Kurs
PySpark Temelleri
4 sa
157.6K
Bu eğitimdeki kodu çevrimiçi olarak çalıştırın ve düzenleyin
Kodu çalıştırSparkSession, Spark’taki tüm işlevsellik için giriş noktasıdır ve PySpark’ta bir dataframe oluşturmak istiyorsanız gereklidir. Bir SparkSession başlatmak için aşağıdaki kodu çalıştırın:
from pyspark.sql import SparkSession # add this import
spark = (
SparkSession.builder
.appName("DataCamp PySpark Tutorial")
.config("spark.memory.offHeap.enabled", "true")
.config("spark.memory.offHeap.size", "10g")
.getOrCreate()
)
Yukarıdaki kodla bir spark oturumu oluşturduk ve uygulama için bir ad belirledik. Ardından veriler, doğrudan diskte depolanmasını önlemek için off-heap belleğe önbelleğe alındı ve bellek miktarı elle belirtildi.
Artık veri kümesini okuyabiliriz. Örnek e-ticaret veri setini PySpark Read CSV eğitimimizden indirebilir veya kendi CSV dosyanızı kullanabilirsiniz:
df = spark.read.csv("datacamp_ecommerce.csv", header=True, escape='"', inferSchema=True)Parçalama sırasında .csv dosyasındaki virgüllerden kaçınmak için bir kaçış karakteri tanımladığımıza dikkat edin.
DataFrame’in başına show() fonksiyonunu kullanarak göz atalım:
df.show(5,0)DataFrame 8 değişkenden oluşur:
InvoiceNo: Her müşteri faturası için benzersiz tanımlayıcı.
StockCode: Stoktaki her öğe için benzersiz tanımlayıcı.
Description: Müşterinin satın aldığı ürün.
Quantity: Bir faturada müşteri tarafından satın alınan her bir ürünün adedi.
InvoiceDate: Satın alma tarihi.
UnitPrice: Her bir ürünün birim fiyatı.
CustomerID: Her kullanıcıya atanan benzersiz tanımlayıcı.
Country: Satın almanın yapıldığı ülke.
Artık bu veri kümesinde bulunan değişkenleri gördüğümüze göre, bu veri noktalarını daha iyi anlamak için biraz keşifsel veri analizi yapalım:
df.count() # Answer: 2,500df.select('CustomerID').distinct().count() # Answer: 95 Çoğu satın alma hangi ülkeden geliyor?
Çoğu satın alma hangi ülkeden geliyor?En fazla satın almanın yapıldığı ülkeyi bulmak için PySpark’ta groupBy() ifadesini kullanmamız gerekir:
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()Yukarıdaki kod çalıştırıldığında aşağıdaki tablo oluşturulacaktır:

Platformdaki satın almaların neredeyse tamamı Birleşik Krallık’tan yapılmış; Almanya, Avustralya ve Fransa gibi ülkelerden ise yalnızca az sayıda işlem var.
Yukarıdaki tablodaki verilerin satın alma sayısına göre sıralanmadığına dikkat edin. Bu tabloyu sıralamak için orderBy() ifadesini ekleyebiliriz:
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()Artık çıktı azalan düzende sıralanmıştır:

Platformda en son satın almanın ne zaman yapıldığını bulmak için InvoiceDate sütununu zaman damgası biçimine çevirmemiz ve PySpark’ta max() fonksiyonunu kullanmamız gerekir:
df = df.withColumn(
"date",
coalesce(
to_timestamp(col("InvoiceDate"), "yy/MM/dd HH:mm"),
to_timestamp(col("InvoiceDate"), "yyyy-MM-dd HH:mm:ss"),
to_timestamp(col("InvoiceDate")) # best-effort fallback
)
)
df.select(max("date")).show()Yukarıdaki kodu çalıştırdıktan sonra aşağıdaki tabloyu görmelisiniz:
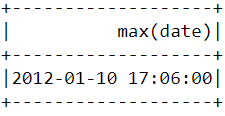
Yukarıda yaptığımıza benzer şekilde, en erken satın alma tarih ve saatini bulmak için min() fonksiyonu kullanılabilir:
df.select(min("date")).show()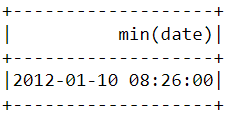
En son ve en erken satın almaların aynı gün, sadece birkaç saat arayla yapıldığına dikkat edin. Bu da indirdiğimiz veri kümesinin yalnızca tek bir günde yapılan satın alma bilgilerini içerdiği anlamına gelir.
