
Dr. Hugo Bowne-Anderson, data scientist and educator at DataCamp, recently conducted a webinar on the five things business leaders need to know about data strategy. Read on for a summary of the webinar, or watch the webinar on-demand.
1. The 80/20 rule for data science
The 80/20 rule, also known as the Pareto principle, states that, for many events, roughly 80% of the effects come from 20% of the causes. In 2018, for instance, roughly 80% of taxes in the U.S. were paid by the top 20% of earners. As it applies to data science, the Pareto principle means that work done in 20% of the time generates 80% of the results. So when prioritizing work in your data strategy, you want to focus on what really drives value.
Focus on what will move the needle
Often, business leaders are drawn to buzzworthy topics like deep learning, machine learning (ML), and AI. But there are more basic areas you should first focus on that can result in large wins, like these:
- Data infrastructure is necessary but you may not see the return immediately. Companies like Spotify have improved data discovery by unifying data sources. Prioritizing data infrastructure can help companies avoid different data standards across silos, better prepare for future data initiatives, and generate consistent data views and dashboards.
- Customer service best practices include call center routing, customer churn models, and conversational AI.
- Sales propensity models are important for your sales and marketing teams.
Descriptive analytics drives 80% of value for business
You might be asking, “Which types of business analytics should I focus on first?” The Pareto principle can help with that:
- Descriptive analytics, or business intelligence, makes up 80% of the value for many businesses. It’s about taking data that your company already has and getting it to the right people in whatever form they can consume it and utilize it. This will be in the form of dashboards, reports, and emails. We challenge all companies that really want to move the needle to focus on five descriptive analytics projects that could inform your decision making, and order them in terms of importance.
- Predictive analytics, or ML, is about preparing for the future by predicting what will happen. ML is the branch of predictive analytics that uses streamlined statistical algorithms to predict the future based on existing information and identify relationships and insights—think Netflix’s recommendation engine.
- Prescriptive analytics, or decision science, is the final phase of business analytics that anticipates what, when, and why certain outcomes will happen—and determines what to do with that information. It applies data to the decision-making process. On our DataFramed podcast, Cassie Kozyrkov, the Chief Data Scientist at Google Cloud, explains the link between decision intelligence and data science.
2. Why big data isn’t all that big
Bigger results with small data
There are many ways to define big data. Hugo provides one good working definition of big data:
Big data is far more data than you can store in a laptop or on one hard drive: something that you need distributed across clusters of computers in order to store, work with, transmit, and analyze.
Companies like Google have leveraged big data to great effect and generated a lot of hype along the way. But Hugo posits that small data can actually generate really good results and we don’t need to get sucked into the hype.
A good way to think of big data is in terms of the Gartner Hype Cycle. If we use Google trends as a proxy for expectations, we’ve surpassed the Peak of Inflated Expectations and are on the way down to the Trough of Disillusionment.
Source: Wikipedia
So, the question is: can small data be enough? Hugo believes the answer is yes. It’s not about mountains of data—it's about small, high-precision data. For instance, Tycho Brahe, a Danish astronomer, collected only about 2,000 data points that informed Johannes Kepler’s three laws of planetary motion, which then informed Newton’s theory of gravitation. And pollsters are able to use a statistically representative sample of around 1,000 citizens and predict outcomes within a 3% margin of error.
What’s more important than big data: variety
Hugo takes it a step further: he says having a variety of data is more important than having big data. Combining qualitative data, or thick data, into your dataset will get you better results. Thick data is a term borrowed from sociology and anthropology that is primarily descriptive, as opposed to thin data, which is numbers-based.
3. Why the future of data work is point-and-click
Using GUIs for data work
What’s the best way to equip people without technical data expertise to tap into business intelligence and use ML to inform their decisions? It’s not by getting every employee to code. The answer is through vendors or tools that productize data analytics. In the future, Hugo predicts that the bulk of data work will be done in graphical user interfaces, also known as GUIs, or drag-and-drop and point-and-click interfaces.
