
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
Imagina contar uma longa história a um amigo, só para perceber que ele esqueceu o início quando você chega ao ponto principal. Essa frustração é exatamente o que rola quando uma IA fica sem “memória de curto prazo”, forçando-a a deixar de lado detalhes importantes pra dar espaço pra novos.
No mundo dos Modelos de Linguagem Grandes (LLMs), essa capacidade de atenção é definida pela janela de contexto.
À medida que os modelos ficam mais fortes e os tamanhos dos contextos aumentam, entender como essas janelas funcionam se torna essencial para construir sistemas de IA confiáveis e escaláveis. Neste guia, vamos ver o básico sobre janelas de contexto, as vantagens e desvantagens de expandi-las e as estratégias para usá-las de forma eficaz.
Para ir além da teoria e aprender a gerenciar limites de contexto em aplicações Python reais, confira nosso curso Desenvolvendo Aplicações LLM com LangChain.
A janela de contexto de um modelo de IA decide a quantidade de texto que ele pode guardar na memória de trabalho enquanto gera uma resposta. Isso limita o tempo que uma conversa pode durar sem esquecer detalhes de interações anteriores.
Você pode pensar nisso como a memória de curto prazo de um ser humano. Ele guarda as informações das conversas anteriores temporariamente pra usar na tarefa que tá rolando.

As janelas de contexto afetam vários aspectos, incluindo a qualidade do raciocínio, a profundidade da conversa e a capacidade do modelo de personalizar respostas de forma eficaz. Ele também decide o tamanho máximo de entrada que pode processar de uma vez. Quando um prompt ou contexto de conversa passa desse limite, o modelo corta as partes mais antigas do texto pra dar espaço.
Para entender melhor o que isso quer dizer, vamos ver alguns conceitos básicos por trás dos modelos de IA e das janelas de contexto.
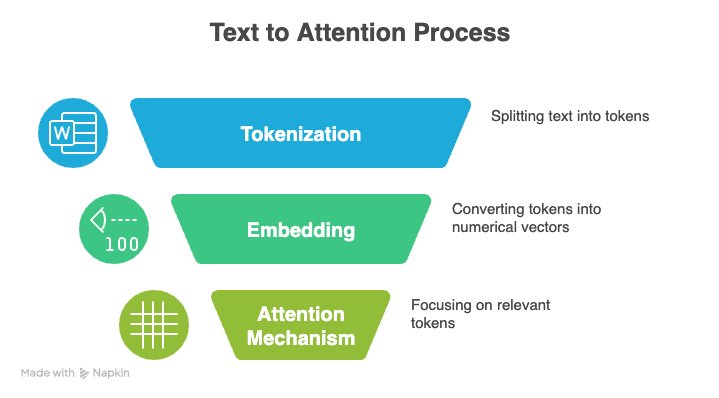
Três conceitos principais estão por trás dos LLMs: tokenização, mecanismo de atenção e codificação posicional.
Tokenização é o processo de transformar texto bruto numa sequência de unidades menores, ou tokens, que um LLM pode processar. Esses tokens podem representar palavras inteiras, caracteres individuais ou até mesmo sílabas parciais. Coletivamente, todo o conjunto de tokens únicos que um modelo reconhece é chamado de vocabulário.
Por exemplo, a frase “Olá, mundo” pode ser tokenizada em [“Hello”, “,”, “ world”].
Durante o treinamento ou inferência, cada token é transformado em um número inteiro único, e o modelo lê esses números em vez do texto original. Ele analisa a sequência numérica, aprende como os tokens se relacionam entre si e gera um novo texto prevendo o próximo token provável.
A tokenização eficiente é super importante na quantidade de informação que cabe na janela de contexto de um modelo. Quando um tokenizador consegue representar o texto com menos tokens, mais conteúdo cabe na mesma janela.
Tokenizadores que representam palavras ou frases comuns como tokens únicos são especialmente eficazes porque reduzem a contagem de tokens, permitindo que o modelo lide com documentos mais longos dentro dos limites do seu contexto.
O chamado mecanismo de atenção é outra base dos LLMs modernos. Isso ajuda um modelo a se concentrar nas partes mais relevantes de sua entrada ao gerar uma saída.
Em vez de tratar todos os tokens da mesma forma, o modelo compara a representação atual com todas as outras representações de tokens e dá uma pontuação para cada comparação. Essa ponderação seletiva permite que o modelo processe sequências longas e entenda o contexto de forma mais eficaz.
