Curso
Fraud Detection in Python
4 h
22.1K
Facilita la toma de decisiones basada en datos con DataCamp para empresas. Cursos completos, tareas y seguimiento del rendimiento adaptados a tu equipo de 2 o más personas.

En esta sección, exploramos amplias categorías de transacciones fraudulentas, discutimos ejemplos comunes de fraude dentro de cada categoría, y cómo utilizar herramientas analíticas para detectarlas y prevenirlas.
El fraude financiero es quizá la forma de fraude más conocida y extendida. Las víctimas suelen ser instituciones financieras y sus clientes. Los culpables suelen ser estafadores que se hacen pasar por clientes o representantes de instituciones financieras.
Fraude con tarjeta de crédito es el uso no autorizado de una tarjeta para comprar productos o retirar dinero en un cajero automático. En la mayoría de los casos, esto se hace utilizando datos de tarjetas robadas. El análisis del fraude puede ayudar a detectar el fraude con tarjeta buscando patrones comunes como:
El robo de identidad se produce cuando se roba la información personal de alguien (como números de cuentas bancarias, números de identificación emitidos por el gobierno, contraseñas de correo electrónico, etc.). Esta información puede utilizarse para suplantar la identidad de la persona para pedir préstamos, abrir cuentas en descubierto y realizar otras grandes transacciones financieras. El análisis del fraude ayuda en estas situaciones señalando comportamientos sospechosos como:
Fraude en los pagos es el uso de medios engañosos para convencer a un particular o a una empresa de que efectúe un pago por algo que no está comprando. Incluye:
La analítica puede ayudar con el fraude en los pagos, controlando y marcando las transacciones que:
El fraude al seguro incluye reclamar grandes indemnizaciones por incidentes menores y pagar primas pequeñas por pólizas arriesgadas. La víctima suele ser la compañía de seguros, mientras que los culpables se hacen pasar por clientes o agentes de seguros.
Reclamaciones fraudulentas se refieren a accidentes que nunca ocurrieron. Para detectar tales afirmaciones, las herramientas analíticas:
Reclamaciones infladas exageran los daños sufridos y el pago reclamado al seguro en siniestros menores. Las herramientas de análisis del fraude pueden ayudar a mitigar las reclamaciones infladas:
Los peritos de seguros verifican manualmente las reclamaciones potencialmente infladas.
Evasión de primas implica dar información falsa a la compañía de seguros para reducir artificialmente el perfil de riesgo y pagar primas más bajas por una póliza concreta. Las herramientas de análisis del fraude pueden ayudar a:
Pólizas falsas son pólizas falsificadas creadas y vendidas por estafadores que se hacen pasar por agentes de seguros. El cliente lo descubre cuando va a presentar una reclamación. El software de análisis de fraudes detecta las pólizas falsas mediante:
Las compañías de seguros también tienen el deber para con la sociedad de identificar patrones de pólizas falsas emitidas en su nombre. La presentación de estos análisis a las fuerzas de seguridad ayuda a descubrir falsos chanchullos políticos.
El fraude sanitario puede producirse en cualquier parte del sistema sanitario, incluidas las aseguradoras sanitarias públicas. La víctima es el pagador, que puede ser uno o varios de varios grupos:
Los culpables suelen ser los proveedores de servicios sanitarios o los pacientes. El fraude sanitario suele cometerse mediante reclamaciones falsas, incluida la facturación de servicios no prestados y la sobrefacturación.
Facturación de servicios no prestados se refiere al cobro a los pagadores de servicios (como pruebas y tratamientos) que no se realizaron al paciente. Para detectar este tipo de fraude, las herramientas de análisis pueden:
Upcoding se refiere a la mala práctica de facturar una categoría de servicios más cara de la que se prestó. Las herramientas de análisis del fraude emplean varios métodos para detectar la codificación ascendente, como por ejemplo
Muchos vendedores de comercio electrónico son pequeñas y medianas empresas que no son necesariamente expertas en tecnología. Por tanto, recae en las plataformas de comercio electrónico la responsabilidad de detectar las actividades fraudulentas y ponerles freno. El fraude en el comercio electrónico y minorista puede presentarse de varias formas:
Apropiación de cuentas se refiere a que un usuario pierde el control de su cuenta a manos de estafadores que abusan de ella realizando compras no autorizadas. Esto suele ocurrir por un error del usuario o por falta de atención a consideraciones de seguridad como las contraseñas y las estafas de phishing.
