
Track
Natural Language Processing in Python
20 hr
In today's rapidly changing tech world, Artificial Intelligence stands out as a crucial and ever-present field, effortlessly weaving its way into our everyday experiences. Central to this AI wave is Natural Language Processing, a sophisticated area powering popular conversational tools such as ChatGPT and Bard.
What if most of the models that make these tools possible are open to everyone and all in a single place?
Enter: Hugging Face, a game-changer in machine learning and natural language processing and a key agent in the democratization of AI. Thanks to transfer learning, it is playing a crucial role in making AI more accessible.
As of today, it boasts the most popular NLP library in Python, with over 115k stars on GitHub, and it has emerged as one of the pivotal platforms for AI enthusiasts and professionals to experiment, deploy, and scale their own models.
Whether you're a data pro or just a curious beginner, Hugging Face has the tools and resources to bring your AI projects to life, pushing the boundaries of what's possible with machine learning.
So, let’s discover what Hugging Face has to offer!
You can also learn more about Using Open Source AI Models with Hugging Face with our code-along.
To most people, Hugging Face might just be another emoji available on their phone keyboard (🤗)
However, in the tech scene, it's the GitHub of the ML world — a collaborative platform brimming with tools that empower anyone to create, train, and deploy NLP and ML models using open-source code.
The revolutionary twist?
These models come already pre-trained, which further simplifies the process of crushing into NLP. To put it simply, developers don’t start from scratch anymore; they now simply load a pre-trained model from the Hugging Face hub, fine-tune it to their specific tasks, and start from there.
This ease of use greatly simplifies the development process.
Thus, Hugging Face is a hub where data scientists, researchers, and ML engineers converge to exchange ideas, seek support, and contribute to open-source initiatives.
They describe themselves as:
“The AI community for building the future.”
This vision is precisely one of the secret ingredients of Hugging Face’s success: having a community-driven approach.
Another reason for its stark growth is the platform's intuitiveness. Providing a simple interface makes it easy to get started - for both newbies and pros.
With an aim to host the largest NLP and ML collection of resources, Hugging Face is committed to democratizing AI and making it accessible to a global community.
Founded in 2016, Hugging Face was an American-French company aiming to develop an interactive AI chatbot targeted at teenagers. However, after open-sourcing the model powering this chatbot, it quickly pivoted to a grander vision: to arm the AI industry with powerful, accessible tools.
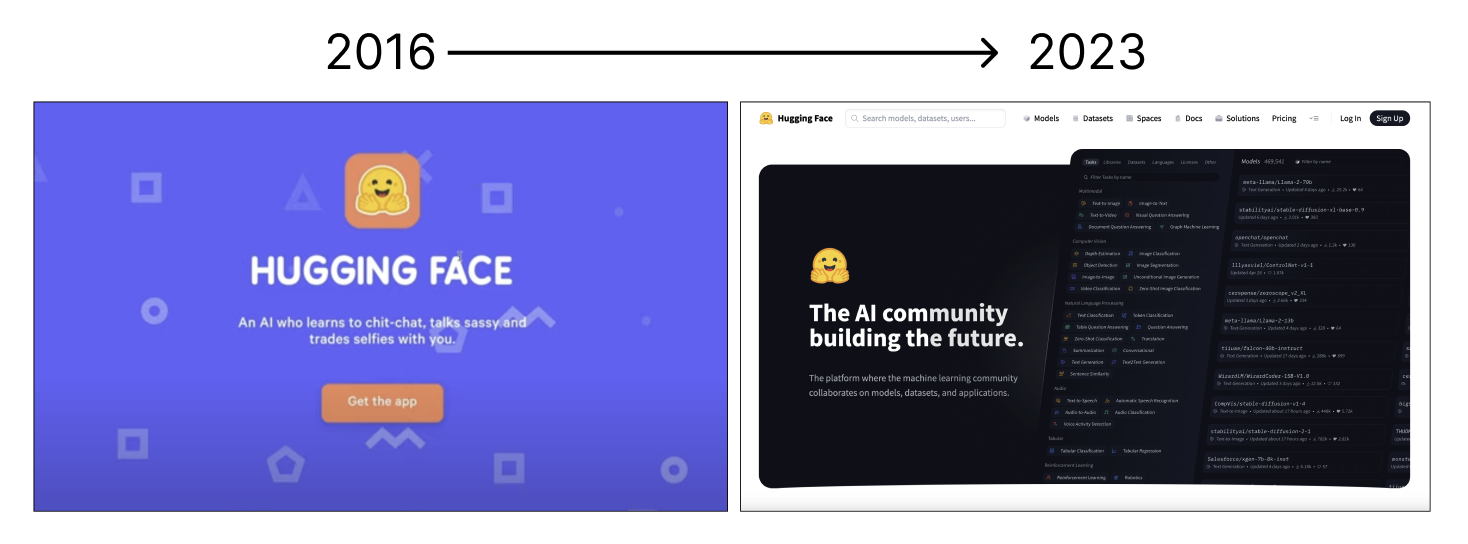
Image by the author.
The 2018 launch of its transformative Transformers library marked one of its biggest and most well-known contributions to the AI community, offering pre-trained models like BERT and GPT that have become staples in NLP tasks.
Today, HuggingFace has totally transformed the ML ecosystem. Its commitment to open-source collaboration has catalyzed innovation in NLP, allowing for communal growth and development of the technology.
The platform has become a nexus for model and dataset sharing, propelling research and practical applications in AI.
Their mantra?
“Democratize good Machine Learning, one commit at a time.”
Through strategic partnerships and a dedication to making advanced NLP tools widely available, Hugging Face has become integral to the community, continually pushing the boundaries of AI and democratizing access to cutting-edge technology.
