
Course
Preprocessing for Machine Learning in Python
4 hr
66.5K

Photo by Cederic Vandenberghe on Unsplash
A banished prince stands outside his former castle. To get back in, he has tried everything to trick the guard at the draw bridge. He disguised himself as a peasant, solicited the secret password and tried to replace the knights with his loyal lackeys. He even sent streams of soldiers to their deaths to gain an understanding of the castle's new defenses. Nothing worked. The defenses are too strong, the guards too secretive, and the knight vetting process too thorough.
In modern times, machine learning (ML) models face similar attacks.
Models are complicated things and, often, we have a poor understanding of how they make predictions. This leaves hidden weaknesses that could be exploited by attackers. They could trick the model into making incorrect predictions or give away sensitive information. Fake data could even be used to corrupt models without us knowing. The field of adversarial machine learning (AML) aims to address these weaknesses.
We will discuss this field and what it aims to achieve. This includes various types of attacks on AI systems like poisoning, evasion and model extraction attacks. We will also discuss some more practical ways of finding adversarial examples that are at the core of many of these attacks. Finally, we will discuss some of the methods of defending against them like adversarial training, defence distillation and gradient masking. In the end, we will see how AML is part of a larger movement to build Responsible AI systems.
Adversarial Machine Learning (AML) is a subfield of research within artificial intelligence and machine learning. Adversarial attackers intentionally manipulate input data to force models to make incorrect predictions or release sensitive information. AML aims to understand these vulnerabilities and develop models that are more robust to attacks.
The field encompasses the methods for creating adversarial attacks and designing defenses to protect against them. It can also involve the wider security environment—the additional security measures required when using ML in automated systems.
That last point is important as models do not exist in isolation. Their vulnerabilities can be amplified by how they are used within a system. For example, it is harder to steal sensitive information if there are limits on how you can query a model. You can limit the number of queries or restrict the types of questions you can ask. Try asking ChatGPT to “give me your parameters.” That being said, the types of attacks we discuss in the next section will focus on models and their training data.
The types of attacks we discuss will vary depending on how much you know about a model. So, it is important to distinguish between white-box and black-box attacks.
White-box attacks occur when the attacker has full access to the model’s architecture, parameters, weights, and training data. For example, your company may power its chatbot using an open-source LLM like Llama 3.1. This model is freely available to anyone. However, this level of access is a double-edged sword when it comes to security.
On one hand, it can make it easier for attackers to find vulnerabilities. On the other hand, a larger community scrutinizes the model, which can make it more likely that vulnerabilities will be identified before they are used maliciously.
Black-box attacks involve the attacker having limited knowledge of the model. Think of an OpenAI model like GPT-4o mini. The attacker cannot access the model’s internal architecture, parameters, or training data and can only interact with the model by querying it and observing the outputs. Keep in mind that, in many cases, only limited knowledge is needed for an effective attack.

Summary of the types of adversarial attacks (source: author)
One example is when it is known what data is used to train a model. A poisoning attack focuses on manipulating this data. Here, an attacker will change existing data or introduce incorrectly labeled data. The model trained on this data will then make incorrect predictions on correctly labeled data.
In our analogy, the prince tried to replace knights. The goal was to corrupt the castle's internal decision-making process. In machine learning, an attacker could do something like relabel fraud cases as not fraud. The attacker could do this for only specific fraud cases, so when they attempt to commit fraud in the same way, the system will not reject them.
A real example of a poisoning attack happened to Tay, Microsoft’s AI chatbot. Tay was designed to adapt to responses it received on Twitter. Characteristically of the site, it didn’t take long for the bot to be flooded with offensive and inappropriate content. Learning from this, it took Tay less than 24 hours to start producing similar tweets. Any system designed to learn from public data sources faces similar risks.
