


Track
ChatGPT Fundamentals
3 hr
Get Started Using the OpenAI API and More!
o3 is OpenAI’s latest frontier model, designed to advance reasoning capabilities across a range of complex tasks like coding, math, science, and visual perception.
The o3 reasoning model is the first reasoning model with access to autonomous tool use. This means that o3 can use search, Python, image generation, and interpretation to achieve its tasks.
This has translated into strong performance on advanced benchmarks that test real-world problem-solving, where previous models have struggled. OpenAI highlights o3’s improvement over o1, positioning it as their most capable and versatile model yet.
o3 builds directly on the foundation set by o1, but the improvements are significant across key areas. OpenAI has positioned o3 as a model designed to handle more complex reasoning tasks, with performance gains reflected in its benchmarks.
When tested on software engineering tasks, o3 achieved 69.1% accuracy on the SWE-Bench Verified Software Engineering benchmark, a substantial improvement over o1’s score of 48.9%.
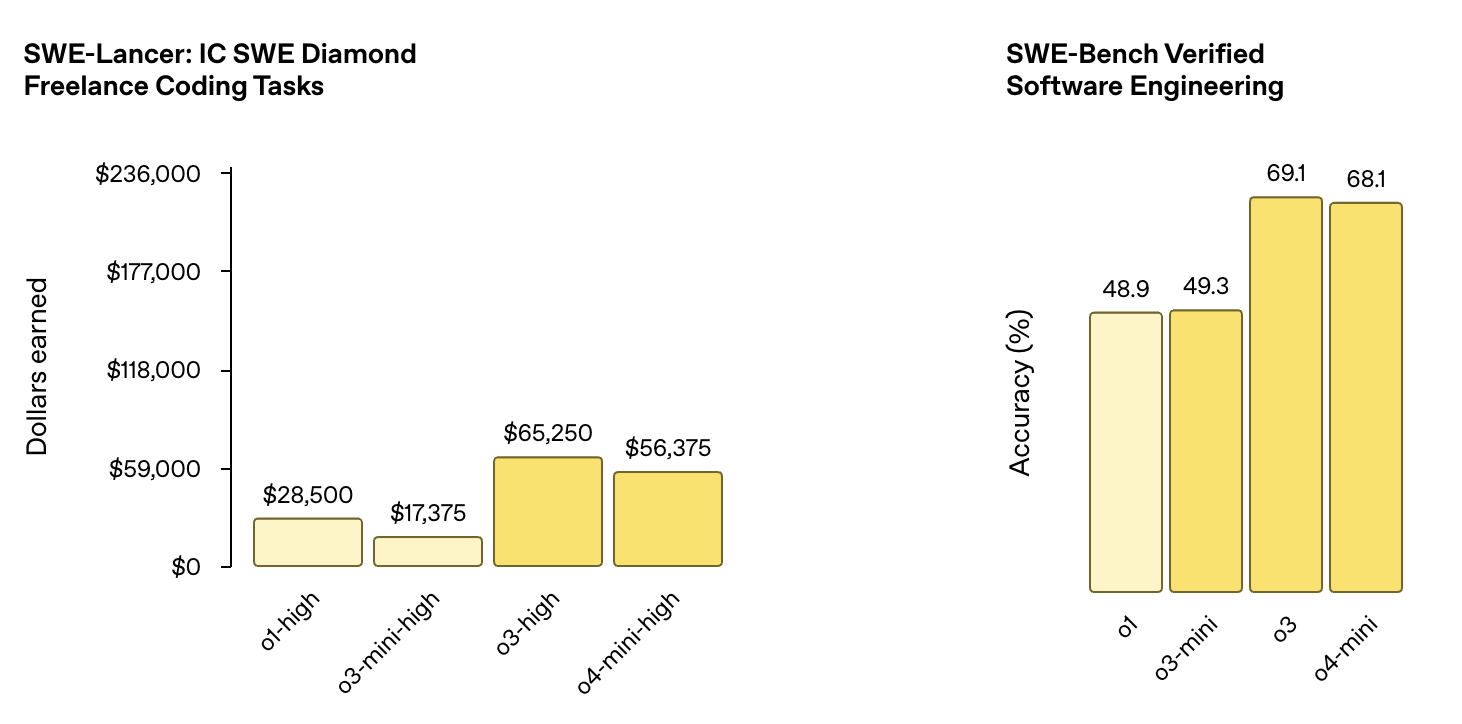
Source: OpenAI
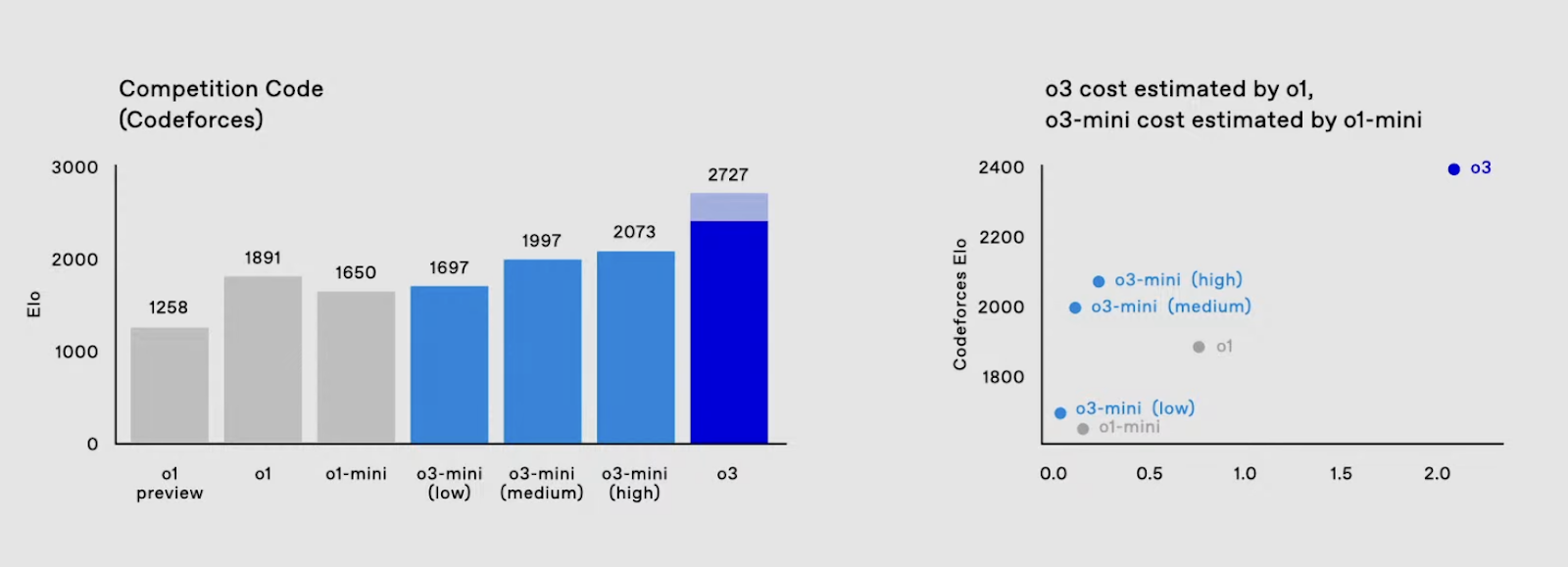
Similarly, in competitive programming, o3 reached an ELO score of 2706, far surpassing o1’s previous high of 1891. Moreover, o3 performs significantly better at code editing benchmarks, with o3 variants outperforming o1 across the board on the Aider Polyglot Code Editing benchmark.
Source: OpenAI
The improvements aren’t limited to coding. o3 also excels in mathematical reasoning, scoring 91.6% accuracy on the AIME 2024, compared to o1’s 74.3%. It also scored an 88.9% on the AIME 2025. These gains suggest a model that can handle more nuanced and difficult problems, moving closer to benchmarks traditionally dominated by human experts.
