
Courses
Nền tảng Big Data với PySpark
4 giờ
65.7K
Chạy và chỉnh sửa mã từ hướng dẫn trực tuyến này.
Chạy mãSparkSession là điểm vào cho mọi chức năng trong Spark, và là bắt buộc nếu bạn muốn xây dựng một dataframe trong PySpark. Chạy các dòng mã sau để khởi tạo SparkSession:
from pyspark.sql import SparkSession # add this import
spark = (
SparkSession.builder
.appName("DataCamp PySpark Tutorial")
.config("spark.memory.offHeap.enabled", "true")
.config("spark.memory.offHeap.size", "10g")
.getOrCreate()
)
Sử dụng đoạn mã trên, chúng ta đã tạo một phiên Spark và đặt tên cho ứng dụng. Sau đó, dữ liệu được lưu đệm trong bộ nhớ off-heap để tránh lưu trực tiếp lên đĩa, và lượng bộ nhớ được chỉ định thủ công.
Giờ chúng ta có thể đọc tập dữ liệu. Bạn có thể tải bộ dữ liệu thương mại điện tử mẫu từ hướng dẫn Đọc CSV với PySpark của chúng tôi hoặc dùng tệp CSV của riêng bạn:
df = spark.read.csv("datacamp_ecommerce.csv", header=True, escape='"', inferSchema=True)Lưu ý chúng ta đã định nghĩa ký tự thoát để tránh dấu phẩy trong tệp .csv khi phân tích cú pháp.
Hãy xem phần đầu của DataFrame bằng hàm show():
df.show(5,0)DataFrame gồm 8 biến:
InvoiceNo: Định danh duy nhất của mỗi hóa đơn khách hàng.
StockCode: Định danh duy nhất của mỗi mặt hàng trong kho.
Description: Mặt hàng khách hàng đã mua.
Quantity: Số lượng mỗi mặt hàng khách hàng mua trong một hóa đơn.
InvoiceDate: Ngày mua hàng.
UnitPrice: Giá của một đơn vị mỗi mặt hàng.
CustomerID: Định danh duy nhất gán cho mỗi người dùng.
Country: Quốc gia nơi phát sinh giao dịch mua.
Giờ chúng ta đã thấy các biến trong tập dữ liệu này, hãy thực hiện một số phân tích dữ liệu khám phá để hiểu sâu hơn về các điểm dữ liệu này:
df.count() # Answer: 2,500df.select('CustomerID').distinct().count() # Answer: 95 Quốc gia nào có nhiều giao dịch mua nhất?
Quốc gia nào có nhiều giao dịch mua nhất?Để tìm quốc gia có nhiều giao dịch mua nhất, chúng ta cần dùng mệnh đề groupBy() trong PySpark:
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()Bảng sau sẽ được hiển thị sau khi chạy đoạn mã trên:

Gần như toàn bộ giao dịch trên nền tảng đến từ Vương quốc Anh, và chỉ một phần nhỏ đến từ các quốc gia như Đức, Úc và Pháp.
Lưu ý dữ liệu trong bảng trên không được trình bày theo thứ tự số lượng giao dịch. Để sắp xếp bảng này, chúng ta có thể thêm mệnh đề orderBy():
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()Đầu ra giờ đã được sắp xếp theo thứ tự giảm dần:

Để tìm thời điểm giao dịch gần nhất, chúng ta cần chuyển cột InvoiceDate thành định dạng timestamp và dùng hàm max() trong PySpark:
df = df.withColumn(
"date",
coalesce(
to_timestamp(col("InvoiceDate"), "yy/MM/dd HH:mm"),
to_timestamp(col("InvoiceDate"), "yyyy-MM-dd HH:mm:ss"),
to_timestamp(col("InvoiceDate")) # best-effort fallback
)
)
df.select(max("date")).show()Bạn sẽ thấy bảng sau xuất hiện sau khi chạy đoạn mã trên:
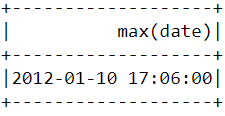
Tương tự như trên, có thể dùng hàm min() để tìm ngày giờ giao dịch sớm nhất:
df.select(min("date")).show()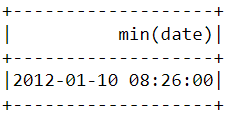
Lưu ý giao dịch gần nhất và sớm nhất diễn ra cùng một ngày, chỉ cách nhau vài giờ. Điều này có nghĩa bộ dữ liệu chúng ta tải chỉ chứa thông tin các giao dịch thực hiện trong một ngày duy nhất.