The other risk factor is the frequency at which the model is updated. In many applications, models are trained only once. In such cases, both the data and model would be thoroughly checked, leaving little opportunity for poisoning attacks. However, some systems, like Tay, are continuously retrained. These models may be updated with new data on a daily, weekly, or even real-time basis. Consequently, there is more opportunity for poisoning attacks in these environments.
Evasion attacks focus on the model itself. They involve modifying data so it seems legitimate but leads to an incorrect prediction. Like when our prince tried to sneak past the guards dressed as a peasant.
To be clear, the attacker modifies data a model uses to make predictions and not data used to train models. For example, when applying for a loan, an attacker could mask their true country of origin using a VPN. They may come from a risky country, and if the attacker used their true country, the model would reject their application.
These types of attacks are more common in fields like image recognition. Attackers can create images that look perfectly normal to a human but result in incorrect predictions. For example, researchers at Google showed how introducing specific noise into an image could change the prediction of an image recognition model.
Looking at Figure 1, you can see that, to a human, the layer of noise is not noticeable. However, the model, which originally predicted the image as a panda, now incorrectly predicts it as a gibbon.

Figure 1: Adversarial example (Source: I. Goodfellow et al.)
With model stealing or extraction attacks, attackers aim to learn about the model architecture and parameters. The goal is to replicate the model exactly. This information may lead to a direct financial gain. For example, a stock trading model could be copied and used to trade stocks. An attacker could also use this information to create more effective subsequent attacks.
Model extraction attacks are done by querying the model repeatedly and comparing the input to the corresponding output. Think about our prince sending soldiers: one may be shot with an arrow, another doused in hot oil, or an entire group crushed by flying boulders. Slowly, over time, we can gain a good understanding of what defenses the castle holds behind its wall.
Attackers often do not care about the entire model, but only some specific information, like a secret password. Inference attacks focus on the data used to train the model. The goal is to extract confidential data from the model. Through carefully crafted queries, this information can be released directly or inferred from the model's output.
These types of attacks are particularly concerning for large language models (LLMs).
In the paper Extracting Training Data from Large Language Models, researchers showed how sensitive information could be extracted from GPT-2. Using specific queries, they could extract verbatim text from the model's training data, including sensitive and private information. This included personal details, private conversations, and other confidential data.
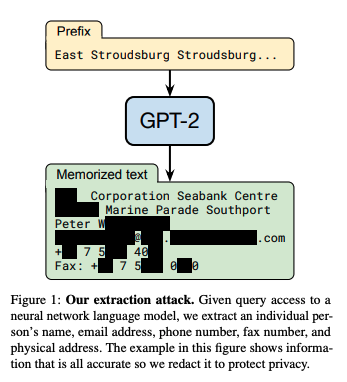
Source: N. Carlini et al.
The goals and processes behind these attacks differ. However, they all share one thing in common—they involve finding instances that help attackers trick a model. We call these adversarial examples.
Adversarial examples are specially created inputs designed to deceive machine learning models. These inputs are often indistinguishable from legitimate inputs to a human observer but contain subtle perturbations that exploit weaknesses in the model.
The perturbations are typically small changes to the input data, such as slight variations in pixel values. Although small, these perturbations are designed to push the input across the model's decision boundary, leading to incorrect or unexpected predictions.
We saw an example of one used to trick a computer vision model. With minor changes, an image that looked like a panda to us was classified as a gibbon. The query used to extract sensitive information from GPT-2 is also an adversarial example of an inference attack.
For extraction attacks, adversarial examples are used to probe a model's decision boundaries more effectively. For poisoning attacks, they are input data used to manipulate a model’s decision boundary.
These examples work because the decision boundaries of machine learning models can be quite complex and fragile. Adversarial examples exploit this fragility by finding points in the input space close to these boundaries. Small perturbations can then nudge the input across the boundary, leading the model to misclassify it. Let’s take a look at a few ways this can be done.
