
Track
Developing AI Applications
21 hr
Atomicity is a core concept in database systems. It means a transaction must either succeed completely or not run at all. If anything fails halfway, the whole thing is rolled back like it never happened.
Why is this so important, you ask? Imagine transferring money from one bank account to another. You press "Send," the app loads for a second, and then something goes wrong. The money disappears from your account, but never lands in the other one. Now it’s just…gone. That scenario is exactly what atomicity is designed to prevent.
You might have heard of ACID before. It is a set of four key properties that databases use to ensure things don’t fall apart. Atomicity is the first on that list, and for good reason: without it, the rest (Consistency, Isolation and Durability) don’t matter much.
In this article, we’ll explore what atomicity means, how it works, and why it’s so critical in everyday systems like banking and e-commerce. We’ll also look at how different databases implement it, and how you can design atomic systems that can handle things well when they inevitably go wrong.
Atomicity means that a transaction in a database is indivisible. It either runs to completion, with every single step going according to plan, or it doesn’t run at all. There’s no in-between. No half-finished updates, no partial data saved, no weird limbo where some things succeeded and others didn’t.
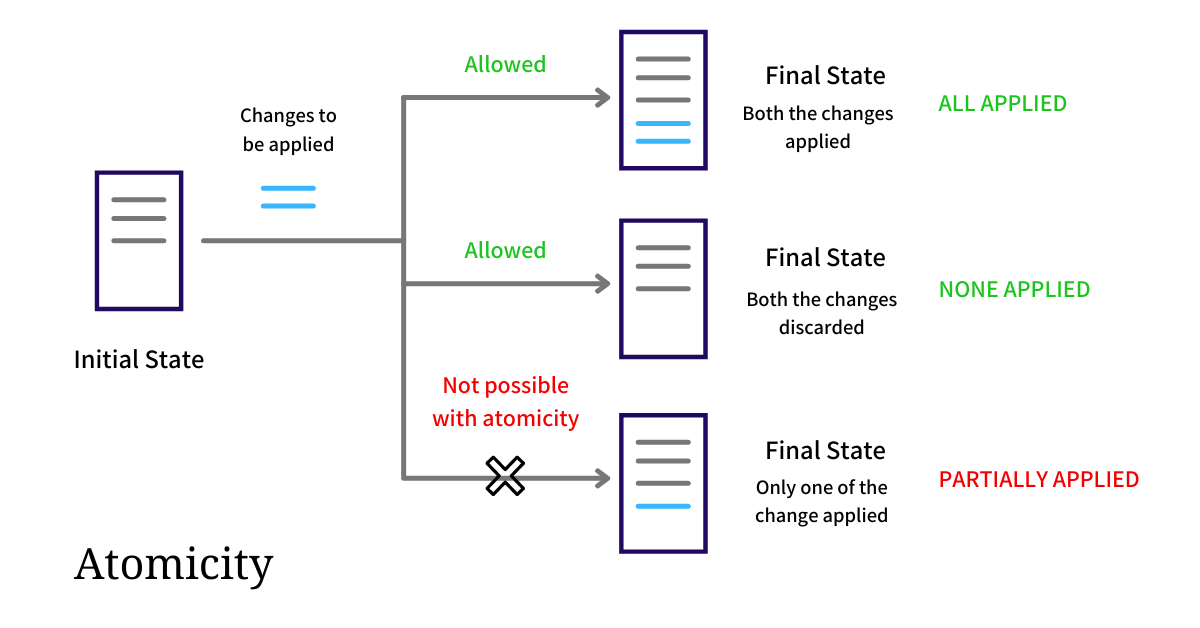
Atomicity in DBMS. Source: Arpit Bhayani
If one part of the transaction fails, the whole thing is rolled back as if nothing ever happened. This is what makes atomicity such a powerful safeguard. Without it, you'd constantly risk leaving your data in a corrupted or inconsistent state, especially in systems where multiple things have to happen in sequence.
Let’s look at a few real-world scenarios where atomicity makes (or breaks) the system:
Let’s say you’re transferring $100 from your checking account to your savings account.
The transaction has two parts:
Without atomicity, it’s possible that step one completes and step two fails, maybe due to a network glitch or server crash. Congratulations, your money just vanished into the void. Atomicity ensures that either both steps succeed, or neither do. If something goes wrong, the $100 stays exactly where it was to begin with.
You’re buying the last limited-edition vinyl record online. The system needs to:
Without atomicity, it might reduce the inventory, but crash before the order is confirmed. Now the store thinks it’s out of stock, but nobody gets the record.
The amount of times that this happens to me when buying something online is astonishing. I usually close the tab and wish their engineers good luck, but I most likely won’t try to purchase from that website in the future. Who knows how they’ll handle my personal details if they can’t ensure their core purchasing functionality is reliable?