Sau khi đã phân tích tập dữ liệu và hiểu rõ hơn từng điểm dữ liệu, chúng ta cần chuẩn bị dữ liệu để đưa vào thuật toán học máy.
Hãy xem lại phần đầu của data frame để hiểu cách tiền xử lý sẽ được thực hiện:
df.show(5,0)
Từ tập dữ liệu trên, chúng ta cần tạo nhiều phân khúc khách hàng dựa trên hành vi mua của từng người dùng.
Các biến trong tập dữ liệu này ở định dạng chưa thể dễ dàng đưa vào mô hình phân khúc khách hàng. Từng đặc trưng riêng lẻ không cho chúng ta biết nhiều về hành vi mua sắm.
Vì vậy, chúng ta sẽ dùng các biến hiện có để suy ra ba đặc trưng giàu thông tin mới - độ gần (recency), tần suất (frequency) và giá trị tiền tệ (monetary) (RFM).
RFM thường được dùng trong marketing để đánh giá giá trị của khách hàng dựa trên:
Giờ chúng ta sẽ tiền xử lý data frame để tạo các biến trên.
Đầu tiên, hãy tính giá trị recency - ngày giờ gần nhất có giao dịch trên nền tảng. Có thể thực hiện qua hai bước:
Chúng ta sẽ lấy mỗi ngày trong data frame trừ đi ngày sớm nhất. Điều này cho biết một khách hàng xuất hiện trong data frame gần đây đến mức nào. Giá trị 0 biểu thị độ gần thấp nhất, vì được gán cho người mua hàng vào ngày sớm nhất.
df = df.withColumn("from_date", to_timestamp(lit("12/1/10 08:26"), "yy/MM/dd HH:mm"))
df2 = df.withColumn("recency", col("date").cast("long") - col("from_date").cast("long"))
w = Window.partitionBy("CustomerID").orderBy(desc("recency"))
df2 = df2.withColumn("rn", row_number().over(w)).filter(col("rn") == 1).drop("rn")Một khách hàng có thể mua nhiều lần vào các thời điểm khác nhau. Chúng ta cần chỉ chọn lần gần nhất họ được ghi nhận mua hàng, vì điều này cho biết giao dịch gần nhất diễn ra khi nào:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')Hãy xem phần đầu của data frame mới. Giờ nó đã có biến “recency” được bổ sung:
df2.show(5,0)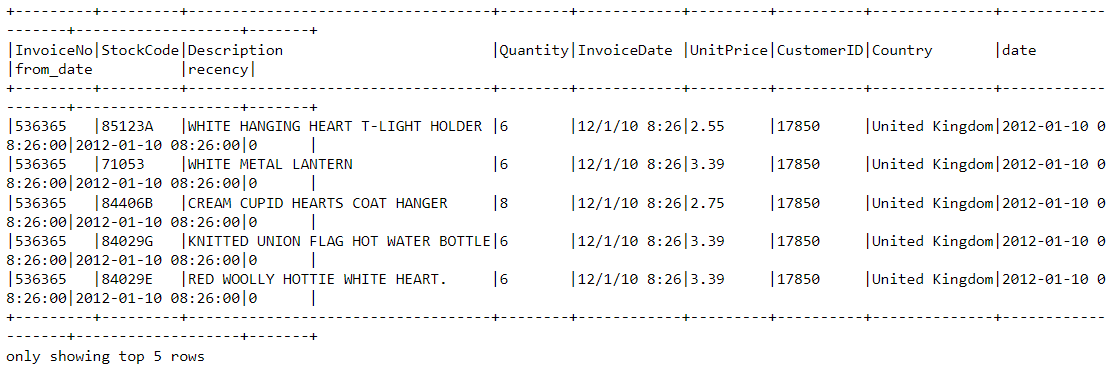
Một cách dễ hơn để xem tất cả biến có trong PySpark DataFrame là dùng hàm printSchema(). Đây là tương đương với hàm info() trong Pandas:
df2.printSchema()Kết quả hiển thị sẽ trông như sau:

Giờ hãy tính giá trị frequency - mức độ thường xuyên một khách hàng mua hàng trên nền tảng. Để làm điều này, chúng ta chỉ cần group theo từng CustomerID và đếm số mặt hàng họ mua. Để biết thêm các kỹ thuật nhóm nâng cao, xem hướng dẫn groupBy trong PySpark:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))Xem phần đầu của DataFrame mới vừa tạo:
df_freq.show(5,0)
Mỗi khách hàng trong DataFrame đã có giá trị tần suất. DataFrame mới này chỉ có hai cột, và chúng ta cần nối nó với DataFrame trước đó. Tìm hiểu thêm về các loại join trong hướng dẫn Join trong PySpark:
df3 = df2.join(df_freq,on='CustomerID',how='inner')Hãy in schema của DataFrame này:
df3.printSchema()
Cuối cùng, hãy tính monetary value - tổng số tiền mỗi khách hàng đã chi trong DataFrame. Có hai bước để thực hiện:
Mỗi CustomerID đi kèm các biến Quantity và UnitPrice cho một lần mua:

Để lấy tổng tiền mỗi khách hàng chi trong một lần mua, chúng ta cần nhân Quantity với UnitPrice:
m_val = df3.withColumn(
"TotalAmount",
col("Quantity").cast("double") * col("UnitPrice").cast("double")
)
Để tìm tổng số tiền mỗi khách hàng chi nói chung, chúng ta chỉ cần group theo cột CustomerID và cộng tổng số tiền đã chi:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))Gộp DataFrame này với tất cả biến khác:
finaldf = m_val.join(df3,on='CustomerID',how='inner')Giờ chúng ta đã tạo đủ biến cần thiết để xây dựng mô hình, hãy chạy các dòng mã sau để chọn đúng các cột cần dùng và loại bỏ hàng trùng lặp khỏi DataFrame:
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()Xem phần đầu của DataFrame cuối cùng để đảm bảo tiền xử lý đã chính xác:

Trước khi xây dựng mô hình phân khúc khách hàng, hãy chuẩn hóa DataFrame để đảm bảo tất cả biến có cùng thang đo gần nhau:
from pyspark.ml.feature import VectorAssembler, StandardScaler
assemble = VectorAssembler(
inputCols=["recency", "frequency", "monetary_value"],
outputCol="features"
)
assembled_data = assemble.transform(finaldf)
scale = StandardScaler(inputCol="features", outputCol="standardized")
data_scale = scale.fit(assembled_data)
data_scale_output = data_scale.transform(assembled_data)
Chạy các dòng mã sau để xem vector đặc trưng đã chuẩn hóa trông như thế nào:
data_scale_output.select('standardized').show(2,truncate=False)
Đây là các đặc trưng đã được scale sẽ được đưa vào thuật toán phân cụm.
Nếu bạn muốn tìm hiểu thêm về chuẩn bị dữ liệu với PySpark, hãy học khóa học kỹ thuật đặc trưng trên DataCamp.
Giờ chúng ta đã hoàn thành phần phân tích và chuẩn bị dữ liệu, hãy xây dựng mô hình phân cụm K-Means.
Thuật toán sẽ được tạo bằng API học máy của PySpark.