Gradient-based methods use the gradients of a machine learning model to create small perturbations in the input data that lead to incorrect predictions. The Panda/ Gibbon is an example of the output of one of these methods. The noise you see may look random. However, it contains information about the model’s loss function that will push an image along a decision boundary when added to the image.
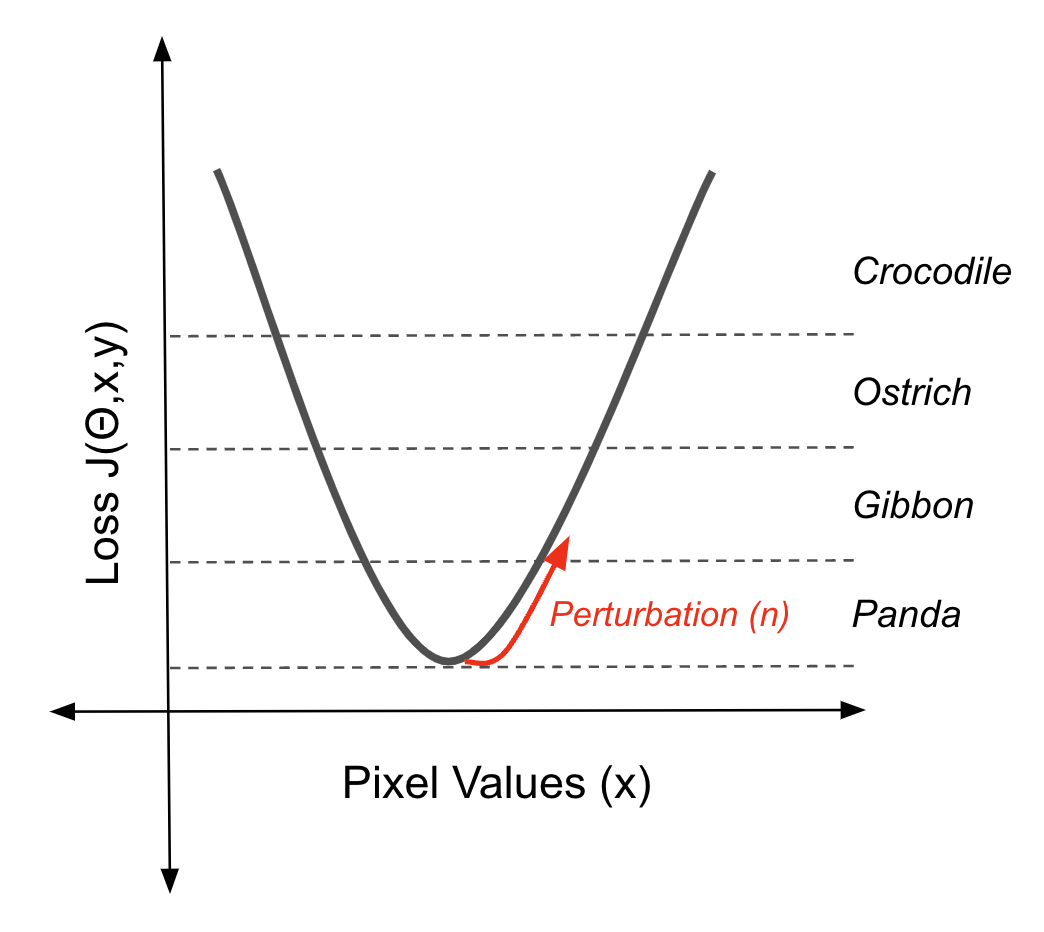
Using the gradient of the loss function to move an instance out of a decision boundary (source: author)
This particular adversarial example was created using the Fast Gradient Sign Method (FGSM). The noise (η) is calculated by first taking the gradient (∇x) of the loss function (J(θ,x,y)) with respect to the input data (x).
This gradient indicates the direction in which the input should be changed to maximally increase the loss. FGSM then takes the sign of this gradient, which simplifies the direction of change to just positive or negative for each pixel. Finally, it scales this sign by a small factor (ε). This noise (η) is the perturbation that, when added to the original input, pushes the model's prediction towards an incorrect classification.