Top tech companies are taking note. Splashy acquisitions of business intelligence tools have recently made the news. Just last year, Salesforce acquired Tableau, and a few weeks ago, Google closed a $2.6 billion acquisition of Looker, a popular BI tool.
Predictive analytics tools are also productizing ML. Google AutoML allows non-data scientists to build diagnostic and predictive analytics models, and Microsoft Azure now has an automated ML tool that makes building models as easy as importing a data set and telling the service which value to predict.
Be self-aware when using data products
Tools like these serve to equip non-technical employees with the ability to become dangerous in using data. But they must be able to use data in the right way. Hugo is interested in products that help people recognize when they have biased results. He recommends checking out Survival of the Best Fit, an educational game about hiring bias in AI.

4. Data strategy means data culture
How much data is actually used?
We’ve already discussed that collecting mountains of data (big data) is not as important as collecting essential, relevant data (small data). In a poll conducted during the webinar, we found that 53% of respondents use less than half of the data they collect. The goal, of course, is to be able to get more of your data to work for you. This requires a robust data strategy and establishing a robust and healthy data culture.
How to build a data strategy
On Episode 30 of our podcast, DataFramed, Taras Gorishnyy, then a Senior Analytics Manager at McKinsey, identified the necessary moving parts to building a data strategy:
- Create a vision for analytics aligned with company strategy
- Establish strong C-level support, e.g., advocacy, funding, and excitement
- Extract value early from at least several use cases
- Implement process redesign and culture change to ensure the right mix of data skills across the company
- Build a strong data foundation to provide integrated, trusted, and timely data
The need for data process redesign and culture change
DataCamp’s mission to democratize data skills around the world is closely tied to the fourth bullet: helping companies build a strong data-fluent culture. Yet when we conducted a survey of over 300 organizations in 2019, we found that only 39% of companies with mature data fluency had implemented process redesign and culture change with respect to data, and only 7% of the companies with immature data fluency had.
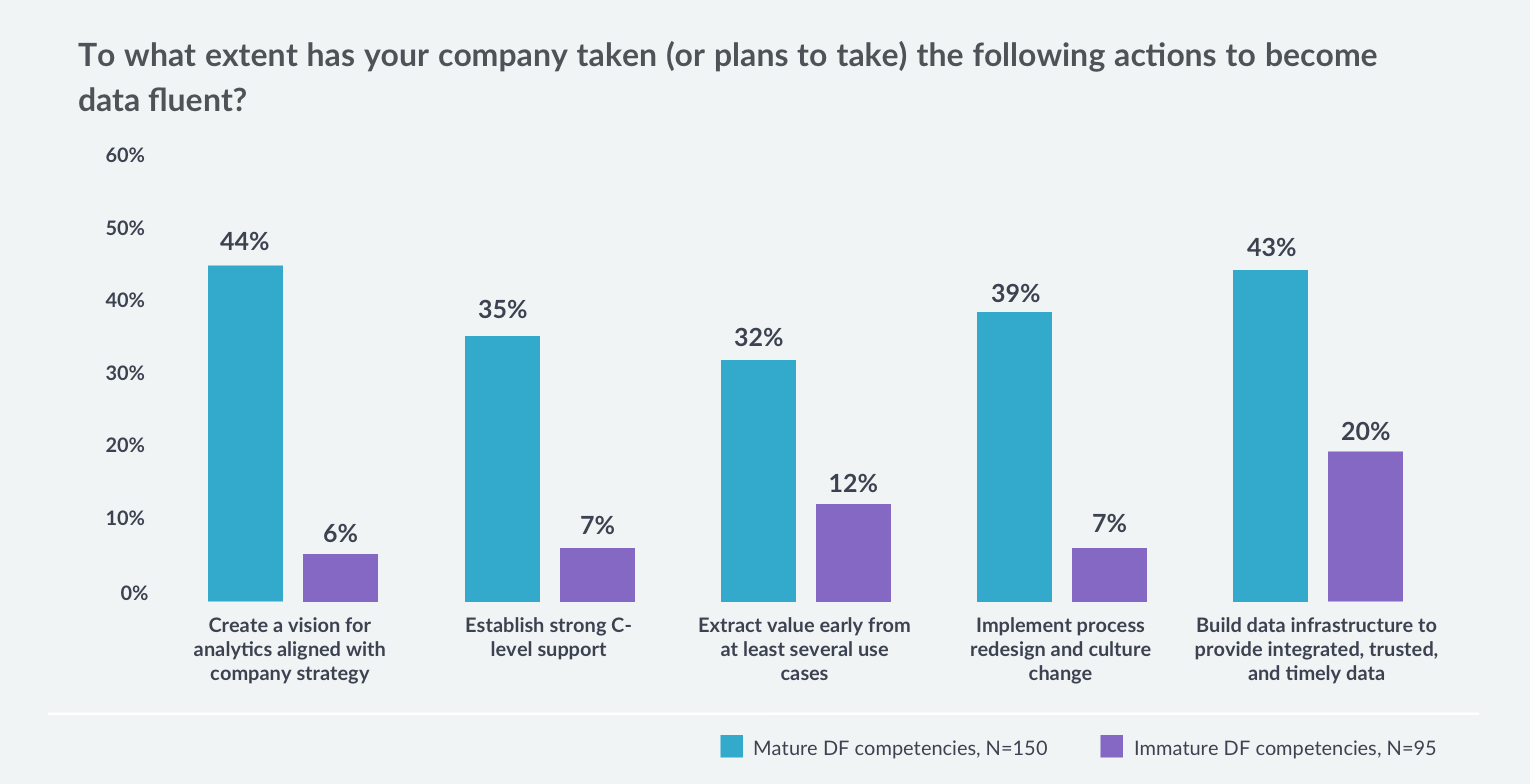