A atenção é construída em torno de três componentes: Consultas, chaves e valores.
Dúvidas: O sinal que o token atual manda pra “procurar” informações relevantes no resto da sequência.
Chaves: O identificador de cada token na sequência que mostra o quanto ele combina com o sinal de busca.
Valores: O conteúdo informativo real que é recuperado e usado quando uma correspondência entre uma consulta e uma chave é encontrada.
O modelo calcula pontuações de similaridade entre consultas e chaves, transforma essas pontuações em pesos usando a função de ativação softmax e, em seguida, gera o resultado final como uma soma ponderada dos valores.
A autoatenção compara o token atual com todos os outros tokens da sequência. Isso cria um custo computacional quadrático: dobrar a janela de contexto quadruplica a capacidade de processamento e a memória necessárias.
À medida que as janelas de contexto se expandem, isso rapidamente se torna caro, então os modelos dependem de otimizações como atenção esparsa, aproximação de baixa classificação ou fragmentação para manter a computação gerenciável.
Os transformadores, que alimentam os modelos linguísticos modernos, não entendem naturalmente a ordem dos tokens. Em vez disso, eles usam a codificação posicional para incluir essas informações.
A codificação posicional adiciona um pequeno sinal a cada token que ajuda o modelo a entender a distância e a disposição relativa.
O jeito específico de usar as informações de posição também define até que ponto o modelo consegue programar de forma confiável as relações dentro de uma sequência, o que determina o tamanho e a eficácia da janela de contexto dele. Vamos comparar alguns métodos populares:
Incorporações posicionais absolutas: O modelo aprende um vetor separado para cada posição na sequência, como se desse a cada token um endereço fixo. Isso funciona para sequências mais curtas, mas o modelo não consegue lidar com posições além daquelas para as quais foi treinado, o que dificulta a extensão da janela de contexto.
Codificações sinusoidais: As posições são codificadas usando ondas senoidais e cosseno repetidas, que dão a cada token um padrão único com base na sua localização. Eles generalizam melhor para comprimentos não vistos do que as incorporações absolutas, embora se tornem menos estáveis com sequências extremamente longas.
Codificações posicionais relativas: Em vez de marcar posições exatas, o modelo aprende a distância entre os tokens. Isso ajuda a generalizar para sequências mais longas, mas o limite geral do contexto ainda depende da arquitetura e da memória do modelo.
Embeddings posicionais rotativos (RoPE): O RoPE codifica a posição girando a representação vetorial de cada token com base na sua posição absoluta, calculando a distância em relação a outros tokens. Esse método fica estável conforme as sequências crescem e dá suporte a janelas de contexto bem maiores.
ALiBi (Atenção aos vieses lineares): O ALiBi usa um viés simples baseado na distância dentro do mecanismo de atenção, então os tokens mais próximos naturalmente recebem um peso maior. Ele funciona bem com sequências longas.
Recomendo dar uma olhada neste tutorial sobre como funcionam os transformadores para uma visão geral detalhada.
Se o contexto ultrapassar a janela de contexto, o modelo pode cortar ou ignorar as partes iniciais, podendo perder contexto importante. É por isso que os pesquisadores estão sempre testando novas técnicas pra ultrapassar esses limites e permitir janelas de contexto mais longas.
Até 2022, os modelos GPT da OpenAI mandavam no pedaço. O primeiro modelo GPT, lançado em 2018, suportava uma janela de 512 tokens. As duas versões seguintes, em 2019 e 2020, dobraram esse limite, chegando a 2.048 tokens para o GPT-3. Os modelos seguintes continuaram ampliando esses limites até um milhão de tokens (GPT-4.1).
Recentemente, a OpenAI foi alcançada ou até mesmo ultrapassada pela concorrência. As versões Gemini 2.5 e 3 Pro do Google combinam com esse tamanho de janela de até um milhão de tokens, o que permite processar livros inteiros, grandes bases de código e cargas de trabalho com vários documentos de uma só vez.
A série Claude Sonnet 4.5 da Anthropic está testando o mesmo tamanho de janela de contexto na versão beta, expandindo do tamanho original de 200.000 tokens.
Famílias de modelos de código aberto como Llama e Mistral geralmente ficam na faixa de 100 mil a 200 mil, oferecendo um desempenho respeitável em contextos longos, ao mesmo tempo em que continuam sendo práticas para implantar localmente ou ajustar.