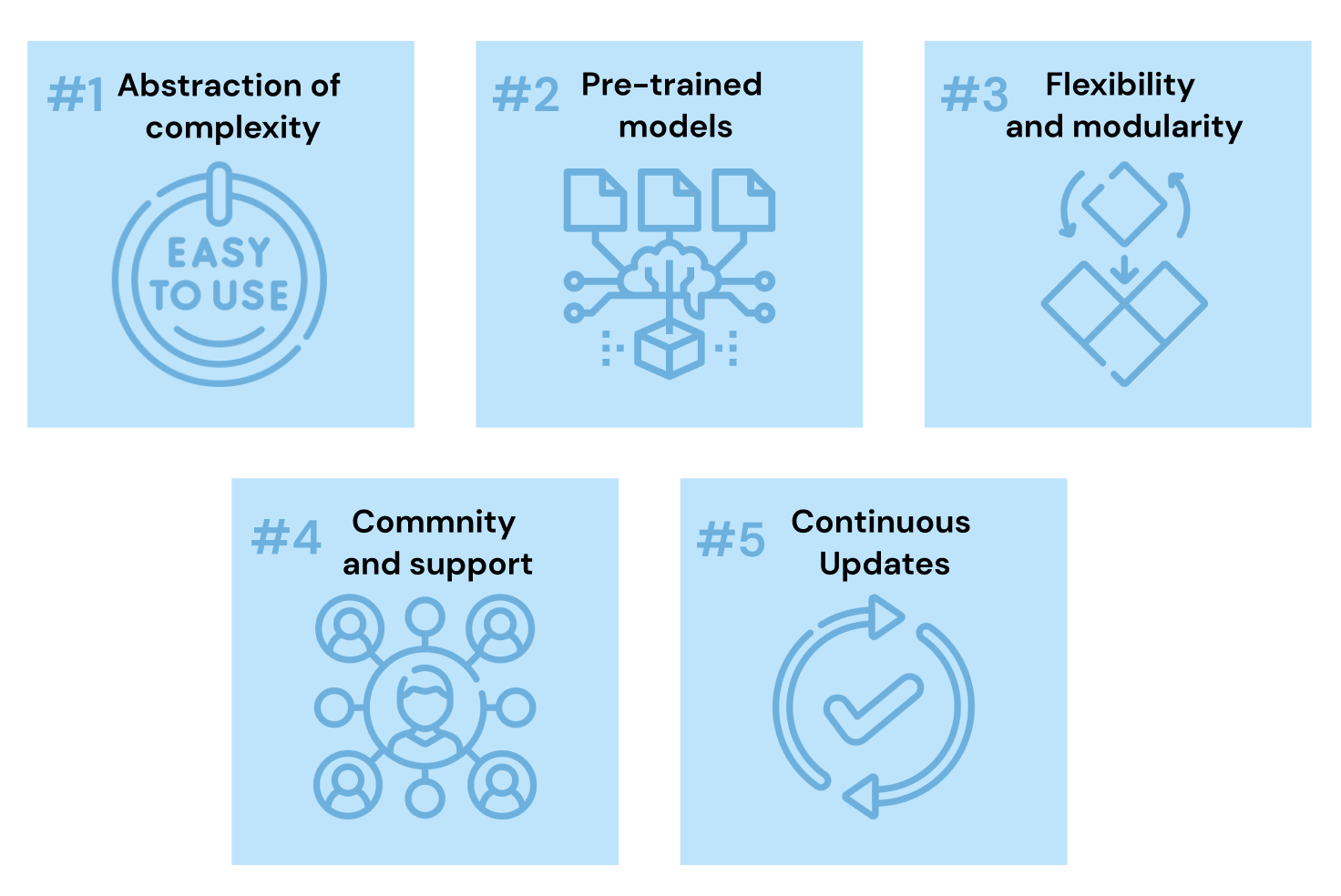
Hugging Face has become a cornerstone of modern NLP through its array of core components and features that cater to a wide range of language processing needs.
So, let’s break down each of them.
The Transformers library is a comprehensive suite of state-of-the-art machine-learning models specially designed for NLP. It consists of an extensive collection of pre-trained models optimized for tasks such as text classification, language generation, translation, and summarization, among others
Hugging Face has abstracted common NLP tasks into a simple-to-use `pipeline()` method, an easy-to-use API for performing a wide variety of tasks. These pipelines allow users to easily apply complex models to real-world problems. If you want to learn more about what’s behind this library, I strongly recommend reading the article An Introduction to Using Transformers and Hugging Face.
These models are easily accessible and customizable, which has been revolutionary for developers and researchers and has played a key role in making sophisticated NLP models more accessible.
Its significance lies in its ability to abstract the complexities involved in training and deploying NLP models, making it easier for practitioners to implement advanced NLP features with minimal code.
The library allows the leveraging of pre-trained models without delving into the underlying algorithms.
The Transformers library simplifies the implementation of NLP models in several key ways:
If you want to check firsthand all the work the transformers library avoids us, learn how to deploy an NLP model with Building a Transformer with PyTorch.
The Model Hub stands as the community's face, a platform where thousands of models and datasets are at your fingertips. It is an innovative feature that allows users to share and discover models contributed by the community, promoting a collaborative approach to NLP development.
