
Corso
Fondamenti di Big Data con PySpark
4 h
65.7K
Esegui e modifica il codice da questo tutorial online
Esegui codiceUna SparkSession è il punto di ingresso a tutta la funzionalità di Spark ed è necessaria se vuoi costruire un DataFrame in PySpark. Esegui le seguenti righe di codice per inizializzare una SparkSession:
from pyspark.sql import SparkSession # add this import
spark = (
SparkSession.builder
.appName("DataCamp PySpark Tutorial")
.config("spark.memory.offHeap.enabled", "true")
.config("spark.memory.offHeap.size", "10g")
.getOrCreate()
)
Con il codice sopra, abbiamo creato una sessione Spark e impostato un nome per l’applicazione. Poi i dati sono stati memorizzati in off-heap memory per evitare di salvarli direttamente su disco, e la quantità di memoria è stata specificata manualmente.
Ora possiamo leggere il dataset. Puoi scaricare il dataset e-commerce di esempio dal nostro tutorial PySpark Read CSV oppure usare il tuo file CSV:
df = spark.read.csv("datacamp_ecommerce.csv", header=True, escape='"', inferSchema=True)Nota che abbiamo definito un carattere di escape per evitare problemi con le virgole nel file .csv durante il parsing.
Diamo un’occhiata alla testa del DataFrame usando la funzione show():
df.show(5,0)Il DataFrame è composto da 8 variabili:
InvoiceNo: L’identificatore univoco di ogni fattura cliente.
StockCode: L’identificatore univoco di ogni articolo a stock.
Description: L’articolo acquistato dal cliente.
Quantity: Il numero di unità di ciascun articolo acquistate da un cliente in una singola fattura.
InvoiceDate: La data di acquisto.
UnitPrice: Prezzo di una singola unità di ciascun articolo.
CustomerID: Identificatore univoco assegnato a ciascun utente.
Country: Il paese da cui è stato effettuato l’acquisto.
Ora che abbiamo visto le variabili presenti nel dataset, facciamo un po’ di analisi esplorativa per capire meglio questi punti dati:
df.count() # Answer: 2,500df.select('CustomerID').distinct().count() # Answer: 95 Da quale paese proviene la maggior parte degli acquisti?
Da quale paese proviene la maggior parte degli acquisti?Per trovare il paese da cui proviene il maggior numero di acquisti, dobbiamo usare la clausola groupBy() in PySpark:
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()La seguente tabella verrà visualizzata dopo l’esecuzione del codice sopra:

Quasi tutti gli acquisti sulla piattaforma sono stati effettuati dal Regno Unito, e solo pochi da paesi come Germania, Australia e Francia.
Nota che i dati nella tabella sopra non sono presentati in ordine di acquisti. Per ordinare questa tabella, possiamo includere la clausola orderBy():
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()L’output ora è ordinato in ordine decrescente:

Per trovare quando è stato effettuato l’acquisto più recente sulla piattaforma, dobbiamo convertire la colonna InvoiceDate in un timestamp e usare la funzione max() in PySpark:
df = df.withColumn(
"date",
coalesce(
to_timestamp(col("InvoiceDate"), "yy/MM/dd HH:mm"),
to_timestamp(col("InvoiceDate"), "yyyy-MM-dd HH:mm:ss"),
to_timestamp(col("InvoiceDate")) # best-effort fallback
)
)
df.select(max("date")).show()Dovresti vedere la seguente tabella dopo aver eseguito il codice sopra:
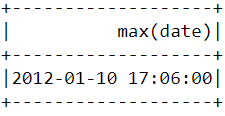
Analogamente a quanto fatto sopra, la funzione min() può essere usata per trovare la data e ora del primo acquisto:
df.select(min("date")).show()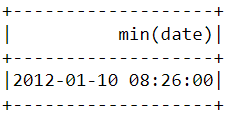
Nota che l’acquisto più recente e quello più antico sono stati effettuati lo stesso giorno, a poche ore di distanza. Questo significa che il dataset scaricato contiene informazioni solo sugli acquisti effettuati in un singolo giorno.
Ora che abbiamo analizzato il dataset e capito meglio ogni punto dato, dobbiamo preparare i dati da fornire all’algoritmo di machine learning.
Diamo di nuovo un’occhiata alla testa del data frame per capire come verrà effettuato il pre-processing:
df.show(5,0)
Dal dataset sopra, dobbiamo creare più segmenti di clienti in base al comportamento d’acquisto di ciascun utente.