Exceções notáveis incluem o Llama Maverick, que suporta uma janela de 1 milhão de tokens projetada para raciocínio de uso geral em documentos longos. Enquanto isso, o Llama Scout vai além com uma capacidade enorme de 10 milhões de tokens, feito especialmente para processar bases de código inteiras ou arquivos jurídicos de uma só vez.
Mas, o lançamento do GPT-5.2 nesta semana mostrou uma mudança na estratégia. Em vez de tentar pegar todo o contexto, a OpenAI limitou seu mais novo carro-chefe a uma janela de 400.000 tokens, trocando tamanho bruto por “memória perfeita” e capacidades de raciocínio superiores que evitam os problemas de distração comuns em modelos maiores.
As diferenças no tamanho da janela de contexto moldam o desempenho de cada modelo em fluxos de trabalho reais. As janelas de contexto estendidas impulsionam modelos com alta precisão, coerência e raciocínio de longo alcance, mas também exigem mais computação e uma seleção de contexto mais cuidadosa.
Os modelos intermediários continuam eficientes e ainda dão conta de documentos longos e conversas extensas, mas precisam da estrutura certa para entradas muito grandes.
Os casos de uso a seguir mostram como os pontos fortes dos modelos com janelas de contexto grandes aparecem em aplicações do mundo real.
Com espaço suficiente para armazenar relatórios completos, transcrições, bases de código ou trabalhos de pesquisa de uma só vez, um modelo pode rastrear padrões, conectar detalhes distantes e manter uma compreensão coerente do início ao fim. Isso oferece muitos campos de aplicação:
Lei: Janelas grandes permitem que os modelos analisem contratos completos, comparem cláusulas em vários documentos e rastreiem referências escondidas em documentos longos.
Saúde: As equipes podem revisar longas diretrizes clínicas, históricos de pacientes ou conjuntos de dados de vários estudos, preservando o contexto importante que janelas menores não conseguiriam mostrar.
Pesquisa: Um modelo com janela grande pode ler artigos completos e revisões de literatura de uma só vez e mostrar conexões que só aparecem quando o documento inteiro está visível.
Janelas de contexto maiores fazem com que a IA conversacional pareça mais natural, porque o modelo consegue lembrar mais da conversa sem esquecer as mensagens anteriores.
No atendimento ao cliente, isso leva a interações mais tranquilas e personalizadas. O modelo pode usar preferências anteriores e conversas anteriores para dar respostas mais precisas e relevantes.
As janelas de contexto ampliadas ajudam a entender melhor o que está escrito, falado e mostrado, dando ao modelo espaço suficiente para juntar todas as modalidades, em vez de processá-las separadamente.
Quando a transcrição completa, os quadros visuais e o material escrito relacionado cabem em uma única janela, o modelo pode comparar detalhes entre formatos, acompanhar relações e construir uma compreensão unificada do contexto.
Isso elimina as lacunas que aparecem quando as informações precisam ser divididas ou resumidas e permite que o modelo analise todo o conjunto de entradas de uma só vez.
Janelas de contexto grandes trazem recursos poderosos para os modelos, mas também trazem novos desafios de desempenho à medida que o tamanho das entradas aumenta. Mesmo os modelos mais avançados têm dificuldade em manter a atenção total em sequências superlongas, então nem sempre usam as informações de todas as partes do contexto de forma tão confiável quanto você esperaria.
Um problema comum em modelos de contexto longo é o efeito “perdido no meio”. Os modelos lembram bem o começo e o fim de uma sequência longa, mas muitas vezes deixam passar ou ignoram detalhes importantes que ficam no meio. Isso pode fazer com que as respostas fiquem mais fracas, mesmo quando o contexto completo está disponível.
Organizar as entradas de um jeito inteligente ajuda a evitar esse problema em tarefas importantes. Isso significa dividi-lo em seções claras ou repetir os pontos principais para que o modelo não os ignore.
Os custos podem aumentar rapidamente com o aumento do tamanho da janela de contexto. Cada token extra aumenta o tamanho do cálculo de atenção, o que aumenta o tempo de inferência, os requisitos de memória da GPU e a carga geral do sistema.
Para fazer isso, precisamos de maneiras mais eficazes de alimentar as informações do modelo. Técnicas como recuperação seletiva, fragmentação hierárquica ou resumos rápidos ajudam a manter a entrada menor, para que o modelo não fique sobrecarregado.
Janelas grandes também trazem preocupações sobre segurança e privacidade. Quando você dá mais informações ao modelo, aumenta a chance de expor dados confidenciais.