Source: OpenAI
The leap is similarly apparent in science-related benchmarks. On GPQA Diamond, which measures performance on PhD-level science questions, o3 achieved an accuracy of 83.3%, up from o1’s 78%. These gains demonstrate a broad enhancement in the model’s ability to solve technically demanding problems across disciplines.
Source: OpenAI
One of the more striking aspects of the new o3 model is its ability to reason with images directly in its chain of thought. This means o3 can blend visual and textual reasoning while solving problems, and this is reflected in o3’s performance across multiple visual reasoning benchmarks.
Source: OpenAI
For example, o3 outperforms o1 across a variety of visual reasoning benchmarks, including the MMMU College-level visual problem-solving benchmark (82.9% vs o1’s 77.6%), the MathVista Visual Math Reasoning benchmark (86.8% vs o1’s 71.8%), and the CharXiv-Reasoning Scientific Figure Reasoning benchmark (78.6% vs o1’s 55.1%).
Source: OpenAI
One area where o3’s progress is especially noteworthy is on the EpochAI Frontier Math benchmark.
This is considered one of the most challenging benchmarks in AI because it consists of novel, unpublished problems that are intentionally designed to be far more difficult than standard datasets. Many of these problems are at the level of mathematical research, often requiring professional mathematicians hours or even days to solve a single problem. Current AI systems typically score under 2% on this benchmark, highlighting its difficulty.