You can go check it out on their official website. There you can easily select the Model Hub by clicking on the Models buttons in the navigator, and a view like the following one should appear to you:
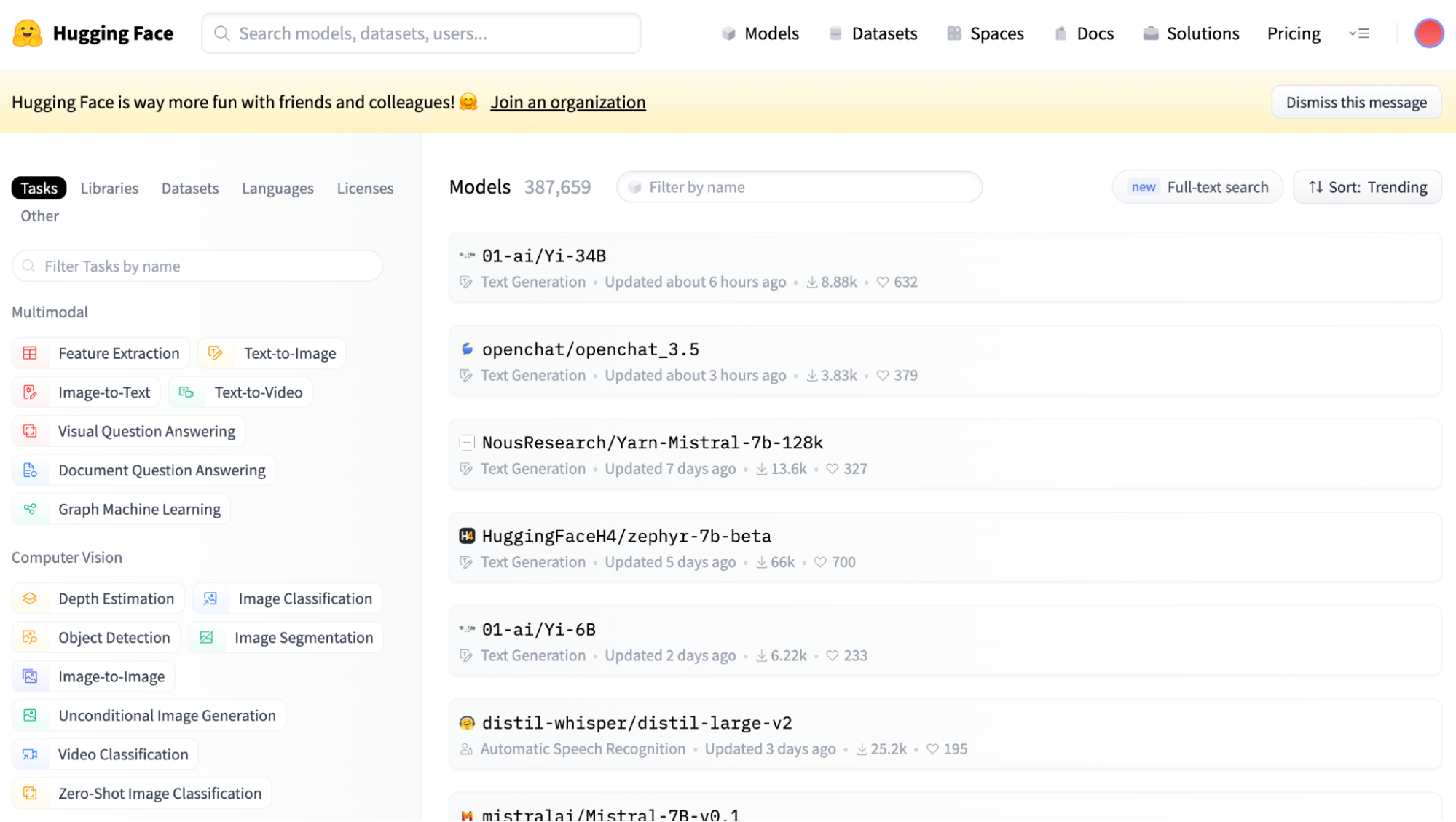
Screenshot of Hugging Face Model Hub main view.
As you can see, in the left-sidebar, there are multiple filters regarding the main task to be performed.
Contributing to the Model Hub is made straightforward by Hugging Face's tools, which guide users through the process of uploading their models. Once contributed, these models are available for the entire community to use, either directly through the hub or via integration with the Hugging Face Transformers library.
This ease of access and contribution fosters a dynamic ecosystem where state-of-the-art models are constantly refined and expanded upon, providing a rich, collaborative foundation for NLP advancement.
Tokenizers are crucial in NLP, as they are responsible for converting text into a format that machine learning models can understand, which is essential for processing different languages and text structures.
They are responsible for breaking down text into tokens—basic units like words, subwords, or characters—thus preparing data for machine learning models to process. These tokens are the building blocks that enable models to understand and generate human language.
They also facilitate the transformation of tokens into vector representations for model input and handle padding and truncation for uniform sequence lengths.
Hugging Face provides a range of user-friendly tokenizers, optimized for their Transformers library, which are key to the seamless preprocessing of text. You can read more about Tokenization in a separate article.
Another key component is the Hugging Face Datasets library, a vast repository of NLP datasets that support the training and benchmarking of ML models.
This library is a crucial tool for developers in the field, as it offers a diverse collection of datasets that can be used to train, test, and benchmark any NLP models across a wide variety of tasks.
One of the main benefits it presents is the simple and user-friendly interface. While you can browse and explore all datasets in the Hugging Face Hub, to use it in your code, they have tailored the dataset library that allows you to download any dataset effortlessly.