Booking a flight is usually more than just selecting a seat. The system needs to:
If step two fails and step three goes through, you’ve paid for a seat that doesn’t exist. Not ideal.
Let’s say your app updates a product’s description in the main database. At the same time, it should update the search index so users can find the product with the new description.
If the database update succeeds but the index update fails, users see out-of-date results, or can’t find the product at all.
So why is atomicity such a big deal?
There are so many reasons a transaction can be interrupted. There could be a power outage, a server crash, or a network timeout halfway through. If atomicity isn’t enforced, that transaction might only be partially completed. Now your database is left in an awkward state: some changes went through, others didn’t, and you’ve got no easy way to undo the mess.
This is where data bugs get really sneaky. Users might not notice anything wrong at first, but over time things stop adding up. Your analytics look weird, orders vanish, accounts don't balance, or support tickets spike because people can’t find what they just saved.
Atomicity prevents all that by ensuring that:
It also ties closely to the other ACID properties. Without atomicity, consistency goes out of the window because you can’t enforce rules if half the data is missing, and isolation breaks, since other users might see partial data from an incomplete transaction.
It’s especially important if you are dealing with:
Behind the simplicity of "all or nothing" lies a surprisingly intricate system. When a database executes a transaction, it’s actively tracking, preparing, and protecting every step.
Here’s a high-level look at what’s going on:
To ensure atomicity, databases write logs of what’s going to happen before it actually happens. These logs are stored separately and act like a backup plan.
If the system crashes mid-transaction, it can refer to the log and roll back any incomplete changes, reapply completed ones safely, and restore the database to a clean, consistent state.
This approach is sometimes called Write-Ahead Logging (WAL) or journaling, and it’s a key piece of crash recovery.
When a transaction fails, the database doesn’t just give up, it carefully undoes the changes. Modified rows are restored to their original state, any locks held by the transaction are released, and logs are used to reverse partial updates.
Now, in the case of a crash, recovery routines kick in at restart time. They replay logs, resolve unfinished transactions, and make sure the database picks up right where it left off, with no weird half-states.
Unsurprisingly, all this comes at a cost. Atomicity introduces:
This is why you need to design large transactions carefully. If you do too much in one go, you might slow down your entire system or run into concurrency issues.
Atomicity is a core concept across all major databases, but the way it’s implemented can vary slightly depending on the underlying storage engine and design philosophy. Let’s take a look at how PostgreSQL and MySQL (InnoDB) make sure transactions work properly.
Before any data is written permanently, PostgreSQL creates a write-ahead log (WAL), the record of every intended change that we talked about earlier. This log is stored safely and used as a recovery plan in case anything goes wrong during the transaction.
When a transaction is committed, PostgreSQL checks the WAL, confirms that all changes are complete and valid, and then finalizes the updates. If something crashes halfway through, the database uses that log to roll back incomplete work.