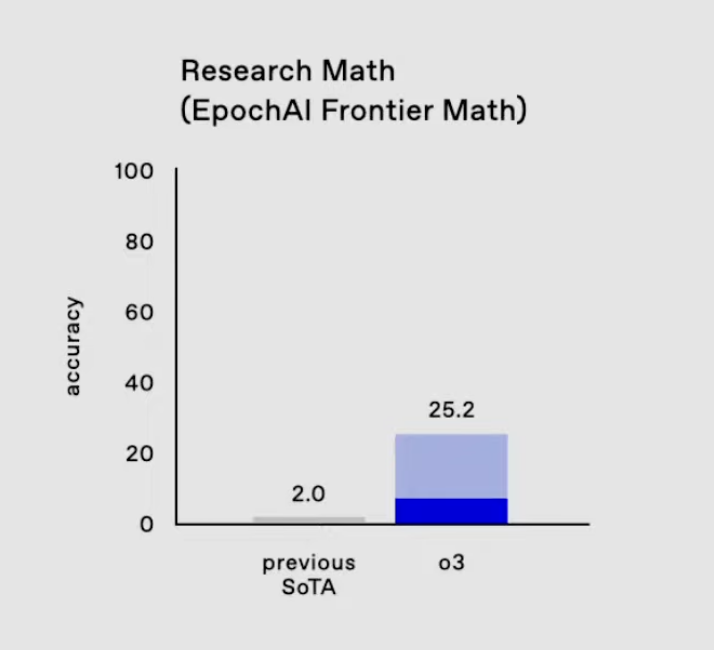
O3 on EpochAI Frontier Math. Source: OpenAI
Epic AI’s Frontier Math is important because it pushes models beyond rote memorization or optimization of familiar patterns. Instead, it tests their ability to generalize, reason abstractly, and tackle problems they haven’t encountered before—traits essential for advancing AI reasoning capabilities. o3’s score of 25.2% on this benchmark is a leap ahead previous state of the art performance. .
One of the most striking achievements of o3 is its performance on the ARC AGI benchmark, a test widely regarded as a gold standard for evaluating general intelligence in AI.
Developed in 2019 by François Chollet, ARC (Abstraction and Reasoning Corpus) focuses on assessing an AI’s ability to learn and generalize new skills from minimal examples. Unlike traditional benchmarks that often test for pre-trained knowledge or pattern recognition, ARC tasks are designed to challenge models to infer rules and transformations on the fly—tasks that humans can solve intuitively but AI has historically struggled with.
What makes ARC AGI particularly difficult is that every task requires distinct reasoning skills. Models cannot rely on memorized solutions or templates; instead, they must adapt to entirely new challenges in