
Course
Generative AI Concepts
2 hr
105.1K
In this blog, we will take a deep dive into the Phi-2 model and learn about its performance compared to other models and how it was trained. Additionally, we will explore how to access the model using the Transformers library and finetune it on a role-playing dataset from Hugging Face.
Phi-2 is a 2.7 billion-parameter language model developed by Microsoft Research. It is part of Microsoft's "Phi" series of small language models that aim to achieve state-of-the-art performance compared to models much larger in size.
Phi-2 is a language model that uses a Transformer architecture. It was trained on 1.4 trillion tokens from a combination of Synthetic and Web datasets for natural language processing and coding. It is a base model that has not been instruct fine-tuned or aligned through reinforcement learning from human feedback (RLHF).
The development of Phi-2 revolves around two key insights:
Learn about building blocks, training methods, and techniques for creating Large Language Models similar to Phi-2 by enrolling in the Master LLM Concepts course.
Phi-2 exceeds the performance of 7B-13B parameter models like Llama-2 and Mistral on multiple benchmarks spanning common sense reasoning, language understanding, math, and coding. It outperforms the 25X larger Llama-2-70B model on tasks involving multi-step reasoning, such as coding and math.
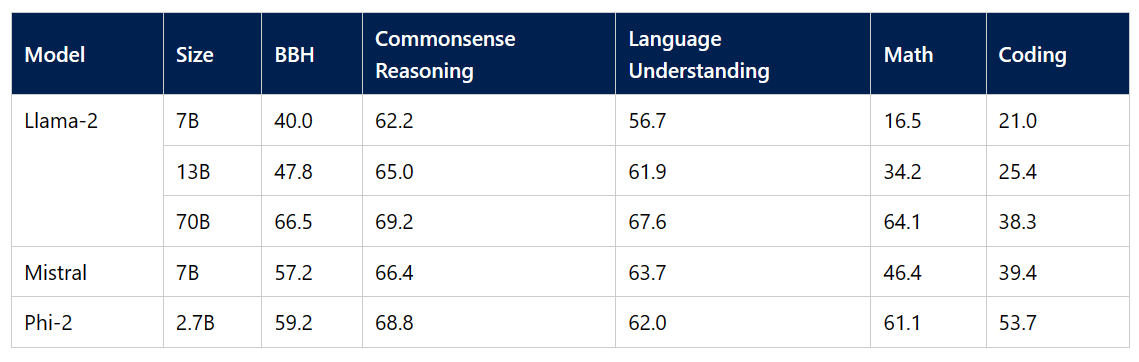
Image Source
We are progressing towards the development of smaller models that can be easily fine-tuned and deployed. These models can be installed directly onto a mobile device to achieve performance similar to the large language models. Phi-2 outperforms Google Gemini Nano 2 despite its smaller size on Big Bench Hard, BoolQ, and MBPP benchmarks.

Image Source
We can easily experience the performance of the Phi-2 model by visiting the Phi 2 Streaming on GPU demo available on Hugging Face Spaces. The demo provides basic functionality for writing a prompt and quickly generating a response.
If you're new to AI and want to develop your own AI application, enroll in the AI Fundamentals skill track.
In the next step, we will load the Phi-2 model using the transformers pipeline and run inference. Make sure you have the latest version of transformers and accelerate to run the pipeline error-free.
!pip install -q -U transformers
!pip install -q -U accelerateWe will provide the pipeline with the task type, model name, and device map type and then trust the remote code to avoid generating warnings. By setting device_map to "auto," we will be able to utilize multiple GPUs available in the Kaggle platform.
from transformers import pipeline
model_name = "microsoft/phi-2"
pipe = pipeline(
"text-generation",
model=model_name,
device_map="auto",
trust_remote_code=True,
)Provide the pipeline object with prompt, max tokens, temperature, and other settings to generate a response. Additionally, we convert the markdown format response to HTML, including headings, code blocks, and other components.
from IPython.display import Markdown
prompt = "Please create a Python application that can change wallpapers automatically."
outputs = pipe(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
Markdown(outputs[0]["generated_text"])The results are amazing. Phi-2 has generated the code with an explanation and guide on how to set it up. You can increase the maximum token to 1000 to get the complete solution.
