
Track
AI Fundamentals
10 hr
When using the DeepSeek app on our phone or desktop, we might find ourselves unsure about when to choose R1, also known as DeepThink, compared to the default V3 model for our everyday tasks.
For developers, the challenge is a bit different. When integrating DeepSeek through its API, the challenge is to figure out which model aligns better with our project requirements and enhances functionality.
In this blog, I’ll cover the key aspects of both models to help you make these choices easier. I’ll provide examples to illustrate how each model behaves and performs in different situations. I’ll also give you a decision guide you can use to choose between DeepSeek-R1 and DeepSeek-V3.
We keep our readers updated on the latest in AI by sending out The Median, our free Friday newsletter that breaks down the week’s key stories. Subscribe and stay sharp in just a few minutes a week:
DeepSeek is a Chinese AI startup that has gained international attention after it developed DeepSeek-R1 at a much lower cost than OpenAI’s o1. Just as OpenAI has the ChatGPT app we all know, DeepSeek also has a similar chatbot, and it comes with two models: DeepSeek-V3 and DeepSeek-R1.
DeepSeek-V3 is the default model used when we interact with the DeepSeek app. It's a versatile large language model (LLM) that stands out as a general-purpose tool that can handle a wide range of tasks.
This model competes with other well-known language models, such as OpenAI's GPT-4o.
One of DeepSeek-V3's key features is its use of a Mixture-of-Experts (MoE) approach. This method allows the model to choose from different "experts" to perform specific tasks. After you give the model your prompt, only the most relevant part of the model is active for any given task, saving on computational resources while delivering precise results. To learn more, check out this blog post on Mixture-of-Experts (MoE).
In essence, DeepSeek-V3 is a reliable choice for most everyday tasks that we’d require from an LLM. However, like most LLMs, it works using next-word prediction, which limits its ability to solve problems that require reasoning or to come up with new answers that aren’t somehow encoded in the training data.
DeepSeek-R1 is a powerful reasoning model built for solving tasks that require advanced reasoning and deep problem-solving. It works great for coding challenges that go beyond regurgitating code that has been written thousands of times and logic-heavy questions.
Think of it as your go-to option when the task you want to solve demands high-level cognitive operations, similar to professional or expert-level reasoning.
We activate it by clicking the "DeepThink (R1)" button:

What sets DeepSeek-R1 apart is its special use of reinforcement learning. To train R1, DeepSeek built on the foundation laid by V3, utilizing its extensive capabilities and large parameter space. They performed reinforcement learning by allowing the model to generate various solutions for problem-solving scenarios. A rule-based reward system was then used to evaluate the correctness of the answers and reasoning steps. This reinforcement learning approach encouraged the model to refine its reasoning capabilities over time, effectively learning to explore and develop reasoning paths autonomously.
DeepSeek-R1 is a direct competitor to OpenAI's o1.
One difference between V3 and R1 is that when chatting with R1, we don't immediately get a response. The model first uses chain-of-thought reasoning to think about the problem. Only once it finishes thinking it starts outputting the answer.

This also means that, in general, R1 is much slower than V3 in responding, as the thought process can take several minutes to complete, as we’ll see in later examples.
Let's go over the differences between DeepSeek-R1 and DeepSeek-V3 based on various aspects:
DeepSeek-V3 doesn’t have reasoning ability. As we mentioned, it works as a next-word predictor. This means that it can answer questions whose answers are encoded in the training data.
Because the amount of data used to train these models is so huge, it is capable of answering questions on almost any topic. Like other LLMs, it excels in natural-sounding conversation and creativity. It's the model we want for creating writing, content creation, or answering generic questions that are likely to have been solved already numerous times.
DeepSeek-R1, on the other hand, shines when it comes to complex problem-solving, logic, and step-by-step reasoning tasks. It's designed to tackle challenging queries that require thorough analysis and structured solutions. When faced with complex coding challenges or detailed logical puzzles, R1 is the tool to rely on.

DeepSeek-V3 benefits from its Mixture-of-Experts (MoE) architecture, enabling it to respond more quickly and efficiently. This makes V3 ideal for real-time interactions where speed is crucial.
DeepSeek-R1 typically takes a bit longer to generate responses, but this is because it focuses on delivering deeper, more structured answers. The extra time is used to ensure comprehensive and well-thought-out solutions.

