
Programa
Fundamentos da IA
10 h
O mecanismo de atenção está no centro dos modelos transformadores. Todas as arquiteturas de modelos populares, como GPT, LLaMAe Mixture of Experts (MoE), dependem dele para conectar tokens e construir significado.
Mas a atenção custa caro. Seu cálculo envolve grandes multiplicações de matrizes e, mais importante ainda, movimentação massiva de dados entre a memória da GPU e as unidades de computação. À medida que o tamanho das sequências aumenta, a largura de banda da memória se torna o verdadeiro gargalo.
Otimizar a atenção, portanto, tem um impacto enorme no desempenho do LLM. desempenho do LLM, e é exatamente aí que entra o Flash Attention. Neste artigo, vou te explicar o que é Flash Attention, como funciona e como usá-lo com PyTorch e Hugging Face Transformers.
Se você está procurando uma maneira de começar a usar LLMs, recomendo fazer nosso curso introdutório sobre conceitos de LLM.
O Flash Attention é um mecanismo de atenção otimizado para transformadores ,, tornando-o significativamente mais rápido e eficiente em termos de memória nas GPUs.
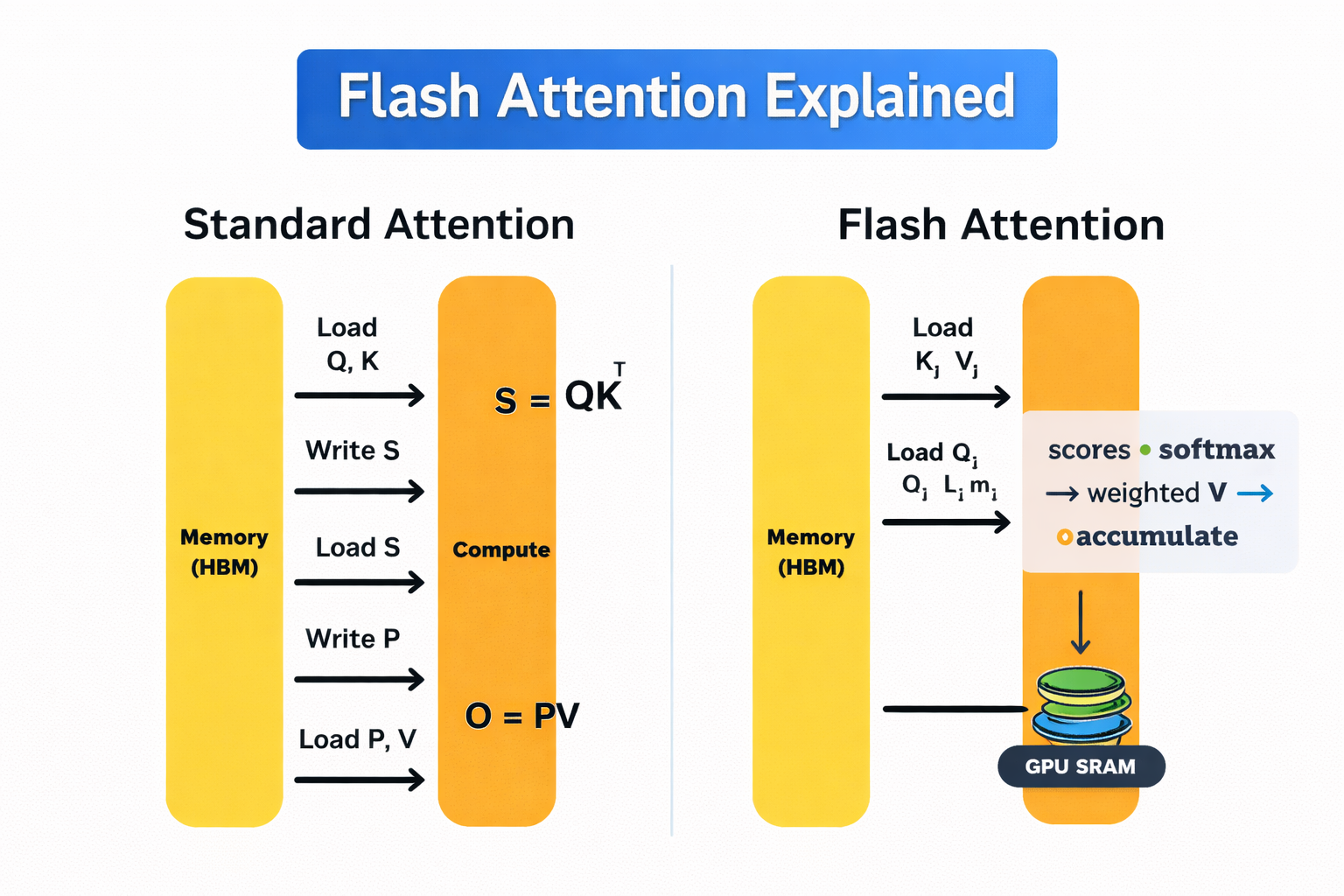
Atenção padrão vs. atenção instantânea
As GPUs têm dois tipos principais de memória. A memória de alta largura de banda (HBM) é grande, mas relativamente lenta. A SRAM no chip é super rápida, mas tem um tamanho bem limitado.