each test. For instance, one task might involve identifying patterns in geometric transformations, while another could require reasoning about numerical sequences. This diversity makes ARC AGI a powerful measure of how well an AI can truly think and learn like a human.
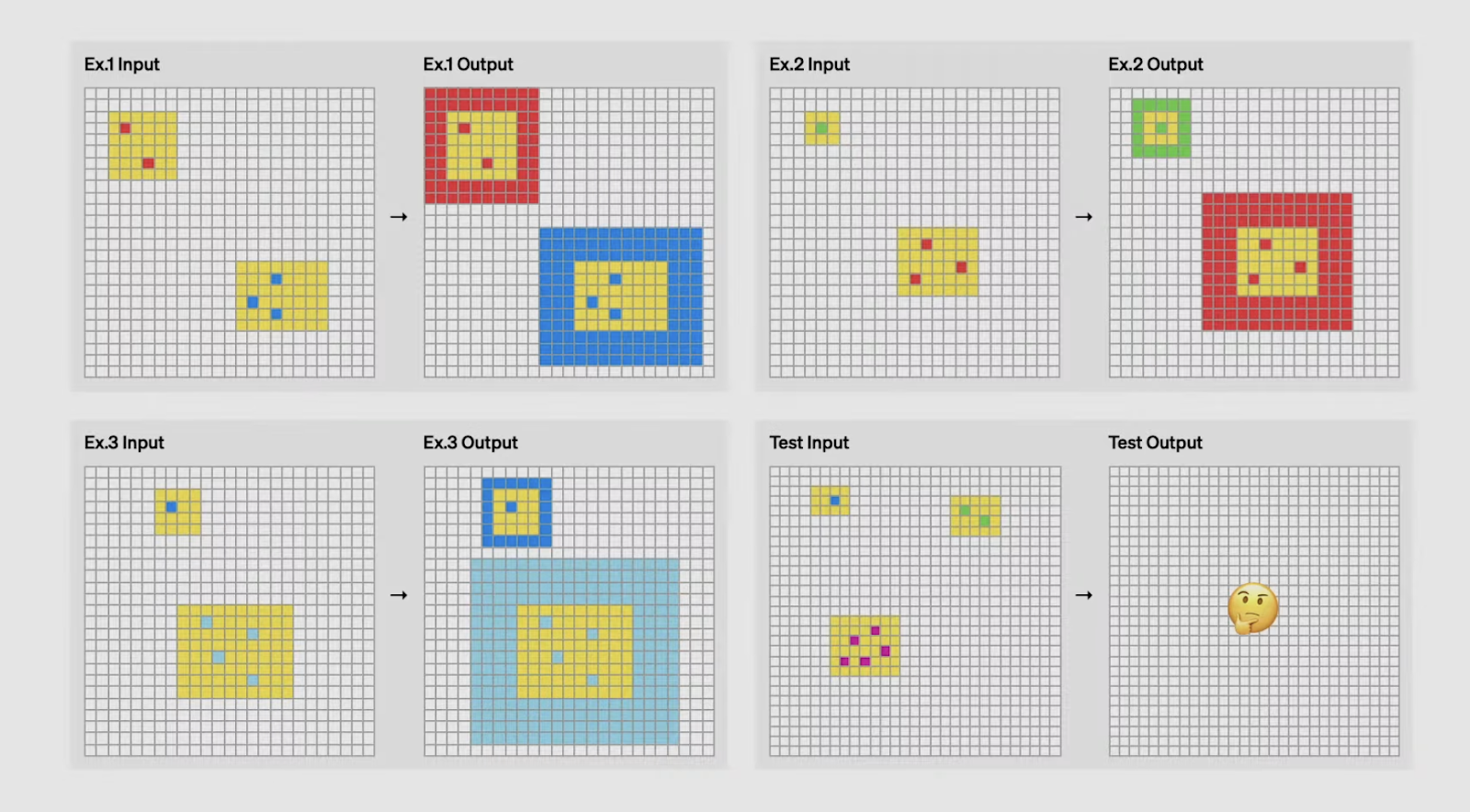
Can you guess the logic by which the input is transformed into output? Source: OpenAI
o3’s performance on ARC AGI marks a significant milestone. On low-compute settings, o3 scored 76% on the semi-private holdout set—a figure far above any previous model.
When tested with high-compute settings, it achieved an even more impressive 88%, surpassing the 85% threshold often cited as human-level performance. This is the first time an AI has outperformed humans on this benchmark, setting a new standard for reasoning-based tasks.
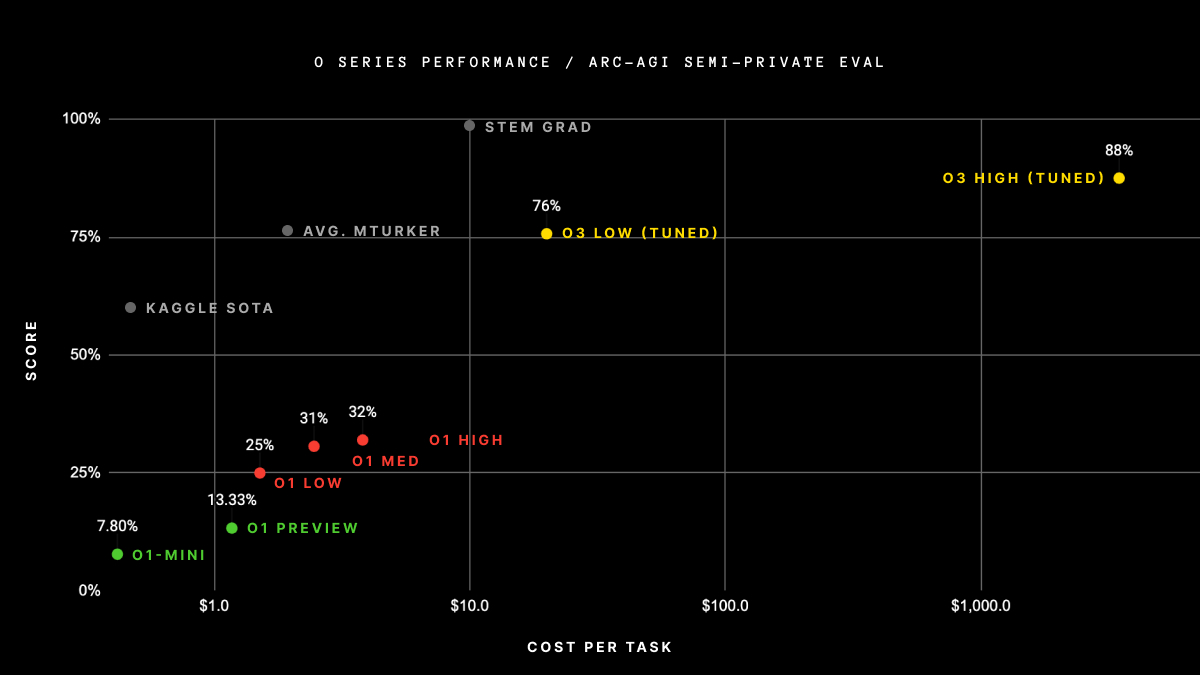
Source: ArcPrize
We believe these results are particularly noteworthy because they demonstrate o3’s ability to handle tasks that demand adaptability and generalization rather than rote knowledge or brute-force computation. It’s a clear indication that o3 is pushing closer to true general intelligence, moving beyond domain-specific capabilities and into areas that were previously thought to be exclusively human territory.