Artık veri kümesini analiz ettik ve her veri noktasını daha iyi anladık; veriyi makine öğrenimi algoritmasına beslemek üzere hazırlamamız gerekiyor.
Ön işlemenin nasıl yapılacağını anlamak için veri çerçevesinin başına tekrar göz atalım:
df.show(5,0)
Yukarıdaki veri kümesinden, her kullanıcının satın alma davranışına göre birden fazla müşteri segmenti oluşturmamız gerekir.
Bu veri kümesindeki değişkenler, müşteri segmentasyonu modeline kolayca beslenebilecek bir formatta değildir. Bu özellikler tek başlarına, müşteri satın alma davranışı hakkında çok şey söylemez.
Bu nedenle mevcut değişkenleri kullanarak üç yeni bilgilendirici özellik türeteceğiz: güncellik (recency), sıklık (frequency) ve parasal değer (monetary) — kısaca RFM.
RFM, bir müşterinin değerini aşağıdakilere göre değerlendirmek için pazarlamada yaygın olarak kullanılır:
Şimdi bu değişkenleri oluşturmak için veri çerçevesini ön işleyeceğiz.
Önce recency değerini hesaplayalım — platformda satın alma yapılan en güncel tarih ve saat. Bu iki adımda yapılabilir:
Veri çerçevesindeki her tarihi en erken tarihten çıkaracağız. Bu bize bir müşterinin veri çerçevesinde en son ne zaman görüldüğünü gösterecek. 0 değeri, en düşük recency anlamına gelir; çünkü en erken tarihte satın alma yaptığı görülen kişiye atanacaktır.
df = df.withColumn("from_date", to_timestamp(lit("12/1/10 08:26"), "yy/MM/dd HH:mm"))
df2 = df.withColumn("recency", col("date").cast("long") - col("from_date").cast("long"))
w = Window.partitionBy("CustomerID").orderBy(desc("recency"))
df2 = df2.withColumn("rn", row_number().over(w)).filter(col("rn") == 1).drop("rn")Bir müşteri farklı zamanlarda birden çok satın alma yapabilir. En son ne zaman satın alma yaptıklarını gösterdiği için yalnızca en son görüldükleri zamanı seçmemiz gerekir:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')Yeni veri çerçevesinin başına bakalım. Artık “recency” adlı bir değişken eklendi:
df2.show(5,0)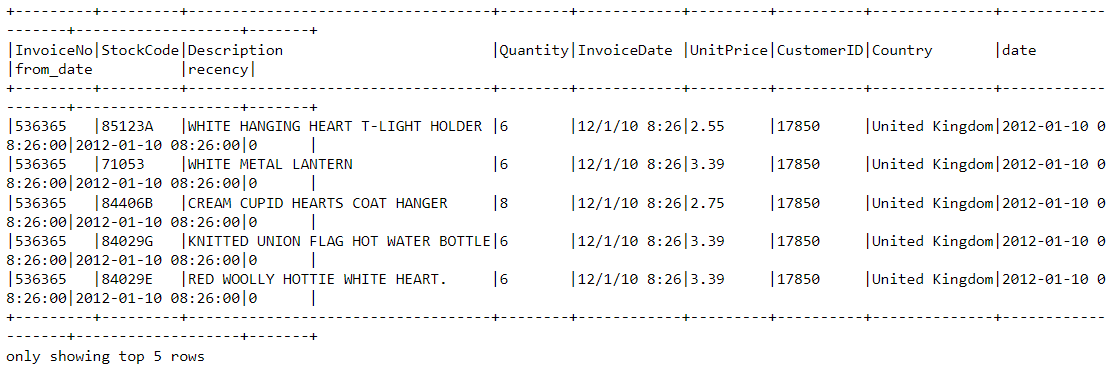
Bir PySpark DataFrame’inde bulunan tüm değişkenleri görmenin daha kolay bir yolu printSchema() fonksiyonunu kullanmaktır. Bu, Pandas’taki info() fonksiyonunun karşılığıdır:
df2.printSchema()Oluşturulan çıktı şöyle görünmelidir:

Şimdi de frequency değerini — bir müşterinin platformda ne sıklıkla bir şeyler satın aldığını — hesaplayalım. Bunu yapmak için her CustomerID’ye göre gruplayıp satın aldıkları öğe sayısını saymamız yeterlidir. Daha gelişmiş gruplama teknikleri için PySpark groupBy eğitimimize bakın:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))Az önce oluşturduğumuz bu yeni DataFrame’in başına bakın:
df_freq.show(5,0)
