Course
Intermediate Python
4 hr
1.4M
In the time when the internet is rich with so much data, and apparently, data has become the new oil, web scraping has become even more important and practical to use in various applications. Web scraping deals with extracting or scraping the information from the website. Web scraping is also sometimes referred to as web harvesting or web data extraction. Copying text from a website and pasting it to your local system is also web scraping. However, it is a manual task. Generally, web scraping deals with extracting data automatically with the help of web crawlers. Web crawlers are scripts that connect to the world wide web using the HTTP protocol and allows you to fetch data in an automated manner.
Whether you are a data scientist, engineer, or anybody who analyzes vast amounts of datasets, the ability to scrape data from the web is a useful skill to have. Let's say you find data from the web, and there is no direct way to download it, web scraping using Python is a skill you can use to extract the data into a useful form that can then be imported and used in various ways.
Some of the practical applications of web scraping could be:
Apart from the above use-cases, web scraping is widely used in natural language processing for extracting text from the websites for training a deep learning model.
Before proceeding, keep in mind that websites like Amazon may update their specific terms of service or create new technical restrictions that affect how their content can be accessed or reused. It is your responsibility to review the site’s Terms of Service and robots.txt file to ensure that your particular use case is compliant. Policies can change and the permissions can vary.
One of the challenges you would come across while scraping information from websites is the various structures of websites. Meaning, the templates of websites will differ and will be unique; hence, generalizing across websites could be a challenge.
Another challenge could be longevity. Since the web developers keep updating their websites, you cannot certainly rely on one scraper for too long. Even though the modifications might be minor, but they still might create a hindrance for you while fetching the data.
Hence, to address the above challenges, there could be various possible solutions. One would be to follow continuous integration & development (CI/CD) and constant maintenance as the website modifications would be dynamic.
Another more realistic approach is to use Application Programming Interfaces (APIs) offered by various websites & platforms. For example, Facebook and twitter provide you API's specially designed for developers who want to experiment with their data or would like extract information to let's say related to all friends & mutual friends and draw a connection graph of it. The format of the data when using APIs is different from usual web scraping i.e., JSON or XML, while in standard web scraping, you mainly deal with data in HTML format.
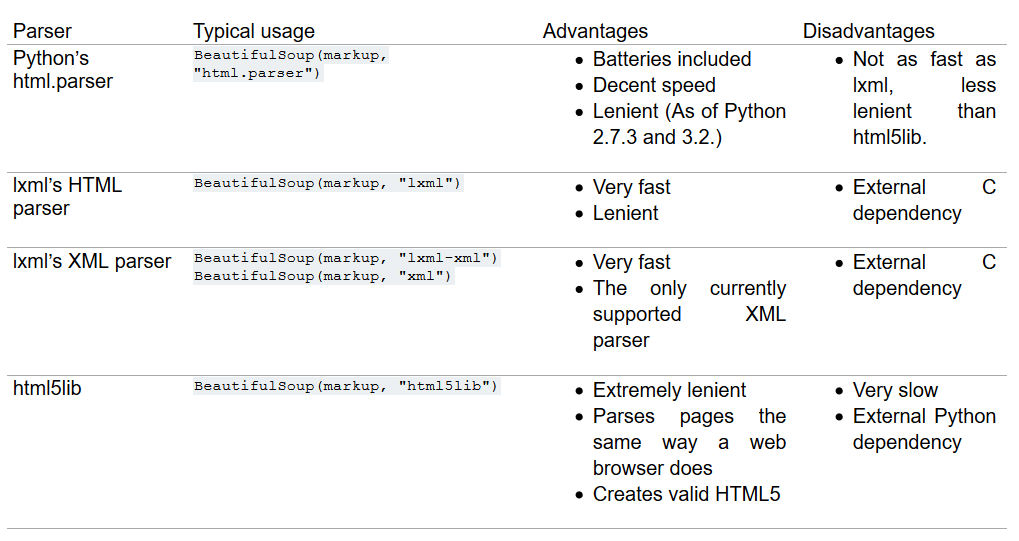
Beautiful Soup is a pure Python library for extracting structured data from a website. It allows you to parse data from HTML and XML files. It acts as a helper module and interacts with HTML in a similar and better way as to how you would interact with a web page using other available developer tools.
It usually saves programmers hours or days of work since it works with your favorite parsers like lxml and html5lib to provide organic Python ways of navigating, searching, and modifying the parse tree.
Another powerful and useful feature of beautiful soup is its intelligence to convert the documents being fetched to Unicode and outgoing documents to UTF-8. As a developer, you do not have to take care of that unless the document intrinsic doesn't specify an encoding or Beautiful Soup is unable to detect one.
It is also considered to be faster when compared to other general parsing or scraping techniques.
Feel free to read more about it from here.
Enough of theory, right? So, let's install beautiful soup and start learning about its features and capabilities using Python.
As a first step, you need to install the Beautiful Soup library using your terminal or jupyter lab. The best way to install beautiful soup is via pip, so make sure you have the pip module already installed.
!pip3 install beautifulsoup4
Requirement already satisfied: beautifulsoup4 in /usr/local/lib/python3.7/site-packages (4.7.1)
Requirement already satisfied: soupsieve>=1.2 in /usr/local/lib/python3.7/site-packages (from beautifulsoup4) (1.9.5)
Let's import the required packages which you will use to scrape the data from the website and visualize it with the help of seaborn, matplotlib, and bokeh.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import re
import time
from datetime import datetime
import matplotlib.dates as mdates
import matplotlib.ticker as ticker
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
This URL that you are going to scrape is the following: https://www.amazon.in/gp/bestsellers/books/. The page argument can be modified to access data for each page. Hence, to access all the pages you will need to loop through all the pages to get the necessary dataset, but first, you need to find out the number of pages from the website.