A autoatenção padrão troca dados constantemente entre esses dois. Essa troca de mensagens é cara e se torna um custo significativo à medida que o comprimento da sequência aumenta.
O Flash Attention evita isso calculando a atenção em pequenos blocos que cabem inteiramente na SRAM rápida. Cadabloco do é processado de ponta a ponta com um, com softmax aplicado de forma incremental, então os resultados intermediários não precisam ser gravados de volta no HBM. Então, a matriz de atenção completa nunca fica guardada na memória.
Diferente dos métodos de atenção esparsa ou linear, a Flash Attention não é uma aproximação. Ele gera exatamente o mesmo resultado matemático que a autoatenção padrão, só que de um jeito mais eficiente em termos de memória.
O Flash Attention consegue ser eficiente porque repensou como calcula a atenção na GPU. Segue um mecanismo simples: faça o máximo de trabalho possível na memória rápida do chip e evite movimentos desnecessários para a memória lenta.
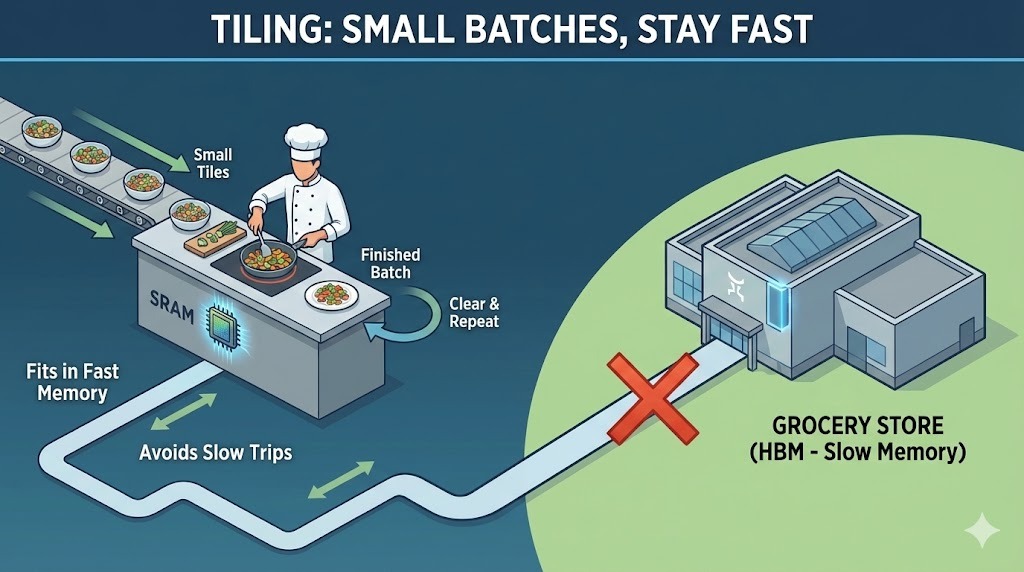
Uma boa maneira de pensar sobre isso é usar uma analogia com a cozinha. A SRAM no chip da GPU é tipo uma bancada de cozinha pequena e rápida. É onde você realmente prepara e cozinha. A memória de alta largura de banda (HBM) da GPU é como um grande supermercado na sua rua. Ele pode guardar tudo o que você precisa, mas ficar indo e voltando leva tempo.