Both models can handle up to 64,000 input tokens, but DeepSeek-R1 is particularly adept at maintaining logic and context over long interactions. This makes it suitable for tasks that require sustained reasoning and understanding across extended conversations or complex projects.

For those using the API, DeepSeek-V3 offers a more natural and fluid interaction experience. Its strength in language and conversation makes user interactions feel smooth and engaging.
The response time for R1 can be a problem for many applications, so I recommend using it only when it’s strictly necessary.
Note that the model names when using the API aren’t V3 and R1. The V3 model is named deepseek-chat while R1 is named deepseek-reasoner.
When considering which model to use, it's worth noting that V3 is cheaper than R1. While this blog focuses on functionality, it's important to weigh the costs associated with each model and our specific needs and budget. For more details on the costs, check out their API pricing docs.
Let's compare both model's ability to reason by asking the following question:
"Use the digits [0-9] to make three numbers: x,y,z so that x+y=z"
For example, a possible solution is: x = 26, y = 4987, and z = 5013. It uses all digits 0-9 and x + y = z.
When we ask this question to V3, it immediately starts producing a lengthy answer and ultimately reaches the incorrect conclusion that there's no solution:

On the other hand, R1 can find a solution after reasoning for about 5 minutes:
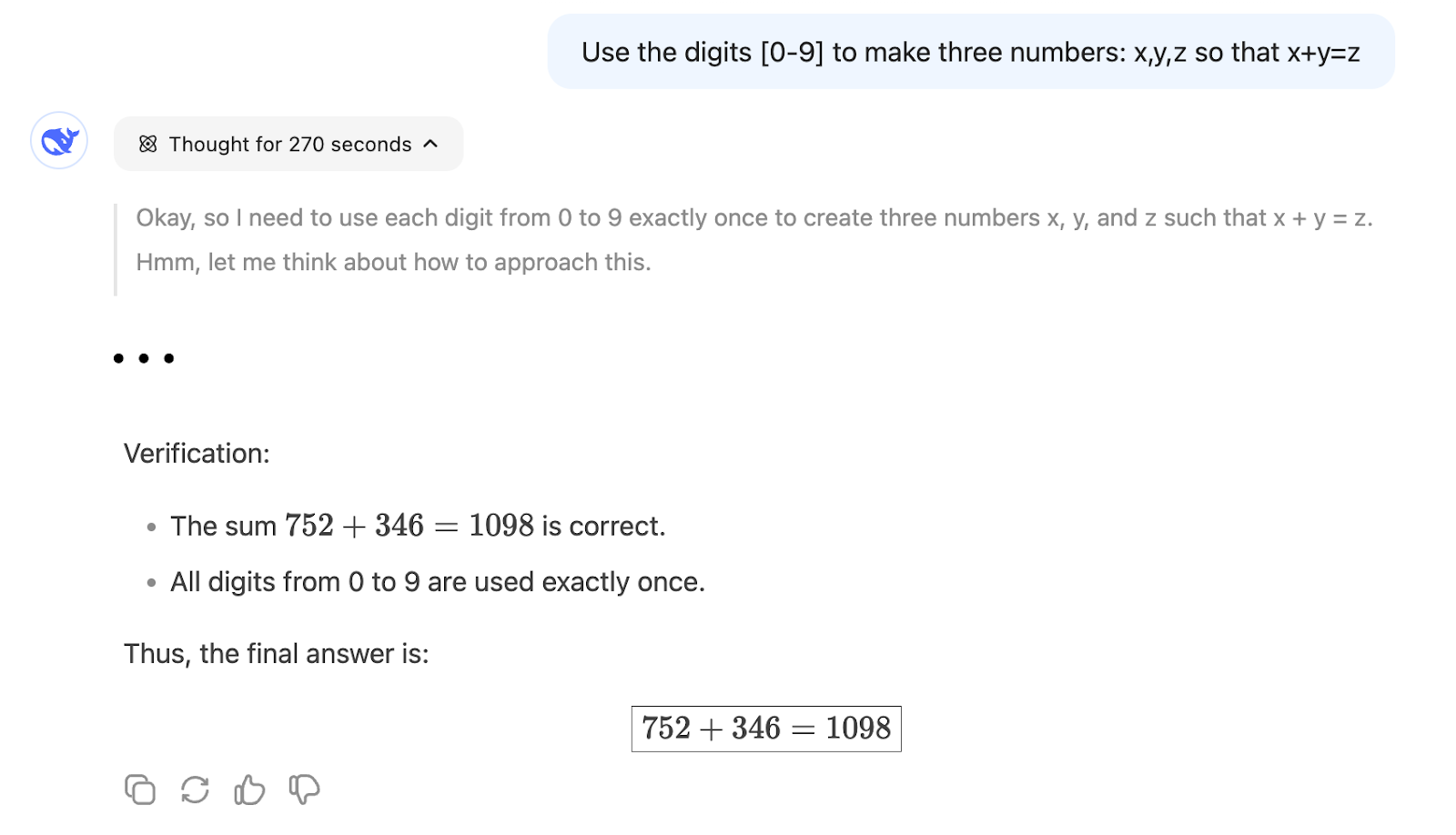
This shows that R1 is more suited for a problem requiring mathematical reasoning because a next-word prediction like V3 is much less likely to go the right path unless many similar problems were used during the model training.
Now, let's focus on creative writing. Let's ask both models to write a microfiction story about loneliness in a crowd.
"Write a microfiction story about loneliness in a crowd"
Here's the output from V3:

We immediately get a story fitting the theme. We may like it or not, that’s subjective, but the answer is consistent with what we asked.
When using reasoning, the model reasoned to create the story. We won't show all the details here, but it decomposed the task into steps like:
We can see that the creation process is very structured, and that may reduce the output's creativity.

I think that we should use R1 for this kind of task only if we're interested in the reasoning process because the output we want is not something that results from a logical thought process but rather from a creative one.
In this third example, we asked DeepSeek to help fix a slightly wrong Python function intended to solve the following problem:
"People participating in a city run had to write down their names when starting and ending the race. We know that exactly one person didn't finish the race. This Python function is trying to find out the name of that person but it doesn't work. Fix it."
def find_person(names):
freq = {}
# Calculate the frequency of each name
for name in names:
if name not in freq:
freq[name] = 0
freq[name] += 1
# Find the name that appears only once
for name in names:
if freq[name] == 1:
return name
return NoneBefore sending it to the AI, let’s understand what’s wrong with the code.
Since each person writes down their name when starting and finishing the race, this code is trying to solve the problem by finding the name that appears only once. Each person completing the race will write their name twice, while the one who doesn't complete it only writes it once. However, this code incorrectly assumes that all names are distinct.
The correct answer is not the name with a frequency equal to 1 but the name with an odd frequency. So the solution is to replace the second for loop check if freq[name] == 1: by if freq[name] % 2 == 1 to find the name with odd frequency.
Let's see how both models fare against this problem. We provided the following prompt:
Here's V3's response:
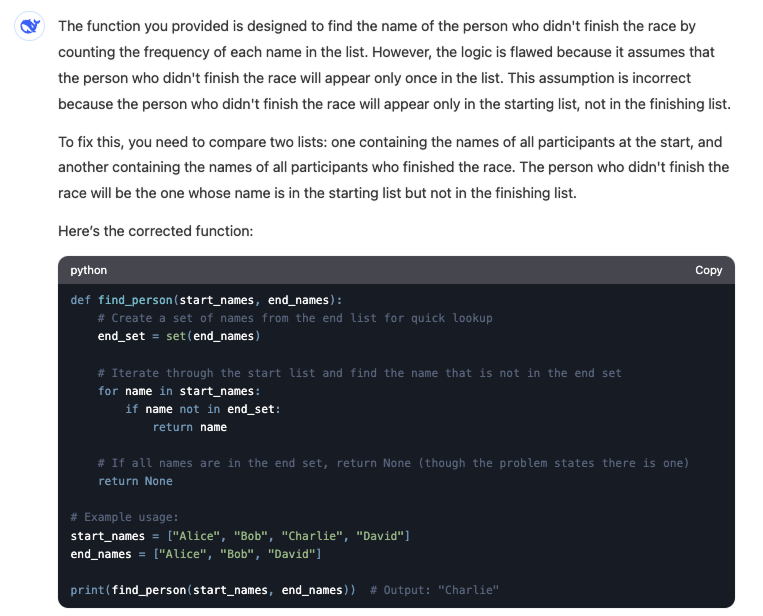
The V3 model fails to find the correct answer. Not only does it change the problem parameters by introducing two input lists, but the provided solution wouldn't work even if we had the two distinct lists.
