Cursus
Basis van PySpark
4 Hr
157.6K
Voer de code uit deze tutorial online uit en pas 'm aan.
Code uitvoerenEen SparkSession is het instappunt voor alle functionaliteit in Spark en is vereist als je een dataframe in PySpark wilt bouwen. Voer de volgende code uit om een SparkSession te initialiseren:
from pyspark.sql import SparkSession # add this import
spark = (
SparkSession.builder
.appName("DataCamp PySpark Tutorial")
.config("spark.memory.offHeap.enabled", "true")
.config("spark.memory.offHeap.size", "10g")
.getOrCreate()
)
Met de bovenstaande code hebben we een spark session opgebouwd en een naam voor de applicatie ingesteld. Daarna is de data gecachet in off-heap-geheugen om te vermijden dat deze direct op schijf wordt opgeslagen, en is de hoeveelheid geheugen handmatig gespecificeerd.
We kunnen nu de dataset inlezen. Je kunt de voorbeeld-e-commercedataset downloaden uit onze PySpark Read CSV-tutorial of je eigen CSV-bestand gebruiken:
df = spark.read.csv("datacamp_ecommerce.csv", header=True, escape='"', inferSchema=True)Let op dat we een escape-teken hebben gedefinieerd om komma's in het .csv-bestand te vermijden tijdens het parsen.
Laten we naar de head van de DataFrame kijken met de functie show():
df.show(5,0)De DataFrame bestaat uit 8 variabelen:
InvoiceNo: De unieke identifier van elke klantenfactuur.
StockCode: De unieke identifier van ieder item op voorraad.
Description: Het item dat door de klant is gekocht.
Quantity: Het aantal stuks van een item dat een klant in één factuur heeft gekocht.
InvoiceDate: De aankoopdatum.
UnitPrice: Prijs van één eenheid van elk item.
CustomerID: Unieke identifier die aan elke gebruiker is toegewezen.
Country: Het land van waaruit de aankoop is gedaan.
Nu we de variabelen in deze dataset hebben gezien, gaan we wat verkennende data-analyse doen om deze datapoints beter te begrijpen:
df.count() # Answer: 2,500df.select('CustomerID').distinct().count() # Answer: 95 Uit welk land komen de meeste aankopen?
Uit welk land komen de meeste aankopen?Om het land te vinden van waaruit de meeste aankopen zijn gedaan, moeten we de groupBy()-clausule in PySpark gebruiken:
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()Na het uitvoeren van de bovenstaande code wordt de volgende tabel weergegeven:

Bijna alle aankopen op het platform zijn gedaan vanuit het Verenigd Koninkrijk, en slechts een handvol vanuit landen als Duitsland, Australië en Frankrijk.
Merk op dat de data in de bovenstaande tabel niet is gepresenteerd in volgorde van aankopen. Om deze tabel te sorteren, kunnen we de orderBy()-clausule toevoegen:
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()De getoonde output is nu in aflopende volgorde gesorteerd:

Om te vinden wanneer de laatste aankoop is gedaan op het platform, moeten we de kolom InvoiceDate converteren naar een timestamp-formaat en de functie max() in PySpark gebruiken:
df = df.withColumn(
"date",
coalesce(
to_timestamp(col("InvoiceDate"), "yy/MM/dd HH:mm"),
to_timestamp(col("InvoiceDate"), "yyyy-MM-dd HH:mm:ss"),
to_timestamp(col("InvoiceDate")) # best-effort fallback
)
)
df.select(max("date")).show()Na het uitvoeren van de bovenstaande code zou je de volgende tabel moeten zien verschijnen:
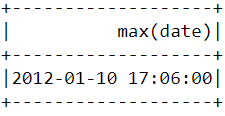
Net als hierboven kun je met de functie min() de vroegste aankoopdatum en -tijd vinden:
df.select(min("date")).show()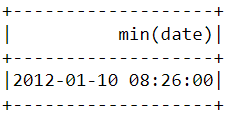
Merk op dat de meest recente en de vroegste aankopen op dezelfde dag zijn gedaan, slechts enkele uren uit elkaar. Dit betekent dat de dataset die we hebben gedownload alleen informatie bevat over aankopen die op één dag zijn gedaan.
Nu we de dataset hebben geanalyseerd en elk datapunt beter begrijpen, moeten we de data voorbereiden om in het machine learning-algoritme te voeren.
Laten we opnieuw naar de head van de dataframe kijken om te begrijpen hoe de preprocessing zal gebeuren:
df.show(5,0)
Uit de bovenstaande dataset moeten we meerdere klantsegmenten creëren op basis van het koopgedrag van elke gebruiker.