Simplificando, a atenção padrão continua indo ao supermercado depois de cada passo. Já o Flash Attention planeja o cozimento pra que tudo caiba na bancada enquanto você cozinha. Vamos entender isso com mais detalhes:
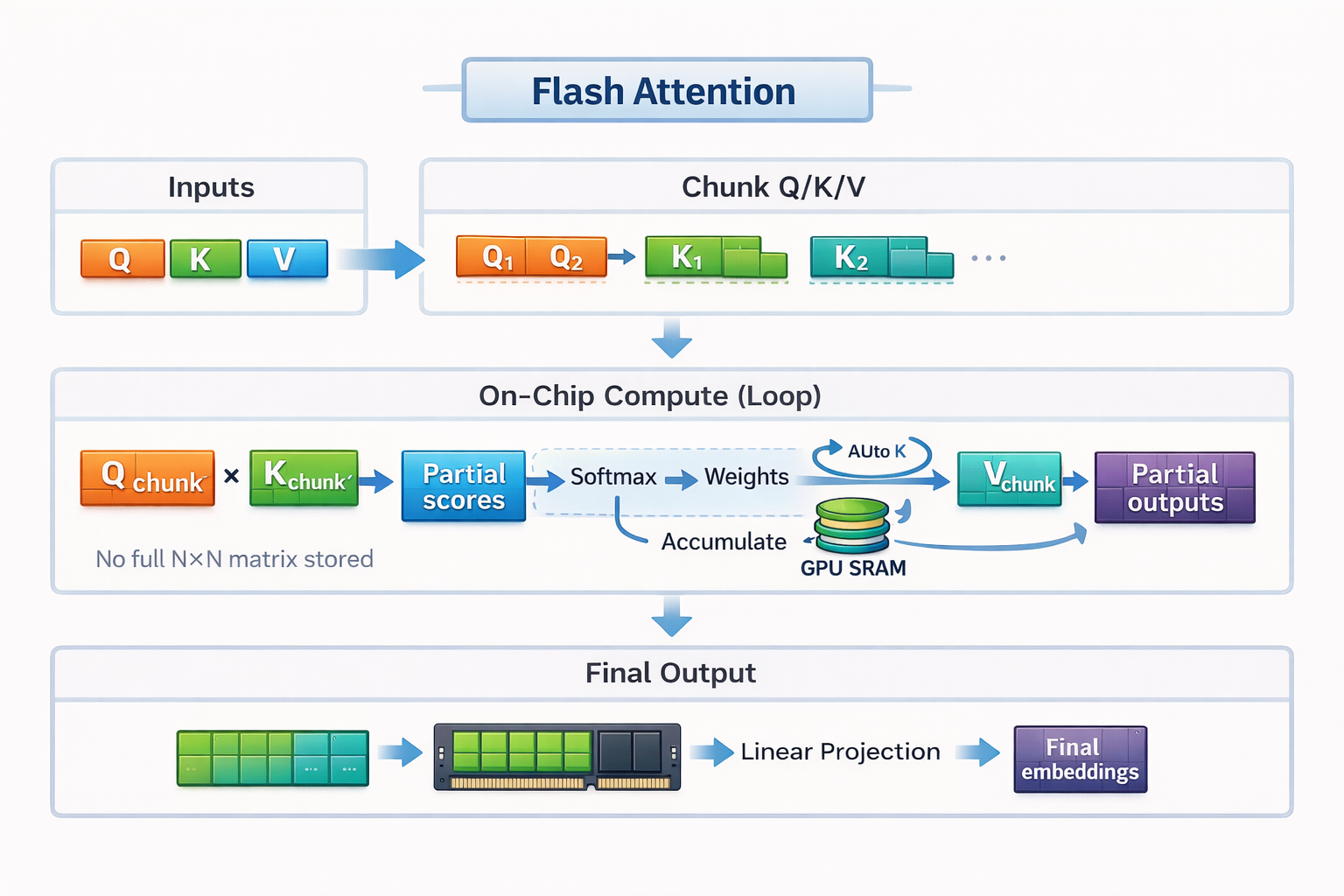
Mecanismo de funcionamento do Flash Attention
O Flash Attention se baseia em duas ideias principais: tiling e recomputação.