That said, the results above are based on the version of o3 shared in OpenAI’s 12 Days of Christmas event in December, and OpenAI has confirmed that the newly released version of o3 is different than the one shown in the tests above. ARC AGI will be releasing o3’s updated performance results soon.
Performance improvement this big doesn’t just happen. The team at OpenAI discovered some breakthroughs to hit these kinds of numbers:
OpenAI found that increasing the compute budget during reinforcement learning training improves model performance—mirroring the scaling behavior we’ve seen with supervised pretraining in GPT models. But this time, instead of optimizing for next-word prediction, o3 learns by maximizing reinforcement learning rewards, often through tool-augmented environments.
In other words, OpenAI is treating reinforcement learning more like pretraining—scaling it up in both duration and compute—and it seems to work. This unlocks abilities that benefit from long-term planning and sequential reasoning, like competitive programming and multi-step math proofs. When paired with tool use, the performance gains become even more apparent.
o3 also shows significant improvements in visual reasoning. It doesn’t just understand images—it integrates them directly into its reasoning loop. That includes interpreting, manipulating, and re-inspecting images while solving problems. This is one reason why o3 performs well on tasks involving scientific figures, math diagrams, and even scheduling from photos.
One key innovation is how o3 retains the raw image in memory throughout its reasoning process. Instead of processing a static caption and discarding the image, it can zoom, rotate, or revisit different parts of the image on demand using tools. This makes its reasoning more dynamic and allows it to tackle messier visual inputs, like a blurry whiteboard, a hand-drawn diagram, or a photo of a conference schedule.
In one example, OpenAI used o3 to read a low-quality image of a show schedule and plan an itinerary that fit in every event with ten-minute breaks in between—something that would require both parsing the visual layout and applying real-time constraints.