Khi xây dựng mô hình phân cụm K-Means, trước tiên chúng ta cần xác định số cụm hoặc nhóm muốn thuật toán trả về. Nếu chọn ba cụm chẳng hạn, thì chúng ta sẽ có ba phân khúc khách hàng.
Kỹ thuật phổ biến nhất để quyết định số cụm trong K-Means gọi là “phương pháp khuỷu tay.”
Cách làm là chạy thuật toán K-Means với một dải số cụm và trực quan hóa kết quả mô hình cho từng số cụm. Biểu đồ sẽ có một điểm gãy trông như khuỷu tay, và chúng ta chọn số cụm tại điểm đó.
Đọc hướng dẫn phân cụm K-Means của DataCamp để hiểu thêm cách thuật toán hoạt động.
Hãy chạy các dòng mã sau để xây dựng thuật toán phân cụm K-Means từ 2 đến 10 cụm:
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(
predictionCol="prediction",
featuresCol="standardized",
metricName="silhouette",
distanceMeasure="squaredEuclidean"
)
ks = range(2, 10)
cost = np.zeros(len(ks))
for idx, k in enumerate(ks):
km = KMeans(featuresCol="standardized", k=k)
model = km.fit(data_scale_output)
output = model.transform(data_scale_output)
cost[idx] = model.summary.trainingCost # WSSSE
Với đoạn mã trên, chúng ta đã xây dựng và đánh giá thành công mô hình phân cụm K-Means với 2 đến 10 cụm. Kết quả đã được đặt trong một mảng và giờ có thể trực quan hóa bằng biểu đồ đường:
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost) # cost has 8 values, one per k in range(2, 10)
df_cost.columns = ["cost"]
new_col = range(2, 10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()Đoạn mã trên sẽ hiển thị biểu đồ sau:
Từ biểu đồ trên, ta thấy có một điểm gãy giống khuỷu tay tại bốn. Vì vậy, chúng ta sẽ tiếp tục xây dựng thuật toán K-Means với bốn cụm:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)Hãy dùng mô hình vừa tạo để gán cụm cho từng khách hàng trong tập dữ liệu:
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)Lưu ý có một cột “prediction” trong DataFrame này cho biết mỗi CustomerID thuộc cụm nào:

Bước cuối cùng trong toàn bộ hướng dẫn này là phân tích các phân khúc khách hàng vừa xây dựng.
Chạy các dòng mã sau để trực quan hóa recency, frequency và monetary value của mỗi CustomerID trong DataFrame:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
rfm_columns = ['recency', 'frequency', 'monetary_value']
for metric in rfm_columns:
sns.barplot(x='prediction', y=metric, data=avg_df)
plt.show()Đoạn mã trên sẽ hiển thị các biểu đồ sau:
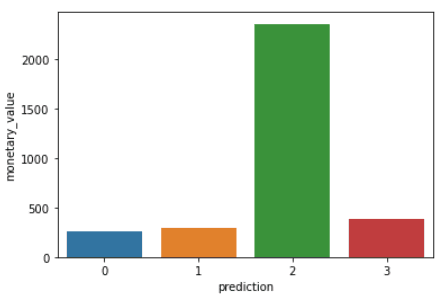
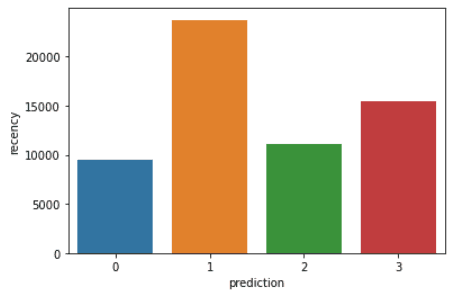
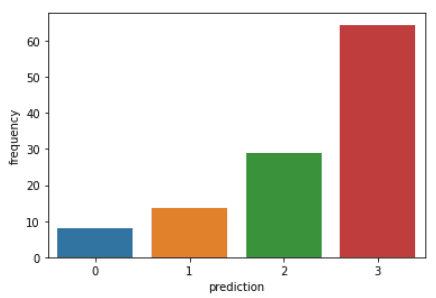
Dưới đây là tổng quan đặc điểm của khách hàng trong từng cụm:
Để đi xa hơn các khái niệm mô hình dự đoán được đề cập trong khóa học này, bạn có thể học khóa Học máy với PySpark trên DataCamp.