Pra continuar com o nosso exemplo da culinária, o tiling é como o Flash Attention encaixa o cálculo da atenção na pequena bancada.
Em vez de carregar toda a sequência e construir uma matriz de atenção completa, o Flash Attention divide as entradas em pequenos blocos, ou mosaicos. Cada bloco cabe inteiramente na SRAM rápida da GPU. O Flash Attention calcula a atenção um bloco de cada vez, do início ao fim, antes de passar para o próximo bloco.
Pela analogia da cozinha, não dá pra colocar todos os ingredientes de um banquete inteiro em uma bancada pequena. Então você prepara e cozinha em pequenas porções. Você corta alguns legumes, cozinha-os, limpa o espaço e depois passa para a próxima leva. Trabalhando assim, você evita ficar indo e voltando o tempo todo ao supermercado.
Essa execução bloco por bloco permite que o Flash Attention mantenha os dados locais, rápidos e eficientes, sem nunca materializar a matriz de atenção completa na memória lenta.
Atenção ao usar o Flash
Durante o treinamento, a atenção padrão guarda muitos resultados intermediários para que possam ser reutilizados durante a passagem para trás. Esse armazenamento tem um custo alto de memória. O Flash Attention tem uma abordagem diferente. Em vez de guardar esses intermediários, ele recalcula pequenas partes das pontuações de atenção sempre que elas são necessárias.
De volta à cozinha, isso é como cortar cebolas. Você pode ir a pé até o supermercado para guardar suas cebolas picadas e depois voltar a pé para buscá-las. Ou você pode jogá-las fora e simplesmente picar uma cebola fresca na hora de cozinhar. Surpreendentemente, a segunda opção é mais rápida porque evita movimentos frequentes/mais longos.
Nas GPUs modernas, o recálculo segue a mesma lógica, porque o cálculo extra é barato comparado com os movimentos de memória. Ao recalcular valores pequenos em vez de armazená-los e carregá-los, o Flash Attention reduz bastante o tráfego de memória, mantendo o treinamento eficiente.
Juntos, o mosaico e o recálculo permitem que o Flash Attention mantenha o cálculo da atenção no contador, minimize as idas ao supermercado e use totalmente os pontos fortes do hardware moderno da GPU.
O Flash Attention 2 (FA2), lançado em 2023, é uma grande atualização em relação à primeira geração. Ele mantém a mesma ideia central de atenção precisa e consciente da E/S, mas melhora a eficiência em várias dimensões importantes nas cargas de trabalho do mundo real.
A primeira versão do Flash Attention paralelizou o cálculo entre o tamanho do lote e os cabeçalhos de atenção. Isso funcionou bem para configurações de treinamento com grandes lotes. Mas não era tão ideal para inferências, onde os tamanhos dos lotes costumam ser pequenos e os comprimentos das sequências são longos.
O FA2 adiciona paralelismo em toda a dimensão do comprimento da sequência. Isso permite que mais partes do cálculo de atenção sejam executadas ao mesmo tempo, mesmo quando o tamanho do lote é pequeno. Ao distribuir o trabalho entre os tokens na sequência, a v2 mantém mais unidades de computação da GPU ocupadas ao mesmo tempo.
