
Track
AI Fundamentals
10 hr
This allows:
So, now you’re not waiting for one word at a time, but you see an entire, refined result instantly. This makes Gemini Diffusion one of the fastest models in terms of sampling speed released by Google for real-time generation tasks. Here are a few benchmarks at which this model excels in producing such amazing results.
At the time of writing, Gemini Diffusion is available as an experimental demo for invited users only. It runs entirely in-browser and supports text, code, canvas, and audio interactions (via built-in MIDI sound generation).
To get started:
No SDKs or APIs required!
Let’s look at what Gemini Diffusion can do across multiple domains, from game development and drawing to code editing and even audio.
Within the playground, I tested the model’s ability to generate long-form content with the following prompt.
Prompt: Explain the merits of toast in the style of Hegel. Then, translate the essay into 10 other languages.
The model returned over 7000 tokens in under 9 seconds, with clear headings, commentary, and text in 10 languages.
As an ML professional, I wanted to test Gemini Diffusion’s ability to generate and execute Python-based machine learning code. So, I asked it to:
Prompt: Write a simple neural network using NumPy and run it.
Gemini returned a complete, well-structured feedforward neural network implementation using only NumPy, including activation function, weight initialization, backpropagation logic, and training loop. It even included explanations for each step.
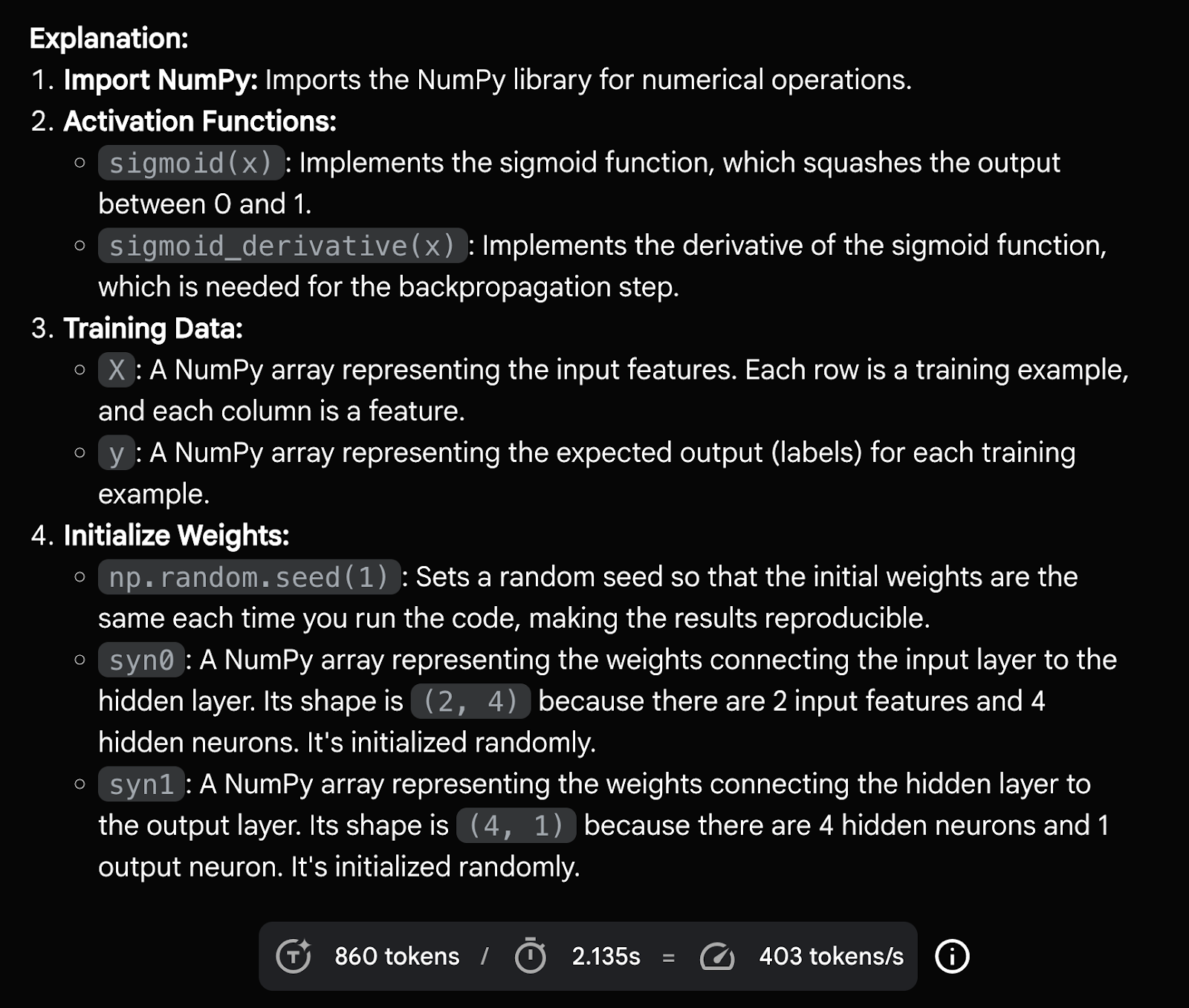
To test runtime capabilities, I followed up with:
Prompt: Can you run this for me?