To connect to the URL and fetch the HTML content following things are required:
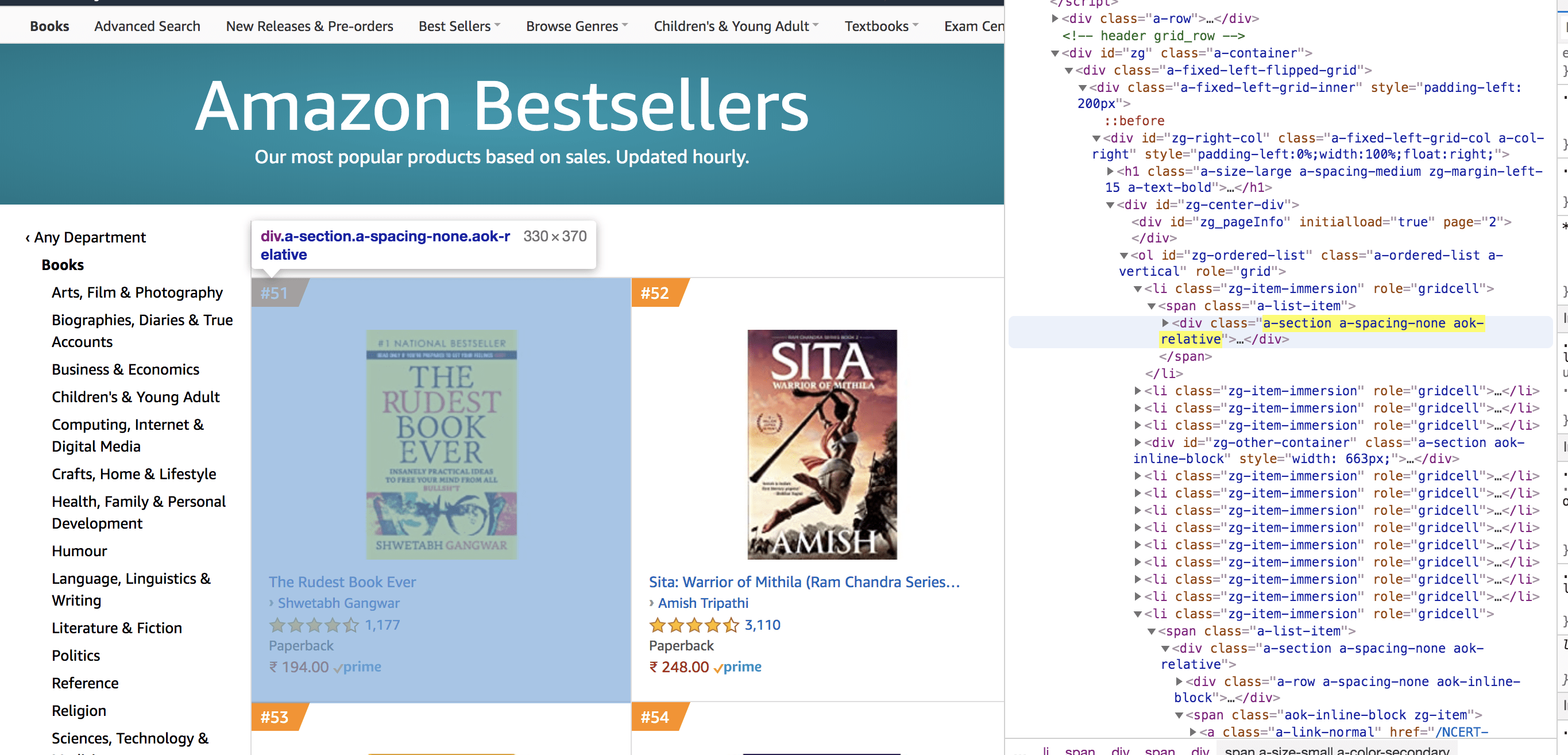
get_data function which will input the page numbers as an argument,user-agent which will help in bypassing the detection as a scraper,requests.get and pass the user-agent header as an argument,Next and the important step is to identify the parent tag under which all the data you need will reside. The data that you are going to extract is:
The below image shows where the parent tag is located, and when you hover over it, all the required elements are highlighted.
