
Course
Fraud Detection in Python
4 hr
22K
Enable data-driven decision-making with DataCamp for Business. Comprehensive courses, assignments, and performance tracking tailored for your team of 2 or more.

In this section, we explore broad categories of fraudulent transactions, discuss common examples of fraud within each category, and how to use analytics tools to detect and prevent them.
Financial fraud is perhaps the most well-known and widespread form of fraud. The victims are typically financial institutions and their customers. The culprits are usually fraudsters pretending to be either customers or representatives of financial institutions.
Credit card fraud is the unauthorized use of a card to purchase goods or withdraw money at an ATM. In most cases, this is done using stolen card details. Fraud analytics can help detect card fraud by looking for common patterns like:
Identity theft happens when someone’s personal information (like bank account numbers, government-issued ID numbers, email passwords, etc.) gets stolen. This information can be used to impersonate the individual to take out loans, open overdraft accounts, and engage in other large financial transactions. Fraud analytics helps in such situations by flagging suspicious behavior like:
Payment fraud is the use of deceptive means to convince an individual or a business to make a payment for something they are not purchasing. It includes:
Analytics can help with payment fraud by monitoring and flagging transactions that:
Insurance fraud includes claiming large payouts for minor incidents and paying small premiums for risky policies. The victim is typically the insurance company, while the culprits pretend to be customers or insurance agents.
Fraudulent claims are about accidents that never happened. To detect such claims, analytics tools:
Inflated claims exaggerate the damage incurred and the claimed insurance payout in minor incidents. Fraud analytics tools can help with mitigating inflated claims by:
Insurance surveyors manually verify potentially inflated claims.
Premium evasion involves giving false information to the insurance company to artificially reduce the risk profile and pay lower premiums for a particular policy. Fraud analytics tools can help to:
Fake policies are counterfeit policies created and sold by scammers pretending to be insurance agents. The customer discovers it when they go to raise a claim. Fraud analytics software detects fake policies by:
Insurance companies also have a duty to society to identify patterns of fake policies issued in their name. Presenting these analyses to law enforcement helps to catch fake policy rackets.
Healthcare fraud can happen in any part of the healthcare system, including public health insurers. The victim is the payer, who can be one or more of various groups:
The culprits are often healthcare service providers or patients. Healthcare fraud is typically committed through false claims, including billing for services not rendered and upcoding.
Billing for services not rendered refers to charging payers for services (such as tests and treatments) that were not performed on the patient. To detect this kind of fraud, analytics tools can:
Upcoding refers to the malpractice of billing for a more expensive service category than was provided. Fraud analytics tools employ various methods to detect upcoding, such as:
Many e-commerce sellers are small and medium enterprises that are not necessarily tech-savvy. Thus, the onus lies on e-commerce platforms to detect fraudulent activity and curb it. E-commerce and retail fraud can happen in various forms:
Account takeovers refer to a user losing control of their account to fraudsters who abuse it by making unauthorized purchases. This usually happens due to user error or inattentiveness to security considerations like passwords and phishing scams.
E-commerce platforms can detect account takeover using techniques like:
Fake returns occur when malicious actors return items different from the purchased item, like ordering an expensive item and returning a counterfeit. It also includes returning used products that cannot be resold. To protect against fake returns, fraud analytics can:
Fraudulent purchases involve unauthorized transactions using stolen or fake payment information and compromised accounts. They can lead to losses for both sellers and unsuspecting buyers. Fraud analytics can help to flag potentially fraudulent purchases by monitoring transactions to identify patterns like:
Chargeback fraud involves abusing the credit card’s chargeback policy to claim refunds on legitimate purchases. Fraud analytics can help protect against chargeback fraud by using:
Fraud analytics tools use a common range of techniques by adapting them to different contexts, datasets, and behaviors of fraudsters in that domain.
All fraud analytics methods have two key goals:
Fraudsters often display significantly different behavior compared to legitimate customers. Anomaly detection helps to identify unusual behaviors that point to potentially fraudulent activity. It encompasses a range of methods:
Check out the Anomaly Detection in Python course to further understand this technique.