What’s great is that this all happens automatically behind the scenes. From a developer’s point of view, it’s seamless: you write a transaction, and PostgreSQL guarantees atomicity without you needing to manage any of the complexity.
No changes are visible to other users until the transaction is fully committed. That keeps things consistent and avoids any “half-saved” weirdness in multi-user environments.
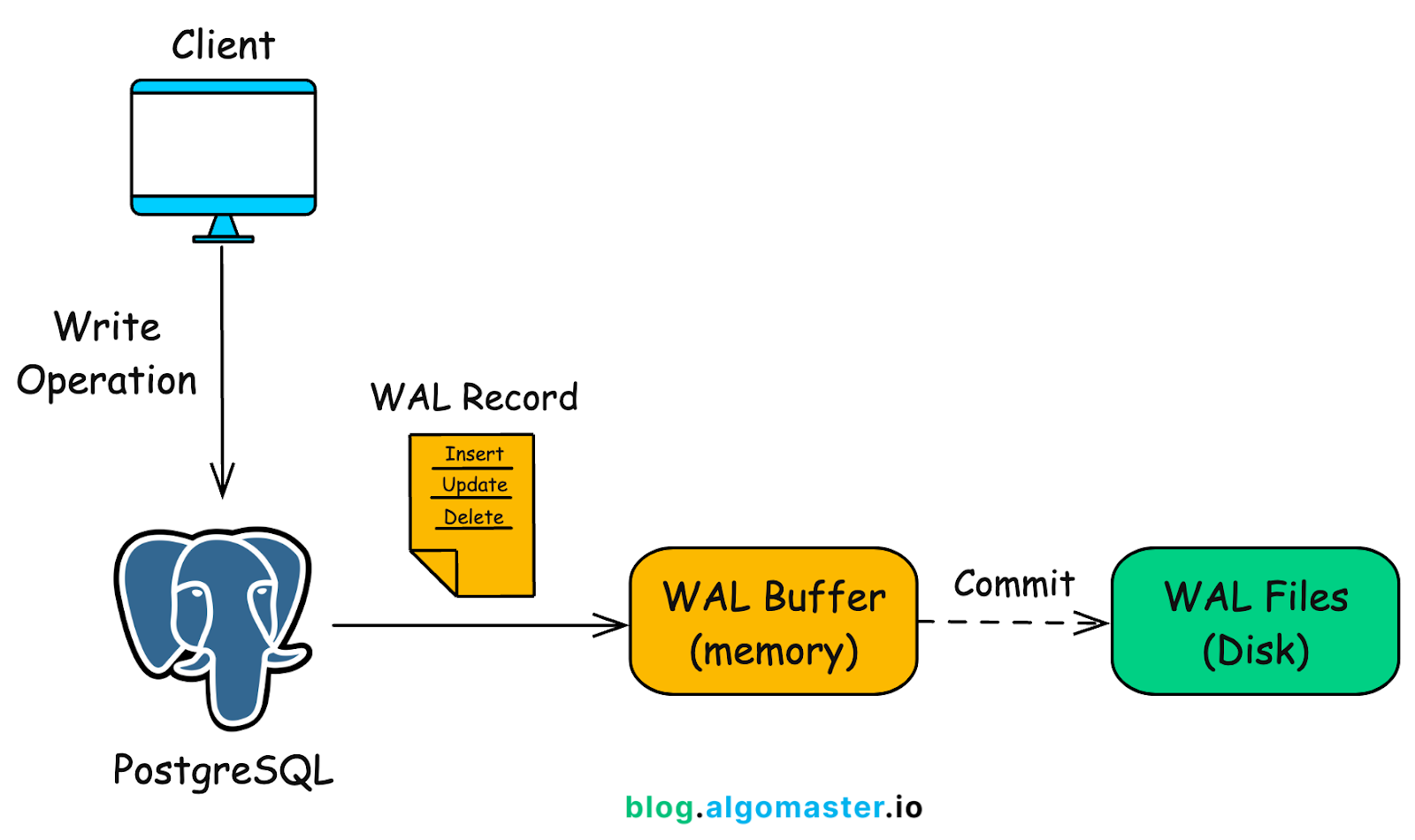
PostgreSQL WAL. Source: AlgoMaster
If you want to get hands-on and create your own databases to test transactions, have a look at our PostgreSQL course.
MySQL’s InnoDB storage engine also supports atomic transactions, and its approach is built for both reliability and performance.
Like PostgreSQL, InnoDB uses a transaction log to keep track of changes before committing them. If something fails, the log is used to roll everything back to the pre-transaction state. This ensures no partial updates sneak through.
One thing InnoDB does particularly well is grouping writes together. This helps reduce disk I/O and improves performance while still protecting atomicity. It also uses undo logs to reverse changes during a rollback and redo logs for crash recovery.
Just like in PostgreSQL, you can rely on the database to handle these mechanisms for you. You don’t have to write any custom rollback code.
There are a few things to keep in mind when working with atomic transactions in your own projects. The overarching idea is to treat atomicity as a default, not a luxury. If you're building systems that modify data in more than one place at a time (which is basically all of them), designing with atomicity in mind will save you time, sanity, and potentially a 3am incident notification.
Not all databases handle atomicity the same way, and not all storage engines are created equal. If atomicity is critical to your use case (e.g., finance, logistics, user state management), make sure your database supports full ACID transactions. That is especially relevant if you’re using MySQL, where storage engine choice matters.
Assume that things will go wrong, because they will. Wrap multi-step operations in transactions and handle errors properly. Be explicit with your BEGIN, COMMIT, and ROLLBACK statements, or use frameworks that handle them safely under the hood.
Most modern ORMs and data access layers offer built-in transaction support. For example:
In Node.js, libraries like Prisma and TypeORM let you wrap logic in a transaction() call that handles commit/rollback behind the scenes.
In Python, SQLAlchemy offers context managers (with session.begin():) that ensure safe commits and rollbacks.
In Java, frameworks like Spring let you annotate methods with @Transactional, so the database handles everything atomically, even across multiple function calls.
These tools make it much easier to build safely by default. They reduce the risk of forgetting a rollback or mismanaging commit logic, especially when your app gets more complex.
Atomicity comes with some overhead, especially in large transactions. Break up massive operations where possible, avoid locking entire tables, and keep transactions short and focused. Long-running transactions increase the risk of contention, deadlocks, and unhappy users.
As we’ve seen before, atomicity doesn’t exist in a vacuum but together with consistency and isolation. Make sure related changes happen together, and consider how concurrent transactions might interact. Use isolation levels that suit your workload without overcomplicating things.
