
Kursus
Fundamental Big Data dengan PySpark
4 Hr
65.7K
Jalankan dan edit kode dari tutorial ini secara online.
Jalankan kodeSparkSession adalah titik masuk ke semua fungsionalitas di Spark, dan diperlukan jika Anda ingin membangun dataframe di PySpark. Jalankan baris kode berikut untuk menginisialisasi SparkSession:
from pyspark.sql import SparkSession # add this import
spark = (
SparkSession.builder
.appName("DataCamp PySpark Tutorial")
.config("spark.memory.offHeap.enabled", "true")
.config("spark.memory.offHeap.size", "10g")
.getOrCreate()
)
Menggunakan kode di atas, kita membangun sesi Spark dan menetapkan nama untuk aplikasinya. Lalu, data di-cache di memori off-heap untuk menghindari penyimpanan langsung ke disk, dan jumlah memori ditentukan secara manual.
Sekarang kita dapat membaca dataset. Anda dapat mengunduh dataset e-commerce contoh dari tutorial PySpark Read CSV kami atau menggunakan file CSV Anda sendiri:
df = spark.read.csv("datacamp_ecommerce.csv", header=True, escape='"', inferSchema=True)Perhatikan bahwa kami mendefinisikan karakter escape untuk menghindari koma di file .csv saat parsing.
Mari lihat kepala DataFrame menggunakan fungsi show():
df.show(5,0)DataFrame terdiri dari 8 variabel:
InvoiceNo: Pengidentifikasi unik setiap faktur pelanggan.
StockCode: Pengidentifikasi unik setiap item dalam stok.
Description: Item yang dibeli pelanggan.
Quantity: Jumlah setiap item yang dibeli pelanggan dalam satu faktur.
InvoiceDate: Tanggal pembelian.
UnitPrice: Harga satu unit setiap item.
CustomerID: Pengidentifikasi unik yang ditetapkan untuk setiap pengguna.
Country: Negara asal pembelian dilakukan.
Sekarang kita telah melihat variabel dalam dataset ini, mari lakukan beberapa analisis data eksploratif untuk lebih memahami titik data ini:
df.count() # Answer: 2,500df.select('CustomerID').distinct().count() # Answer: 95 Negara mana yang paling banyak menjadi asal pembelian?
Negara mana yang paling banyak menjadi asal pembelian?Untuk menemukan negara yang paling banyak melakukan pembelian, kita perlu menggunakan klausa groupBy() di PySpark:
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()Tabel berikut akan dirender setelah menjalankan kode di atas:

Hampir semua pembelian di platform dilakukan dari United Kingdom, dan hanya sebagian kecil berasal dari negara seperti Jerman, Australia, dan Prancis.
Perhatikan bahwa data pada tabel di atas tidak disajikan dalam urutan jumlah pembelian. Untuk mengurutkan tabel ini, kita dapat menyertakan klausa orderBy():
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()Output yang ditampilkan sekarang diurutkan secara menurun:

Untuk mengetahui kapan pembelian terbaru dilakukan di platform, kita perlu mengonversi kolom InvoiceDate ke format timestamp dan menggunakan fungsi max() di PySpark:
df = df.withColumn(
"date",
coalesce(
to_timestamp(col("InvoiceDate"), "yy/MM/dd HH:mm"),
to_timestamp(col("InvoiceDate"), "yyyy-MM-dd HH:mm:ss"),
to_timestamp(col("InvoiceDate")) # best-effort fallback
)
)
df.select(max("date")).show()Anda akan melihat tabel berikut muncul setelah menjalankan kode di atas:
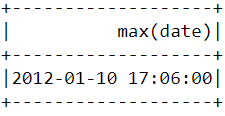
Mirip seperti di atas, fungsi min() dapat digunakan untuk menemukan tanggal dan waktu pembelian paling awal:
df.select(min("date")).show()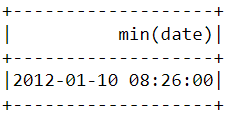
Perhatikan bahwa pembelian paling baru dan paling awal dilakukan pada hari yang sama, hanya berselang beberapa jam. Ini berarti dataset yang kita unduh hanya berisi informasi pembelian yang dilakukan pada satu hari.
Sekarang kita telah menganalisis dataset dan memahami setiap titik data dengan lebih baik, kita perlu menyiapkan data untuk dimasukkan ke dalam algoritma machine learning.
Mari lihat kembali kepala data frame untuk memahami bagaimana pra-pemrosesan akan dilakukan:
df.show(5,0)
Dari dataset di atas, kita perlu membuat beberapa segmen pelanggan berdasarkan perilaku pembelian masing-masing pengguna.