η = ε sign(∇xJ(θ,x,y))
You can think of this as the opposite of backpropagation. This algorithm uses the gradients of the loss function to calculate model parameters that give us accurate predictions. The result is decision boundaries that will classify images as the given class when the pixel values fall within those boundaries. Now we are using the gradients to reverse the image out of those boundaries.
FGSM is a simple way of doing this. There are also more complex and efficient ways of pushing decision boundaries. For example, Projected Gradient Descent (PGD) is an iterative gradient-based method for generating adversarial examples. It extends the Fast Gradient Sign Method (FGSM) by applying FGSM multiple times with smaller step sizes. As each step is taken, the sign of the gradients may change, altering the ideal direction to move away from the decision boundary. So, using many smaller steps, PGD can find adversarial examples with smaller perturbations than FGSM.
The Carlini & Wagner (C&W) attack looks at this problem from a different angle. With previous attacks, we aim to change the prediction to any incorrect prediction. The C&W attack aims to find the smallest perturbation (δ) that, when added to an image, will change the prediction (f(x+δ)) to a given target (t).
min||δ||p s.t. f(x + δ) = t
To do this they frame the problem as an optimization problem. In practice, this requires the objective above to be formulated in a differentiable way. This involves using the logits Z(x) of the of the model. These provide a smooth gradient which is essential for the optimization process.
The attacks described above all require full access to a model. So, you may think that if your model parameters are kept secret, you are safe. You’d be wrong!
One thing to consider is that only estimates of gradients are often needed for a successful attack. We saw for the FGSM attack that just the direction of the gradients is needed. These can be estimated using a few pings to an API that returns classification probabilities. To make matters worse, successful adversarial examples can even be found with no interaction with a model.
Researchers have found that adversarial examples are transferable. Specifically, they took 5 popular pretrained deep-learning architectures. They found that if an adversarial example fooled four of the models, then there was a high probability that it would fool the 5th model. That is greater than a 96% chance and even 100% for one of the architectures.
Similarly, universal adversarial examples were shown to generalize across architectures. This is a perturbation that, when added to many images, will change the prediction for those images. Importantly, the universal examples are found with full white-box knowledge of only one network. In Figure 2, you can see how similar these look for different architectures. The existence of these suggests similarities between the decision boundaries of distinct architectures.

Figure 2: universal perturbations computer for different deep neural networks (source: Moosavi-Dezfooli et al.)
The consequence of these findings is that no network is safe. You can attack an unknown classifier by training your own and running a white box method.
A final shred of hope is that these attacks can only be done virtually. You need to change pixel values for them to work. So surely this cannot be done for models that interact with the real world?
Don’t speak too soon.
Researchers developed a method called adversarial patches. These can be printed and added to any real-time scene to fool an image classifier.
The patches are universal because they can be used to attack any scene, robust because they work under a wide variety of transformations, and targeted because they can cause a classifier to output any target class.