Similar to the parent tag, you need to find the attributes for book name, author, rating, customers rated, and price. You will have to go to the webpage you would like to scrape, select the attribute and right-click on it, and select inspect element. This will help you in finding out the specific information fields you need an extract from the sheer HTML web page, as shown in the figure below:
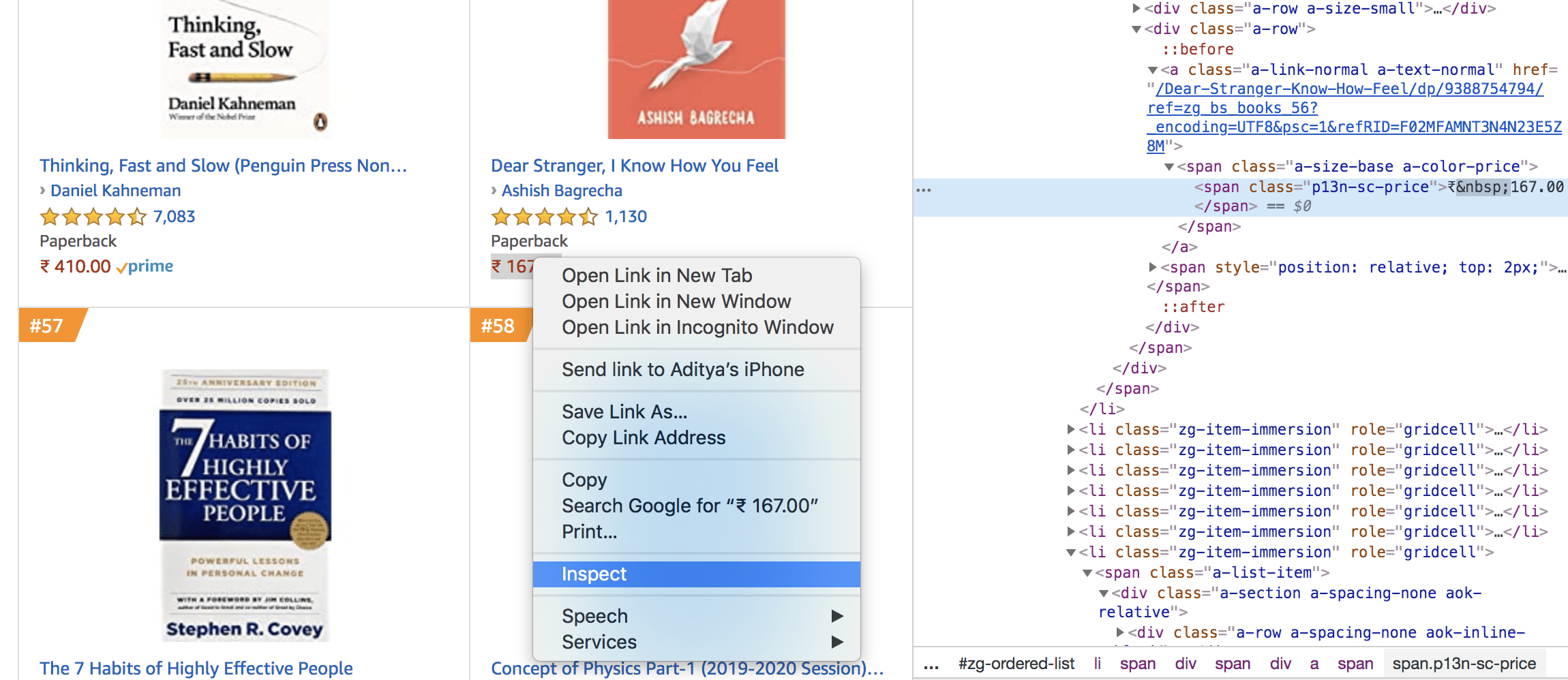
Note that some author names are not registered with Amazon, so you need to apply extra find for those authors. In the below cell code, you would find nested if-else conditions for author names, which are to extract the author/publication names.
no_pages = 2
def get_data(pageNo):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept-Encoding":"gzip, deflate", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "DNT":"1","Connection":"close", "Upgrade-Insecure-Requests":"1"}
r = requests.get('https://www.amazon.in/gp/bestsellers/books/ref=zg_bs_pg_'+str(pageNo)+'?ie=UTF8&pg='+str(pageNo), headers=headers)#, proxies=proxies)
content = r.content
soup = BeautifulSoup(content)
#print(soup)
alls = []
for d in soup.findAll('div', attrs={'class':'a-section a-spacing-none aok-relative'}):
#print(d)
name = d.find('span', attrs={'class':'zg-text-center-align'})
n = name.find_all('img', alt=True)
#print(n[0]['alt'])
author = d.find('a', attrs={'class':'a-size-small a-link-child'})
rating = d.find('span', attrs={'class':'a-icon-alt'})
users_rated = d.find('a', attrs={'class':'a-size-small a-link-normal'})
price = d.find('span', attrs={'class':'p13n-sc-price'})
all1=[]
if name is not None:
#print(n[0]['alt'])
all1.append(n[0]['alt'])
else:
all1.append("unknown-product")
if author is not None:
#print(author.text)
all1.append(author.text)
elif author is None:
author = d.find('span', attrs={'class':'a-size-small a-color-base'})
if author is not None:
all1.append(author.text)
else:
all1.append('0')
if rating is not None:
#print(rating.text)
all1.append(rating.text)
else:
all1.append('-1')
if users_rated is not None:
#print(price.text)
all1.append(users_rated.text)
else:
all1.append('0')
if price is not None:
#print(price.text)
all1.append(price.text)
else:
all1.append('0')
alls.append(all1)
return alls
The below code cell will perform the following functions:
get_data function inside a for loop,for loop will iterate over this function starting from 1 till the number of pages+1.results = []
for i in range(1, no_pages+1):
results.append(get_data(i))
flatten = lambda l: [item for sublist in l for item in sublist]
df = pd.DataFrame(flatten(results),columns=['Book Name','Author','Rating','Customers_Rated', 'Price'])
df.to_csv('amazon_products.csv', index=False, encoding='utf-8')
Now let's load the CSV file you created and save in the above cell. Again, this is an optional step; you could even use the dataframe df directly and ignore the below step.
df = pd.read_csv("amazon_products.csv")
df.shape
(100, 5)
The shape of the dataframe reveals that there are 100 rows and 5 columns in your CSV file.
Let's print the first 5 rows of the dataset.
df.head(61)
| Book Name | Author | Rating | Customers_Rated | Price | |
|---|---|---|---|---|---|
| 0 | The Power of your Subconscious Mind | Joseph Murphy | 4.5 out of 5 stars | 13,948 | ₹ 99.00 |
| 1 | Think and Grow Rich | Napoleon Hill | 4.5 out of 5 stars | 16,670 | ₹ 99.00 |
| 2 | Word Power Made Easy | Norman Lewis | 4.4 out of 5 stars | 10,708 | ₹ 130.00 |
| 3 | Mathematics for Class 12 (Set of 2 Vol.) Exami... | R.D. Sharma | 4.5 out of 5 stars | 18 | ₹ 930.00 |
| 4 | The Girl in Room 105 | Chetan Bhagat | 4.3 out of 5 stars | 5,162 | ₹ 149.00 |
| ... | ... | ... | ... | ... | ... |
| 56 | COMBO PACK OF Guide To JAIIB Legal Aspects Pri... | MEC MILLAN | 4.5 out of 5 stars | 114 | ₹ 1,400.00 |
| 57 | Wren & Martin High School English Grammar and ... | Rao N | 4.4 out of 5 stars | 1,613 | ₹ 400.00 |
| 58 | Objective General Knowledge | Sanjiv Kumar | 4.2 out of 5 stars | 742 | ₹ 254.00 |
| 59 | The Rudest Book Ever | Shwetabh Gangwar | 4.6 out of 5 stars | 1,177 | ₹ 194.00 |
| 60 | Sita: Warrior of Mithila (Ram Chandra Series -... | Amish Tripathi | 4.4 out of 5 stars | 3,110 | ₹ 248.00 |
61 rows × 5 columns
Let's do some preprocessing on the Ratings, Customers_Rated, and Price column.