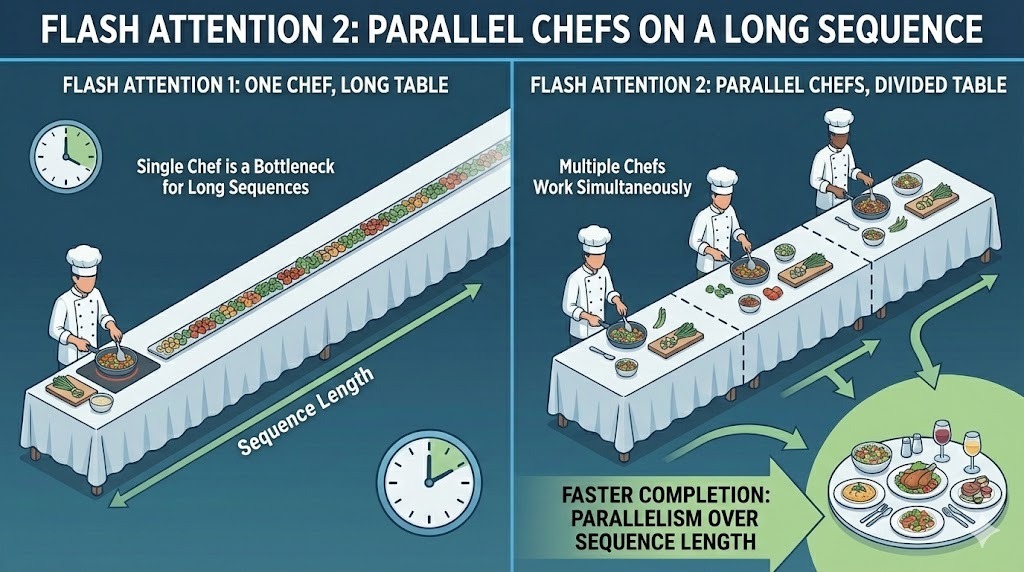
Paralelismo entre lotes no Flash Attention 2
A vantagem prática é um rendimento maior e uma melhor utilização do hardware em cenários comuns de inferência, onde prompts longos e pequenos lotes são a norma.
As GPUs são super boas em multiplicação de matrizes. Um hardware especial chamado Tensor Cores consegue fazer operações de multiplicação de matrizes gerais (GEMM) super rápido.
O problema é que a atenção não é só multiplicação de matrizes: envolve operações como dimensionamento, mascaramento e softmax, que rolam em núcleos de GPU padrão e são bem mais lentas em comparação.
A FA2 diminuiu esse desequilíbrio. Reestrutura o cálculo para minimizar as operações de ponto flutuante não matriciais, especialmente aquelas envolvidas no redimensionamento das pontuações de atenção. A maior parte do tempo de execução é gasta em operações matriciais grandes e eficientes que os Tensor Cores podem acelerar.
O Flash Attention v1 foi otimizado para dimensões de cabeça de 64 ou 128, que combinavam com modelos como BERT e GPT-3. Conforme as arquiteturas dos modelos foram evoluindo, as dimensões dos cabeçotes ficaram maiores para dar suporte a tamanhos de incorporação maiores e maior capacidade do modelo.
O FA2 passou a dar suporte a cabeçotes com dimensões de até 256. Isso o tornou compatível com arquiteturas mais recentes que dependem de cabeças de atenção mais amplas.
O Flash Attention 3 (FA3) é o padrão atual da indústria que alimenta modelos de última geração como o GPT-5.2. Ele se baseia na mesma estrutura de atenção exata e sensível à E/S das versões anteriores, mas foi projetado especificamente para GPUs NVIDIA H100 (Hopper).
A principal mudança é que o FA3 foi projetado para explorar os novos recursos de hardware assíncrono do Hopper, permitindo que a movimentação da memória e a computação se sobreponham de forma muito mais agressiva do que antes.
Nas versões anteriores, todos os threads da GPU, conhecidos como warps, seguiam o mesmo caminho de execução. O FA3 muda esse modelo com a especialização em warp. Ele atribui uma de duas funções distintas a cada warp:
Essa separação permite que a transferência de dados e o cálculo aconteçam ao mesmo tempo. Enquanto os warps produtores buscam os próximos blocos de dados, os warps consumidores continuam ocupados fazendo cálculos nos blocos atuais, melhorando bastante a latência.