De variabelen in deze dataset zijn in een formaat dat niet gemakkelijk door het klantsegmentatiemodel kan worden gebruikt. Deze features vertellen afzonderlijk niet veel over het koopgedrag van klanten.
Daarom gebruiken we de bestaande variabelen om drie nieuwe informatieve features af te leiden: recency, frequency en monetary value (RFM).
RFM wordt vaak gebruikt in marketing om de waarde van een klant te beoordelen op basis van:
We gaan de dataframe nu preprocessen om de bovenstaande variabelen te maken.
Als eerste berekenen we de waarde van recency: de laatste datum en tijd waarop een aankoop op het platform is gedaan. Dit kan in twee stappen:
We trekken elke datum in de dataframe af van de vroegste datum. Dit vertelt ons hoe recent een klant in de dataframe is gezien. Een waarde van 0 geeft de laagste recency aan, omdat deze wordt toegewezen aan de persoon die op de vroegste datum een aankoop deed.
df = df.withColumn("from_date", to_timestamp(lit("12/1/10 08:26"), "yy/MM/dd HH:mm"))
df2 = df.withColumn("recency", col("date").cast("long") - col("from_date").cast("long"))
w = Window.partitionBy("CustomerID").orderBy(desc("recency"))
df2 = df2.withColumn("rn", row_number().over(w)).filter(col("rn") == 1).drop("rn")Eén klant kan meerdere aankopen op verschillende tijdstippen doen. We moeten alleen het laatste moment selecteren waarop hij of zij een product kocht, omdat dit aangeeft wanneer de meest recente aankoop is gedaan:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')Bekijk de head van de nieuwe dataframe. Er is nu een variabele “recency” aan toegevoegd:
df2.show(5,0)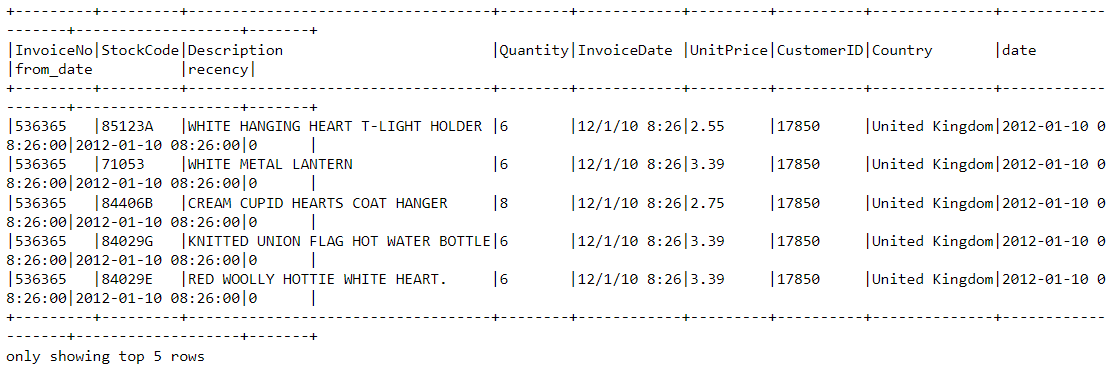
Een eenvoudigere manier om alle variabelen in een PySpark-DataFrame te bekijken, is met de functie printSchema(). Dit is het equivalent van de functie info() in Pandas:
df2.printSchema()De weergave zou er ongeveer zo uit moeten zien:

Laten we nu de waarde van frequency berekenen: hoe vaak een klant iets koopt op het platform. Hiervoor hoeven we alleen per CustomerID te groeperen en het aantal items dat ze hebben gekocht te tellen. Voor meer geavanceerde groeperingstechnieken, zie onze PySpark groupBy-tutorial:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))Bekijk de head van deze nieuwe DataFrame die we net hebben gemaakt:
df_freq.show(5,0)
Er is een frequentiewaarde toegevoegd aan elke klant in de DataFrame. Deze nieuwe DataFrame heeft slechts twee kolommen, en we moeten hem joinen met de vorige. Leer meer over verschillende join-typen in onze PySpark Joins-tutorial:
df3 = df2.join(df_freq,on='CustomerID',how='inner')Laten we de schema van deze DataFrame printen:
df3.printSchema()
Tot slot berekenen we de monetary value: het totale bedrag dat elke klant in de DataFrame heeft uitgegeven. Dit doen we in twee stappen:
Elke CustomerID gaat bij een enkele aankoop vergezeld van de variabelen Quantity en UnitPrice:

Om het totaalbedrag per klant in één aankoop te krijgen, moeten we Quantity vermenigvuldigen met UnitPrice:
m_val = df3.withColumn(
"TotalAmount",
col("Quantity").cast("double") * col("UnitPrice").cast("double")
)
Om het totaalbedrag te vinden dat elke klant in totaal heeft uitgegeven, hoeven we alleen te groeperen op de kolom CustomerID en het totaalbedrag op te tellen:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))Voeg deze DataFrame samen met alle andere variabelen:
finaldf = m_val.join(df3,on='CustomerID',how='inner')Nu we alle benodigde variabelen hebben gemaakt om het model te bouwen, voer je de volgende code uit om alleen de vereiste kolommen te selecteren en dubbele rijen uit de DataFrame te verwijderen:
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()Bekijk de head van de uiteindelijke DataFrame om te controleren of de preprocessing correct is uitgevoerd:

Voordat we het klantsegmentatiemodel bouwen, standaardiseren we de DataFrame om te zorgen dat alle variabelen ongeveer op dezelfde schaal liggen:
from pyspark.ml.feature import VectorAssembler, StandardScaler
assemble = VectorAssembler(
inputCols=["recency", "frequency", "monetary_value"],
outputCol="features"
)
assembled_data = assemble.transform(finaldf)
scale = StandardScaler(inputCol="features", outputCol="standardized")
data_scale = scale.fit(assembled_data)
data_scale_output = data_scale.transform(assembled_data)
Voer de volgende regels uit om te zien hoe de gestandaardiseerde featurevector eruitziet:
data_scale_output.select('standardized').show(2,truncate=False)
Dit zijn de geschaalde features die aan het clustering-algoritme worden doorgegeven.
Wil je meer leren over datapreparatie met PySpark, volg dan deze feature engineering-cursus op DataCamp.
Nu we de data-analyse en -voorbereiding hebben afgerond, bouwen we het K-Means-clusteringmodel.
Het algoritme wordt gemaakt met de machine learning-API van PySpark.
Bij het bouwen van een K-Means-clusteringmodel moeten we eerst bepalen hoeveel clusters of groepen we willen dat het algoritme teruggeeft. Als we bijvoorbeeld kiezen voor drie clusters, hebben we drie klantsegmenten.
De populairste techniek om te beslissen hoeveel clusters je in K-Means gebruikt, heet de “elbow-methode”.
Dit doe je door K-Means te draaien voor een reeks aantallen clusters en de modelresultaten voor elk aantal te visualiseren. De plot heeft een knikpunt dat op een elleboog lijkt, en we kiezen het aantal clusters op dat punt.
Lees deze DataCamp K-Means-clustering-tutorial om meer te leren over hoe het algoritme werkt.
Laten we de volgende code draaien om een K-Means-clusteringalgoritme te bouwen met 2 tot 10 clusters:
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(
predictionCol="prediction",
featuresCol="standardized",
metricName="silhouette",
distanceMeasure="squaredEuclidean"
)
ks = range(2, 10)
cost = np.zeros(len(ks))
for idx, k in enumerate(ks):
km = KMeans(featuresCol="standardized", k=k)
model = km.fit(data_scale_output)
output = model.transform(data_scale_output)
cost[idx] = model.summary.trainingCost # WSSSE
Met de bovenstaande code hebben we met succes een K-Means-clusteringmodel met 2 tot 10 clusters gebouwd en geëvalueerd. De resultaten zijn in een array geplaatst en kunnen nu in een lijngrafiek worden gevisualiseerd:
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost[2:])
df_cost.columns = ["cost"]
new_col = range(2,10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()De bovenstaande code toont de volgende grafiek:
Uit de bovenstaande plot zien we een knikpunt dat op een elleboog lijkt bij vier. Daarom bouwen we het K-Means-algoritme met vier clusters:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)Laten we het model dat we hebben gemaakt gebruiken om clusters toe te wijzen aan elke klant in de dataset:
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)Merk op dat er een kolom “prediction” in deze DataFrame staat die aangeeft tot welk cluster elke CustomerID behoort:

De laatste stap in deze hele tutorial is het analyseren van de klantsegmenten die we zojuist hebben gebouwd.