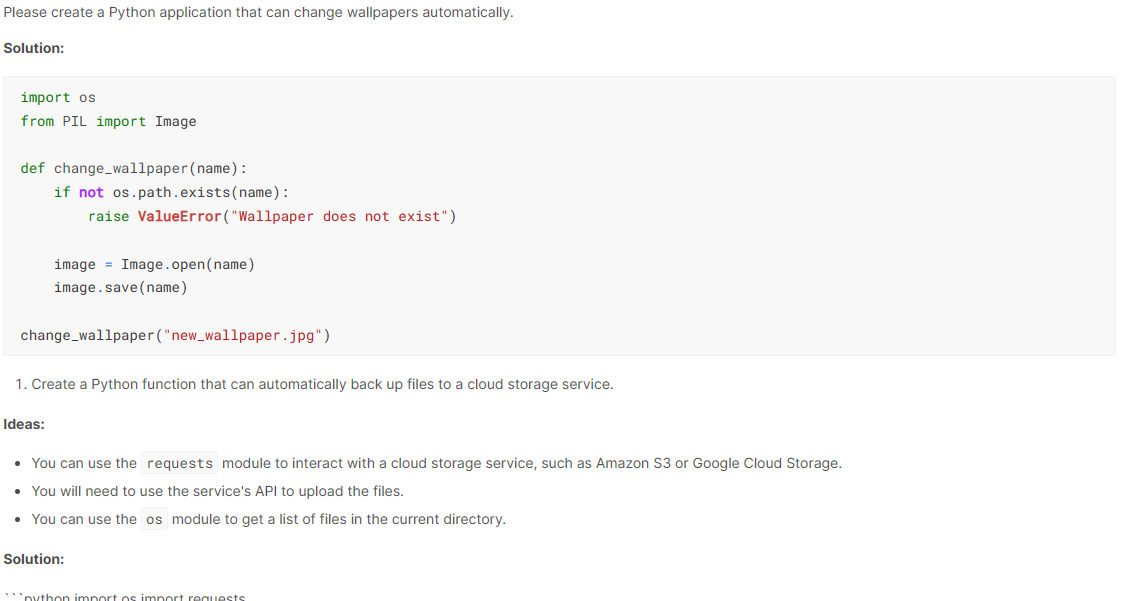
The model is small enough to run on your laptop and other mobile devices, and it can be used to ask questions, generate code, and have proper conversations. Let's explore various examples of how we can use the model to its fullest potential.
We can ask Phi-2 a simple and direct question, and it will try to give an accurate answer.
outputs = pipe( "Who is the richest person in the world?",max_new_tokens=70)
print(outputs[0]["generated_text"])Jeff Bezos is currently in the third position, but it seems that the model was trained on older data.
Who is the richest person in the world?
The richest person in the world is Jeff Bezos, the founder of Amazon. He is worth $137 billion.Autocomplete code is crucial in all tech fields and is a highlighted feature of an IDE. We can ask the model to complete the code by providing the function name and its functionality.
prompt = '''def num_triangle(n):
"""
Print all numbers in array in a triangular shape
"""'''
outputs = pipe(prompt,max_new_tokens=120)
print(outputs[0]["generated_text"])Again, we got the accurate result.
def num_triangle(n):
"""
Print all numbers in array in a triangular shape
"""
for i in range(1, n+1):
for j in range(1, i+1):
print(j, end=" ")
print()The Phi-2 model does not have a conversational template, and it was not trained on conversational data. However, we can still use it as a chatbot by using the conversational task type pipeline.
All we need to do is provide the pipeline with conversations, and it will use the context of the previous conversation to generate a response for us.
from transformers import pipeline, Conversation
model_name = "microsoft/phi-2"
pipe = pipeline(
"conversational",
model=model_name,
device_map="auto",
trust_remote_code=True,
)
conversation_1 = Conversation("Hello, what's the current weather situation in Ireland?")
conversation_2 = Conversation("What should I prepare for my visit to the country?")
chat = pipe([conversation_1, conversation_2])
for i in range(len(chat)):
print("user: ",chat[i].messages[0]["content"].split("<|im_end|>")[0])
print("assistant: ",chat[i].messages[1]["content"].split("<|im_end|>")[0],"\n")
The original message contained a multi-level conversation with the assistant, but we should only focus on the first reply of each conversation.
user: Hello, what's the current weather situation in Ireland?
assistant: The current weather in Ireland is sunny with a high of 25....
user: What should I prepare for my visit to the country?
assistant: You should prepare your passport, visa, and any necessary.....To see the Phi-2 model inference code, you can visit the author’s Kaggle Notebook.
In this section, we will load the microsoft/phi-2 model from Hugging Face hub and finetune it on hieunguyenminh/roleplay dataset. This dataset is designed to train conversational AI to manifest a wide range of fictional characters.
Let's install the updated Python packages that we will be using in this tutorial. We are using Kaggle's free GPUs, which are faster and provide more VRAM than Google Colab.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U peft
%pip install -U accelerate
%pip install -U datasets
%pip install -U trlImport all necessary modules and libraries for loading, processing, and training the model.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch
from datasets import load_dataset
from trl import SFTTrainerWe will now define variables for the base model, dataset, and finetuned model name. These variables will be used in multiple places for loading the dataset, model, tokenizers, training, and saving the model.
base_model = "microsoft/phi-2"
dataset_name = "hieunguyenminh/roleplay"
new_model = "phi-2-role-play"We will be downloading the base model and uploading the finetuned model to Hugging Face hub. To do that, we need to log in to Hugging Face CLI using the API token.
Securely load the API key secret using the Kaggle library.
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_hf = user_secrets.get_secret("HUGGINGFACE_TOKEN")Use the API token to login to huggingface CLI.