DataFrame’de her müşteriye bir frequency değeri eklendi. Bu yeni DataFrame yalnızca iki sütundan oluşuyor ve öncekiyle birleştirmemiz gerekiyor. Farklı birleştirme türleri hakkında daha fazla bilgi için PySpark Joins eğitimimize göz atın:
df3 = df2.join(df_freq,on='CustomerID',how='inner')Bu DataFrame’in şemasını yazdıralım:
df3.printSchema()
Son olarak monetary value’yu — DataFrame’de her müşteri tarafından harcanan toplam tutarı — hesaplayalım. Bunu gerçekleştirmek için iki adım gerekir:
Her CustomerID, tek bir satın alma için Quantity ve UnitPrice adlı değişkenlerle birlikte gelir:

Bir müşterinin tek bir satın almada harcadığı toplam tutarı elde etmek için Quantity ile UnitPrice’ı çarpmamız gerekir:
m_val = df3.withColumn(
"TotalAmount",
col("Quantity").cast("double") * col("UnitPrice").cast("double")
)
Her müşterinin toplamda ne kadar harcadığını bulmak için, CustomerID sütununa göre gruplayıp harcanan toplam tutarı toplamamız yeterlidir:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))Bu DataFrame’i diğer tüm değişkenlerle birleştirin:
finaldf = m_val.join(df3,on='CustomerID',how='inner')Artık modeli kurmak için gerekli tüm değişkenleri oluşturduğumuza göre, yalnızca gereken sütunları seçmek ve DataFrame’den yinelenen satırları düşmek için aşağıdaki kod satırlarını çalıştırın:
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()Ön işlemenin doğru yapıldığından emin olmak için nihai DataFrame’in başına bakın:

Müşteri segmentasyonu modelini kurmadan önce, tüm değişkenlerin benzer ölçekte olmasını sağlamak için DataFrame’i standardize edelim:
from pyspark.ml.feature import VectorAssembler, StandardScaler
assemble = VectorAssembler(
inputCols=["recency", "frequency", "monetary_value"],
outputCol="features"
)
assembled_data = assemble.transform(finaldf)
scale = StandardScaler(inputCol="features", outputCol="standardized")
data_scale = scale.fit(assembled_data)
data_scale_output = data_scale.transform(assembled_data)
Standardize edilmiş özellik vektörünün nasıl göründüğünü görmek için aşağıdaki kodu çalıştırın:
data_scale_output.select('standardized').show(2,truncate=False)
Bunlar, kümeleme algoritmasına besleyeceğimiz ölçeklenmiş özelliklerdir.
PySpark ile veri hazırlama hakkında daha fazla bilgi edinmek isterseniz, DataCamp’teki bu özellik mühendisliği kursunu alın.
Tüm veri analizi ve hazırlığı tamamladığımıza göre K-Means kümeleme modelini kuralım.
Algoritma, PySpark’ın makine öğrenimi API’si kullanılarak oluşturulacaktır.
Bir K-Means kümeleme modeli kurarken, önce algoritmanın döndürmesini istediğimiz küme veya grup sayısını belirlememiz gerekir. Örneğin üç kümeye karar verirsek, üç müşteri segmentimiz olur.