df['Rating'] = df['Rating'].apply(lambda x: x.split()[0])
df['Rating'] = pd.to_numeric(df['Rating'])
df["Price"] = df["Price"].str.replace('₹', '')
df["Price"] = df["Price"].str.replace(',', '')
df['Price'] = df['Price'].apply(lambda x: x.split('.')[0])
df['Price'] = df['Price'].astype(int)
df["Customers_Rated"] = df["Customers_Rated"].str.replace(',', '')
df['Customers_Rated'] = pd.to_numeric(df['Customers_Rated'], errors='ignore')
df.head()
| Book Name | Author | Rating | Customers_Rated | Price | |
|---|---|---|---|---|---|
| 0 | The Power of your Subconscious Mind | Joseph Murphy | 4.5 | 13948 | 99 |
| 1 | Think and Grow Rich | Napoleon Hill | 4.5 | 16670 | 99 |
| 2 | Word Power Made Easy | Norman Lewis | 4.4 | 10708 | 130 |
| 3 | Mathematics for Class 12 (Set of 2 Vol.) Exami... | R.D. Sharma | 4.5 | 18 | 930 |
| 4 | The Girl in Room 105 | Chetan Bhagat | 4.3 | 5162 | 149 |
Let's verify the data types of the DataFrame.
df.dtypes
Book Name object
Author object
Rating float64
Customers_Rated int64
Price int64
dtype: object
Replace the zero values in the DataFrame to NaN.
df.replace(str(0), np.nan, inplace=True)
df.replace(0, np.nan, inplace=True)
count_nan = len(df) - df.count()
count_nan
Book Name 0
Author 6
Rating 0
Customers_Rated 0
Price 1
dtype: int64
From the above output, you can observe that there is a total of six books that do not have an Author Name, while one book does not have a price associated with it. These pieces of information are crucial for an author who wants to sell his or her books and should not neglect to put such information.
Let's drop these NaNs.
df = df.dropna()
Let's find out which authors had the highest-priced book. You will visualize the results for such the top 20 authors.
data = df.sort_values(["Price"], axis=0, ascending=False)[:15]
data
| Book Name | Author | Rating | Customers_Rated | Price | |
|---|---|---|---|---|---|
| 56 | COMBO PACK OF Guide To JAIIB Legal Aspects Pri... | MEC MILLAN | 4.5 | 114 | 1400.0 |
| 98 | Diseases of Ear, Nose and Throat | P L Dhingra | 4.7 | 118 | 1285.0 |