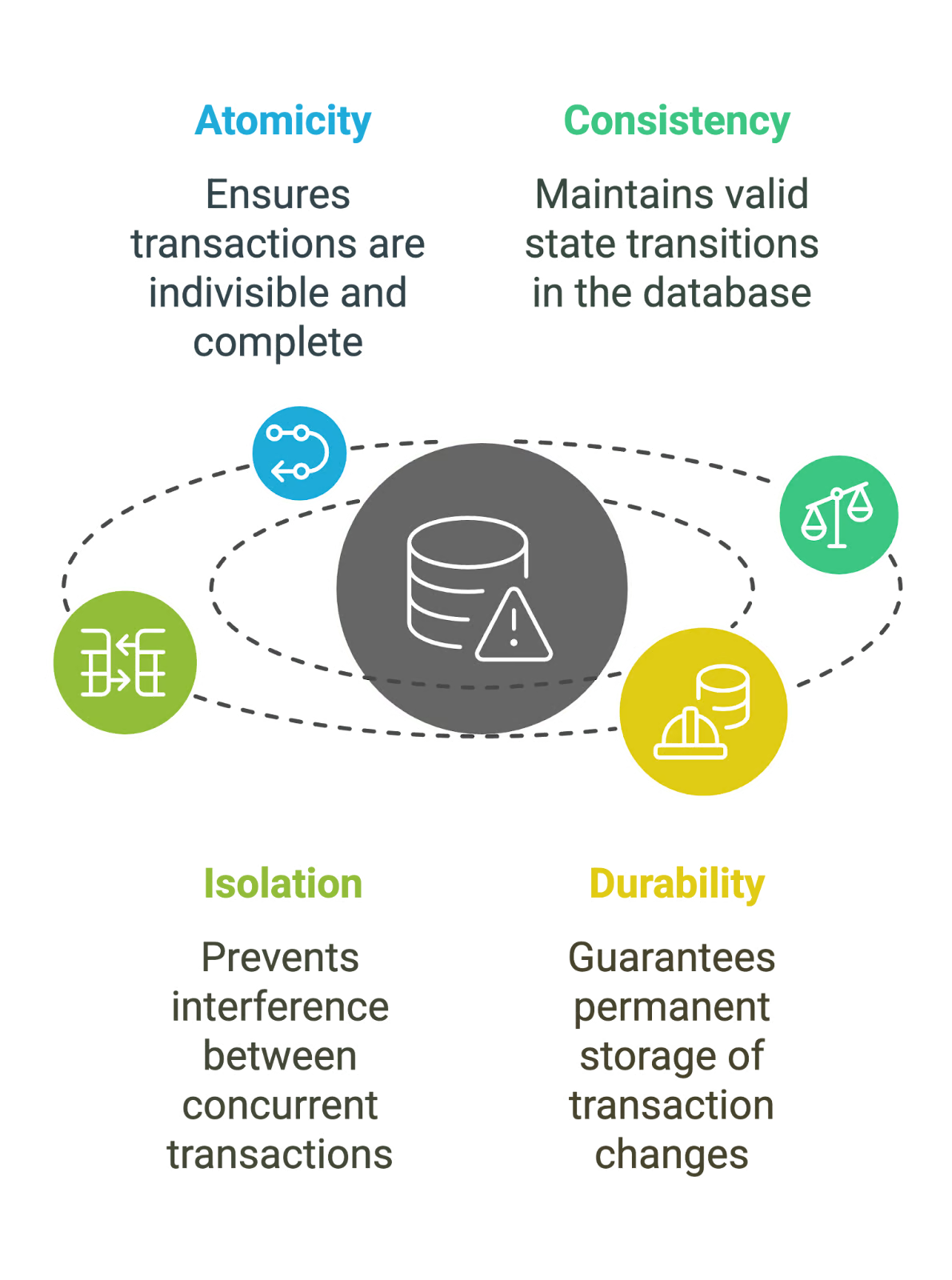
ACID Properties in DBMS. Source: Datacamp
Don't just test your happy paths. Simulate what happens when your app crashes mid-transaction, or when a query times out. You can use failpoints or mock DB failures to see how your system behaves under pressure.
If you’re building systems where multiple things need to happen together, atomicity isn’t optional, it’s essential. Whether you're moving money between accounts, updating inventory, or syncing systems, atomicity ensures your data doesn't end up in a broken or half-finished state.
If you want to go deeper, why not take our Database Design course? You’ll learn to design databases in SQL to process, store, and organize data in a more efficient way.
And if you’re interested in more practical database design articles and tutorials, have a look at our database normalization series:
Learn Data Engineering with DataCamp
Track
Course
Course
blog
Kurtis Pykes
13 min
Tutorial
Oluseye Jeremiah
Tutorial
Marie Fayard
Tutorial
François Aubry
Tutorial
Allan Ouko
code-along
Adel Nehme
