Curso
Detecção de Fraudes em Python
4 h
22K
Permita que você tome decisões baseadas em dados com o DataCamp for Business. Cursos abrangentes, tarefas e acompanhamento de desempenho personalizados para sua equipe de 2 ou mais pessoas.

Nesta seção, exploramos categorias amplas de transações fraudulentas, discutimos exemplos comuns de fraude em cada categoria e como usar ferramentas de análise para detectá-las e evitá-las.
A fraude financeira é talvez a forma mais conhecida e difundida de fraude. Normalmente, as vítimas são instituições financeiras e seus clientes. Os culpados geralmente são fraudadores que fingem ser clientes ou representantes de instituições financeiras.
Fraude de cartão de crédito é o uso não autorizado de um cartão para comprar produtos ou sacar dinheiro em um caixa eletrônico. Na maioria dos casos, isso é feito usando detalhes de cartões roubados. A análise de fraudes pode ajudar a detectar fraudes com cartões, procurando padrões comuns como:
Roubo de identidade acontece quando as informações pessoais de alguém (como números de contas bancárias, números de identidade emitidos pelo governo, senhas de e-mail etc.) são roubadas. Essas informações podem ser usadas para se passar pelo indivíduo para fazer empréstimos, abrir contas de cheque especial e participar de outras transações financeiras de grande porte. A análise de fraudes ajuda nessas situações, sinalizando comportamentos suspeitos, como:
Fraude de pagamento é o uso de meios enganosos para convencer um indivíduo ou uma empresa a fazer um pagamento por algo que não está comprando. Ele inclui:
O Analytics pode ajudar com a fraude de pagamento, monitorando e sinalizando transações que:
A fraude em seguros inclui a reivindicação de grandes pagamentos por incidentes menores e o pagamento de pequenos prêmios por apólices de risco. Normalmente, a vítima é a companhia de seguros, enquanto os criminosos fingem ser clientes ou agentes de seguros.
Reivindicações fraudulentas são sobre acidentes que nunca aconteceram. Para detectar essas alegações, as ferramentas de análise:
Sinistros inflacionados exageram os danos incorridos e o pagamento de seguro reivindicado em incidentes menores. As ferramentas de análise de fraudes podem ajudar a reduzir os pedidos de indenização inflados:
Os inspetores de seguros verificam manualmente os sinistros potencialmente inflados.
Evasão de prêmios envolve fornecer informações falsas à companhia de seguros para reduzir artificialmente o perfil de risco e pagar prêmios mais baixos por uma determinada apólice. As ferramentas de análise de fraudes podem ajudar você a:
Apólices falsas são apólices falsificadas criadas e vendidas por golpistas que fingem ser agentes de seguros. O cliente descobre isso quando vai fazer uma reclamação. O software de análise de fraude detecta políticas falsas por meio de:
As seguradoras também têm o dever para com a sociedade de identificar padrões de apólices falsas emitidas em seu nome. A apresentação dessas análises às autoridades policiais ajuda a capturar falsos esquemas de políticas.
A fraude no setor de saúde pode ocorrer em qualquer parte do sistema de saúde, inclusive nas seguradoras de saúde pública. A vítima é o pagador, que pode ser um ou mais de vários grupos:
Os culpados geralmente são os prestadores de serviços de saúde ou os pacientes. A fraude no setor de saúde é normalmente cometida por meio de alegações falsas, incluindo o faturamento de serviços não prestados e a codificação excessiva.
Faturamento de serviços não prestados refere-se à cobrança de pagadores por serviços (como exames e tratamentos) que não foram realizados no paciente. Para detectar esse tipo de fraude, as ferramentas de análise podem:
Upcoding refere-se à má prática de cobrar por uma categoria de serviço mais cara do que a fornecida. As ferramentas de análise de fraude empregam vários métodos para detectar upcoding, como:
Muitos vendedores de comércio eletrônico são pequenas e médias empresas que não são necessariamente conhecedoras de tecnologia. Assim, o ônus recai sobre as plataformas de comércio eletrônico para detectar atividades fraudulentas e coibi-las. As fraudes no comércio eletrônico e no varejo podem ocorrer de várias formas:
Aquisições de contas referem-se a um usuário que perde o controle de sua conta para fraudadores que abusam dela fazendo compras não autorizadas. Isso geralmente acontece devido a erro do usuário ou falta de atenção às considerações de segurança, como senhas e golpes de phishing.