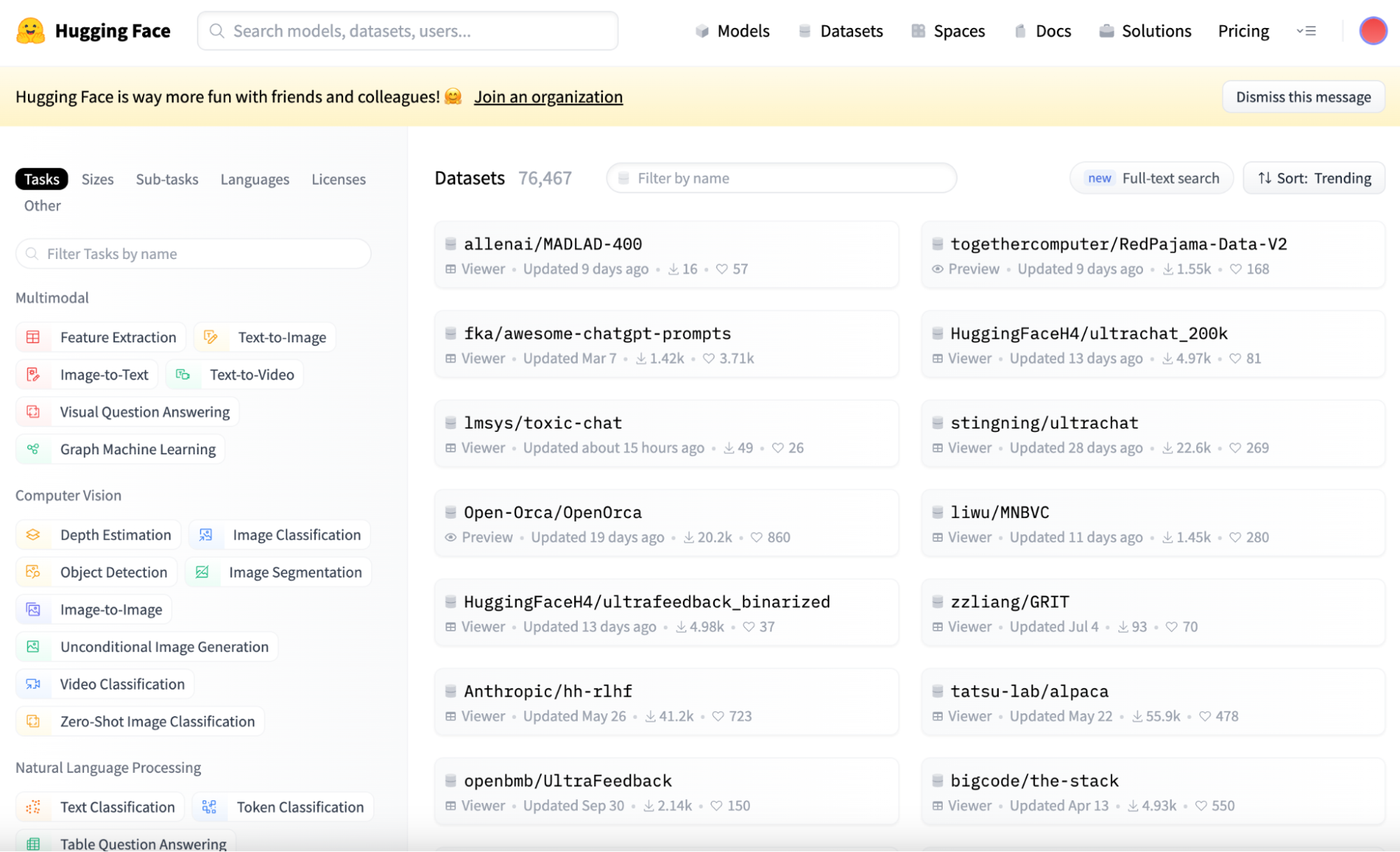
Screenshot of Hugging Face Datasets main view.
It includes datasets for common tasks such as text classification, translation, and question-answering, as well as more specialized datasets for unique challenges in the field.
So, now that we are all on the same page and understand the core concepts behind Hugging Face, let’s try to figure out how to use this technological little gem.
This guide will walk you briefly through the basics of getting started with Hugging Face, including installation, using pre-trained models, fine-tuning, and sharing your models with the community.
First, you should combine the transformers library with your favorite deep learning library, either TensorFlow or PyTorch.
The transformers library can be easily installed using pip, Python's package installer.
pip install transformers
To have the full capability, you should also install the datasets and the tokenizers library.
pip install tokenizers, datasets
Hugging Face's model hub offers a huge collection of pre-trained models that you can use for a wide range of NLP tasks. Let’s discover how to use our first pre-trained model.
1. Select a Pre-trained Model: First, you need to select a pre-trained model. To do so, we go to the Model Hub.
Imagine we want to infer the sentiment corresponding to a string of text. So we can easily browse only the models that perform `Text Classification` tasks by selecting the Text Classification button on the left-sidebar.
Hugging Face models always appeared ordered by Trending. Usually, the higher results are the most used ones. So, we select the second result, which is the most used sentiment analysis model.