K-Means’te kaç küme kullanılacağına karar vermek için kullanılan en popüler teknik “dirsek yöntemi”dir.
Bu, K-Means algoritmasını geniş bir küme aralığı için çalıştırıp her küme için model sonuçlarını görselleştirerek yapılır. Grafikte dirseğe benzeyen bir kırılma noktası olur ve bu noktadaki küme sayısını seçeriz.
Algoritmanın nasıl çalıştığı hakkında daha fazla bilgi edinmek için bu DataCamp K-Means kümeleme eğitimini okuyun.
2’den 10 kümeye kadar bir K-Means kümeleme algoritması kurmak için aşağıdaki kodu çalıştıralım:
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(
predictionCol="prediction",
featuresCol="standardized",
metricName="silhouette",
distanceMeasure="squaredEuclidean"
)
ks = range(2, 10)
cost = np.zeros(len(ks))
for idx, k in enumerate(ks):
km = KMeans(featuresCol="standardized", k=k)
model = km.fit(data_scale_output)
output = model.transform(data_scale_output)
cost[idx] = model.summary.trainingCost # WSSSE
Yukarıdaki kodla, 2’den 10’a kadar küme sayıları için bir K-Means kümeleme modeli başarıyla kurup değerlendirdik. Sonuçlar bir diziye kondu ve şimdi bir çizgi grafikte görselleştirilebilir:
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost[2:])
df_cost.columns = ["cost"]
new_col = range(2,10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()Yukarıdaki kod şu grafiği oluşturacaktır:
Yukarıdaki grafikten, dörtte dirseğe benzeyen bir kırılma noktası olduğunu görüyoruz. Bu nedenle, dört kümeli K-Means algoritmasını kurmaya devam edeceğiz:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)Oluşturduğumuz modeli veri kümesindeki her müşteriye kümeler atamak için kullanalım:
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)Bu DataFrame’de her CustomerID’nin hangi kümeye ait olduğunu söyleyen bir “prediction” sütunu olduğuna dikkat edin:

Bu eğitimin son adımı, az önce oluşturduğumuz müşteri segmentlerini analiz etmektir.
DataFrame’deki her CustomerID’nin recency, frequency ve monetary değerini görselleştirmek için aşağıdaki kodu çalıştırın:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
list1 = ['recency','frequency','monetary_value']
for i in list1:
sns.barplot(x='prediction',y=str(i),data=avg_df)
plt.show()Yukarıdaki kodlar şu grafikleri oluşturacaktır:
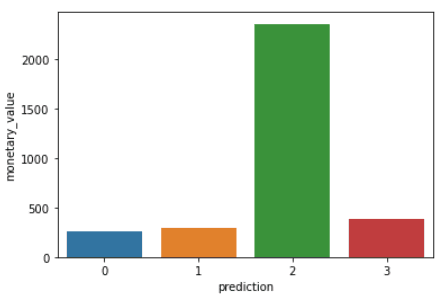
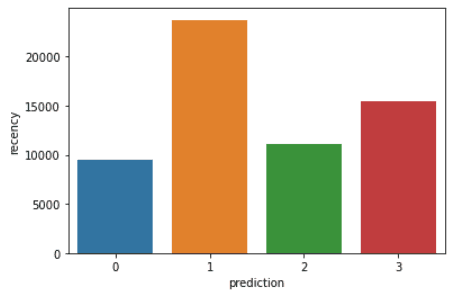
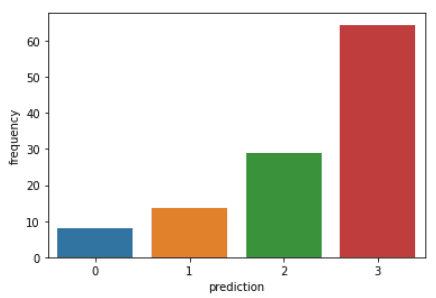
Her kümedeki müşterilerin sergilediği özelliklere genel bakış:
Bu derste ele alınan öngörüsel modelleme kavramlarının ötesine geçmek için, Datacamp’teki PySpark ile Makine Öğrenimi kursunu alabilirsiniz.