Giờ bạn đã hoàn thành hướng dẫn này, dưới đây là các bước tiếp theo được khuyến nghị theo mục tiêu của bạn:
| Mục tiêu | Tài nguyên khuyến nghị |
|---|---|
| Nắm vững căn bản PySpark | Khóa học Giới thiệu về PySpark |
| Học làm sạch dữ liệu | Khóa học Làm sạch dữ liệu với PySpark |
| Xây dựng pipeline ML | Khóa học Học máy với PySpark |
| Hiểu kiến trúc Spark | Hướng dẫn Apache Spark: ML với PySpark |
| Trở thành kỹ sư dữ liệu | Lộ trình Dữ liệu lớn với PySpark |
| Chuẩn bị phỏng vấn PySpark | 36 Câu hỏi và Trả lời phỏng vấn PySpark hàng đầu |
Nếu bạn theo được toàn bộ hướng dẫn PySpark này, xin chúc mừng! Giờ bạn đã cài đặt thành công PySpark trên thiết bị cục bộ, phân tích một bộ dữ liệu thương mại điện tử và xây dựng một thuật toán học máy bằng framework này.
Một lưu ý của phân tích trên là nó được thực hiện với 2.500 hàng dữ liệu thương mại điện tử thu thập trong một ngày. Kết quả phân tích sẽ vững chắc hơn nếu chúng ta có lượng dữ liệu lớn hơn, vì các kỹ thuật như mô hình RFM thường được áp dụng trên dữ liệu lịch sử nhiều tháng.
Tuy nhiên, bạn có thể áp dụng các nguyên tắc đã học trong bài viết này cho nhiều tập dữ liệu lớn trong không gian học máy không giám sát.
Xem cheat sheet này của DataCamp để tìm hiểu thêm về cú pháp và các mô-đun của PySpark.
Cuối cùng, nếu bạn muốn vượt ra ngoài các khái niệm đã đề cập trong hướng dẫn này và học nền tảng lập trình với PySpark, bạn có thể học lộ trình Dữ liệu lớn với PySpark trên DataCamp. Lộ trình này gồm một chuỗi khóa học sẽ dạy bạn thực hiện các nội dung sau với PySpark:
PySpark là công cụ phù hợp khi dữ liệu của bạn vượt quá khả năng xử lý của một máy đơn. Dự án phân khúc khách hàng RFM trong hướng dẫn này đi qua toàn bộ quy trình: nạp dữ liệu, phân tích khám phá, kỹ thuật đặc trưng và ML. Đây là những mẫu hình bạn sẽ lặp lại trên các tập dữ liệu lớn hơn nhiều trong môi trường sản xuất.
Một lưu ý thẳng thắn: ví dụ này dùng 2.500 hàng từ một ngày giao dịch. PySpark xử lý điều đó một cách nhẹ nhàng. Giá trị thực sự của thiết lập phân tán đến khi bạn làm việc với nhiều tháng lịch sử giao dịch với hàng triệu sự kiện — đó là lúc thực thi trong bộ nhớ và khả năng chịu lỗi thực sự tạo khác biệt.
Để tiếp tục nâng cao, lộ trình Dữ liệu lớn với PySpark của chúng tôi bao quát pipeline kỹ thuật dữ liệu, hệ thống gợi ý và ML sản xuất theo chuỗi có cấu trúc. Dành cho đội ngũ, DataCamp for Business cung cấp lộ trình học tập phù hợp với vai trò kỹ sư dữ liệu. Yêu cầu demo để tìm hiểu thêm.
Học Python và PySpark với DataCamp
Courses
Courses
Courses