Variabel dalam dataset ini berada dalam format yang tidak mudah dimasukkan ke model segmentasi pelanggan. Fitur-fitur ini secara terpisah tidak banyak memberi tahu kita tentang perilaku pembelian pelanggan.
Karena itu, kita akan menggunakan variabel yang ada untuk menurunkan tiga fitur informatif baru - recency, frequency, dan monetary value (RFM).
RFM umum digunakan dalam pemasaran untuk mengevaluasi nilai klien berdasarkan:
Sekarang kita akan melakukan pra-pemrosesan data frame untuk membuat variabel di atas.
Pertama, mari hitung nilai recency - tanggal dan waktu terbaru pembelian yang dilakukan di platform. Ini dapat dicapai dalam dua langkah:
Kita akan mengurangkan setiap tanggal di data frame dari tanggal paling awal. Ini akan memberi tahu kita seberapa baru seorang pelanggan terlihat di data frame. Nilai 0 menunjukkan recency terendah, karena akan diberikan kepada orang yang terlihat melakukan pembelian pada tanggal paling awal.
df = df.withColumn("from_date", to_timestamp(lit("12/1/10 08:26"), "yy/MM/dd HH:mm"))
df2 = df.withColumn("recency", col("date").cast("long") - col("from_date").cast("long"))
w = Window.partitionBy("CustomerID").orderBy(desc("recency"))
df2 = df2.withColumn("rn", row_number().over(w)).filter(col("rn") == 1).drop("rn")Satu pelanggan dapat melakukan beberapa pembelian pada waktu yang berbeda. Kita perlu memilih hanya waktu terakhir mereka terlihat membeli produk, karena ini menunjukkan kapan pembelian paling baru dilakukan:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')Mari lihat kepala data frame baru. Kini terdapat variabel bernama “recency” yang ditambahkan:
df2.show(5,0)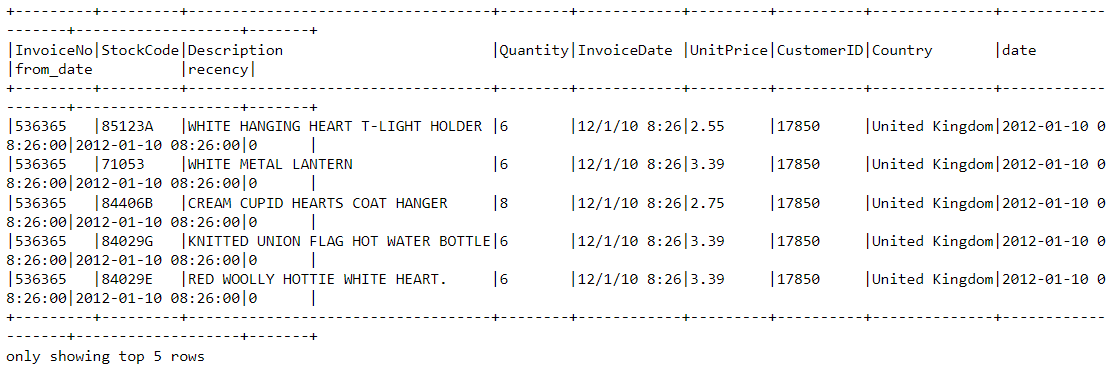
Cara yang lebih mudah untuk melihat semua variabel dalam sebuah DataFrame PySpark adalah menggunakan fungsi printSchema(). Ini setara dengan fungsi info() di Pandas:
df2.printSchema()Output yang dirender akan terlihat seperti ini:

Sekarang mari hitung nilai frequency - seberapa sering pelanggan membeli sesuatu di platform. Untuk melakukannya, kita hanya perlu melakukan group by setiap CustomerID dan menghitung jumlah item yang mereka beli. Untuk teknik pengelompokan yang lebih lanjut, lihat tutorial PySpark groupBy kami:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))Lihat kepala DataFrame baru yang baru saja kita buat:
df_freq.show(5,0)
Terdapat nilai frequency yang ditambahkan ke setiap pelanggan dalam DataFrame. DataFrame baru ini hanya memiliki dua kolom, dan kita perlu menggabungkannya dengan yang sebelumnya. Pelajari lebih lanjut tentang berbagai tipe join di tutorial PySpark Joins kami:
df3 = df2.join(df_freq,on='CustomerID',how='inner')Mari cetak skema DataFrame ini:
df3.printSchema()
Terakhir, mari hitung monetary value - total jumlah yang dibelanjakan oleh setiap pelanggan dalam DataFrame. Ada dua langkah untuk mencapainya:
Setiap CustomerID memiliki variabel Quantity dan UnitPrice untuk satu pembelian:

Untuk mendapatkan total jumlah yang dibelanjakan setiap pelanggan dalam satu pembelian, kita perlu mengalikan Quantity dengan UnitPrice:
m_val = df3.withColumn(
"TotalAmount",
col("Quantity").cast("double") * col("UnitPrice").cast("double")
)
Untuk menemukan total jumlah yang dibelanjakan oleh setiap pelanggan secara keseluruhan, kita hanya perlu melakukan group by kolom CustomerID dan menjumlahkan total jumlah yang dibelanjakan:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))Gabungkan DataFrame ini dengan semua variabel lainnya:
finaldf = m_val.join(df3,on='CustomerID',how='inner')Sekarang kita telah membuat semua variabel yang diperlukan untuk membangun model, jalankan baris kode berikut untuk memilih hanya kolom yang dibutuhkan dan menghapus baris duplikat dari DataFrame:
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()Lihat kepala DataFrame final untuk memastikan bahwa pra-pemrosesan telah dilakukan dengan tepat:

Sebelum membangun model segmentasi pelanggan, mari standarkan DataFrame untuk memastikan semua variabel berada pada skala yang serupa:
from pyspark.ml.feature import VectorAssembler, StandardScaler
assemble = VectorAssembler(
inputCols=["recency", "frequency", "monetary_value"],
outputCol="features"
)
assembled_data = assemble.transform(finaldf)
scale = StandardScaler(inputCol="features", outputCol="standardized")
data_scale = scale.fit(assembled_data)
data_scale_output = data_scale.transform(assembled_data)
Jalankan baris kode berikut untuk melihat seperti apa vektor fitur yang sudah distandarkan:
data_scale_output.select('standardized').show(2,truncate=False)
Inilah fitur berskala yang akan dimasukkan ke algoritma pengelompokan.
Jika Anda ingin mempelajari lebih lanjut tentang persiapan data dengan PySpark, ikuti kursus feature engineering ini di DataCamp.
Sekarang kita telah menyelesaikan semua analisis dan persiapan data, mari bangun model pengelompokan K-Means.
Algoritma akan dibuat menggunakan API machine learning PySpark.
Saat membangun model pengelompokan K-Means, pertama-tama kita perlu menentukan jumlah klaster atau grup yang kita inginkan dari algoritma. Jika kita memutuskan tiga klaster, misalnya, maka kita akan memiliki tiga segmen pelanggan.
Teknik paling populer untuk memutuskan berapa banyak klaster yang digunakan dalam K-Means disebut “metode siku (elbow method).”
Ini dilakukan dengan menjalankan algoritma K-Means untuk rentang jumlah klaster dan memvisualisasikan hasil model untuk setiap klaster. Plot akan memiliki titik belok yang terlihat seperti siku, dan kita cukup memilih jumlah klaster pada titik tersebut.
Baca tutorial K-Means clustering DataCamp ini untuk mempelajari lebih lanjut cara kerja algoritma.
Mari jalankan baris kode berikut untuk membangun algoritma pengelompokan K-Means dari 2 hingga 10 klaster:
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(
predictionCol="prediction",
featuresCol="standardized",
metricName="silhouette",
distanceMeasure="squaredEuclidean"
)
ks = range(2, 10)
cost = np.zeros(len(ks))
for idx, k in enumerate(ks):
km = KMeans(featuresCol="standardized", k=k)
model = km.fit(data_scale_output)
output = model.transform(data_scale_output)
cost[idx] = model.summary.trainingCost # WSSSE
Dengan kode di atas, kita telah berhasil membangun dan mengevaluasi model pengelompokan K-Means dengan 2 hingga 10 klaster. Hasilnya telah ditempatkan dalam sebuah array, dan sekarang dapat divisualisasikan dalam grafik garis:
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost) # cost has 8 values, one per k in range(2, 10)
df_cost.columns = ["cost"]
new_col = range(2, 10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()Kode di atas akan merender grafik berikut:
Dari plot di atas, kita dapat melihat ada titik belok yang terlihat seperti siku pada angka empat. Karena itu, kita akan melanjutkan membangun algoritma K-Means dengan empat klaster:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)Mari gunakan model yang kita buat untuk menetapkan klaster kepada setiap pelanggan dalam dataset:
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)Perhatikan bahwa ada kolom “prediction” dalam DataFrame ini yang memberi tahu kita klaster mana yang dimiliki setiap CustomerID:

Langkah terakhir dalam seluruh tutorial ini adalah menganalisis segmen pelanggan yang baru saja kita bangun.