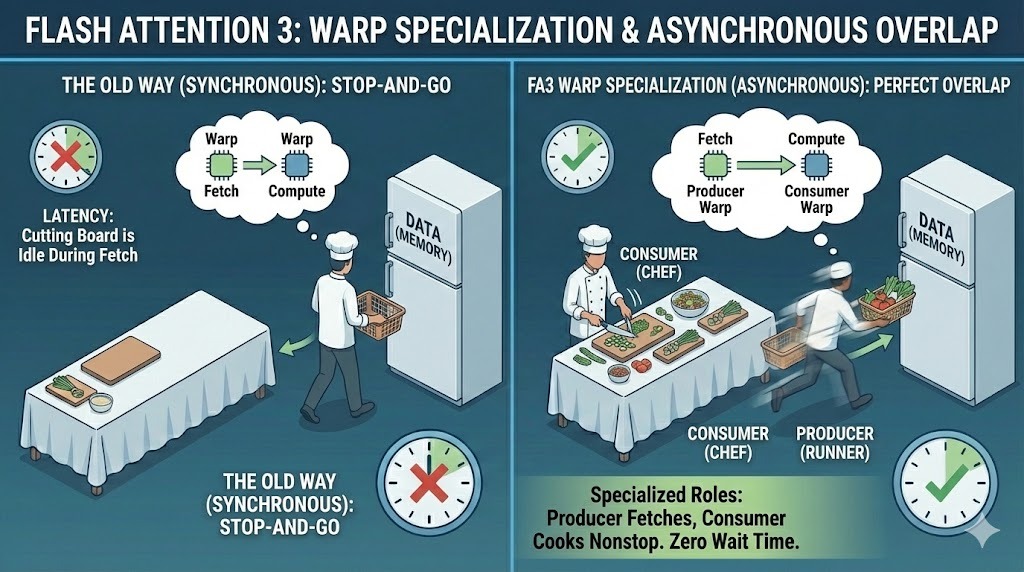
Especialização em Warp no Flash Attention 3
O Flash Attention 3 também traz suporte nativo para FP8, ou precisão de ponto flutuante de 8 bits. As versões anteriores dependiam principalmente de FP16 ou BF16, que já reduziam o uso de memória em comparação com FP32, mas ainda consumiam uma largura de banda significativa.
O FP8 reduz o consumo de memória pra mais ou menos a metade de novo. Essa redução significa mais produtividade e menos pressão na memória. Nas GPUs Hopper, o FP8 tem aceleração por hardware, o que significa que o FA3 pode processar mais operações de atenção por segundo sem perder a precisão no nível do modelo.
Essa capacidade é uma das principais razões pelas quais modelos grandes como o Gemini 3 conseguem lidar com janelas de contexto enormes janelas de contexto enquanto atendem milhões de usuários de forma eficiente.
Uma última parte do design do FA3 é o uso do Tensor Memory Accelerator, ou TMA, do H100. O TMA é um hardware especializado que lida com cópias de memória de forma assíncrona, sem ocupar os principais núcleos de computação.
O Flash Attention 3 usa o TMA para mover blocos de dados em segundo plano enquanto a computação continua sem interrupções. Ao combinar o movimento da memória com a matemática, o FA3 consegue extrair quase 75% do desempenho máximo teórico do hardware.
O Flash Attention 4 (FA4) é o próximo passo experimental na otimização da atenção. Ele foi feito para as futuras GPUs Blackwell B200 da NVIDIA e mostra o que pode ser feito quando os kernels de atenção são criados para uma classe totalmente nova de hardware.
À medida que os tamanhos dos modelos continuam a crescer e os treinamentos avançam para a escala de trilhões de parâmetros, até mesmo o Flash Attention 3 acabará atingindo seus limites. O FA4 é uma tentativa inicial de acabar com esses limites, levando a utilização do hardware mais longe do que qualquer outro kernel anterior.
Nesta fase, o Flash Attention 4 é uma tecnologia em fase de pesquisa e pré-produção. Parece muito promissor, mas ainda não é usado em modelos implantados ou de nível de produção.
Um dos principais destaques do Flash Attention 4 é o desempenho. É o primeiro kernel de atenção projetado para ultrapassar 1 PFLOPS, ou um quatrilhão de operações de ponto flutuante por segundo, em uma única GPU.