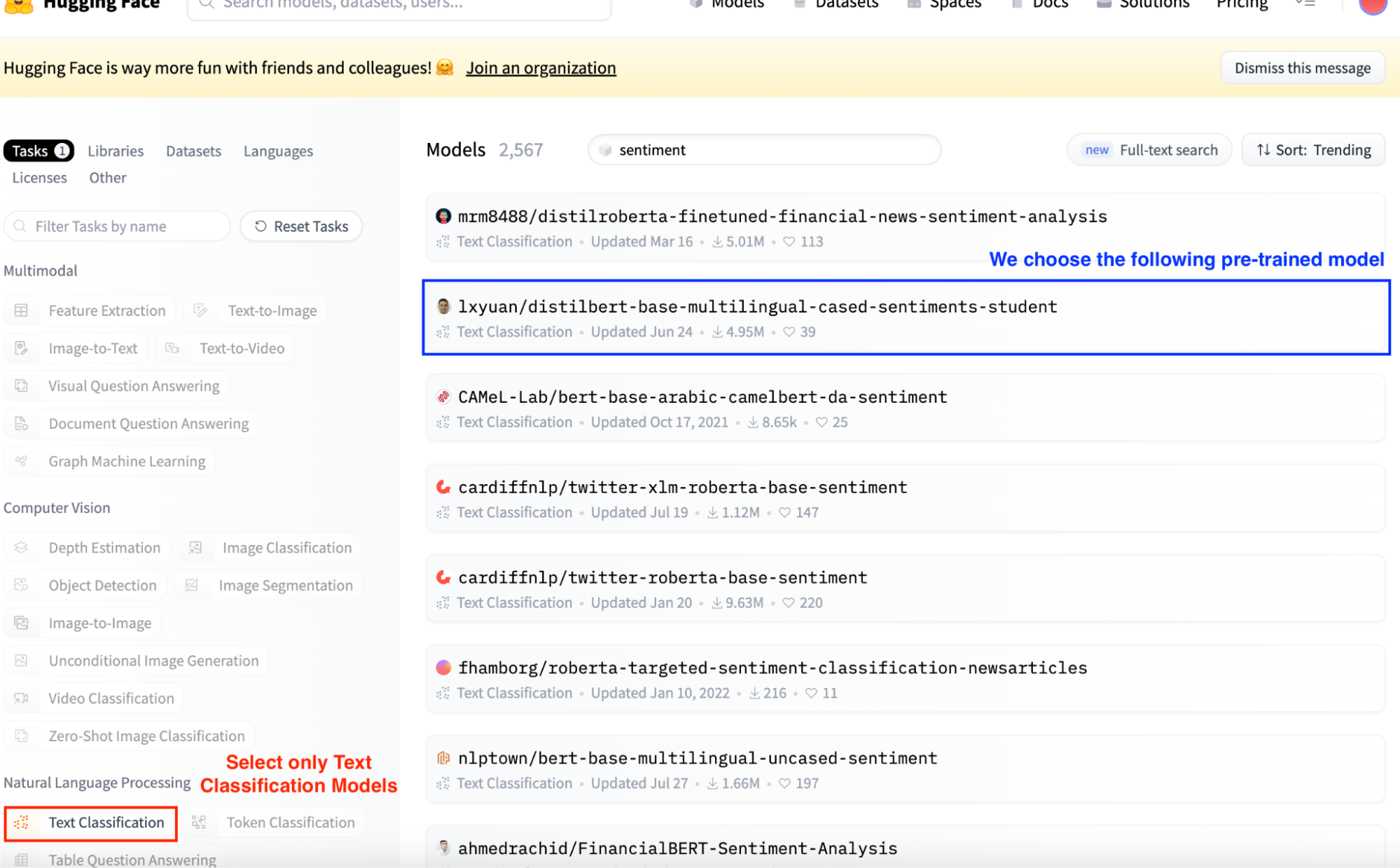
Screenshot of Hugging Face Model Hub main view. Selecting Text Classification models.
To use it, we need to copy the corresponding name of the model. It can be found within the top section of its specific view.
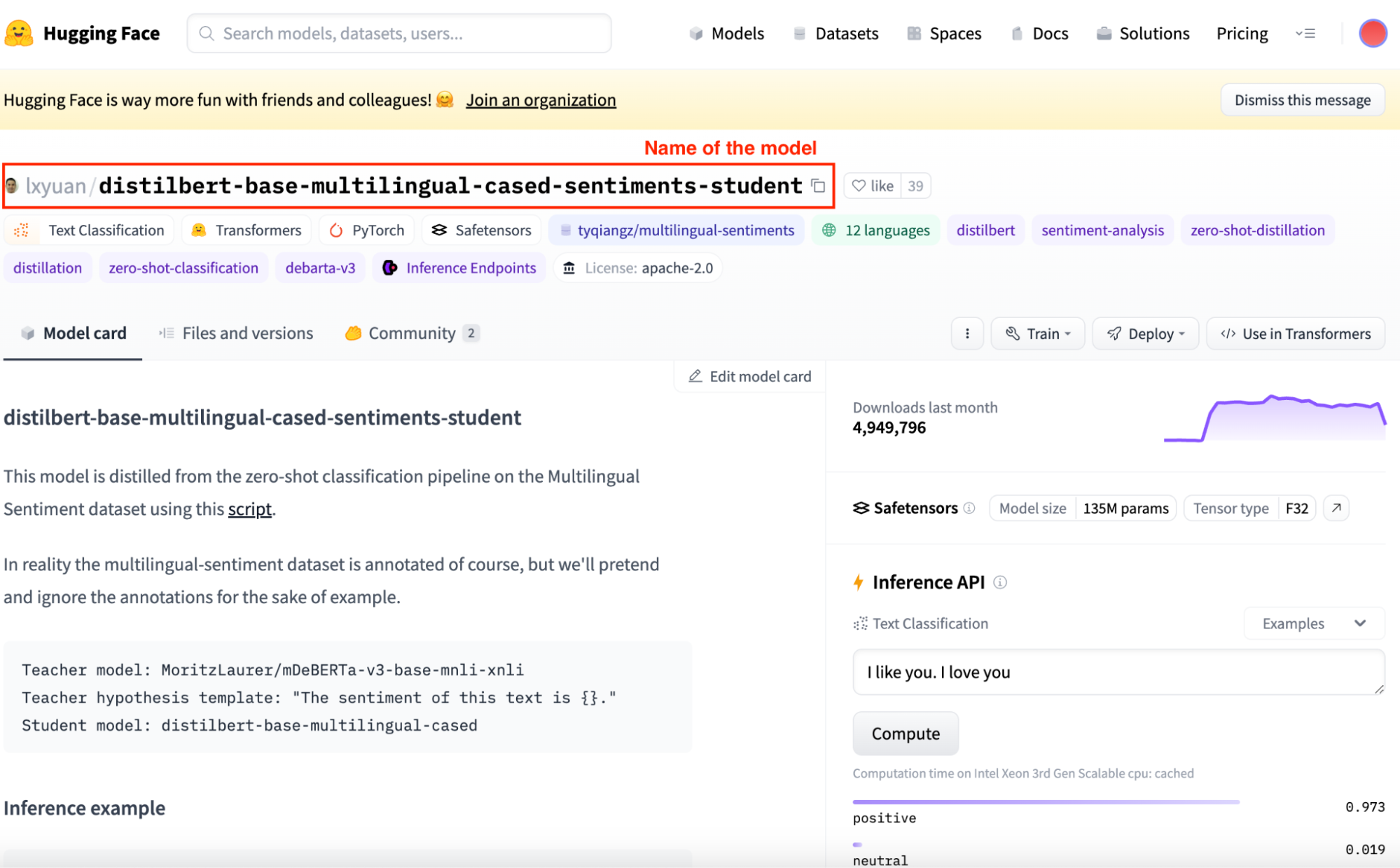
Screenshot of Hugging Face Model Hub-specific model view.