Jalankan baris kode berikut untuk memvisualisasikan recency, frequency, dan monetary value dari setiap CustomerID dalam DataFrame:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
rfm_columns = ['recency', 'frequency', 'monetary_value']
for metric in rfm_columns:
sns.barplot(x='prediction', y=metric, data=avg_df)
plt.show()Kode di atas akan merender plot berikut:
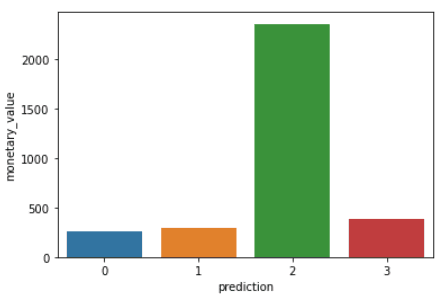
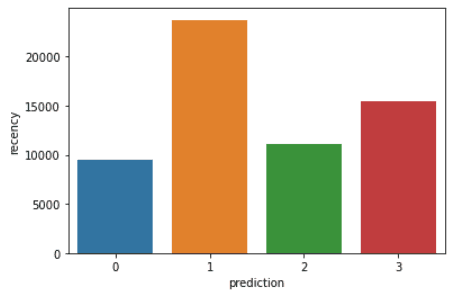
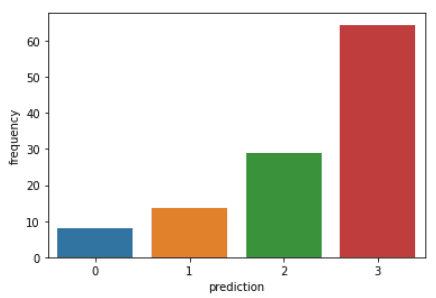
Berikut gambaran karakteristik yang ditampilkan pelanggan di setiap klaster:
Untuk melampaui konsep pemodelan prediktif yang dibahas dalam kursus ini, Anda dapat mengikuti kursus Machine Learning with PySpark di DataCamp.
Sekarang Anda telah menyelesaikan tutorial ini, berikut langkah berikutnya yang direkomendasikan berdasarkan tujuan Anda:
| Tujuan | Sumber Rekomendasi |
|---|---|
| Kuasi dasar-dasar PySpark | Kursus Introduction to PySpark |
| Pelajari pembersihan data | Kursus Cleaning Data with PySpark |
| Bangun pipeline ML | Kursus Machine Learning with PySpark |
| Pahami arsitektur Spark | Apache Spark Tutorial: ML with PySpark |
| Jadi data engineer | Track Big Data with PySpark |
| Persiapkan wawancara PySpark | Top 36 PySpark Interview Questions and Answers |
Jika Anda berhasil mengikuti seluruh tutorial PySpark ini, selamat! Anda kini telah berhasil menginstal PySpark di perangkat lokal, menganalisis dataset e-commerce, dan membangun algoritma machine learning menggunakan kerangka kerja ini.
Satu catatan dari analisis di atas adalah bahwa analisis dilakukan dengan 2.500 baris data e-commerce yang dikumpulkan pada satu hari. Hasil analisis ini dapat diperkokoh jika kita memiliki jumlah data yang lebih besar, karena teknik seperti pemodelan RFM biasanya diterapkan pada data historis selama berbulan-bulan.
Namun, Anda dapat mengambil prinsip yang dipelajari dalam artikel ini dan menerapkannya pada berbagai dataset yang lebih besar di ranah machine learning tanpa pengawasan.
Lihat lembar contekan ini oleh DataCamp untuk mempelajari lebih lanjut tentang sintaks PySpark dan modul-modulnya.
Terakhir, jika Anda ingin melampaui konsep yang dibahas dalam tutorial ini dan mempelajari dasar-dasar pemrograman dengan PySpark, Anda dapat mengikuti track pembelajaran Big Data with PySpark di DataCamp. Track ini berisi rangkaian kursus yang akan mengajarkan Anda melakukan hal berikut dengan PySpark:
PySpark adalah alat yang tepat ketika data Anda melampaui kemampuan satu mesin. Proyek segmentasi pelanggan RFM dalam tutorial ini membahas seluruh alur: memuat data, analisis eksploratif, rekayasa fitur, dan ML. Ini adalah pola yang akan Anda gunakan kembali pada dataset yang jauh lebih besar di produksi.
Satu catatan jujur: contoh ini menggunakan 2.500 baris dari satu hari transaksi. PySpark menangani itu dengan nyaman. Keuntungan nyata dari pengaturan terdistribusi datang saat Anda bekerja dengan riwayat transaksi berbulan-bulan di jutaan peristiwa — saat itulah eksekusi in-memory dan toleransi kesalahan benar-benar berarti.
Untuk terus membangun, track Big Data with PySpark kami mencakup pipeline data engineering, recommendation engine, dan ML produksi dalam urutan terstruktur. Untuk tim, DataCamp for Business menawarkan jalur pembelajaran yang disesuaikan untuk peran data engineering. Ajukan demo untuk mempelajari lebih lanjut.
Pelajari Python dan PySpark dengan DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