Las plataformas de comercio electrónico pueden detectar la usurpación de cuentas utilizando técnicas como:
Devoluciones falsas se producen cuando actores maliciosos devuelven artículos diferentes del artículo comprado, como pedir un artículo caro y devolver una falsificación. También incluye la devolución de productos usados que no puedan revenderse. Para protegerte contra las devoluciones falsas, la analítica del fraude puede:
Compras fraudulentas implican transacciones no autorizadas utilizando información de pago robada o falsa y cuentas comprometidas. Pueden provocar pérdidas tanto a los vendedores como a los compradores desprevenidos. El análisis del fraude puede ayudar a señalar las compras potencialmente fraudulentas mediante la supervisión de las transacciones para identificar patrones como:
Fraude de devolución de cargo consiste en abusar de la política de devolución de cargo de la tarjeta de crédito para reclamar el reembolso de compras legítimas. La analítica del fraude puede ayudar a protegerse contra el fraude por devolución de cargo utilizando:
Las herramientas de análisis del fraude utilizan una gama común de técnicas, adaptándolas a los distintos contextos, conjuntos de datos y comportamientos de los defraudadores en ese ámbito.
Todos los métodos de análisis del fraude tienen dos objetivos clave:
Los defraudadores suelen mostrar un comportamiento muy diferente al de los clientes legítimos. La detección de anomalías ayuda a identificar comportamientos inusuales que apuntan a una actividad potencialmente fraudulenta. Abarca una serie de métodos:
Consulta el curso Detección de anomalías en Python para comprender mejor esta técnica.
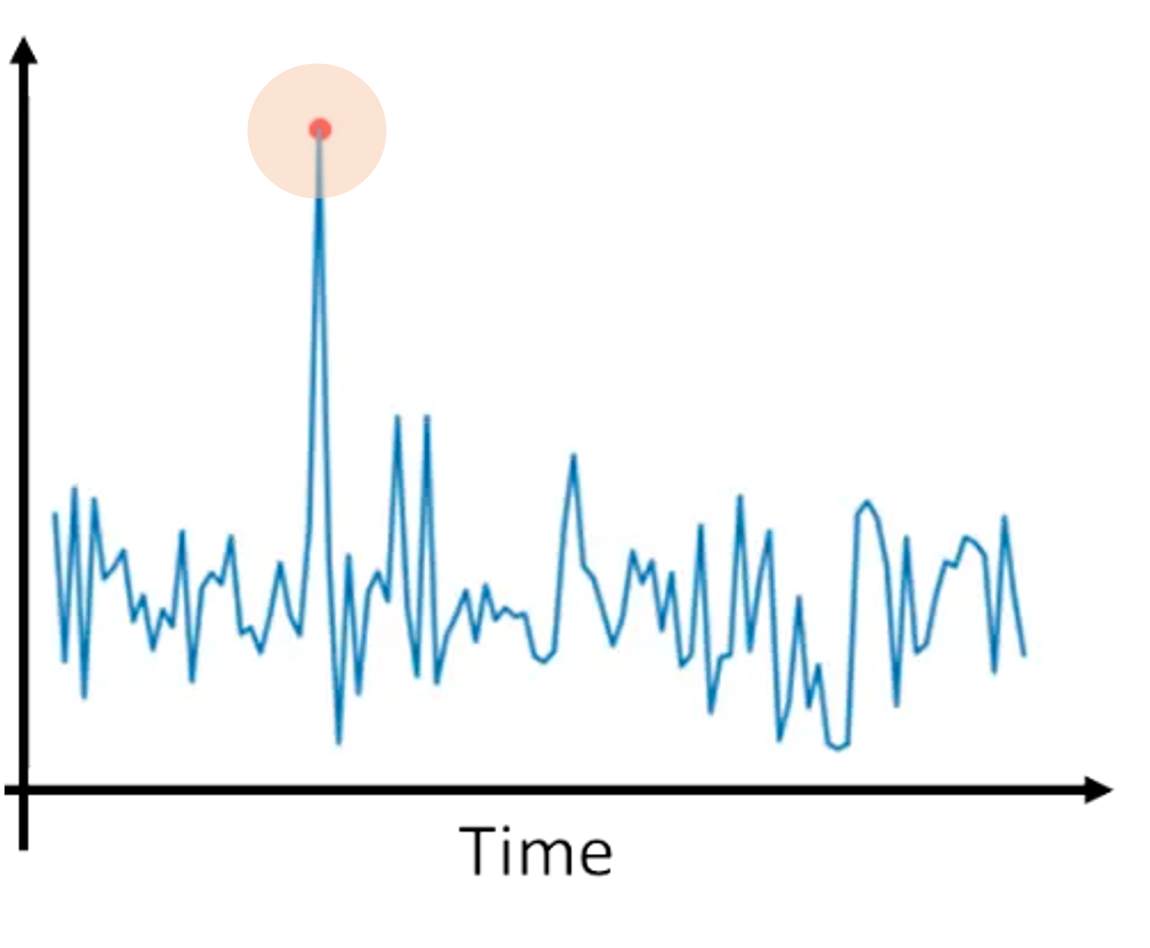
Ilustración de la detección de anomalías. Fuente de la imagen: Comprender la IA
El aprendizaje automático supervisado es un método probado de detección de anomalías. Los humanos etiquetan conjuntos de datos basándose en casos conocidos de comportamientos fraudulentos anteriores. A continuación, los algoritmos de aprendizaje automático se entrenan en conjuntos de datos etiquetados para predecir la probabilidad de que una nueva transacción sea fraudulenta.
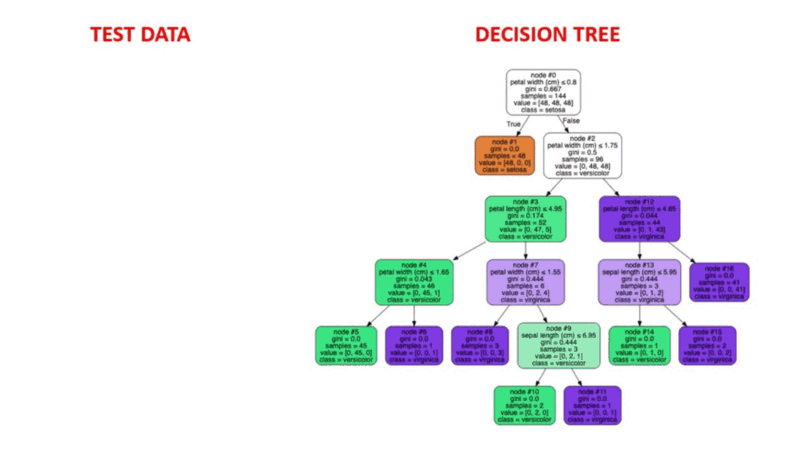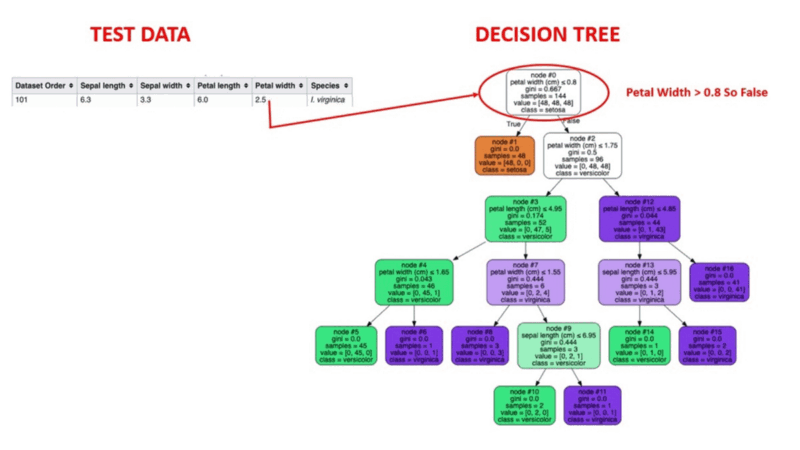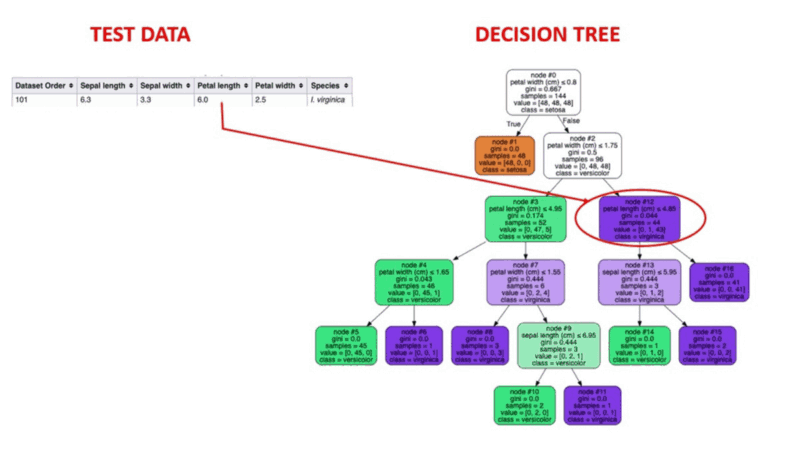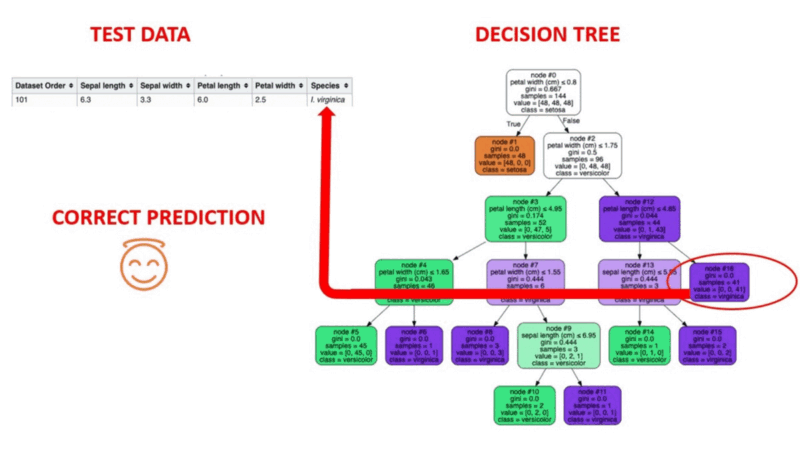
Ilustración animada de cómo funcionan los árboles de decisión. Fuente de la imagen: Aprendizaje automático supervisado
Consulta el tema del curso Aprendizaje automático supervisado en Python para saber más sobre estas técnicas.
Los algoritmos supervisados de aprendizaje automático, que predicen basándose en comportamientos anteriores, pierden eficacia a medida que los defraudadores adoptan nuevos métodos.