O objetivo é chegar a um futuro em que treinar modelos com trilhões de parâmetros não demore uma eternidade pra terminar. Nessa escala, mesmo pequenas ineficiências podem causar atrasos enormes. O FA4 quer tornar esses treinos futuros possíveis, tirando o máximo de um único chip.
Para chegar a esse desempenho, o FA4 leva a assincronia muito mais longe do que as versões anteriores. Ele estende o modelo produtor-consumidor para pipelines altamente complexos e com várias etapas, onde a movimentação de dados, a computação e a sincronização operam de forma independente.
Em vez de uma sobreposição relativamente simples entre carregamento e computação, o FA4 gerencia a execução profundamente assíncrona em várias etapas. Diferentes partes do kernel avançam em velocidades diferentes, coordenadas por um agendamento no nível do hardware, em vez de um único fluxo sincronizado.
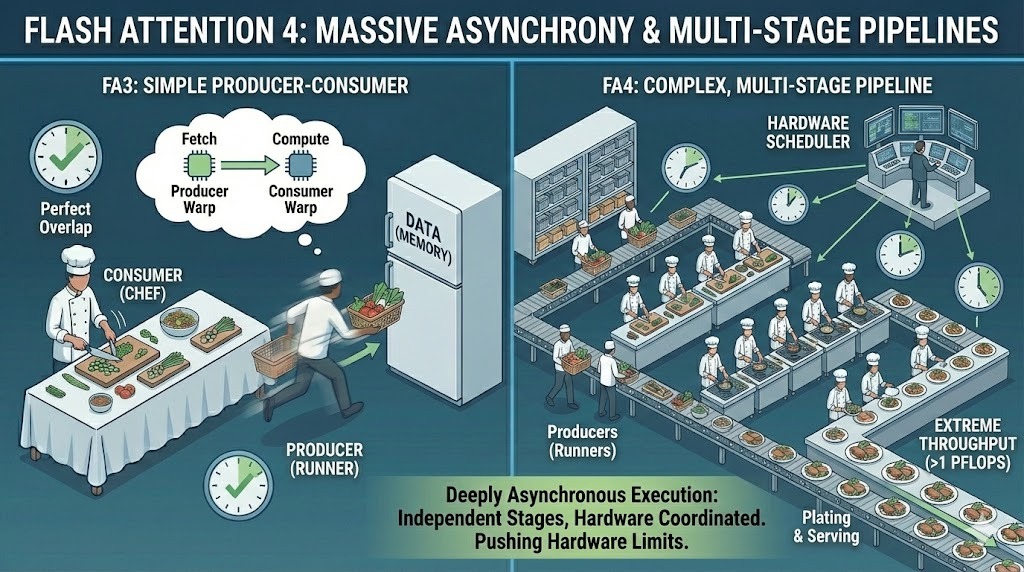
Grande asincronia no Flash Attention 4
Essa complexidade também é o motivo pelo qual o FA4 continua sendo experimental. É um desafio gerenciar a precisão, a estabilidade e a integração nesse nível. A comunidade ainda precisa trabalhar mais antes que as equipes possam usá-la com segurança em grandes modelos de produção.
Vamos ver como o Flash Attention se compara ao mecanismo de atenção padrão em alguns domínios importantes.
Os benchmarks mostram sempre que todas as versões do Flash Attention são melhores do que a autoatenção padrão, com ganhos que aumentam conforme a sequência fica mais longa.
O artigo original sobre Flash Attention relata um aumento de velocidade de aproximadamente 2 a 4 vezes em relação à atenção padrão otimizada. O Flash Attention 2 melhora ainda mais isso, aumentando o paralelismo e saturando melhor a GPU, muitas vezes proporcionando outra melhoria de ~2× na prática.
O Flash Attention 3 melhora ainda mais o desempenho nas GPUs Hopper, principalmente com FP8, conseguindo uma utilização de hardware muito maior do que a atenção padrão consegue.
A atenção padrão mostra explicitamente a matriz de atenção N × N completa, o que faz com que a memória cresça quadraticamente em relação ao comprimento da sequência. À medida que N cresce, o uso da memória explode, sobrecarregando rapidamente a memória da GPU. O Flash Attention evita armazenar essa matriz por completo.