1. Load a pre-trained model: Now that we already know what model to use, let’s use it in Python. First we need to import the AutoTokenizer and the AutoModelForSequenceClassification classes from transformers.
Using these AutoModel classes will automatically infer the model architecture from the model name.
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "lxyuan/distilbert-base-multilingual-cased-sentiments-student"
# We call define a model object
model = AutoModelForSequenceClassification.from_pretrained(model_name)
2. Prepare your input: Load a tokenizer for our model, in this case, the transformers library facilitates the process as it inferes the tokenizer to be used from the name of the model that we have chosen.
#We call the tokenizer class
tokenizer = AutoTokenizer.from_pretrained(model_name)
3. Run the model: Generate a pipeline object with the chosen model, the tokenizer, and the task to be performed. In our case, a sentiment analysis. If you initialize the classifier object with the task, the pipeline class will populate it with the default values, even though it is not recommended in production.
# Initializing a classifier with a model and a tokenizer
classifier = pipeline("sentiment-analysis", model = model, tokenizer = tokenizer)
# When passing only the task, the pipeline command inferes both the model and tokenizer.
classifier = pipeline("sentiment-analysis")
We can execute this model by introducing some input.
output = classifier("I've been waiting for this tutorial all my life!")
4. Interpret the outputs: The model will return an object containing various elements depending on the model's class. For example, for this sentiment analysis example, we will get:
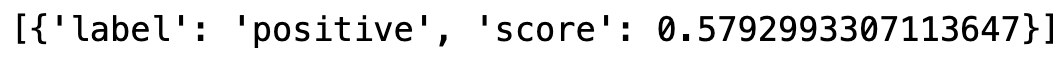
Obtained output.
Fine-tuning is the process of taking a pre-trained model and updating its parameters by training on a dataset specific to your task. This allows you to leverage the model's learned representations and adapt them to your use case.
Imagine we need to use a text-classifier model to infer sentiments from a list of tweets. One natural question that comes to mind is: Will this pre-trained model work properly?
To make sure it does, we can take advantage of fine-tuning by training a pre-trained Hugging Face model with a dataset containing tweets and their corresponding sentiments so the performance improves.
Here's a basic example of fine-tuning a model for sequence classification:
1. Choose a pre-trained model and a dataset: Select a model architecture suitable for your task. In this case, we want to keep using the same sentiment analysis model. However, now we need some data to train our model.
And this is precisely where the datasets library kicks in. We can go check all datasets in the Model Hub, and find the one that fits us the best.
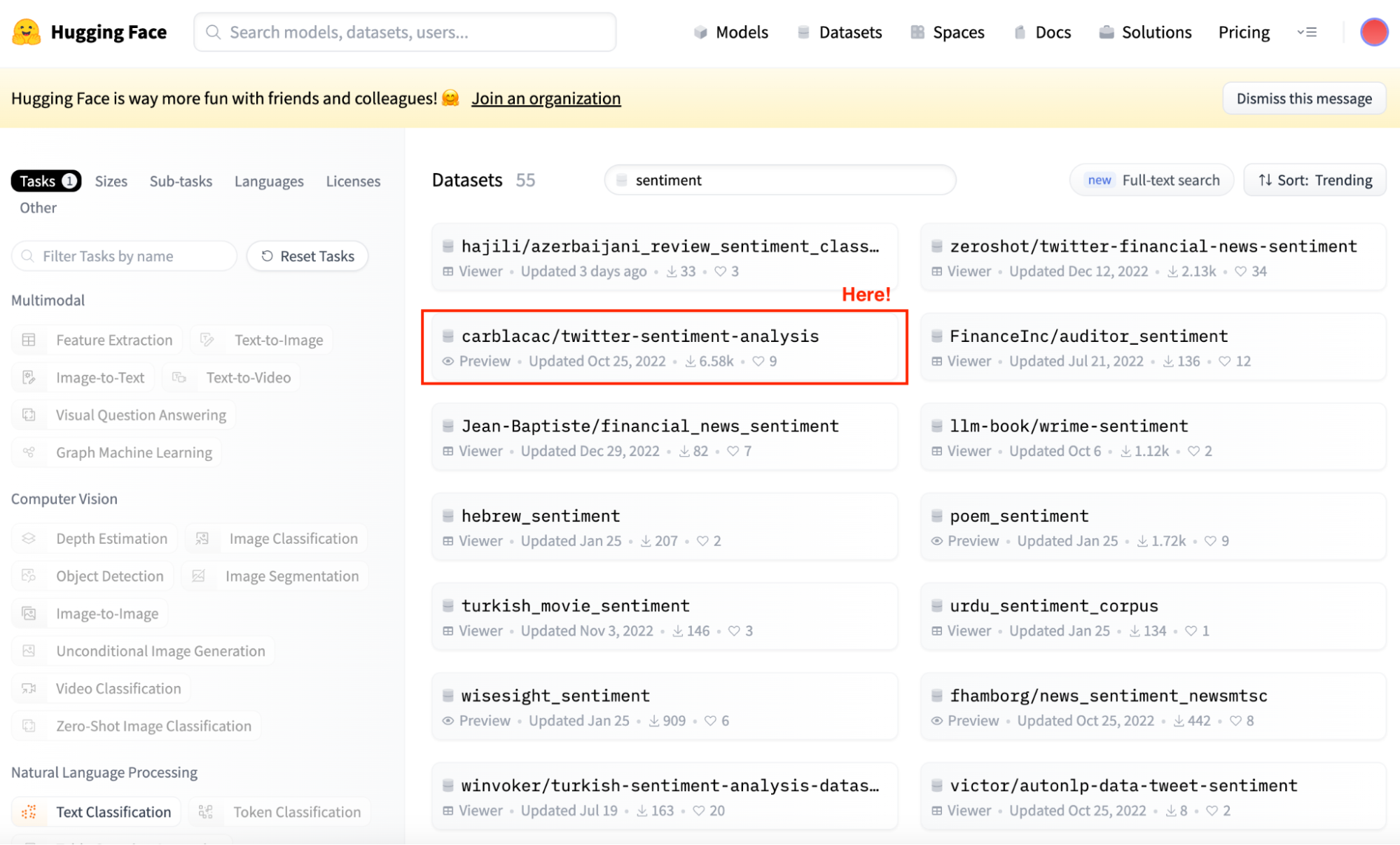
Screenshot of Hugging Face Datasets Hub main view. Selecting Sentiment analysis datasets.