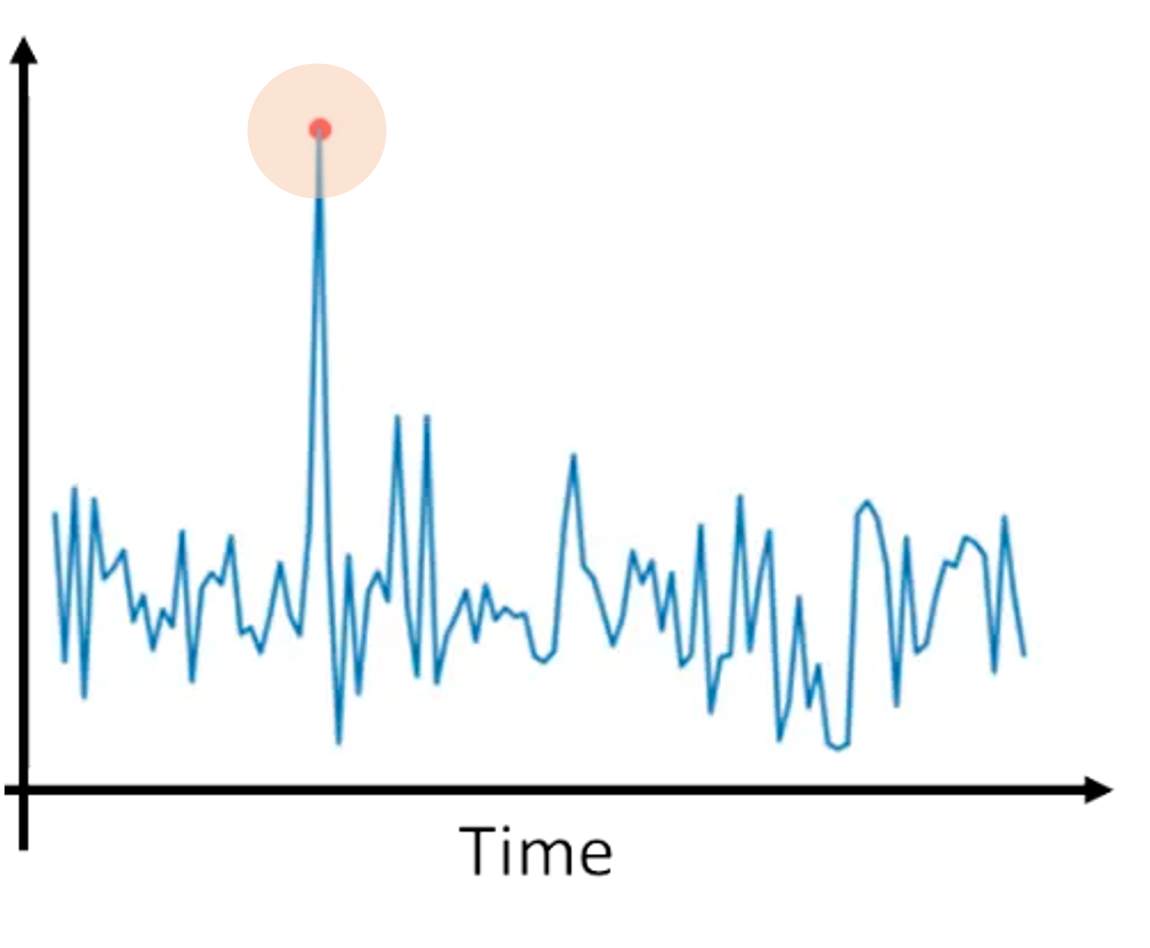
Illustration of anomaly detection. Image source: Understanding AI
Supervised machine learning is a proven method of anomaly detection. Humans label datasets based on known instances of past fraudulent behavior. Machine learning algorithms are then trained on labeled datasets to predict the likelihood of a new transaction being fraudulent.