We wanted to test the visual skills with a quick test of our own. We first gave o1 a rudimentary drawing and asked it, “Which fractal are we starting to draw?”
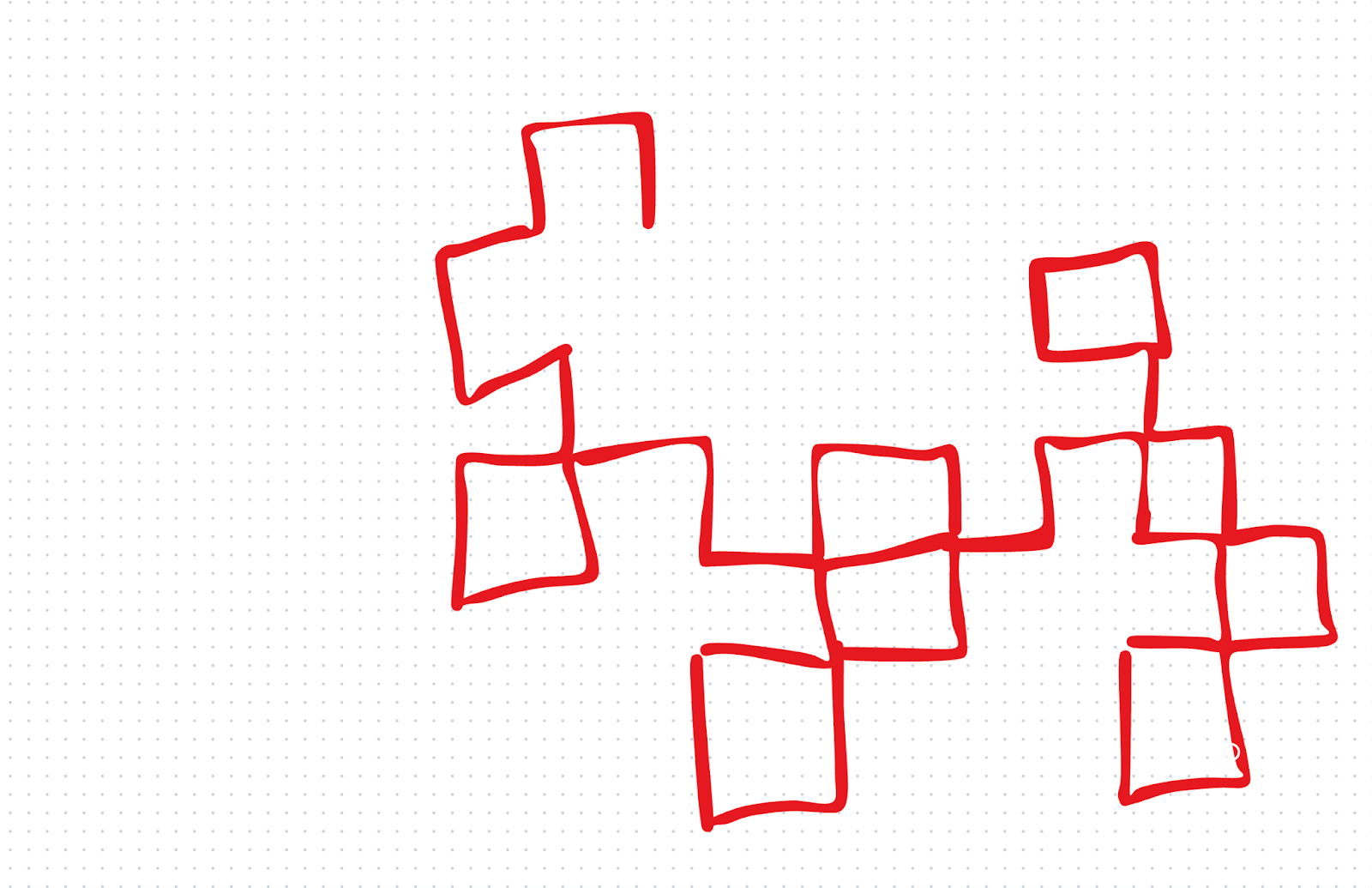
o1 answered incorrectly. o3, on the other hand, got it right: It told us we were starting to draw the dragon curve. This was a small test, but we were impressed with the result because we didn’t give o3 much to go on.

Interestingly, the cost versus performance metrics are better with o3. That is, the performance is higher at the same levels of inference cost. This could be thanks to architectural optimizations that improve token throughput and reduce latency. Cost has been a big topic of discussion ever since Deepseek-R1 announced super high performance at a fraction of the cost of ChatGPT.
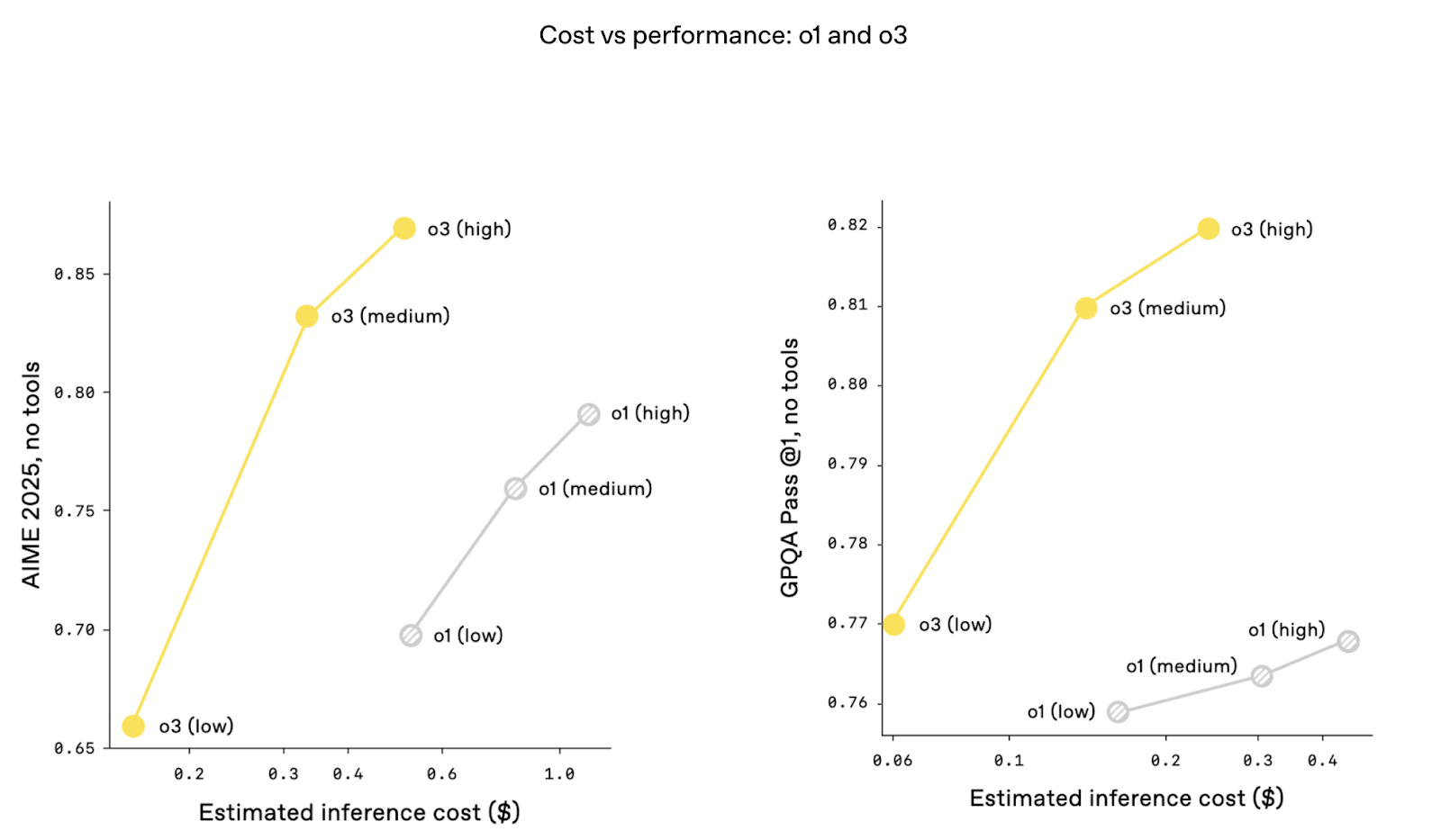
As of April 2025, o3-mini has been fully replaced by o4-mini in ChatGPT and the API. o4-mini offers better performance on most benchmarks, adds native multimodal input, and retains tool compatibility—all while remaining faster and more affordable than o3. In effect, o4-mini now takes over the role that o3-mini was designed to fill. The content below, however, remains valid about o3-mini.
o3-mini was introduced alongside o3 as a cost-efficient alternative designed to bring advanced reasoning capabilities to more users while maintaining performance. OpenAI described o3-mini as redefining the “cost-performance frontier” in reasoning models, making it accessible for tasks that demand high accuracy but need to balance resource constraints.
One of the standout features of o3-mini is its adaptive thinking time, which allows users to adjust the model’s reasoning effort based on the complexity of the task. For simpler problems, users can select low-effort reasoning to maximize speed and efficiency.
For more challenging tasks, higher reasoning effort options enable the model to perform at levels comparable to o3 itself, but at a fraction of the cost. This flexibility is particularly compelling for developers and researchers working across diverse use cases.