Bu eğitimi tamamladığınıza göre, hedeflerinize göre önerilen sonraki adımlar şunlardır:
| Hedef | Önerilen Kaynak |
|---|---|
| PySpark temellerine hâkim olun | PySpark’e Giriş kursu |
| Veri temizlemeyi öğrenin | PySpark ile Veri Temizleme kursu |
| ML boru hatları kurun | PySpark ile Makine Öğrenimi kursu |
| Spark mimarisini anlayın | Apache Spark Eğitimi: PySpark ile ML |
| Veri mühendisi olun | PySpark ile Büyük Veri öğrenme yolu |
Bu PySpark eğitimini baştan sona takip etmeyi başardıysanız tebrikler! Artık PySpark’ı yerel cihazınıza başarıyla kurdunuz, bir e-ticaret veri kümesini analiz ettiniz ve çerçeveyi kullanarak bir makine öğrenimi algoritması oluşturdunuz.
Yukarıdaki analizin bir handikapı, tek bir günde toplanan 2.500 satırlık e-ticaret verisiyle gerçekleştirilmiş olmasıdır. RFM modelleme gibi teknikler genellikle aylarca geçmiş veriye uygulanır; dolayısıyla daha büyük miktarda veriyle çalışsaydık bu analizin çıktıları daha da sağlamlaşırdı.
Yine de bu makalede öğrendiğiniz ilkeleri, denetimsiz makine öğrenimi alanındaki çok daha büyük ve çeşitli veri kümelerine uygulayabilirsiniz.
PySpark’ın sözdizimi ve modülleri hakkında daha fazla bilgi edinmek için DataCamp’in bu özet kartına göz atın.
Son olarak, bu eğitimde ele alınan kavramların ötesine geçmek ve PySpark ile programlamanın temellerini öğrenmek isterseniz, DataCamp’teki PySpark ile Büyük Veri öğrenme yolunu alabilirsiniz. Bu yol, PySpark ile aşağıdakileri yapmayı öğretecek bir dizi kurstan oluşur:
Bu eğitim boyunca gördüğünüz gibi, PySpark ve dağıtık veri işlemede ustalaşmak, modern dünyada giderek yaygınlaşan büyük ölçekli veri kümelerini yönetmek için kritik öneme sahiptir. Terabaytlarca hatta petabaytlarca veriyi yöneten şirketler için, PySpark’ta yetkin bir ekibe sahip olmak eyleme dönük içgörüler elde etme ve rekabet avantajını koruma yeteneğinizi önemli ölçüde artırabilir.
Ancak, özellikle hızlı tempolu ortamlarda çalışan ekipler için en son teknolojiler ve en iyi uygulamalarla güncel kalmak zorlu olabilir. İşte burada DataCamp for Business fark yaratabilir. DataCamp for Business, ekibinizin veri bilimi ve mühendisliğinde en ileri çizgide kalması için ihtiyaç duyduğu araçları ve eğitimi sağlar.
PySpark’e Giriş ve PySpark ile Büyük Veri gibi dersleri içeren özelleştirilmiş öğrenme yollarıyla, ekip üyeleriniz yeni başlayanlardan uzmanlığa ilerleyebilir; PySpark ile büyük veriyi nasıl yöneteceklerini, işleyeceklerini ve analiz edeceklerini öğrenirler. Platformun etkileşimli öğrenme yolları ve gerçek dünya projeleri, ekibinizin yalnızca teoriyi değil, işlerine hemen uygulayabilecekleri pratik deneyimi de kazanmasını sağlar.
DataCamp’i ekibinizin öğrenme stratejisine dahil etmek, kuruluşunuzun büyük verinin karmaşık zorluklarını aşmak için gereken en güncel becerilerle her zaman donatılmış olacağı anlamına gelir. İster makine öğrenimi boru hatları kurmak ister büyük ölçekli veri analizi yapmak olsun, ekibiniz her şeye hazır olacaktır. Daha fazla bilgi için bugün bir demo talep edin.
DataCamp ile Python ve PySpark öğrenin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