Gemini responded that it cannot execute Python code natively, as it lacks an integrated runtime environment. However, it simulated the expected output by estimating the loss at various training intervals, demonstrating what a typical output would look like if run in a local environment like Jupyter Notebook.
While Gemini Diffusion can’t yet run code in-browser, this capability to simulate output behavior and provide expected results is still highly valuable for prototyping. If runtime integration is added in the future, it could transform the tool into a fully self-contained playground for learning and experimenting with machine learning models.
Next, I experimented with something more playful, i.e., an interactive drawing app featuring brushes, colors, and shapes. I began with a basic prompt:
Prompt: Make me a drawing app with multiple brushes and colors.
Gemini responded with a canvas-based sketchpad, including a base color palette, brush size selectors (small, medium, large), and a clear button.
Building on this, I asked the model to add a “pink” color option to the palette, which it integrated seamlessly. I then requested additional drawing tools—rectangle, square, and circle—and Gemini Diffusion delivered those as selectable shape options.
The final output matched all my prompts and worked well as a creative tool. The only noticeable drawback was some lag and reduced smoothness during drawing interactions, likely due to the limitations of running in preview mode. But overall, it was impressively functional for a real-time in-browser prototype.
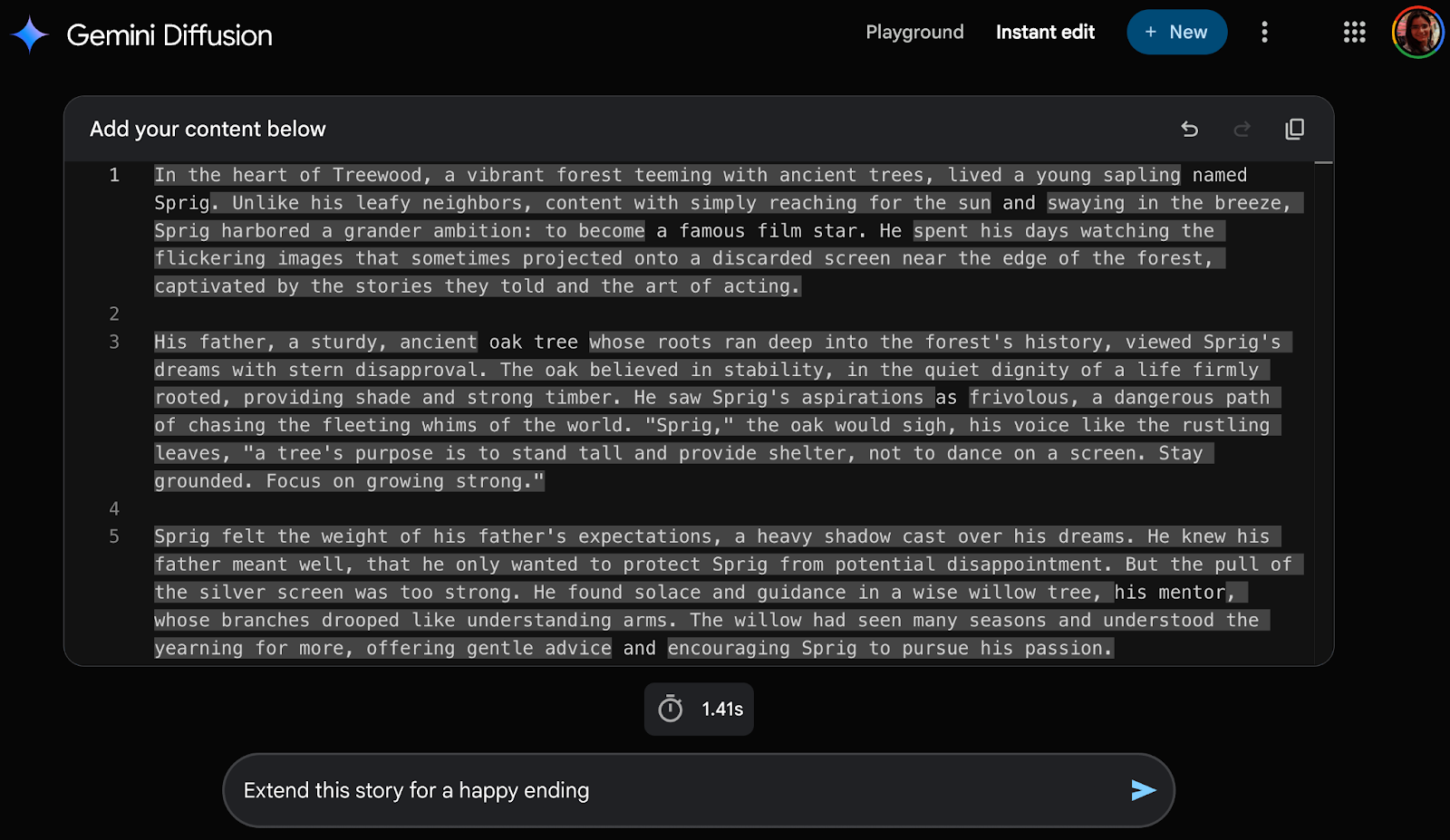
This tool is also great for writing and editing stories. Using Instant Edit, I gave the model a single-line story and asked it to extend it.
Content textbox: Write a story about a happy tree named Sprig who lives in Treewood and dreams of becoming a famous film star.