Now that I already know what dataset to choose, we can simply initialize both the model and dataset.
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
If we check the dataset we just downloaded, it is a dictionary containing a subset for training and a subset for testing. If we convert the training subset to a dataframe, it looks like follows:
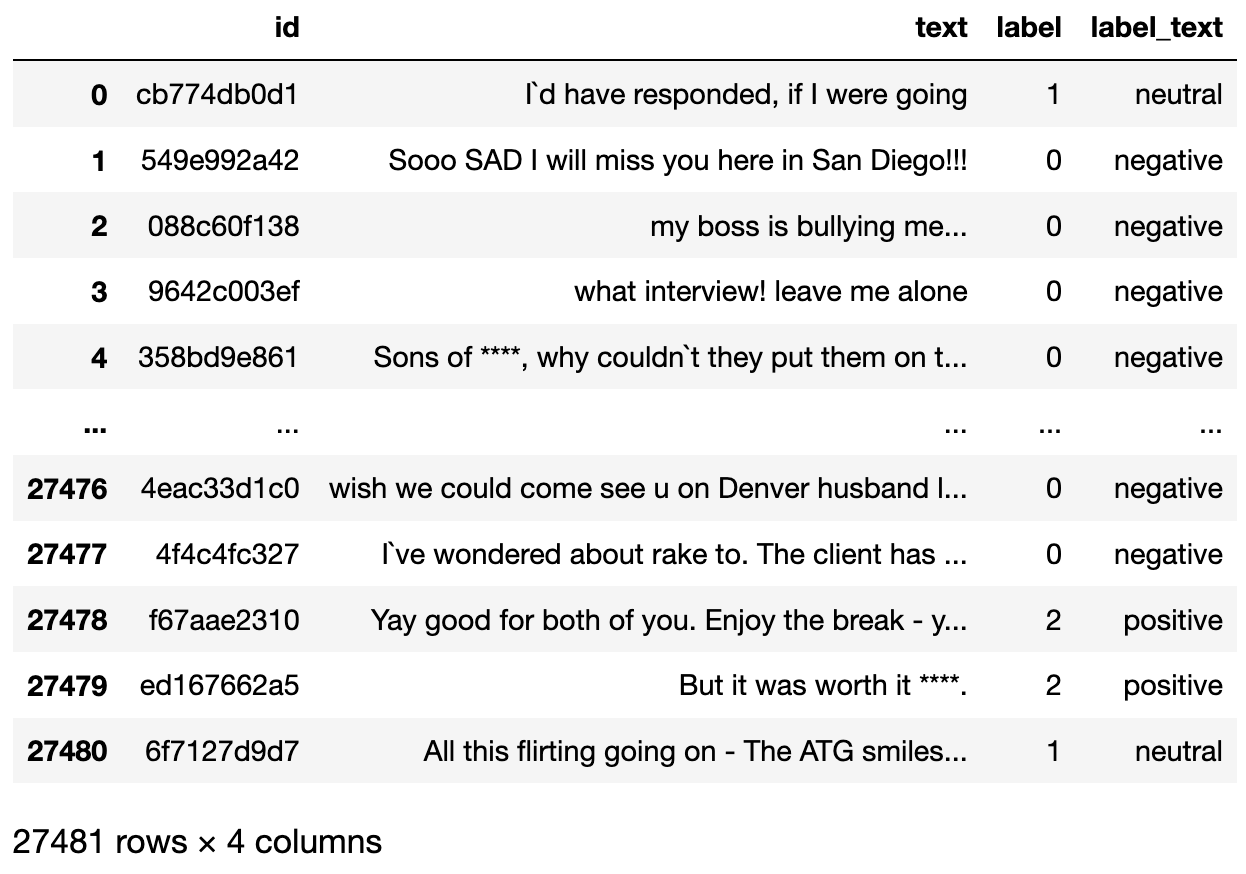
The data set to be used.
2. Prepare Your dataset: Now that we already have our dataset, we need a tokenizer to prepare it to be parsed by our model. The text variable of our dataset needs to be tokenized so we can use it to fine-tune our model.
This is why the second step is to load a pre-trained Tokenizer and tokenize our dataset so it can be used for the fine-tuning.