As plataformas de comércio eletrônico podem detectar o sequestro de contas usando técnicas como:
Devoluções falsas ocorrem quando agentes mal-intencionados devolvem itens diferentes do item comprado, como pedir um item caro e devolver uma falsificação. Isso também inclui a devolução de produtos usados que não podem ser revendidos. Para se proteger contra devoluções falsas, a análise de fraudes pode:
Compras fraudulentas envolvem transações não autorizadas usando informações de pagamento roubadas ou falsas e contas comprometidas. Eles podem levar a perdas tanto para vendedores quanto para compradores desavisados. A análise de fraudes pode ajudar a sinalizar compras potencialmente fraudulentas, monitorando as transações para identificar padrões como:
Fraude de estorno envolve o abuso da política de estorno do cartão de crédito para solicitar reembolsos de compras legítimas. A análise de fraude pode ajudar você a se proteger contra fraudes de estorno usando:
As ferramentas de análise de fraude usam uma gama comum de técnicas, adaptando-as a diferentes contextos, conjuntos de dados e comportamentos de fraudadores nesse domínio.
Todos os métodos de análise de fraude têm dois objetivos principais:
Os fraudadores geralmente apresentam um comportamento significativamente diferente dos clientes legítimos. A detecção de anomalias ajuda a identificar comportamentos incomuns que apontam para atividades potencialmente fraudulentas. Ele abrange uma série de métodos:
Confira o curso Anomaly Detection in Python para entender melhor essa técnica.
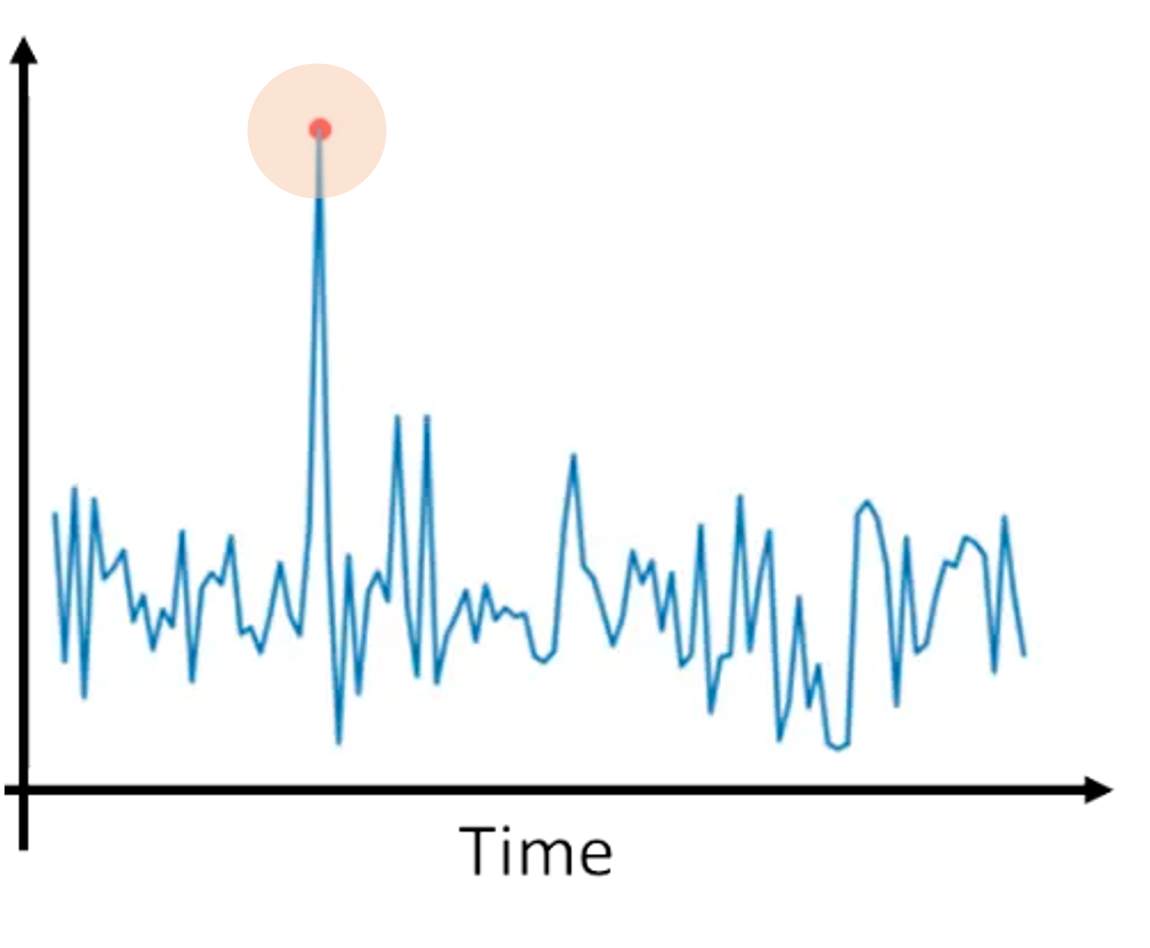
Ilustração da detecção de anomalias. Fonte da imagem: Entendendo a IA
O aprendizado de máquina supervisionado é um método comprovado de detecção de anomalias. Os seres humanos rotulam conjuntos de dados com base em instâncias conhecidas de comportamento fraudulento anterior. Os algoritmos de aprendizado de máquina são então treinados em conjuntos de dados rotulados para prever a probabilidade de uma nova transação ser fraudulenta.