El aprendizaje automático no supervisado es útil para predecir patrones desconocidos en los datos. La otra ventaja de los métodos no supervisados es que no necesitas gastar recursos humanos para etiquetar grandes conjuntos de datos. El algoritmo detecta patrones por sí mismo.
Cómo funciona la agrupación. Fuente de la imagen: Agrupación en el aprendizaje automático
Consulta el Aprendizaje no supervisado en Python para saber más sobre las técnicas mencionadas.
Los métodos tradicionales de detección del fraude mediante el cotejo de patrones de comportamiento sospechoso son eficaces para las cuentas individuales. Sin embargo, los defraudadores suelen operar como grupos de individuos que utilizan un conjunto de dispositivos, cuentas de correo electrónico y direcciones físicas, lo que dificulta el seguimiento de comportamientos sospechosos cuando se considera esa cuenta de forma aislada.
Consulta el curso Introducción al Análisis de Redes en Python para profundizar en estas técnicas.
Muchas formas de fraude, como las reclamaciones falsas de seguros, las opiniones falsas de clientes, los correos electrónicos de phishing y similares, se basan en bloques de texto. Analizar el contenido de sus textos suele dar pistas para distinguir la actividad genuina de los clientes de los intentos de fraude.
Consulta la pista de habilidades Procesamiento del Lenguaje Natural en Python para profundizar en el tema.