Source: Don’t Wait: What 300+ L&D Leaders Have Learned About Building Data Fluency
Upskilling, not hiring, is the path to data fluency
Every company wants to hire top talent, but according to the 80/20 rule, the majority of companies won’t be able to do so. There is a shortage of talent for the abundance of data work that needs to be done, and it’s unrealistic to build a data strategy around hiring unicorns. The alternative? Establish a data culture of upskilling and reskilling your existing employees by cultivating a learning environment at your company.
5. Why data strategy is really about empathy
Consider your stakeholders
Hugo posits that data strategy, as with any other business strategy, requires careful consideration of who you're impacting and what different stakeholders need. A company’s data strategy informs how it builds products and implements business decisions at a large scale. So when using data, it's important to remember that each data point represents a person or a group of people. There’s no question that data can help companies at scale—but it can also hurt them.
A case in point: A few months ago, it came to light that the Apple Card was “sexist” against women applying for credit. While Apple may not have intended to obstruct fairness in the application process, they ended up with a huge PR challenge and increased scrutiny by regulators. Algorithms can’t be implicitly trusted—they must be evaluated through the lens of empathy.
Acknowledge your blind spots
On Episode 50 of our podcast, DataFramed, Cathy O’Neil, author of Weapons of Math Destruction, said, “Data science doesn’t just predict the future. It causes the future.”
Companies building products at scale and developing large-scale data strategy not only need to list who they believe their stakeholders are, but they must consult as many people as possible, because there will inevitably be groups that are impacted that they overlook, just as Apple did.
Be honest about which tasks will be automated
A lot of people are scared of machines taking over their jobs. But as technology improves, job automation won’t be the biggest challenge for employees—task automation will be. Certain parts of someone’s job may end up being automated away. So the challenge for employers is figuring out how these employees can be upskilled and reskilled in light of this automation, and how to transition them to do more high-level work.
For a deeper dive into these topics, watch Hugo’s webinar on-demand.