Le variabili in questo dataset sono in un formato che non può essere facilmente inglobato nel modello di segmentazione clienti. Queste feature, prese singolarmente, non ci dicono molto sul comportamento d’acquisto.
Per questo, useremo le variabili esistenti per derivare tre nuove feature informative: recency, frequency e monetary value (RFM).
RFM è comunemente usato nel marketing per valutare il valore di un cliente in base a:
Ora pre-processeremo il data frame per creare le variabili sopra.
Per prima cosa, calcoliamo il valore di recency, cioè la data e ora più recenti in cui è stato effettuato un acquisto sulla piattaforma. Possiamo farlo in due passaggi:
Sottrarremo ogni data nel data frame dalla data più antica. Questo ci dirà quanto di recente un cliente è stato visto nel data frame. Un valore pari a 0 indica la recency più bassa, perché verrà assegnato alla persona vista effettuare un acquisto nella data più antica.
df = df.withColumn("from_date", to_timestamp(lit("12/1/10 08:26"), "yy/MM/dd HH:mm"))
df2 = df.withColumn("recency", col("date").cast("long") - col("from_date").cast("long"))
w = Window.partitionBy("CustomerID").orderBy(desc("recency"))
df2 = df2.withColumn("rn", row_number().over(w)).filter(col("rn") == 1).drop("rn")Un cliente può effettuare più acquisti in momenti diversi. Dobbiamo selezionare solo l’ultima volta in cui è stato visto acquistare un prodotto, poiché è indicativa dell’acquisto più recente:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')Diamo un’occhiata alla testa del nuovo data frame. Ora ha una variabile chiamata “recency” aggiunta:
df2.show(5,0)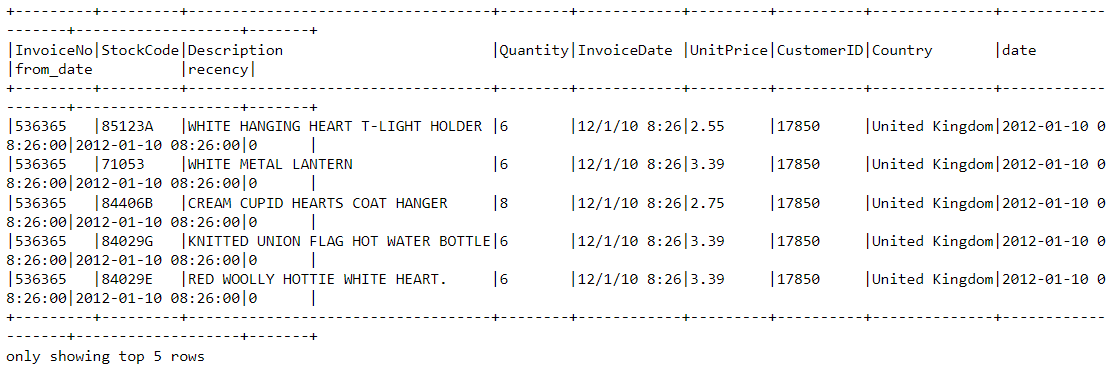
Un modo più semplice per visualizzare tutte le variabili presenti in un DataFrame PySpark è usare la funzione printSchema(). È l’equivalente della funzione info() in Pandas:
df2.printSchema()L’output dovrebbe apparire così:

Ora calcoliamo la frequency, cioè quanto spesso un cliente acquista qualcosa sulla piattaforma. Per farlo, ci basta raggruppare per ogni CustomerID e contare il numero di articoli acquistati. Per tecniche di raggruppamento più avanzate, vedi il nostro tutorial PySpark groupBy:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))Guarda la testa di questo nuovo DataFrame che abbiamo appena creato:
df_freq.show(5,0)
C’è un valore di frequency associato a ciascun cliente nel DataFrame. Questo nuovo DataFrame ha solo due colonne e dobbiamo farne il join con quello precedente. Scopri di più sui diversi tipi di join nel nostro tutorial PySpark Joins:
df3 = df2.join(df_freq,on='CustomerID',how='inner')Stampiamo lo schema di questo DataFrame:
df3.printSchema()
Infine, calcoliamo il monetary value, ovvero l’importo totale speso da ciascun cliente nel DataFrame. Ci sono due passaggi per ottenerlo:
Ogni CustomerID ha associate le variabili Quantity e UnitPrice per un singolo acquisto:

Per ottenere l’importo totale speso da ciascun cliente in un acquisto, dobbiamo moltiplicare Quantity per UnitPrice:
m_val = df3.withColumn(
"TotalAmount",
col("Quantity").cast("double") * col("UnitPrice").cast("double")
)
Per trovare l’importo totale speso da ciascun cliente in generale, basta raggruppare per la colonna CustomerID e sommare l’importo totale speso:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))Unisci questo DataFrame a tutte le altre variabili:
finaldf = m_val.join(df3,on='CustomerID',how='inner')Ora che abbiamo creato tutte le variabili necessarie per costruire il modello, esegui le seguenti righe di codice per selezionare solo le colonne richieste ed eliminare le righe duplicate dal DataFrame:
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()Guarda la testa del DataFrame finale per assicurarti che il pre-processing sia stato eseguito correttamente:

Prima di costruire il modello di segmentazione clienti, standardizziamo il DataFrame per assicurare che tutte le variabili siano su scale simili:
from pyspark.ml.feature import VectorAssembler, StandardScaler
assemble = VectorAssembler(
inputCols=["recency", "frequency", "monetary_value"],
outputCol="features"
)
assembled_data = assemble.transform(finaldf)
scale = StandardScaler(inputCol="features", outputCol="standardized")
data_scale = scale.fit(assembled_data)
data_scale_output = data_scale.transform(assembled_data)
Esegui le seguenti righe di codice per vedere com’è il vettore di feature standardizzato:
data_scale_output.select('standardized').show(2,truncate=False)
Queste sono le feature scalate che verranno fornite all’algoritmo di clustering.
Se vuoi approfondire la preparazione dei dati con PySpark, segui questo corso di feature engineering su DataCamp.
Ora che abbiamo completato analisi e preparazione dei dati, costruiamo il modello di clustering K-Means.
L’algoritmo verrà creato usando la API di machine learning di PySpark.
Quando si costruisce un modello di clustering K-Means, dobbiamo prima determinare il numero di cluster o gruppi che vogliamo ottenere. Se ad esempio scegliamo tre cluster, avremo tre segmenti di clienti.
La tecnica più usata per decidere quanti cluster usare in K-Means è chiamata “metodo del gomito”.
Si esegue K-Means per un intervallo di numeri di cluster e si visualizzano i risultati del modello per ciascun cluster. Il grafico mostrerà un punto di inflessione che assomiglia a un gomito, e scegliamo il numero di cluster in quel punto.
Leggi questo tutorial sul clustering K-Means di DataCamp per saperne di più su come funziona l’algoritmo.
Eseguiamo le seguenti righe di codice per costruire un algoritmo di clustering K-Means da 2 a 10 cluster:
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(
predictionCol="prediction",
featuresCol="standardized",
metricName="silhouette",
distanceMeasure="squaredEuclidean"
)
ks = range(2, 10)
cost = np.zeros(len(ks))
for idx, k in enumerate(ks):
km = KMeans(featuresCol="standardized", k=k)
model = km.fit(data_scale_output)
output = model.transform(data_scale_output)
cost[idx] = model.summary.trainingCost # WSSSE
Con il codice sopra, abbiamo costruito e valutato con successo un modello di clustering K-Means con 2–10 cluster. I risultati sono stati inseriti in un array e ora possono essere visualizzati in un grafico a linee:
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost) # cost ha 8 valori, uno per k in range(2, 10)
df_cost.columns = ["cost"]
new_col = range(2, 10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()Il codice sopra produrrà il seguente grafico:
Dal grafico sopra, si vede un punto di inflessione simile a un gomito in corrispondenza di quattro. Per questo procederemo a costruire l’algoritmo K-Means con quattro cluster:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)Usiamo il modello creato per assegnare i cluster a ciascun cliente nel dataset:
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)Nota che c’è una colonna “prediction” in questo DataFrame che indica a quale cluster appartiene ciascun CustomerID:

L’ultimo passo di questo tutorial è analizzare i segmenti di clienti che abbiamo appena creato.