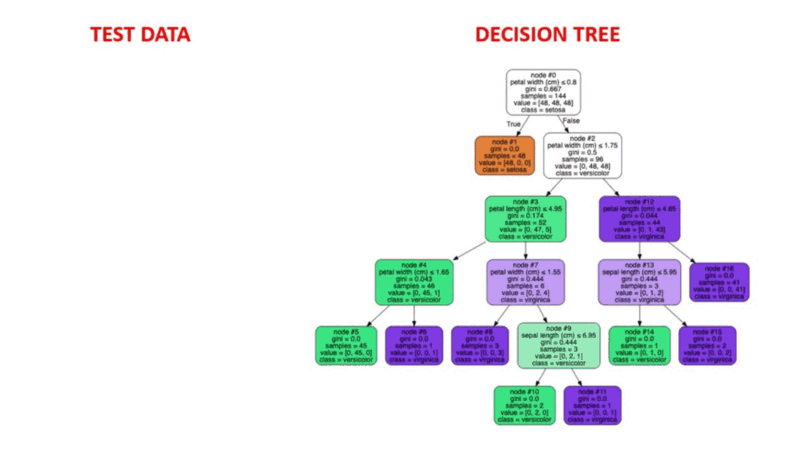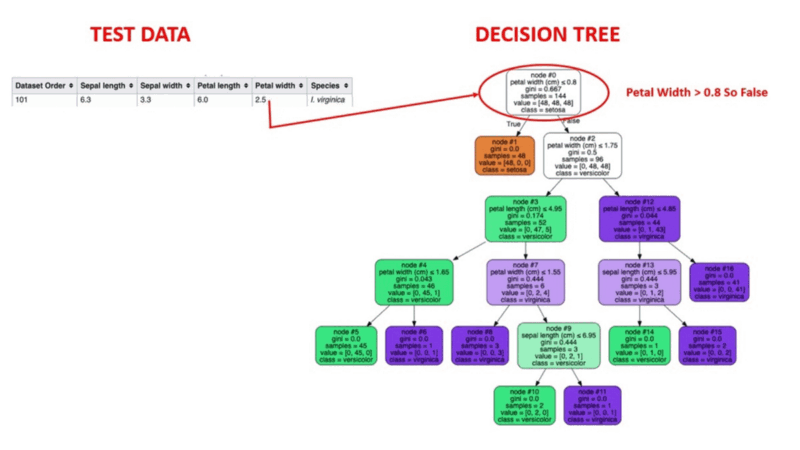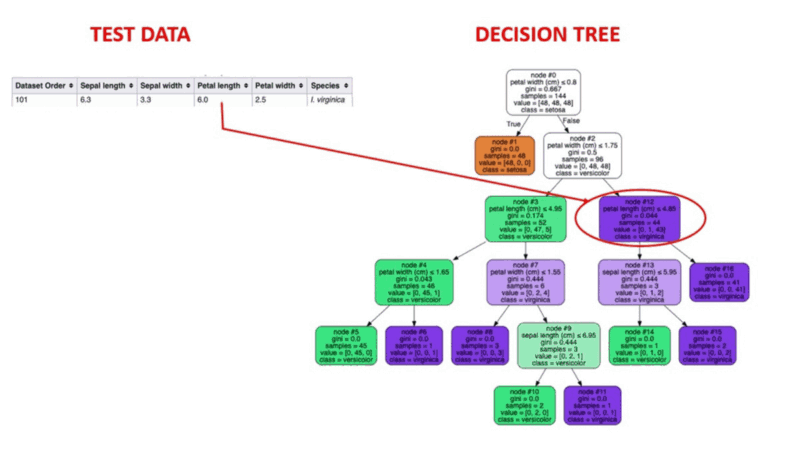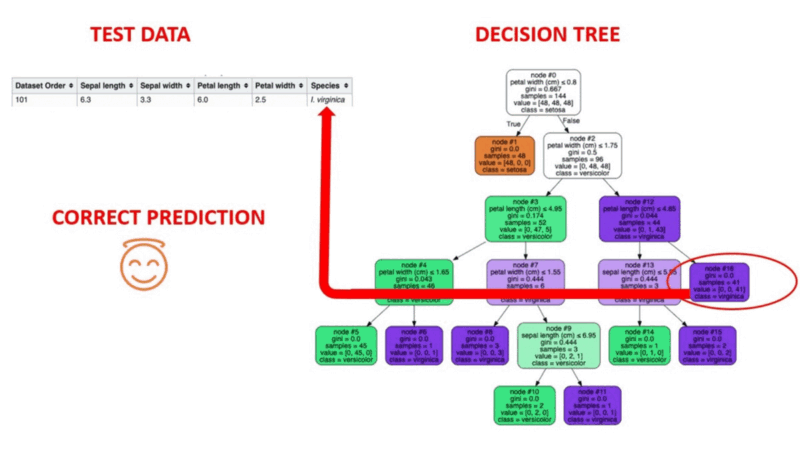
Ilustração animada de como funcionam as árvores de decisão. Fonte da imagem: Aprendizado de máquina supervisionado
Consulte a trilha do curso Supervised Machine Learning in Python para saber mais sobre essas técnicas.
Os algoritmos de aprendizado de máquina supervisionados, que fazem previsões com base em comportamentos anteriores, tornam-se menos eficazes à medida que os fraudadores adotam novos métodos.
O aprendizado de máquina não supervisionado é útil para prever padrões desconhecidos nos dados. A outra vantagem dos métodos não supervisionados é que você não precisa gastar recursos humanos para rotular grandes conjuntos de dados. O algoritmo detecta padrões por si só.
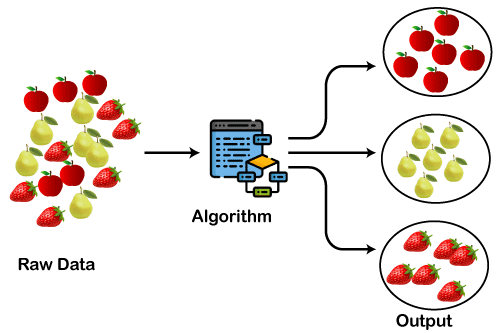
Como funciona o clustering. Fonte da imagem: Agrupamento no aprendizado de máquina
Consulte a seção Aprendizado não supervisionado em Python para saber mais sobre as técnicas mencionadas.
Os métodos tradicionais de detecção de fraude por meio da correspondência de padrões de comportamento suspeito são eficazes para contas individuais. No entanto, os fraudadores geralmente operam como grupos de indivíduos que usam um conjunto de dispositivos, contas de e-mail e endereços físicos, o que torna difícil rastrear comportamentos suspeitos quando essa conta é considerada isoladamente.
Consulte o curso Introdução à análise de rede em Python para obter uma compreensão mais profunda dessas técnicas.
Muitas formas de fraude, como falsas reivindicações de seguro, avaliações falsas de clientes, e-mails de phishing e similares, são baseadas em blocos de texto. A análise do conteúdo do texto geralmente leva a pistas para distinguir a atividade genuína do cliente das tentativas de fraude.
Consulte a trilha de habilidades Processamento de linguagem natural em Python para obter uma compreensão mais aprofundada do assunto.