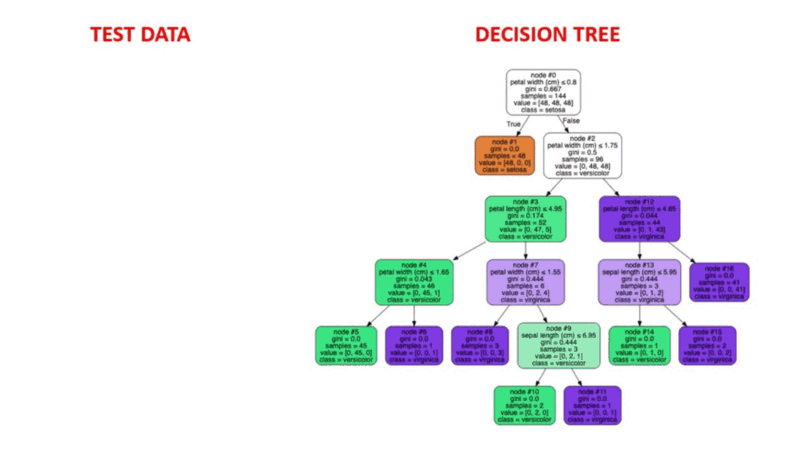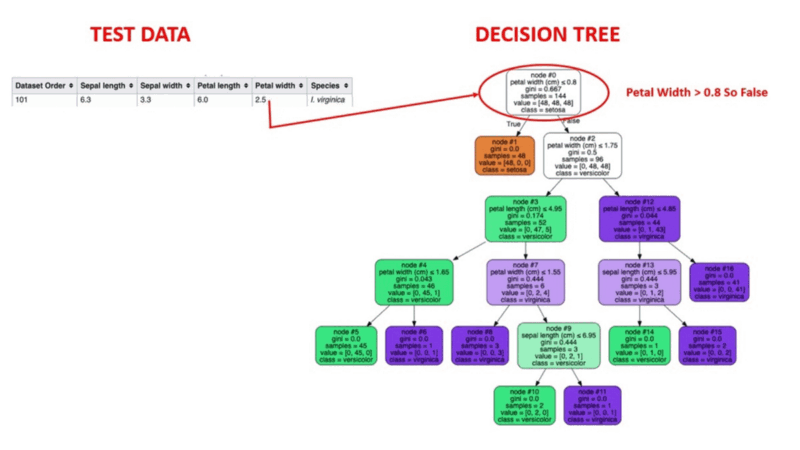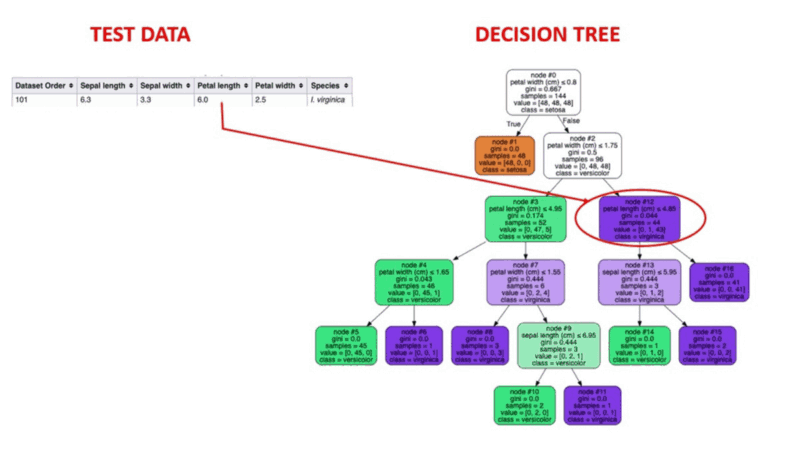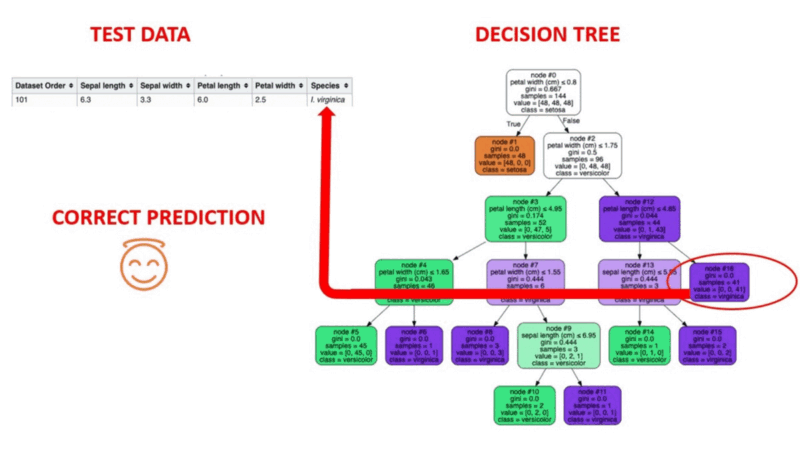
Animated Illustration of how decision trees work. Image source: Supervised Machine Learning
Check the Supervised Machine Learning in Python course track to learn more about these techniques.
Supervised machine learning algorithms, which predict based on past behaviors, become less effective as fraudsters adopt new methods.
Unsupervised machine learning is helpful in predicting unknown patterns in the data. The other advantage of unsupervised methods is that you don’t need to spend human resources to label large datasets. The algorithm detects patterns by itself.
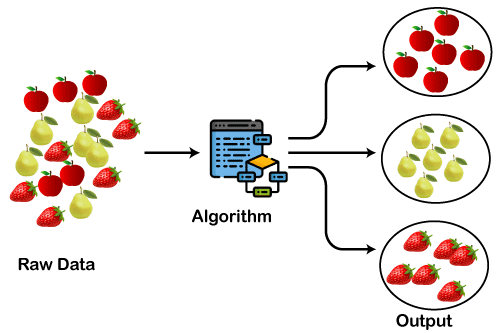
How clustering works. Image source: Clustering in Machine Learning
Check the Unsupervised Learning in Python to learn more about the mentioned techniques.