To deepen the narrative, I then asked the model to add dramatic tension by introducing a disapproving father figure.
Prompt: Add drama to this story by adding a father character who is unhappy with Sprig’s career choice.
The model responded by expanding the story inline, seamlessly weaving in a wise but stern oak tree father who disapproved of Sprig’s theatrical dreams. The edits were highlighted with visual toggles, allowing me to compare the original and updated content.
This example demonstrated how Instant Edit can support incremental storytelling and controlled creative refinement, all while keeping the user in the loop.
For my final test, I prompted Gemini Diffusion to create an interactive xylophone app. The model generated a colorful, well-laid-out set of keys with corresponding sound mappings, event listeners, and hover effects, showcasing its ability to handle interactive audio UIs.
Prompt: Generate a xylophone app where the user can press the keys and it generates sounds. Each note lasts a reasonable time after pressing. Do not use any external assets. Use built-in MIDI sound generation. Lay out the keys as in a real xylophone.
Note: Even though Gemini Diffusion doesn’t support audio or video generation, it was able to simulate realistic audio behavior using MIDI-style tone synthesis within the browser preview.
This highlights the model’s ability to build functional audio interfaces without requiring any external assets or libraries.
I recommend turning on the sound for the video below:
Learn AI with these courses!
Track
Track
Course
blog
Alex Olteanu
8 min
Tutorial
François Aubry
Tutorial
François Aubry
Tutorial
Abid Ali Awan
Tutorial
François Aubry
Tutorial
François Aubry