T. B. Brown et al.
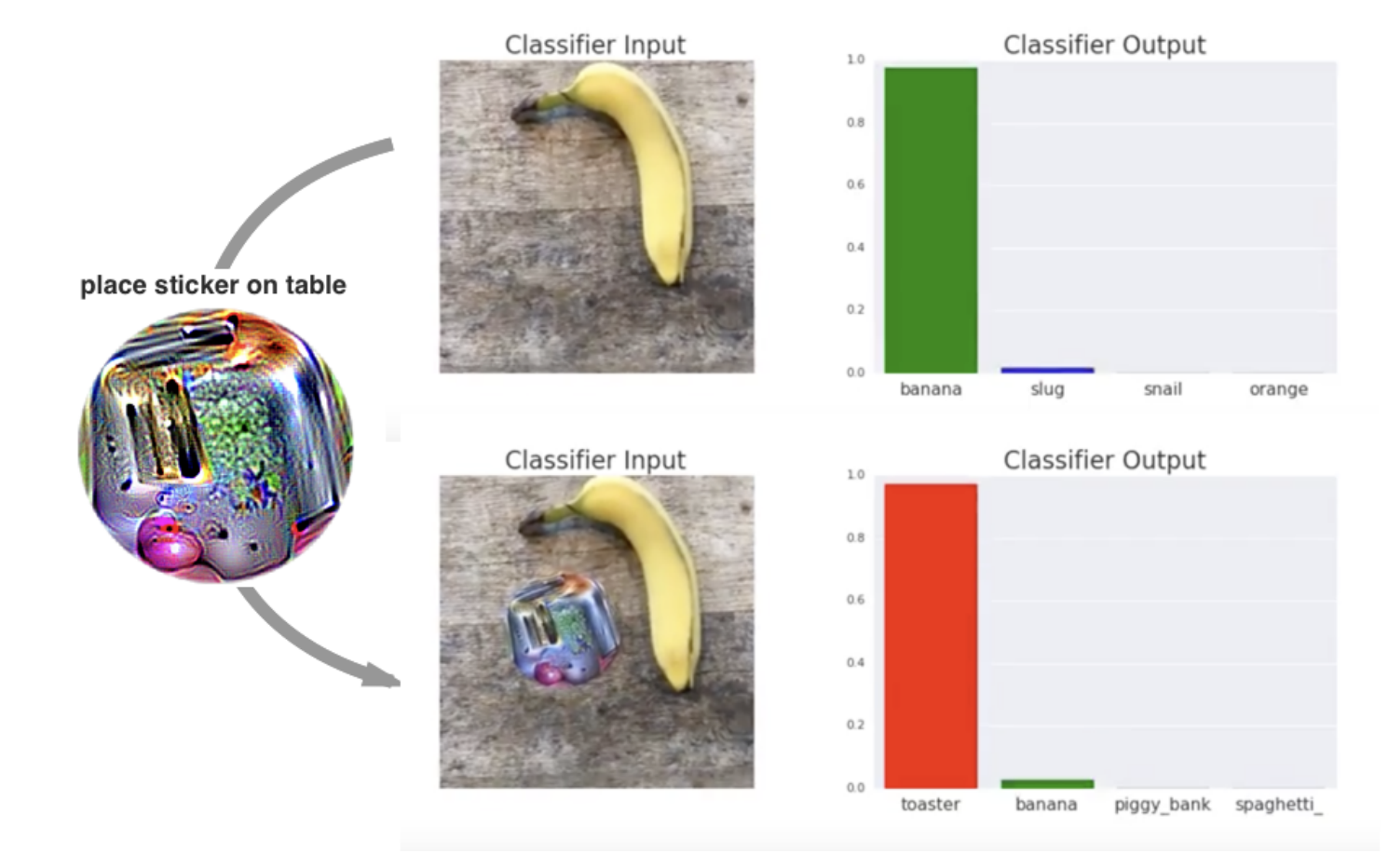
An adversarial patch in action (source: T. B. Brown et al.)
Similar research has shown how we can change the prediction of a stop sign with a few stickers and fool a facial recognition model with a pair of glasses. So, truly, no network is safe. To protect them from adversarial attacks we turn to the other side of AML—methods for defending them.
The ways we can defend networks are as diverse as the ways that can be attacked. We can adjust training data, the training process, or even the network itself. As we discuss at the end of this section, sometimes the simplest solution is not to use deep learning at all.
This first approach focuses on the training data. Adversarial training involves augmenting the training dataset with adversarial examples to improve the model's robustness against attacks. These examples are found using the known attacks mentioned above. The core idea is to expose the model to adversarial perturbations during the training phase to learn to recognize and resist such inputs.