| 3 | Mathematics for Class 12 (Set of 2 Vol.) Exami... | R.D. Sharma | 4.5 | 18 | 930.0 |
| 96 | Madhymik Bhautik Vigyan -12 (Part 1-2) (NCERT ... | Kumar-Mittal | 5.0 | 1 | 765.0 |
| 6 | My First Library: Boxset of 10 Board Books for... | Wonder House Books | 4.5 | 3116 | 750.0 |
| 38 | Indian Polity - For Civil Services and Other S... | M. Laxmikanth | 4.6 | 1210 | 700.0 |
| 42 | A Modern Approach to Verbal & Non-Verbal Reaso... | R.S. Aggarwal | 4.4 | 1822 | 675.0 |
| 27 | The Intelligent Investor (English) Paperback –... | Benjamin Graham | 4.4 | 6201 | 650.0 |
| 99 | Law of CONTRACT & Specific Relief | Dr. Avtar Singh | 4.4 | 23 | 643.0 |
| 49 | All In One ENGLISH CORE CBSE Class 12 2019-20 | Arihant Experts | 4.4 | 493 | 599.0 |
| 72 | The Secret | Rhonda Byrne | 4.5 | 11220 | 556.0 |
| 86 | How to Prepare for Quantitative Aptitude for t... | Arun Sharma | 4.4 | 847 | 537.0 |
| 8 | Quantitative Aptitude for Competitive Examinat... | R S Aggarwal | 4.4 | 4553 | 435.0 |
| 16 | Sapiens: A Brief History of Humankind | Yuval Noah Harari | 4.6 | 14985 | 434.0 |
| 84 | Concept of Physics Part-2 (2019-2020 Session) ... | H.C. Verma | 4.6 | 1807 | 433.0 |
from bokeh.models import ColumnDataSource
from bokeh.transform import dodge
import math
from bokeh.io import curdoc
curdoc().clear()
from bokeh.io import push_notebook, show, output_notebook
from bokeh.layouts import row
from bokeh.plotting import figure
from bokeh.transform import factor_cmap
from bokeh.models import Legend
output_notebook()
p = figure(x_range=data.iloc[:,1], plot_width=800, plot_height=550, title="Authors Highest Priced Book", toolbar_location=None, tools="")
p.vbar(x=data.iloc[:,1], top=data.iloc[:,4], width=0.9)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.xaxis.major_label_orientation = math.pi/2
show(p)
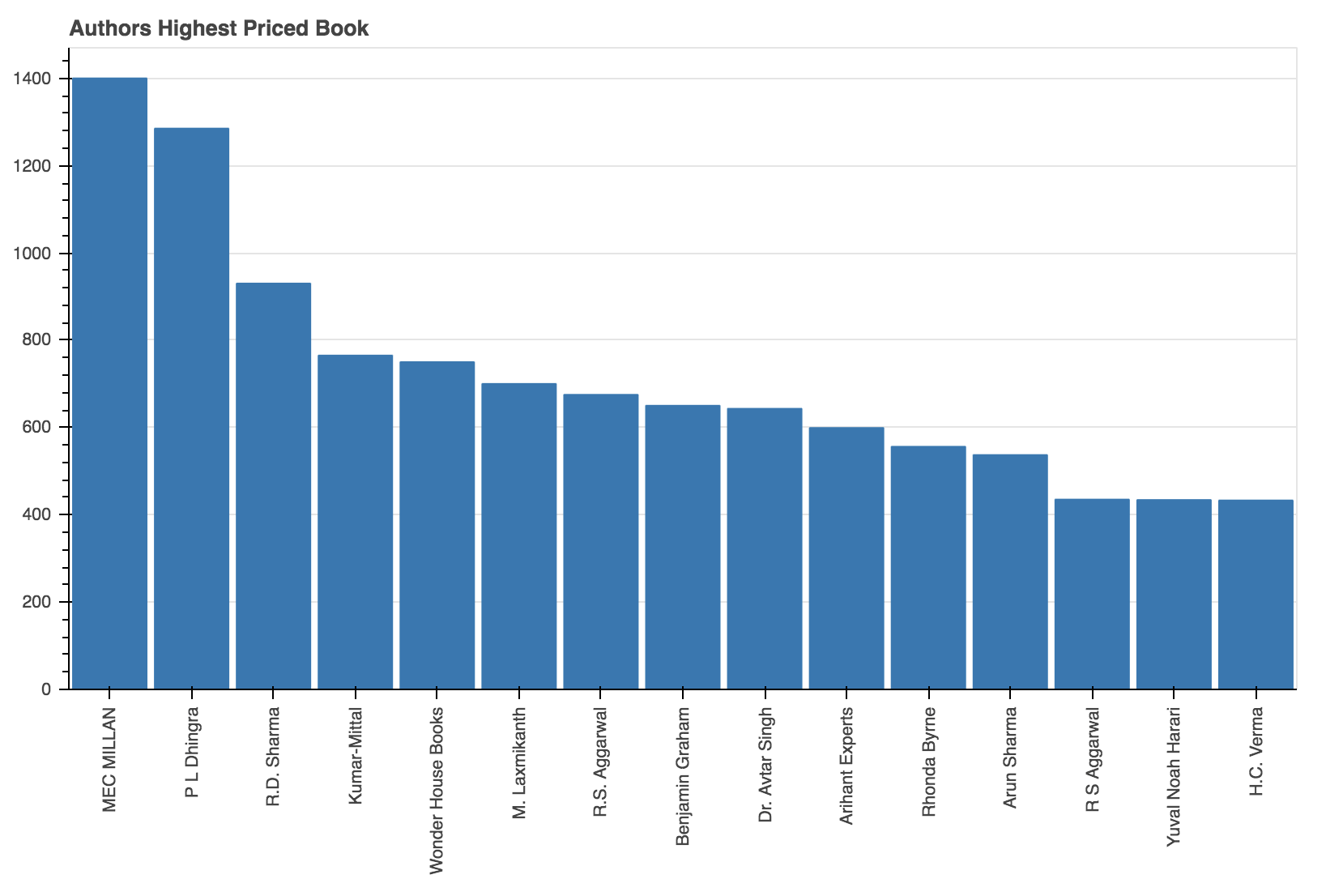
From the above graph, you can observe that the top two highest-priced books are by the author Mecmillan and P L Dhingra.
Let's find out which authors have the top-rated books and which books of those authors are top rated. However, while finding this out, you would filter out those authors in which less than 1000 customers rated.