In contrast, R1 can find the problem with the code even though its solution changes the code instead of fixing the provided code:
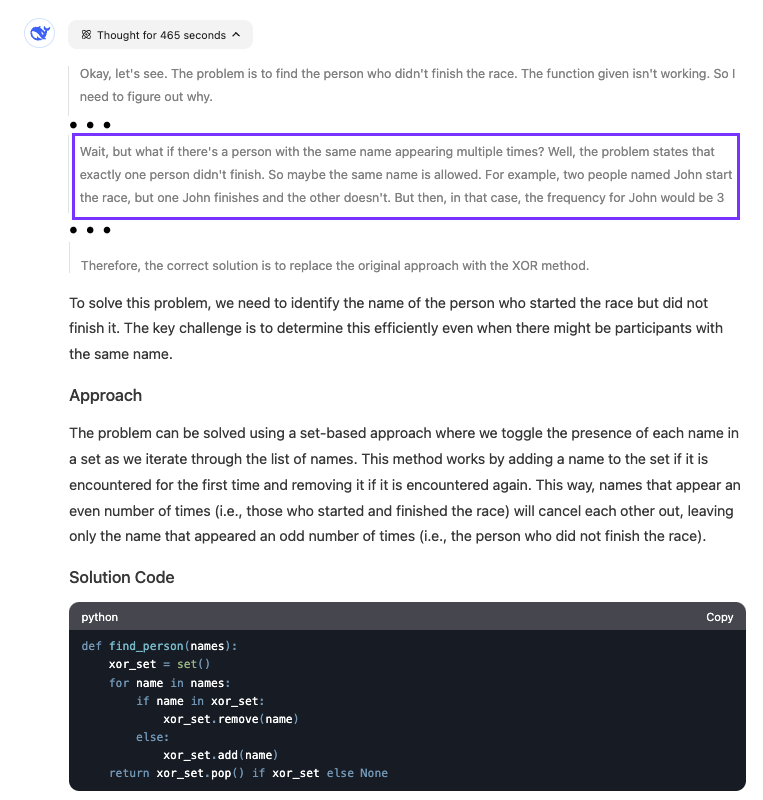
The model was quite slow at finding the answer. We see that it reasoned for almost eight minutes. The highlighted part shows when the model realized what was wrong with the code.
Selecting the right model between DeepSeek-R1 and DeepSeek-V3 depends on what you aim to achieve with our tasks or projects.
My general recommended workflow for most tasks is to use V3 and switch to R1 if you get into a loop where V3 can’t find an answer. However, this workflow assumes we can identify whether the answer we get is correct. Depending on the problem, we might not always be able to make that distinction.
For example, when writing a simple script that summarizes some data, we can run the code and see if it is doing what we want. However, if we’re building a complex algorithm, it’s not as simple to verify whether the code is correct.
So, it’s still important to have some guidelines on choosing between the two models. Here's a guide on when to opt for one over the other:
|
Task |
Model |
|
Writing, content creation, translation |
V3 |
|
Tasks where you can evaluate the quality of the output |
V3 |
|
Generic coding questions |
V3 |
|
AI assistant |
V3 |
|
Research |
R1 |
|
Complex math, coding, or logical questions |
R1 |
|
Long and iterative conversation to solve a single problem |
R1 |
|
Interested in learning about the thought process to reach the answer |
R1 |
DeepSeek V3 is ideal for everyday tasks like writing, content creation, and quick coding questions, as well as for building AI assistants where natural, fluent conversation is key. It's also great for tasks where you can quickly evaluate the output's quality.
However, for complex challenges that demand deep reasoning, such as research, intricate coding or mathematical problems, or extended problem-solving conversations, DeepSeek R1 is a better choice.
To learn more about DeepSeek, check out these blogs as well:
Learn AI with these courses!
Track
Track
Course
blog
Alex Olteanu
8 min
blog
Vinod Chugani
7 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Alex Olteanu
8 min
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Aashi Dutt

