Track
Associate Data Engineer in SQL
30 hr
Imagine a customer calling, confused because their money was deducted but never credited to the recipient, or an order went through without updating the inventory. These problems happen when data integrity isn’t enforced. That’s where ACID principles come in.
ACID principles are enforced to ensure every transaction is processed reliably, keeping data safe and systems running smoothly. Understanding these principles is key to building reliable and fault-tolerant systems.
In this guide, you'll learn:
Let’s get into it!
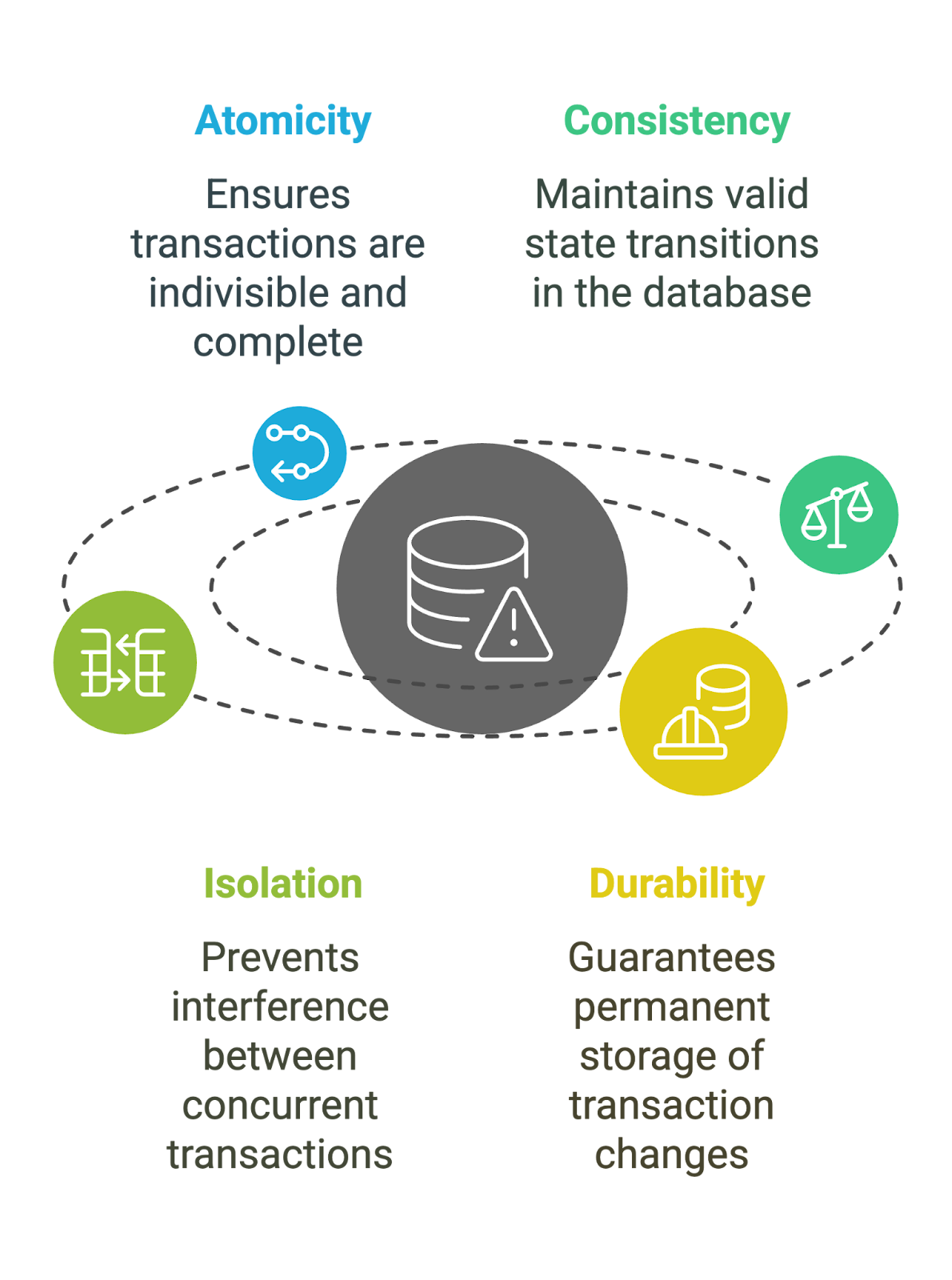
ACID transactions refer to four properties that ensure the reliable processing of database transactions. The four principles are:
These principles guarantee that transactions are executed fully, without partial updates or data corruption, even in the case of system failures. ACID transactions are critical in scenarios where data integrity is paramount.