data = df[df['Customers_Rated'] > 1000]
data = data.sort_values(['Rating'],axis=0, ascending=False)[:15]
data
| Book Name | Author | Rating | Customers_Rated | Price | |
|---|---|---|---|---|---|
| 26 | Inner Engineering: A Yogi’s Guide to Joy | Sadhguru | 4.7 | 4091 | 254.0 |
| 70 | Bhagavad-Gita (Hindi) | A. C. Bhaktivedanta | 4.7 | 1023 | 150.0 |
| 11 | The Alchemist | Paulo Coelho | 4.7 | 22182 | 264.0 |
| 47 | Harry Potter and the Philosopher's Stone | J.K. Rowling | 4.7 | 7737 | 234.0 |
| 84 | Concept of Physics Part-2 (2019-2020 Session) ... | H.C. Verma | 4.6 | 1807 | 433.0 |
| 16 | Sapiens: A Brief History of Humankind | Yuval Noah Harari | 4.6 | 14985 | 434.0 |
| 38 | Indian Polity - For Civil Services and Other S... | M. Laxmikanth | 4.6 | 1210 | 700.0 |
| 29 | Wings of Fire: An Autobiography of Abdul Kalam | Arun Tiwari | 4.6 | 3513 | 301.0 |
| 39 | The Theory of Everything | Stephen Hawking | 4.6 | 2004 | 199.0 |
| 25 | The Immortals of Meluha (Shiva Trilogy) | Amish | 4.6 | 4538 | 248.0 |
| 23 | Life's Amazing Secrets: How to Find Balance an... | Gaur Gopal Das | 4.6 | 3422 | 213.0 |
| 34 | Dear Stranger, I Know How You Feel | Ashish Bagrecha | 4.6 | 1130 | 167.0 |
| 17 | The Monk Who Sold His Ferrari | Robin Sharma | 4.6 | 5877 | 137.0 |
| 13 | How to Win Friends and Influence People | Dale Carnegie | 4.6 | 15377 | 99.0 |
| 59 | The Rudest Book Ever | Shwetabh Gangwar | 4.6 | 1177 | 194.0 |
p = figure(x_range=data.iloc[:,0], plot_width=800, plot_height=600, title="Top Rated Books with more than 1000 Customers Rating", toolbar_location=None, tools="")
p.vbar(x=data.iloc[:,0], top=data.iloc[:,2], width=0.9)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.xaxis.major_label_orientation = math.pi/2
show(p)
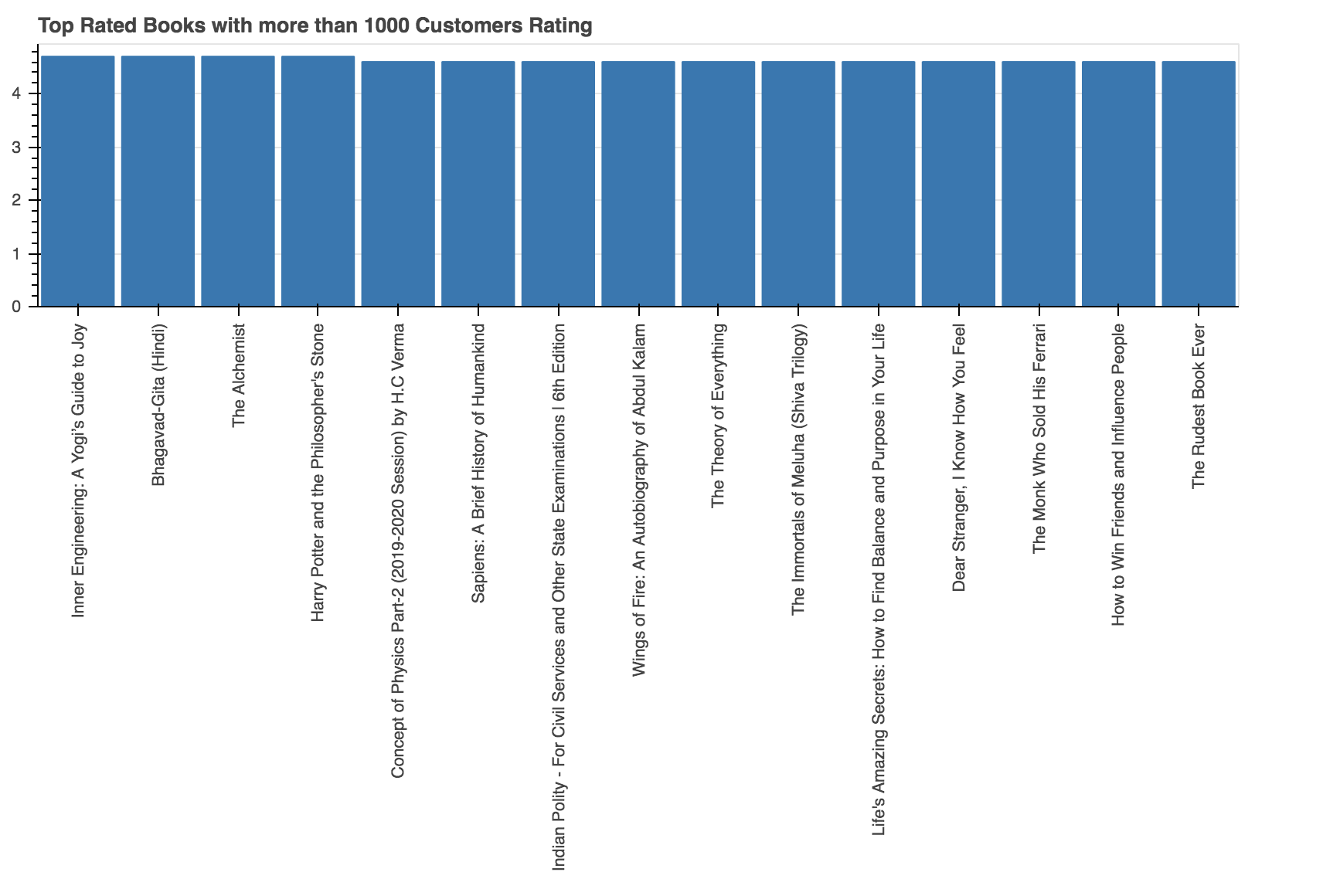
From the above output, you can observe that the top three rated books with more than 1000 customer ratings are Inner Engineering: A Yogi’s Guide to Joy, Bhagavad-Gita (Hindi), and The Alchemist.