Source: OpenAI
The live demo showcased how o3-mini delivers on its promise. For example, in a coding task, o3-mini was tasked with generating a Python script to create a local server with an interactive UI for testing. Despite the complexity of the task, the model performed well, demonstrating its ability to handle programming challenges.
Source: OpenAI
We see o3-mini as a practical solution for scenarios where cost-effectiveness and performance must align.
It took some extra time for O3 to become available, and some of the reasons might have been related to innovations in safety.
OpenAI said it rebuilt its safety training datasets and introduced thousands of targeted refusal prompts. They called out specific categories: biological threats, malware generation, and jailbreak techniques. This refreshed training data has enabled o3 to demonstrate strong refusal accuracy on internal benchmarks, such as instruction hierarchy handling and jailbreak resilience. To accomplish this, reportedly, OpenAI had team members spend a thousand hours flagging unsafe content.
OpenAI has also implemented a reasoning-based LLM monitor (what they call a “safety-focused reasoning monitor”). So in addition to training the model to say “no” to unsafe prompts, OpenAI has introduced an additional safety layer, which is a reasoning-based LLM. Think of this as a watchdog model running in parallel, trained specifically to reason through the intent and potential risks of user inputs, using human-written safety rules as a guide.
OpenAI has adopted a proactive approach to safety testing for o3 and o3 mini by opening access to researchers for public safety evaluations before the models’ full release.
A central feature of OpenAI’s safety strategy for o3 is deliberative alignment, a method that goes beyond traditional safety approaches. The graph below highlights how deliberative alignment differs from other methods such as RLHF (Reinforcement Learning with Human Feedback), RLAIF (Reinforcement Learning with AI Feedback), and inference-time refinement techniques like Self-REFINE.