Traditional methods of fraud detection by pattern matching for suspicious behavior are effective for individual accounts. However, fraudsters often operate as groups of individuals using a set of devices, email accounts, and physical addresses, making it challenging to track suspicious behavior when that account is considered in isolation.
Check the Introduction to Network Analysis in Python course for a deeper understanding of these techniques.
Many forms of fraud, like false insurance claims, fake customer reviews, phishing emails, and the like, are based on blocks of text. Analyzing their text content often leads to clues to distinguish genuine customer activity from attempts at fraud.
Check the Natural Language Processing in Python skill track for a more in-depth understanding of the subject.
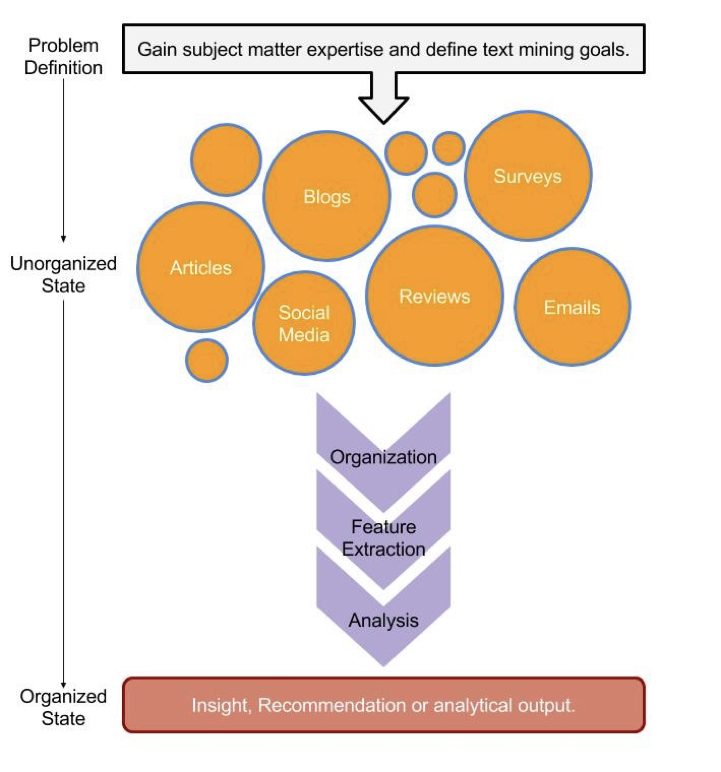
Illustration of the text mining workflow. Image source: Text Mining with Bag-of-Words in R
In this section, we give a high-level overview of the practical principles of implementing fraud detection workflows.
All fraud detection algorithms are based on analyzing and identifying patterns observed in large datasets. Thus, high-quality, relevant, and curated datasets like transaction logs and customer profiles are crucial to train these algorithms.
After collecting data, the next logical step is to use it to train fraud detection models. Raw data is typically unsuitable for training models. Thus, cleaning and normalizing the data before using it as a training dataset is necessary. Data preprocessing, together with feature engineering, covers these steps.
Fraud analytics algorithms are, at their core, built upon machine learning techniques. Historical data is the basis for training machine learning algorithms. After collecting and cleaning the data, the next step is to train the models. During training, the model learns to predict which transactions or user profiles are more likely to be fraudulent.
Besides flagging potentially fraudulent behavior, it is equally important not to obstruct regular users. A false positive is when the model flags a genuine transaction as fraudulent. Minimizing false positives is important to maintain a good customer experience. To ensure this, the trained model is evaluated using various metrics.
After committing fraud, it becomes increasingly challenging to recover the stolen funds or goods from the fraudster. Thus, the goal is to detect and prevent fraud in real time before the transaction is executed. Integrating fraud analytics into the transaction processing pipeline enables real-time detection. There are two ways of doing this:
Stakeholders like company management, data scientists, compliance officers, fraud analysts, and security teams monitor the results of ongoing fraud detection efforts. Tools like dashboards, real-time alerts, and automated reports facilitate monitoring and supervision.
Validate your professional data scientist skills.

Learn more about analytics and machine learning with these courses!
Course
Course
Course
blog
Elena Kosourova
11 min
blog
Joleen Bothma
9 min
blog
Joleen Bothma
10 min
blog
Andrea Valenzuela
12 min
blog
Javier Canales Luna
14 min
podcast