p = figure(x_range=data.iloc[:,1], plot_width=800, plot_height=600, title="Top Rated Books with more than 1000 Customers Rating", toolbar_location=None, tools="")
p.vbar(x=data.iloc[:,1], top=data.iloc[:,2], width=0.9)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.xaxis.major_label_orientation = math.pi/2
show(p)
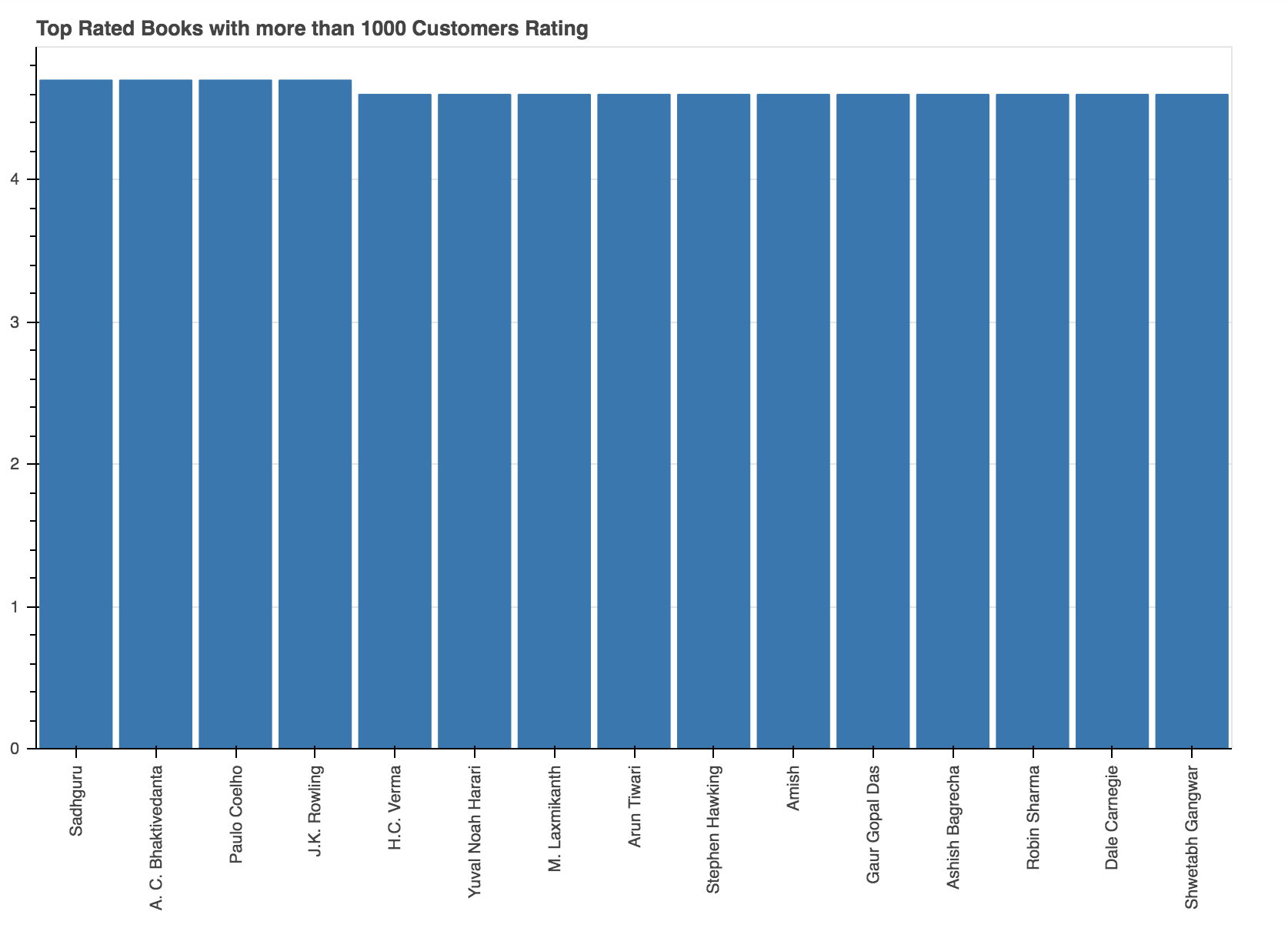
The above graph shows the top 10 authors in descending order who have the highest rated books with more than 1000 customer ratings, which are Sadhguru, A. C. Bhaktivedanta and Paulo Coelho.
While you have already seen the top-rated books and top-rated authors, it would still be more convincing and credible to conclude the best author and the book based on the number of customers who rated for that book.
So, let's quickly find that out.
data = df.sort_values(["Customers_Rated"], axis=0, ascending=False)[:20]
data
| Book Name | Author | Rating | Customers_Rated | Price | |
|---|---|---|---|---|---|
| 11 | The Alchemist | Paulo Coelho | 4.7 | 22182 | 264.0 |
| 1 | Think and Grow Rich | Napoleon Hill | 4.5 | 16670 | 99.0 |
| 13 | How to Win Friends and Influence People | Dale Carnegie | 4.6 | 15377 | 99.0 |
| 16 | Sapiens: A Brief History of Humankind | Yuval Noah Harari | 4.6 | 14985 | 434.0 |
| 18 | Rich Dad Poor Dad : What The Rich Teach Their ... | Robert T. Kiyosaki | 4.5 | 14591 | 296.0 |
| 10 | The Subtle Art of Not Giving a F*ck | Mark Manson | 4.4 | 14418 | 365.0 |
| 0 | The Power of your Subconscious Mind | Joseph Murphy | 4.5 | 13948 | 99.0 |
| 48 | The Power of Your Subconscious Mind | Joseph Murphy | 4.5 | 13948 | 99.0 |
| 72 | The Secret | Rhonda Byrne | 4.5 | 11220 | 556.0 |
| 41 | 1984 | George Orwell | 4.5 | 10829 | 95.0 |
| 2 | Word Power Made Easy | Norman Lewis | 4.4 | 10708 | 130.0 |
| 46 | Man's Search For Meaning: The classic tribute ... | Viktor E Frankl | 4.4 | 8544 | 245.0 |
| 67 | The 7 Habits of Highly Effective People | R. Stephen Covey | 4.3 | 8229 | 397.0 |
| 47 | Harry Potter and the Philosopher's Stone | J.K. Rowling | 4.7 | 7737 | 234.0 |
| 40 | One Indian Girl | Chetan Bhagat | 3.8 | 7128 | 113.0 |
| 65 | Thinking, Fast and Slow (Penguin Press Non-Fic... | Daniel Kahneman | 4.4 | 7087 | 410.0 |