In banking transactions, ACID guarantees that money is either fully transferred or not at all, preventing issues like partial transfers or double deductions. In e-commerce, ACID principles ensure customer orders are processed correctly, payments are completed, and inventory updates reflect real-time stock levels. Similarly, in inventory management systems, ACID maintains consistency by preventing stock discrepancies due to concurrent transactions.
Each of the four properties that comprise the ACID principles addresses a specific transaction management aspect.
Let's explore these properties to understand how they contribute to robust database systems.
Atomicity guarantees that a transaction is treated as a single, indivisible unit. This means that all operations within a transaction must either be completed fully or not at all. If any part of the transaction fails, the system rolls back the entire transaction, ensuring no partial updates occur.
Example: In a banking transaction, atomicity ensures that both operations are completed successfully when money is debited from one account and credited to another. If either the debit or credit fails, the transaction is entirely reversed.
Consistency ensures that a transaction brings the database from one valid state to another while adhering to predefined rules or constraints. After completing a transaction, the data must meet all the database's integrity rules.
Example: In banking, consistency ensures that the total balance across all accounts remains unchanged after a transfer. For example, if $100 is transferred between accounts, the sum of both account balances remains the same to preserve the accounting rules.
Isolation prevents transactions from interfering with each other. When multiple transactions are executed simultaneously, isolation ensures they don't affect each other’s outcomes. Each transaction must be isolated to avoid conflicts – especially in high-concurrency environments.
Example: If two customers attempt to purchase the last item in stock at the same time, isolation ensures that only one transaction will succeed, and the inventory is updated correctly to reflect the change.
Durability guarantees that once a transaction is completed, its changes are permanently stored in the database (even if the system crashes immediately afterward). This ensures that the data remains intact and accessible after failures.
Example: In an e-commerce system, durability ensures that the order data is saved to the database after a customer completes a purchase. Even if the server crashes moments later, the purchase record remains intact and can be retrieved when the system is restored.
ACID properties. Image by Author
Most relational databases are built with ACID principles at their core. This means they are designed to maintain data accuracy and reliability.
In this section, let’s explore how databases implement ACID properties.
For those new to relational databases, this Introduction to Relational Databases in SQL course is perfect for building a strong foundation.
Traditional SQL databases enforce ACID properties through transaction control mechanisms such as SQL commands like BEGIN, COMMIT, and ROLLBACK. These commands manage transactions, while transaction logs and locks ensure data integrity.
For example:
ROLLBACK in case of errors, preventing partial updates.Most SQL databases come with built-in ACID compliance to maintain transactional integrity. Systems like MySQL, PostgreSQL, Oracle, and Microsoft SQL Server use transaction logs (e.g., Write-Ahead Logging in PostgreSQL) and locking protocols (e.g., two-phase locking) to enforce ACID properties. These mechanisms help preserve data integrity for each transaction.
More specifically:
Working with SQL Server? This course on Transactions and Error Handling in SQL Server is a great way to master transaction control and ensure data integrity.
Here’s a simple SQL example of a transaction in PostgreSQL that adheres to ACID principles.
This example demonstrates transferring money between two accounts to ensure that the transaction either fully completes or fully rolls back in case of failure:
BEGIN;
-- Step 1: Debit $500 from Account A
UPDATE accounts
SET balance = balance - 500
WHERE account_id = 'A';
-- Step 2: Credit $500 to Account B
UPDATE accounts
SET balance = balance + 500
WHERE account_id = 'B';
-- Commit the transaction if both steps succeed
COMMIT;
-- Rollback the transaction if an error occurs
ROLLBACK;In this transaction:
If you're just getting started with SQL, this Introduction to SQL course will help you grasp the fundamentals and start writing queries with confidence.
Learn more about data engineering and databases with these courses!
Track
Course
Course
blog
Allan Ouko
13 min
blog
Mike Shakhomirov
11 min
Tutorial
Oluseye Jeremiah
Tutorial
Marie Fayard
Tutorial
Francisco Javier Carrera Arias
code-along
Adel Nehme