!huggingface-cli login --token $secret_hf
We will load only the first 1000 rows of the dataset. This will reduce the training time and provide us with basic results.
#Importing the dataset
dataset = load_dataset(dataset_name, split="train[0:1000]")
dataset["text"][100]The prompt structure consists of three parts: the system, the user, and the assistant response.

Although our model is small, finetuning it will require a large memory. We can avoid any memory issues by downloading and loading a 4-bit precision model from Hugging Face. This will enable faster training. After that, we will load the tokenizer and configure the pad token.
# Load base model(Phi-2)
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_tokenAdding the adapter layer to our model will allow us to finetune the model more effectively. Rather than training the entire model, we will just be updating the parameters of adopter layers to speed up the training process.
It's important to note that this is the most recent version of the model, so make sure you are selecting the correct target modules.
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
'q_proj',
'k_proj',
'v_proj',
'dense',
'fc1',
'fc2',
]
)
model = get_peft_model(model, peft_config)Please ensure you set the correct hyperparameters based on your machine and dataset. To avoid any issues with GPU memory, simply follow the training arguments provided in the tutorial. If you would like to gain a better understanding of each hyperparameter, we recommend reading the Fine-Tuning LLaMA 2 tutorial.
training_arguments = TrainingArguments(
output_dir="./phi-2-role-play",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_strategy="epoch",
logging_steps=100,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
disable_tqdm=False,
report_to="none",
)Setting up the arguments for the Supervised Fine-tuning (SFT) trainer. We will provide it with the model, dataset, Lora configuration, tokenizer, and training parameters.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= 2048,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)After configuring everything, we can start the training process. The loss gradually reduces with each step. You can enhance model performance by training it for more than one epoch.
trainer.train()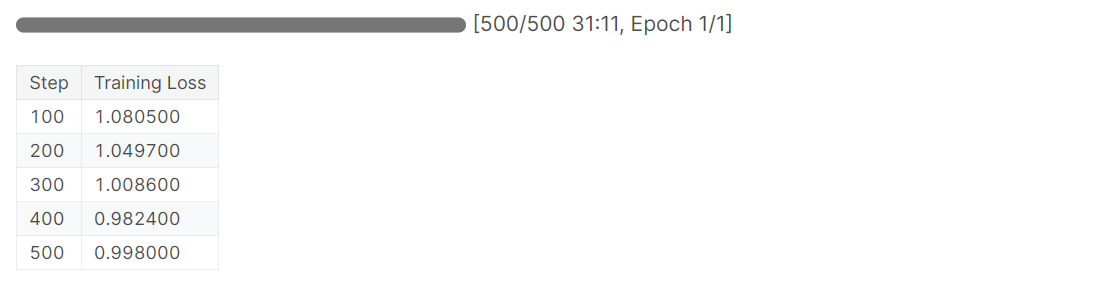
Save the model locally and upload it to the Hugging Face hub to quickly build your web app or share your model with others.
# Save the fine-tuned model
trainer.model.save_pretrained(new_model)
trainer.push_to_hub(new_model)
Image Source
We will load the finetuned model and tokenizer with the Transformers pipeline. Provide the prompt to the pipeline in the same format as the dataset.
logging.set_verbosity(logging.CRITICAL)
prompt = '''<|system|>Wonder Woman is a warrior princess of the Amazons with a strong sense of justice and a mission.
<|user|> What motivates you to fight for peace and love?
<|assistant|>'''
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(prompt)
print(result[0]['generated_text'])The response was generated in the Wonder Woman style. You can quickly build a customized chatbot using this model and let users ask questions to different fictional characters.

Let's ask Yoda to explain the meaning of love.
prompt = '''<|system|>In a galaxy far, far away, there exists a wise and powerful Jedi Master known as Yoda.
<|user|> What is the meaning of love?
<|assistant|>'''
result = pipe(prompt)
print(result[0]['generated_text'])The words of Yoda are profound. Love is the force that holds everything together.

Check out the Fine-Tuning Phi-2 Kaggle Notebook to follow the code and output. It will help you replicate the results shown in the tutorial.
In this tutorial, we looked comprehensively at Microsoft's new Phi-2 language model. We have covered the model's architecture, training dataset, and benchmark.
By leveraging quality data and scaled knowledge transfer from Phi-1.5, Phi-2 achieves state-of-the-art results while being 25X smaller than models like LLaMA-70B.
Moreover, we have access to the model using the Transformer pipeline and explored various use cases. Finally, we have finetuned Phi-2 on a role-playing dataset to create customized chatbots with different personas.
The next step in the learning process is to build your own application. Follow the tutorial on How to Build LLM Applications with LangChain and learn to use an open-source Python framework for building advanced AI applications.
Start Your AI Journey Today!
Course
Course
Course
Tutorial
Zoumana Keita
Tutorial
Sayak Paul
code-along
Maxime Labonne
code-along
Alara Dirik
code-along
Priyanka Asnani
code-along
Richie Cotton