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
3. Build a PyTorch dataset with encodings: The third step is to generate a train and testing dataset. The training set will be used to fine-tune our model, while the testing set will be used to evaluate it.
Usually, the fine-tuning process takes a lot of time. In order to facilitate the tutorial, we randomly sample both datasets to reduce the computation time.
from datasets import load_dataset
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
4. Fine-tune the model: Our final step is to set up the training arguments and start the training process. The transformers library contains the trainer() class, which takes care of everything.
We first define the training arguments together with the evaluation strategy. Once everything is defined, we can easily train the model with the train() command.
from transformers import Trainer, TrainingArguments
import numpy as np
training_args = TrainingArguments(output_dir="trainer_output", evaluation_strategy="epoch")
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
5. Evaluate the model: After training, evaluate the model's performance on a validation or test set. Again, the trainer class already contains an evaluate method that takes care of this.
import evaluate
trainer.evaluate()
Our fine-tuned model presents an accuracy of 70%.
Now that we have already improved our model, how can we share it with the community? This brings us to our final step.
Once we’ve fine-tuned your model, you might want to share it with the community.
Hugging Face makes this process straightforward. First, you need to install the huggingface_hub library.
A requirement for this final step is to have an active token to be able to connect to your Hugging Face account. You can easily get one following this guideline. When working in a Jupyter Notebook, we can easily import the notebook_login library.
from huggingface_hub import notebook_login
notebook_login()
This will generate a login within our Jupyter Notebook. We just need to submit our token, and our notebook will be connected to our hugging face account.
Now we just need to upload our model using the push_to_hub command.
finetuned_model.push_to_hub("my-awesome-model")
And, after this, the model will be available for everyone in our Hugging Face profile.
If we want to standardize any NLP process, with Hugging Face, it usually involves three simple steps that take less than five lines of code:
1. Define a model object with the pipeline class (and the corresponding model and tokenizer).
2. Define the input text or prompt.
3. Execute the pre-trained model with our input and observe the output.
Text classification is a fundamental task in NLP. It consists of assigning to every input text one or more categories. This can be used for a variety of applications such as spam detection, sentiment analysis, topic labeling, and more.
You can observe the example code below, how, with only the three simple steps provided in the previous section, we can implement a text classification model.
# We import the pipeline module from the transformers library
from transformers import pipeline
# We load the pre-trained text classification model.
classifier = pipeline("text-classification",model='lxyuan/distilbert-base-multilingual-cased-sentiments-student')
# Input to be classified
input_ = "I absolutely love the transformers library!"
# Perform classification
output_ = classifier(input_)
# Observer the result
print(output_)
Easy, right?
So let’s go to the second use-case and one of the most abused of all time.
Most of you must already be familiar with ChatGPT or Google Bard, which are tools that generate text from an input prompt. This process is called “Text Generation,” and it is a fascinating aspect of NLP, where a model produces human-like text from an initial input.
It has a wide range of applications, from creating chatbot responses to generating creative writing.
The core idea is to train a model on a large corpus of text, enabling it to learn patterns, styles, and structures of language. As you can imagine, the most expensive part is precisely the training of the model.
However, Hugging Face allows us to implement such a model in just five lines of code, just like in the previous case.
See the example below:
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
prompt = "In a world dominated by AI,"
generated_text = generator(prompt, max_length=50)[0]['generated_text']
print(generated_text)
Question answering, commonly referred to as QA, is a field in NLP focused on building systems that automatically answer questions posed by humans in natural language.
QA systems are widely used in various applications, such as virtual assistants, customer support, and information retrieval systems.
QA systems can be broadly categorized into two types:
These systems typically use a combination of natural language understanding to interpret the question and information retrieval to find relevant answers.
Again, implementing one of these models using Hugging Face is fast and easy.
from transformers import pipeline
qa_pipeline = pipeline('question-answering', model='distilbert-base-uncased-distilled-squad')
context = """Paris is the capital and most populous city of France. The city has an area of 105 square kilometers and a population of 2,140,526 residents."""
question = "What is the population of Paris?"
answer = qa_pipeline(question=question, context=context)
print(answer)
The final use case is translation. Machine translation is a subfield of computational linguistics that focuses on translating text or speech from one language to another using software. With the advent of deep learning, machine translation has made significant strides, particularly with models like Neural Machine Translation (NMT) that use large neural networks.
Modern NMT systems, unlike traditional rule-based or statistical translation models, learn to translate by training on large datasets of bilingual text. They use sequence-to-sequence architectures, where one part of the network encodes the source text, and another decodes it into the target language, often with impressive fluency and accuracy.
A simple example using Hugging Face would be:
from transformers import pipeline
# Load the translation pipeline for English to Spanish
translator = pipeline('translation_en_to_de')
# Text to translate from English to Spanish
text_to_translate = "This is a great day for science!"
# Perform the translation
translation = translator(text_to_translate, max_length=40)
# Print the translated text
print(translation[0]['translation_text'])
Hugging Face has emerged as a transformative force in the field of artificial intelligence and natural language processing. Its comprehensive suite of tools, including the revolutionary Transformers library, the collaborative Model Hub, and the extensive Datasets library, has democratized access to advanced NLP capabilities.
By fostering an environment where innovation is shared and built upon collectively, Hugging Face is not only contributing to the advancement of AI but is also shaping a future where technology is more accessible, inclusive, and powerful.
As we continue to witness and participate in the AI revolution, Hugging Face offers a reminder that the most profound technological advancements are those that are open, shared, and built together.
It's not just about creating smarter machines but about fostering a smarter, more connected community of developers, researchers, and enthusiasts who are eager to push the boundaries of what's possible.
Start Your AI & NLP Journey Today!
Track
Track
Course
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
code-along
Alara Dirik
code-along
Priyanka Asnani
code-along
Jacob Marquez