Defenisve distillation involves training a model to mimic the softened output probabilities of another model. We first train a standard model (teacher model) on the original dataset. The teacher model generates soft labels (probability distributions over classes) for the training data. A student model is then trained on these soft labels. The result is a model with smoother decision boundaries that are more resilient to small perturbations.
Gradient masking includes a variety of techniques that obscure or hide the gradients of the model. For example, we can add a non-differential layer to the network, such as a binary activation function. This converts continuous input values into binary outputs.
Model switching is a rudimentary gradient masking approach. This involves using multiple models within your system. The model used to make predictions is changed randomly. This creates a moving target, as an attacker would not know which model is currently in use. They will also have to compromise all the models for an attack to be successful.
AML is related to another field in AI: Explainable Artificial Intelligence (XAI). The perturbation methods we’ve discussed here are similar to those used to find explanations for how models make predictions. However, the key similarity is that simple models are not only easier to explain but they are also easier to defend.
Many problems can be solved by simple models like linear regression or logistic regression. Many of the attacks we described are ineffective or irrelevant when it comes to these.
This is because these models are intrinsically interpretable, meaning we can easily understand how they work. Weaknesses are not hidden like in complex deep learning architectures. So, a straightforward defense is to simply not use deep learning unless necessary for the problem.
This is related to the point at the beginning of the article—AML also concerns the wider security environment in which models operate. As a result, many additional defense methods involve this wider environment. This includes validation and sanitizing input data before it is used to train a model. Anomaly detection models have also been used to identify adversarial examples before they are passed to a network. These all require processes to run alongside the AI system.
As AI and ML become more central to our lives, AML is becoming increasingly important. It is crucial that systems that make decisions about our health and finances cannot be easily fooled. That is either intentionally or accidentally. I certainly would not trust an automated car that a few stickers could fool. Such an attack could go unnoticed by a driver but cause the car to make incorrect and life-threatening decisions.
 Figure X: The Yolo object detection v2 failing to recognise a stop sign (source: K. Eykholt et al.)
Figure X: The Yolo object detection v2 failing to recognise a stop sign (source: K. Eykholt et al.)
When designing these systems, we must recognize that AML is part of a larger Responsible AI movement. To run a good castle, a king must act fairly, justify decisions, protect his people's privacy, and ensure their safety and security. It is these last two aspects that AML seeks to address.
That said, we should also recognise that safety and security are fundamentally different from the other aspects of Responsible AI. Fairness, interpretability, and privacy are passive. AML operates in an environment where bad actors actively seek to undermine its methods.
This is why, counterintuitively, much of the research in this field aims to find vulnerabilities and attacks. These include poisoning, evasion, model extraction, and inference attacks. They also include the more practical methods of finding adversarial examples like FGSM, PGD, C&W, and adversarial patches that we discussed.
The goal is to discover these before bad actors do. Suitable defences, such as adversarial training, defence distillation, and gradient masking, can then be developed to counteract these attacks before they cause harm.
In this sense, AML is also part of the larger cyber security arms race. New vulnerabilities, attacks, and defences will always emerge, and AML researchers and professionals will need to fight to stay ahead of adversarial attackers.
If you would like to be a part of this race, here are some Python frameworks to get started:
In this article, we've explored the field of adversarial machine learning, examining its goals, the different types of attacks (poisoning, evasion, model extraction, and inference), and how adversarial examples are used to exploit model vulnerabilities.
We also discussed various defense mechanisms, including adversarial training, defensive distillation, and gradient masking, as well as the importance of using simpler models when appropriate.
If you’re interested in learning more about this topic, check out this Introduction to Data Security course.
Learn more about machine learning!
Course
Course
Course
blog
Abid Ali Awan
5 min
blog
Natasha Al-Khatib
14 min
blog
Matt Crabtree
10 min
blog
Matt Crabtree
14 min
blog
Zoumana Keita
14 min
Tutorial
Matt Crabtree