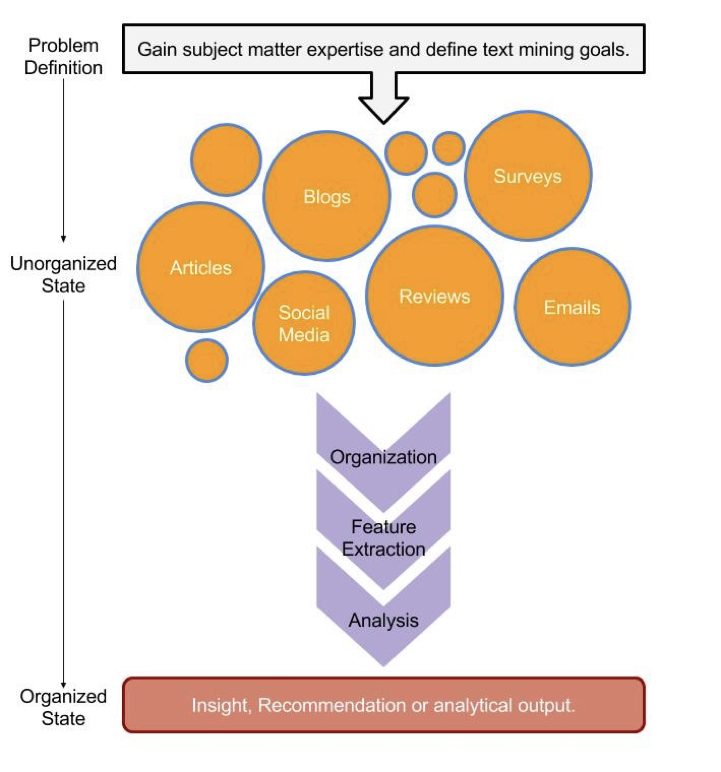
Ilustración del flujo de trabajo de la minería de textos. Fuente de la imagen: Minería de textos con bolsas de palabras en R
En esta sección, damos una visión general de alto nivel de los principios prácticos de la aplicación de los flujos de trabajo de detección del fraude.
Todos los algoritmos de detección del fraude se basan en analizar e identificar patrones observados en grandes conjuntos de datos. Por tanto, los conjuntos de datos de alta calidad, relevantes y curados, como los registros de transacciones y los perfiles de clientes, son cruciales para entrenar estos algoritmos.
Tras recopilar datos, el siguiente paso lógico es utilizarlos para entrenar modelos de detección del fraude. Los datos brutos suelen ser inadecuados para entrenar modelos. Por tanto, es necesario limpiar y normalizar los datos antes de utilizarlos como conjunto de datos de entrenamiento. El preprocesamiento de datos, junto con la ingeniería de rasgos, abarca estos pasos.
Los algoritmos de análisis del fraude se basan, en esencia, en técnicas de aprendizaje automático. Los datos históricos son la base para entrenar los algoritmos de aprendizaje automático. Tras recoger y limpiar los datos, el siguiente paso es entrenar los modelos. Durante el entrenamiento, el modelo aprende a predecir qué transacciones o perfiles de usuario tienen más probabilidades de ser fraudulentos.
Además de señalar los comportamientos potencialmente fraudulentos, es igualmente importante no obstaculizar a los usuarios normales. Un falso positivo es cuando el modelo señala como fraudulenta una transacción auténtica. Minimizar los falsos positivos es importante para mantener una buena experiencia del cliente. Para asegurarnos de ello, el modelo entrenado se evalúa utilizando diversas métricas.
Tras cometer un fraude, cada vez resulta más difícil recuperar los fondos o bienes robados al defraudador. Así, el objetivo es detectar y prevenir el fraude en tiempo real, antes de que se ejecute la transacción. Integrar el análisis del fraude en la cadena de procesamiento de las transacciones permite detectarlo en tiempo real. Hay dos formas de hacerlo:
Las partes interesadas, como la dirección de la empresa, los científicos de datos, los responsables de cumplimiento, los analistas de fraude y los equipos de seguridad, supervisan los resultados de los esfuerzos continuos de detección del fraude. Herramientas como cuadros de mando, alertas en tiempo real e informes automatizados facilitan el seguimiento y la supervisión.
Valida tus habilidades profesionales de científico de datos.

¡Aprende más sobre analítica y aprendizaje automático con estos cursos!
Curso
Curso
Curso
blog
Javier Canales Luna
14 min
blog
Matt Crabtree
10 min
blog
Kurtis Pykes
13 min
blog
Matt Crabtree
14 min
Tutorial
Zoumana Keita