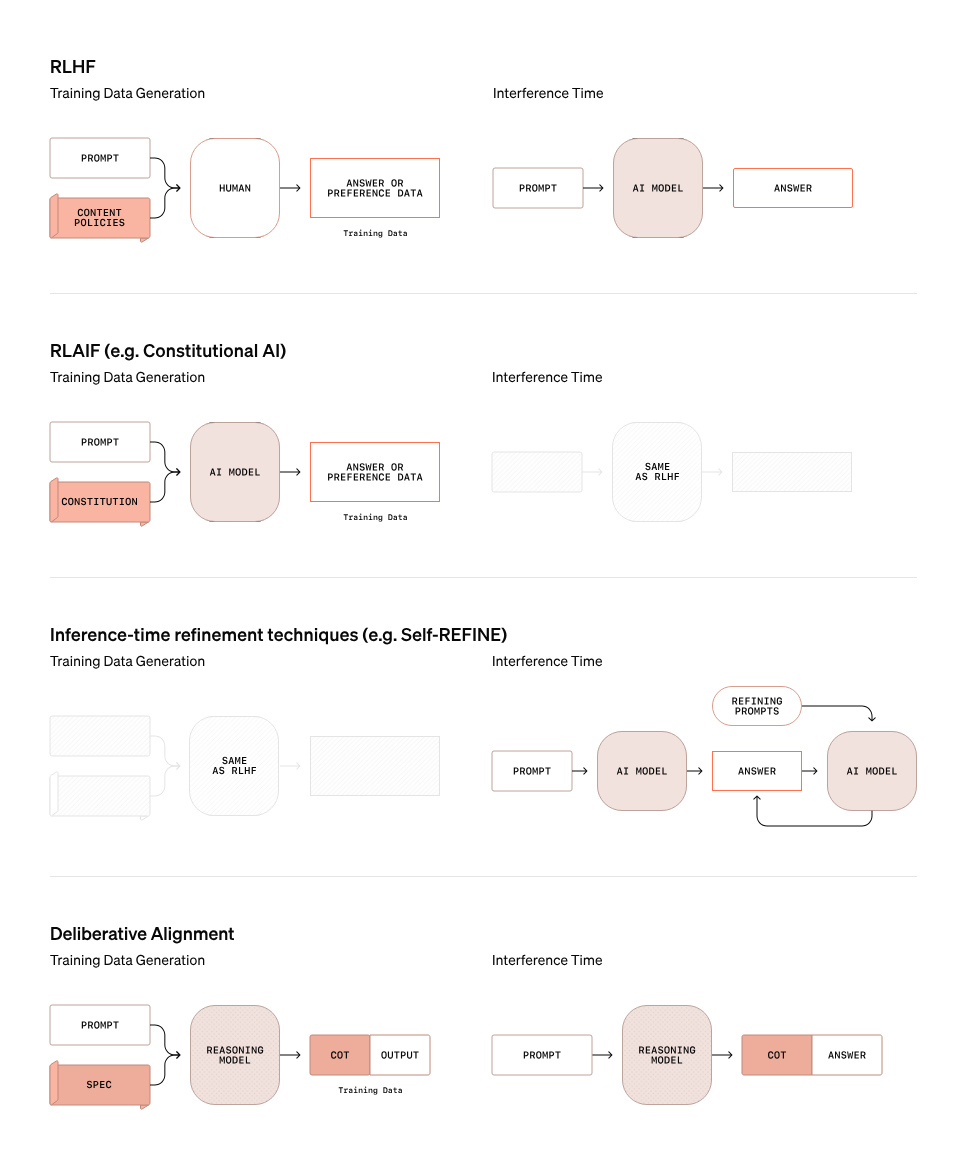
Source: OpenAI
In deliberative alignment, the model doesn’t simply rely on static rules or preference datasets to determine whether a prompt is safe or unsafe. Instead, it uses its reasoning capabilities to evaluate prompts in real-time. The graph above illustrates this process:
OpenAI expects that we will want to keep reading up on safety. In anticipation of this, they released their Preparedness Framework with their ideas on measuring and protecting against severe harm.
In the ChatGPT model picker, you’ll now see o3 and o4-mini available. According to OpenAI’s announcement, o3-pro is expected to launch in the coming weeks. It will include the same tool-use capabilities—such as Python, browsing, and image analysis—as the other models in the o-series.
If you’re interested in updates on when o3-pro becomes available, sign up for DataCamp’s newsletter, The Median, and we’ll let you know as soon as it drops.
O3 and o3 mini highlight the growing complexity of AI systems and the challenges of releasing them responsibly. While the benchmarks are impressive, we find ourselves more interested in the questions these models raise: How well will they continue to perform in real-world scenarios? Are the safety measures robust enough to address edge cases at scale?
To us, o3 and o3 mini are early signals of AI systems inching toward greater autonomy. Their impressive reasoning and adaptability suggest a shift from tools we operate to agents that act on our behalf. What happens when these systems navigate open-ended tasks without human prompting? How do we evaluate models that generate their own goals, not just their outputs?
If you’re interested in exploring more AI topics, we recommend:
Learn AI with these courses!
Track
Course
Course
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Richie Cotton
8 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
Tutorial
Abid Ali Awan