Ao calcular a atenção em blocos e manter os resultados intermediários na memória rápida do chip, ele reduz o uso de memória para linear no comprimento da sequência para dimensões fixas da cabeça. Essa mudança da escala de memória quadrática para linear elimina o maior gargalo estrutural na atenção padrão.
Essa redução de memória permite janelas de contexto mais longas. Com a atenção padrão, os modelos geralmente apresentam erros de memória insuficiente quando as sequências atingem alguns milhares de tokens.
O Flash Attention torna os contextos de tokens de 4k e 8k práticos em uma única GPU e ainda abre janelas muito mais longas, como tokens de 16k ou 32k, nesse único dispositivo quando combinado com outras técnicas de economia de memória.
Não fique confuso aqui: As janelas enormes de milhões de tokens alcançadas em alguns modelos de fronteira atuais, como o Gemini 3, são obtidas dividindo a sequência entre grandes clusters de GPUs, pois excedem em muito a capacidade de memória de qualquer dispositivo individual.
Hoje em dia, usar o Flash Attention é bem mais fácil do que antigamente. Na maioria dos casos, você não precisa escrever kernels CUDA personalizados ou alterar a arquitetura do seu modelo. O suporte já está integrado nas ferramentas populares atualmente.
Desde PyTorch 2.0, o Flash Attention está disponível diretamente em torch.nn.functional.scaled_dot_product_attention. Quando você chama essa função, o PyTorch escolhe automaticamente o backend de atenção mais rápido disponível para o seu hardware.
Nas GPUs compatíveis, esse backend é o Flash Attention. Do ponto de vista do usuário, muitas vezes parece um código de atenção padrão, mas, nos bastidores, o PyTorch envia um kernel Flash Attention otimizado.
Se você estiver usando o Hugging Face Transformers, ativar o Flash Attention geralmente é uma mudança de uma linha. Definir attn_implementation="flash_attention_2" na configuração do modelo diz à biblioteca para usar o Flash Attention 2 sempre que possível.
Para muitos modelos de transformadores, isso é o suficiente para melhorar a velocidade e a memória sem mexer no resto do código de treinamento ou inferência.
O Flash Attention 2 é feito pra placas de vídeo NVIDIA modernas e funciona melhor nas arquiteturas Ampere, Ada e Hopper, incluindo as placas A100, RTX 3090, RTX 4090 e H100. Essas GPUs oferecem a largura de banda de memória e os recursos arquitetônicos necessários para aproveitar ao máximo o tiling e o paralelismo no FA2.
Também vale a pena notar que o Flash Attention v1 original também suporta GPUs mais antigas. Placas baseadas em Turing, como a T4 e a RTX 2080, ainda podem usar o Flash Attention v1, embora as versões mais recentes precisem de hardware mais novo para aproveitar todo o ganho de desempenho.
Na prática, se você já está usando o PyTorch 2.x ou o Hugging Face Transformers em uma GPU NVIDIA moderna, o Flash Attention geralmente está a apenas uma mudança de configuração de distância.
A atenção padrão esbarrou numa parede dura porque o crescimento quadrático da memória tornou as sequências longas lentas, caras ou simplesmente impossíveis devido a falhas de memória insuficiente. O Flash Attention mudou isso ao repensar como a atenção é dada.
Ao reduzir o uso de memória de quadrático para linear em relação ao comprimento da sequência, o Flash Attention torna a modelagem de contexto longo mais prática. Janelas de contexto que antes sobrecarregavam as GPUs com alguns milhares de tokens agora chegam a 4k, 8k e até mais de 32k tokens no mesmo hardware.
Se você está trabalhando com transformadores em grande escala e não está usando o Flash Attention, com certeza está deixando o desempenho de lado.
Quer criar seus próprios modelos que usam o Flash Attention? Faça nosso curso sobre modelos transformadores com PyTorch!
Cursos de IA
Programa
Curso
Curso
blog
Natassha Selvaraj
15 min
blog
Abid Ali Awan
5 min
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Arjun Sarkar