Voer de volgende code uit om de recency, frequency en monetary value van elke CustomerID in de DataFrame te visualiseren:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
list1 = ['recency','frequency','monetary_value']
for i in list1:
sns.barplot(x='prediction',y=str(i),data=avg_df)
plt.show()De bovenstaande code laat de volgende grafieken zien:
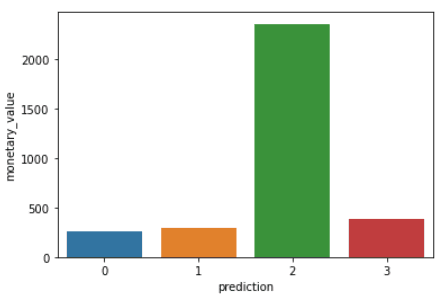
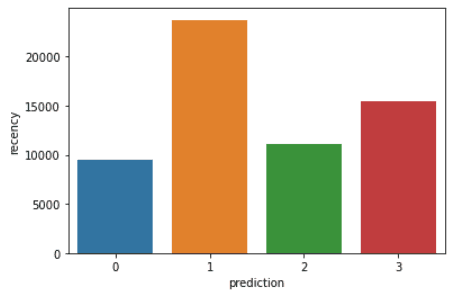
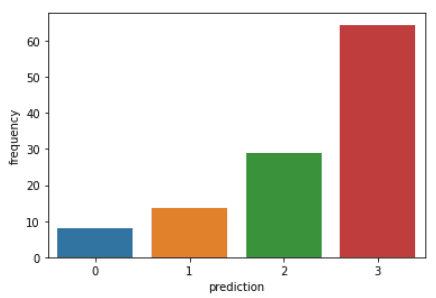
Hier is een overzicht van de kenmerken die klanten in elk cluster laten zien:
Wil je verder gaan dan de predictieve modellering die in deze cursus is behandeld, volg dan de cursus Machine Learning with PySpark op Datacamp.
Nu je deze tutorial hebt voltooid, zijn dit de aanbevolen volgende stappen op basis van je doelen:
| Doel | Aanbevolen bron |
|---|---|
| Beheers de PySpark-basics | Introduction to PySpark-cursus |
| Leer data opschonen | Cleaning Data with PySpark-cursus |
| ML-pijplijnen bouwen | Machine Learning with PySpark-cursus |
| Begrijp Spark-architectuur | Apache Spark Tutorial: ML with PySpark |
| Word data engineer | Big Data with PySpark-track |
Als je deze hele PySpark-tutorial hebt kunnen volgen: gefeliciteerd! Je hebt nu PySpark op je lokale apparaat geïnstalleerd, een e-commercedataset geanalyseerd en een machine learning-algoritme gebouwd met het framework.
Een kanttekening bij de bovenstaande analyse is dat deze is uitgevoerd met 2.500 rijen e-commercedata die op één dag zijn verzameld. De uitkomst van deze analyse zou sterker zijn als we met meer data konden werken, aangezien technieken zoals RFM-modellering doorgaans op maanden aan historische data worden toegepast.
Je kunt de in dit artikel geleerde principes echter toepassen op allerlei grotere datasets binnen de wereld van ongecontroleerde machine learning.
Bekijk deze cheat sheetvan DataCamp om meer te leren over de PySpark-syntaxis en modules.
Wil je ten slotte verder gaan dan de concepten die in deze tutorial zijn behandeld en de basis van programmeren met PySpark leren, volg dan de Big Data with PySpark-leertrack op DataCamp. Deze track bevat een reeks cursussen die je met PySpark het volgende leren doen:
Zoals je in deze tutorial hebt gezien, is het beheersen van PySpark en gedistribueerde gegevensverwerking essentieel voor het werken met grootschalige datasets, die steeds vaker voorkomen. Voor bedrijven die terabytes of zelfs petabytes aan data beheren, kan een team dat bedreven is in PySpark je vermogen om bruikbare inzichten te verkrijgen aanzienlijk vergroten en je concurrentievoordeel behouden.
Bijblijven met de nieuwste technologieën en best practices kan echter een uitdaging zijn, zeker voor teams in een dynamische omgeving. Daar kan DataCamp for Business het verschil maken. DataCamp for Business biedt je team de tools en training die nodig zijn om op het snijvlak van data science en engineering te blijven.
Met op maat gemaakte leertracks, waaronder cursussen zoals Introduction to PySpark en Big Data with PySpark, kunnen teamleden van beginner naar expert groeien en leren hoe ze big data met PySpark kunnen manipuleren, verwerken en analyseren. De interactieve leerroutes en real-world projecten van het platform zorgen ervoor dat je team niet alleen theorie leert, maar ook direct toepasbare praktijkervaring opdoet.
Door DataCamp op te nemen in de leerstrategie van je team, is je organisatie altijd uitgerust met de nieuwste skills om de complexe uitdagingen van big data aan te gaan. Of het nu gaat om het bouwen van machine learning-pijplijnen of het uitvoeren van grootschalige data-analyse, je team is overal op voorbereid. Vraag vandaag een demo aan om meer te weten te komen.
Leer Python en PySpark met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