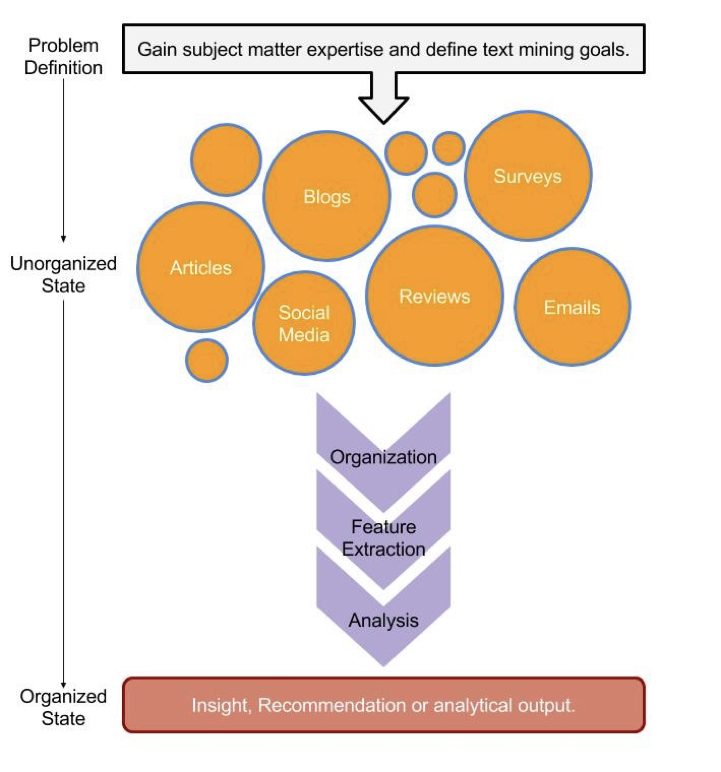
Ilustração do fluxo de trabalho de mineração de texto. Fonte da imagem: Mineração de texto com saco de palavras em R
Nesta seção, apresentamos uma visão geral de alto nível dos princípios práticos da implementação de fluxos de trabalho de detecção de fraudes.
Todos os algoritmos de detecção de fraude são baseados na análise e na identificação de padrões observados em grandes conjuntos de dados. Assim, conjuntos de dados de alta qualidade, relevantes e com curadoria, como registros de transações e perfis de clientes, são essenciais para treinar esses algoritmos.
Depois de coletar dados, a próxima etapa lógica é usá-los para treinar modelos de detecção de fraudes. Normalmente, os dados brutos não são adequados para o treinamento de modelos. Portanto, é necessário limpar e normalizar os dados antes de usá-los como um conjunto de dados de treinamento. O pré-processamento de dados, juntamente com a engenharia de recursos, abrange essas etapas.
Os algoritmos de análise de fraudes são, em sua essência, desenvolvidos com base em técnicas de aprendizado de máquina. Os dados históricos são a base para o treinamento de algoritmos de aprendizado de máquina. Depois de coletar e limpar os dados, a próxima etapa é treinar os modelos. Durante o treinamento, o modelo aprende a prever quais transações ou perfis de usuário têm maior probabilidade de serem fraudulentos.
Além de sinalizar comportamentos potencialmente fraudulentos, é igualmente importante não obstruir os usuários comuns. Um falso positivo ocorre quando o modelo identifica uma transação genuína como fraudulenta. Minimizar os falsos positivos é importante para manter uma boa experiência do cliente. Para garantir isso, o modelo treinado é avaliado usando várias métricas.
Depois de cometer uma fraude, torna-se cada vez mais difícil recuperar os fundos ou bens roubados do fraudador. Assim, o objetivo é detectar e evitar fraudes em tempo real antes que a transação seja executada. A integração da análise de fraudes no pipeline de processamento de transações permite a detecção em tempo real. Há duas maneiras de fazer isso:
As partes interessadas, como a administração da empresa, cientistas de dados, diretores de conformidade, analistas de fraude e equipes de segurança, monitoram os resultados dos esforços contínuos de detecção de fraude. Ferramentas como painéis de controle, alertas em tempo real e relatórios automatizados facilitam o monitoramento e a supervisão.
Valide suas habilidades profissionais de cientista de dados.

Saiba mais sobre análise e aprendizado de máquina com estes cursos!
Curso
Curso
Curso
blog
Javier Canales Luna
14 min
blog
Matt Crabtree
10 min
blog
Austin Chia
9 min
blog
Tim Lu
12 min
blog
Javier Canales Luna
12 min