| 27 | The Intelligent Investor (English) Paperback –... | Benjamin Graham | 4.4 | 6201 | 650.0 |
| 17 | The Monk Who Sold His Ferrari | Robin Sharma | 4.6 | 5877 | 137.0 |
| 53 | Ram - Scion of Ikshvaku (Ram Chandra) | Amish Tripathi | 4.2 | 5766 | 262.0 |
| 93 | The Richest Man in Babylon | George S. Clason | 4.5 | 5694 | 129.0 |
from bokeh.transform import factor_cmap
from bokeh.models import Legend
from bokeh.palettes import Dark2_5 as palette
import itertools
from bokeh.palettes import d3
#colors has a list of colors which can be used in plots
colors = itertools.cycle(palette)
palette = d3['Category20'][20]
index_cmap = factor_cmap('Author', palette=palette,
factors=data["Author"])
p = figure(plot_width=700, plot_height=700, title = "Top Authors: Rating vs. Customers Rated")
p.scatter('Rating','Customers_Rated',source=data,fill_alpha=0.6, fill_color=index_cmap,size=20,legend='Author')
p.xaxis.axis_label = 'RATING'
p.yaxis.axis_label = 'CUSTOMERS RATED'
p.legend.location = 'top_left'
BokehDeprecationWarning: 'legend' keyword is deprecated, use explicit 'legend_label', 'legend_field', or 'legend_group' keywords instead
show(p)
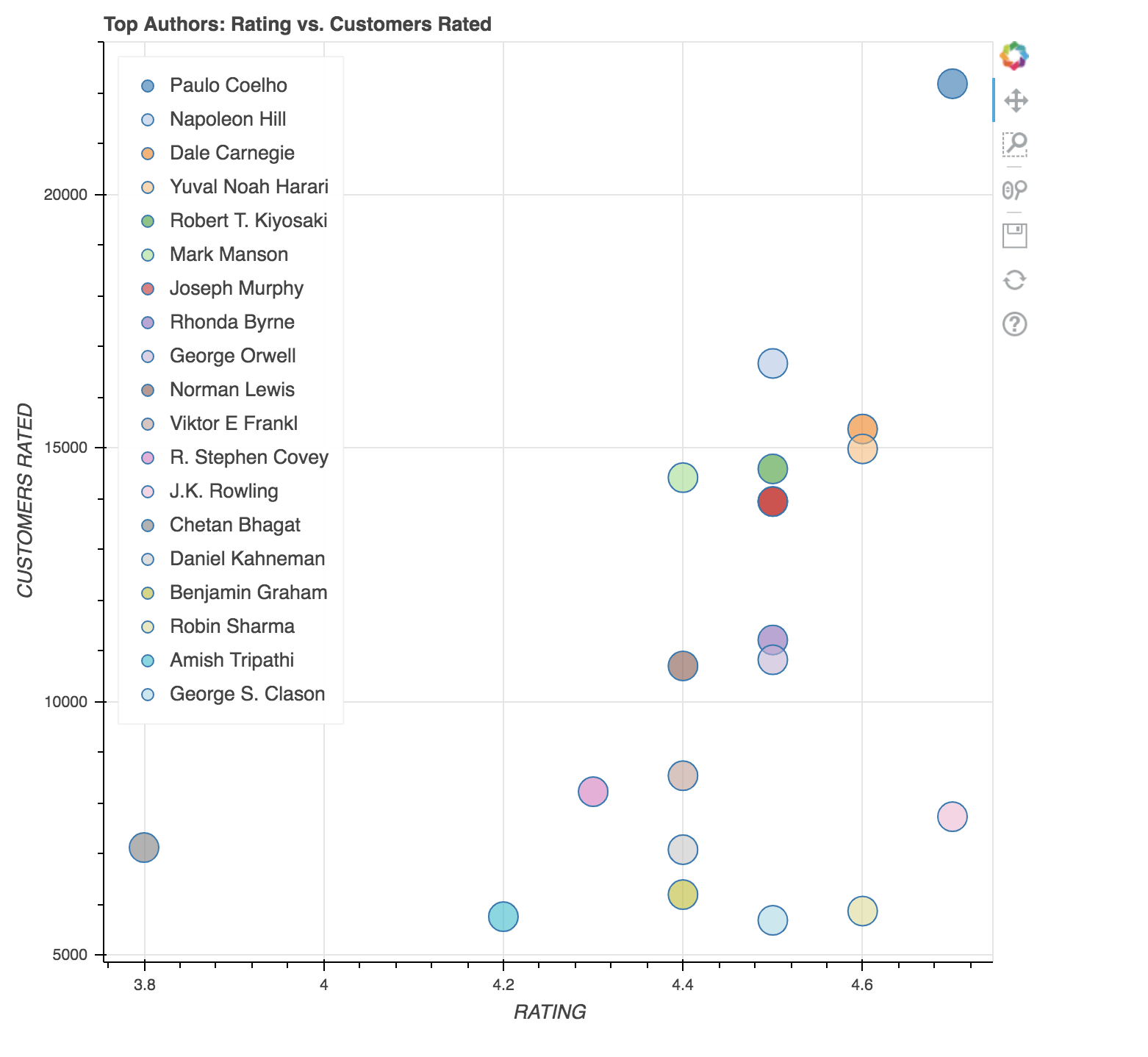
The above graph is a scatter plot of Authors who bagged customer rating vs. actual rating. The following conclusions can be made after looking at the above plot.
Congratulations on finishing the tutorial.
This tutorial was a basic introduction to scraping Amazon with beautiful soup and how you can make sense out of the information extracted by visualizing it using the bokeh plotting library. A good exercise to take a step forward in learning web scraping with beautiful soup is to scrape data from some other websites and see how you can get insights from it. We also have a tutorial on scraping Reddit if you want more guidance on scraping popular websites.
If you are just getting started in Python and would like to learn more, take DataCamp's Introduction to Data Science in Python course.
Learn more about Python
Course
Course
Course
blog
Allan Ouko
10 min
Tutorial
Sicelo Masango
Tutorial
Abhishek Kasireddy
Tutorial
Hugo Bowne-Anderson
Tutorial
Hafsa Jabeen
Tutorial
Matthew Przybyla