É por isso que as equipes precisam de regras sólidas de tratamento de dados, etapas de redação e controles de acesso para garantir que grandes janelas de contexto não criem novos riscos.
Muitas vezes, informações desnecessárias ou pouco relevantes aumentam a carga cognitiva do modelo, aumentando o risco de alucinações e padrões errados. Entradas muito longas também podem trazer ruído que pode atrapalhar o entendimento do modelo sobre a tarefa.
Na prática, um desempenho de alta qualidade geralmente vem de um contexto cuidadosamente selecionado, garantindo que o modelo veja as informações certas, em vez de só ficar exposto à maior quantidade de informações possível.
Vários métodos podem ser usados para aproveitar ao máximo as janelas de contexto. Entre elas estão a Retrieval Augmented Generation (RAG), engenharia de contexto, chunking e seleção de modelos.
A Retrieval Augmented Generation (RAG) funciona pegando informações extras de um banco de dados externo e colocando no modelo sempre que o contexto precisar.
Em vez de enfiar documentos inteiros na janela de contexto, o RAG guarda tudo separadamente e só pega as partes que importam para a pergunta atual. Isso mantém o contexto pequeno, mas ainda dá ao modelo todas as informações que ele precisa.
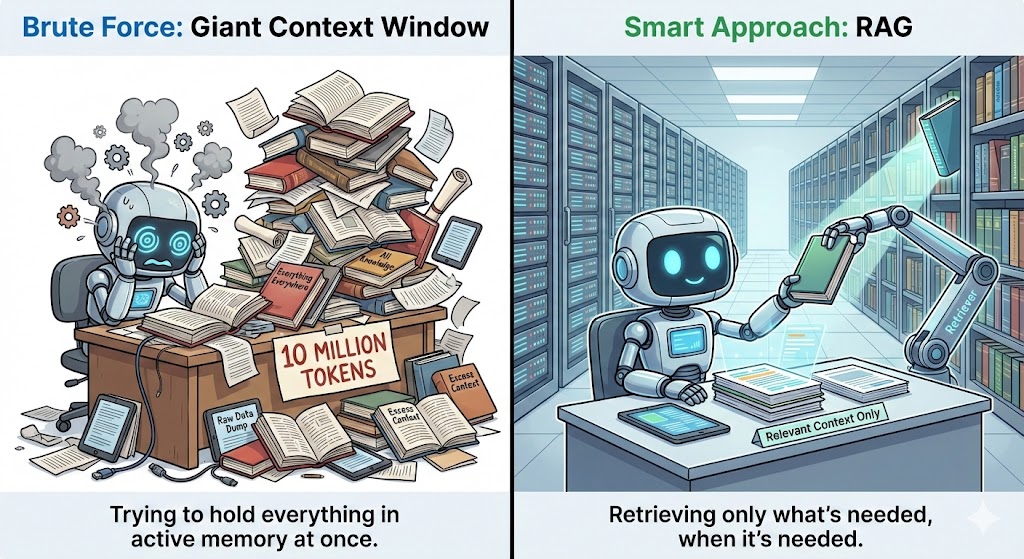
Ele faz isso usando embeddings ou pesquisa vetorial para encontrar os trechos mais relevantes e enviá-los ao modelo de forma clara e estruturada. Isso aumenta a precisão, garantindo que o modelo possa usar informações extras relevantes além dos dados de treinamento.
A engenharia de contexto foca em dar aos modelos informações relevantes, em vez de sobrecarregá-los com detalhes desnecessários. Algumas estratégias que funcionam bem são dividir documentos grandes em partes, resumir as partes menos importantes e usar etapas simples de pré-processamento para destacar os pontos principais.
A pesquisa semântica ajuda aqui, identificando o texto que é importante para a consulta atual. Você também pode melhorar os resultados colocando as informações mais importantes no começo ou no final do contexto, já que os modelos costumam lembrar melhor desses pontos.
A divisão em partes divide documentos longos em seções menores e mais fáceis de entender. A ideia é juntar o conteúdo com base no assunto, na estrutura ou na tarefa que ele ajuda.
Isso mantém cada parte coerente e ajuda o modelo a se concentrar, em vez de se perder em um monte de texto. Se você quiser saber mais, fique à vontade para conferir este artigo sobre estratégias avançadas de chunking.
O chunking semântico agrupa frases que têm um significado parecido, em vez de cortar o texto em limites de caracteres aleatórios. Ele divide o conteúdo em pontos de quebra naturais, como mudanças de tópico, transições de parágrafo ou cabeçalhos de seção.
