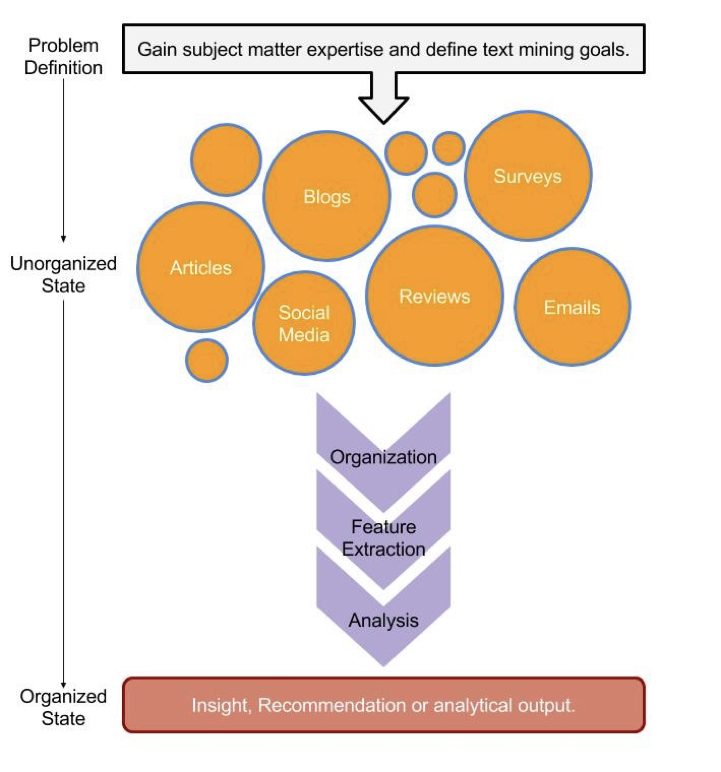
Illustration des Textmining-Workflows. Bildquelle: Text Mining mit Bag-of-Words in R
In diesem Abschnitt geben wir einen Überblick über die praktischen Grundsätze der Implementierung von Betrugserkennungsworkflows.
Alle Algorithmen zur Betrugserkennung basieren auf der Analyse und Identifizierung von Mustern, die in großen Datensätzen beobachtet werden. Daher sind hochwertige, relevante und kuratierte Datensätze wie Transaktionsprotokolle und Kundenprofile für das Training dieser Algorithmen entscheidend.
Nach dem Sammeln von Daten ist der nächste logische Schritt, sie zum Trainieren von Betrugserkennungsmodellen zu verwenden. Rohdaten sind in der Regel nicht für das Training von Modellen geeignet. Daher ist es notwendig, die Daten zu bereinigen und zu normalisieren, bevor sie als Trainingsdatensatz verwendet werden. Die Datenvorverarbeitung umfasst zusammen mit dem Feature Engineering diese Schritte.
Die Algorithmen zur Betrugsanalyse basieren im Kern auf maschinellen Lernverfahren. Historische Daten sind die Grundlage für das Training von Algorithmen für maschinelles Lernen. Nach dem Sammeln und Bereinigen der Daten ist der nächste Schritt das Trainieren der Modelle. Während des Trainings lernt das Modell, vorauszusagen, welche Transaktionen oder Nutzerprofile mit größerer Wahrscheinlichkeit betrügerisch sind.
Es ist nicht nur wichtig, potenziell betrügerisches Verhalten zu erkennen, sondern auch, normale Nutzer nicht zu behindern. Ein False Positive ist, wenn das Modell eine echte Transaktion als betrügerisch einstuft. Die Minimierung von Fehlalarmen ist wichtig, um ein gutes Kundenerlebnis zu gewährleisten. Um dies zu gewährleisten, wird das trainierte Modell anhand verschiedener Metriken bewertet.
Nachdem du einen Betrug begangen hast, wird es immer schwieriger, die gestohlenen Gelder oder Waren vom Betrüger zurückzubekommen. Ziel ist es also, Betrug in Echtzeit zu erkennen und zu verhindern, bevor die Transaktion ausgeführt wird. Die Integration von Betrugsanalysen in die Transaktionsverarbeitung ermöglicht eine Aufdeckung in Echtzeit. Es gibt zwei Möglichkeiten, dies zu tun:
Beteiligte wie die Unternehmensleitung, Datenwissenschaftler, Compliance-Beauftragte, Betrugsanalysten und Sicherheitsteams überwachen die Ergebnisse der laufenden Betrugsaufdeckung. Tools wie Dashboards, Echtzeitwarnungen und automatische Berichte erleichtern die Überwachung und Kontrolle.
Überprüfe deine professionellen Fähigkeiten als Data Scientist.

Lerne mehr über Analytik und maschinelles Lernen mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