Esegui le seguenti righe di codice per visualizzare recency, frequency e monetary value di ciascun CustomerID nel DataFrame:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
rfm_columns = ['recency', 'frequency', 'monetary_value']
for metric in rfm_columns:
sns.barplot(x='prediction', y=metric, data=avg_df)
plt.show()Il codice sopra genererà i seguenti grafici:
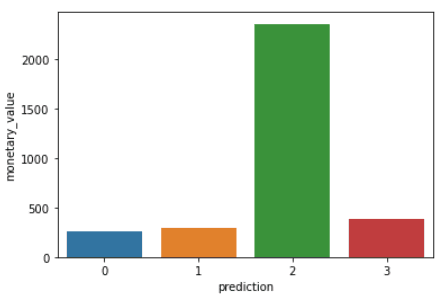
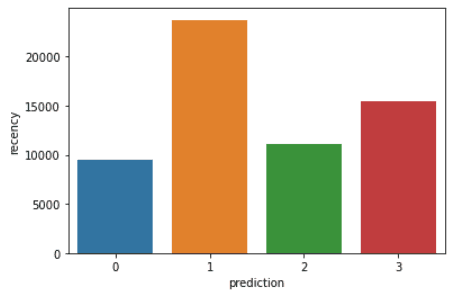
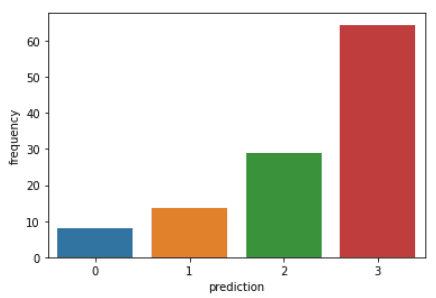
Ecco una panoramica delle caratteristiche mostrate dai clienti in ciascun cluster:
Per andare oltre i concetti di modellazione predittiva trattati in questo corso, puoi seguire il corso Machine Learning with PySpark su DataCamp.
Ora che hai completato questo tutorial, ecco i prossimi passi consigliati in base ai tuoi obiettivi:
| Obiettivo | Risorsa consigliata |
|---|---|
| Padronanza delle basi di PySpark | Introduction to PySpark course |
| Imparare il data cleaning | Cleaning Data with PySpark course |
| Costruire pipeline di ML | Machine Learning with PySpark course |
| Capire l’architettura di Spark | Apache Spark Tutorial: ML with PySpark |
| Diventare data engineer | Big Data with PySpark track |
| Prepararsi ai colloqui su PySpark | Top 36 PySpark Interview Questions and Answers |
Se sei riuscito a seguire tutto questo tutorial su PySpark, congratulazioni! Hai installato PySpark sul tuo dispositivo locale, analizzato un dataset e-commerce e costruito un algoritmo di machine learning usando il framework.
Una riserva sull’analisi sopra è che è stata condotta con 2.500 righe di dati e-commerce raccolti in un solo giorno. L’esito di questa analisi sarebbe più solido se avessimo a disposizione un volume di dati maggiore, poiché tecniche come la modellazione RFM vengono di solito applicate a mesi di dati storici.
Tuttavia, puoi applicare i principi appresi in questo articolo a un’ampia varietà di dataset più grandi nell’ambito del machine learning non supervisionato.
Dai un’occhiata a questo cheat sheet di DataCamp per imparare di più sulla sintassi di PySpark e i suoi moduli.
Infine, se vuoi andare oltre i concetti trattati in questo tutorial e imparare le basi della programmazione con PySpark, puoi seguire il percorso di apprendimento Big Data with PySpark su DataCamp. Questo track contiene una serie di corsi che ti insegneranno a fare quanto segue con PySpark:
PySpark è lo strumento giusto quando i tuoi dati superano ciò che può gestire una singola macchina. Il progetto di segmentazione clienti RFM in questo tutorial percorre l’intero workflow: caricamento dati, analisi esplorativa, feature engineering e ML. Sono pattern che riutilizzerai su dataset molto più grandi in produzione.
Un’onesta precisazione: questo esempio usa 2.500 righe di un solo giorno di transazioni. PySpark le gestisce comodamente. Il vero vantaggio di un setup distribuito arriva quando lavori con mesi di cronologia transazionale e milioni di eventi — è allora che l’esecuzione in-memory e la tolleranza ai guasti fanno davvero la differenza.
Per continuare, il nostro track Big Data with PySpark copre pipeline di data engineering, motori di raccomandazione e ML in produzione in una sequenza strutturata. Per i team, DataCamp for Business offre percorsi di apprendimento su misura per i ruoli di data engineering. Richiedi una demo per saperne di più.
Impara Python e PySpark con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