A divisão em blocos com base em tarefas vai ainda mais longe, moldando cada bloco em torno da pergunta específica que você está tentando responder. Cada seção tem só as informações que são realmente importantes para aquela tarefa.
Tarefas que envolvem análise completa de documentos, raciocínio com vários arquivos ou conversas longas se dão bem com modelos com janelas na faixa de 200 mil a 1 milhão. Para tarefas mais específicas, como resumos, revisão de código ou respostas a perguntas curtas, os modelos na faixa de 100 mil a 200 mil geralmente oferecem o melhor equilíbrio entre velocidade, custo e precisão.
Janelas menores ainda podem funcionar bem quando combinadas com sistemas de recuperação robustos. Um bom sistema RAG ( ) ou MCP (Model Context Protocol) consegue pegar asinformações certasquando você precisa, então o modelo não precisa guardar tudo na memória.
Antes de encerrarmos, vamos dar uma olhada para onde a tecnologia está indo em relação às janelas de contexto.
As arquiteturas dos modelos futuros estão mudando para janelas de contexto dinâmicas, em vez de janelas de tamanho fixo.
Os pesquisadores estão explorando abordagens que combinam os pontos fortes dos transformadores com novos sistemas de memória de longo alcance, resultando em modelos que podem armazenar e recuperar informações sem depender apenas de mecanismos de atenção.
Essas arquiteturas superam os limites atuais, passando de janelas de contexto estáticas para camadas de memória dinâmicas que crescem com a tarefa.
Os sistemas de memória são outra área de inovação. Espera-se que os modelos futuros dependam mais de sistemas de memória sensíveis ao contexto que vão além de uma única sessão e oferecem continuidade ao longo do tempo.
Em vez de tratar cada conversa como um novo começo, esses sistemas guardam as preferências principais, decisões passadas e temas recorrentes numa camada de memória estruturada que pode ser recuperada quando for relevante.
Isso faz com que a personalização passe de reativa para proativa, permitindo que o modelo entenda os usuários de forma mais holística e apoie objetivos de longo prazo com muito mais consistência.
A recuperação externa também está evoluindo. Atualmente, o RAG funciona como um mecanismo de busca, puxando textos relevantes para o prompt. Versões avançadas, como a Correção de Recuperação e Geração Aumentada (CRAG, na sigla em inglês) d , já surgiram, mas isso é só o começo.
No futuro, a recuperação parecerá mais integrada, quase como se o modelo tivesse sua própria memória externa. Eles vão automaticamente juntar, compactar e mostrar as informações de novo com pouca intervenção do usuário.
A memória persistente também vai mudar a forma como interagimos com a IA. Em vez de esquecer tudo quando uma sessão termina, o modelo vai lembrar detalhes importantes ao longo de dias, semanas ou até meses. À medida que aprende seu estilo, hábitos e prioridades, ele pode te dar respostas mais personalizadas e úteis, sem precisar repetir tudo.
Ferramentascomo o Mem0 já estãoe são pioneiras nessa abordagem, agindo como uma camada de memória dedicada entre aplicativos e LLMs. Mas, olhando pro futuro, a gente espera ver mais desses recursos embutidos diretamente nas arquiteturas dos modelos, em vez de depender de camadas externas.
Janelas maiores trazem novos fluxos de trabalho incríveis, mas também podem ser um desafio para a atenção, aumentar os custos de computação e trazer riscos de qualidade quando o contexto fica sobrecarregado. Isso faz com que a gestão estratégica do contexto seja essencial.
Técnicas como aumento de recuperação, fragmentação semântica e engenharia de contexto ajudam os modelos a se manterem focados, eficientes e confiáveis, mesmo com o aumento de suas capacidades.
Olhando para o futuro, os melhores sistemas com LLM juntam ferramentas inteligentes e uma boa compreensão de como o contexto afeta o raciocínio. Ao aplicar esses princípios, as equipes podem aproveitar os benefícios dos modelos de contexto longo enquanto se preparam para a próxima geração de arquiteturas que ampliam ainda mais os limites do contexto.
Leve seus conhecimentos básicos de Python para o próximo nível como programa de habilidades Desenvolvimento de grandes modelos de linguagem. Ele foi feito pra guiar você desde o código básico até a construção e o ajuste fino de seus próprios aplicativos de IA poderosos.
Cursos de LLM
Programa
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Abid Ali Awan
11 min
blog
Bhavishya Pandit
8 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
