This article focuses on application containerization in modern software development with cloud provider container orchestration, which allows us to deploy and dynamically scale our applications to any workload demand with repeatability, maintainability, observability, and high availability whilst being cost-effective and providing disaster recovery.
In Brief
- Containers allow us to package our applications independent of a platform as lightweight images that are highly performant to spin up and replicate.
- Container orchestration engines allow us to dynamically manage unpredictable and large distributed compute workloads.
- AWS EKS is one of the most popular container orchestrators and offers tight integration with numerous AWS services.
- Use Helm charts to deploy complex machine learning or data science Kubernetes applications with a single command.
Why Containers?
It’s almost impossible to answer the “why” without the “what,” so let’s start with what problems containers aim to solve and what a container is in order to answer the “why.”
The old model of software engineering would see developers writing code on their local machines, which would then be deployed and shipped to a test environment, followed by a release to production. The problem with this model was the inconsistencies between environments and the dependencies and libraries running on the various servers.
So, an application that “works on my machine” (to coin a classic developer quote) might be reliant on runtime libraries of very different versions to that of the target environment, which could lead to unexpected behaviors once deployed.
Containers solve this by abstracting the application layer entirely by packaging compiled code, libraries, dependencies, and runtimes into an “image.”
A container image can then be used as a template that a container engine, such as Docker, can quickly deploy and run as a container instance with predictable behavior across any environment.
The next problems containers solve are scalability, maintainability, and cost-effectiveness. Historically, production environments consisted of a large amount of (expensive) hardware resources that would be ring-fenced and protected for exclusive use by high-volume or business-critical applications. These expensive environments would need constant management, maintenance, and patching.
The amount of hardware allocated to such applications would need to be the maximum amount to meet the peak load but applications do not always have consistent, predictable usage patterns. This fact leads to large amounts of hardware sitting dormant during off-peak times.
The solution is container orchestration.
Since a container image is platform-independent, container compute resources can be scaled up and down on demand using any available server that has the capacity to run a container engine, leaving the maintenance of the underlying server operating system decoupled from the application.
This has a clear impact on cost-effectiveness since if we manage our containers and orchestrate them in a way that dynamically meets the current demand, then we are maximizing the use of the bare metal.
This explanation is a “mile-high” view, and we will dive into the depths in the following sections, but before we do, let’s talk about some practical uses of containers.
Containers for Data Science and Machine Learning
Applications for data science and machine learning are prone to being highly compute-intensive
with sometimes unpredictable usage patterns and deal with vast amounts of data.
Such applications frequently benefit from parallelization in order to divide and conquer a problem before persisting results to a data store. This is a massive over-simplification, but straight away, it’s clear that such applications are a perfect fit for containers and container orchestration!
So, armed with all that knowledge, let’s get into the “how.” Then, at the end of this article, we will revisit the link between data science and machine learning applications when we talk about Helm and how we can run complex applications deployed as containers within a container orchestration engine with minimal effort and configuration.
There are many container engines out there, but for this article we will be using the most popular, Docker. You can familiarize yourself with the platform in our Introduction to Docker tutorial.
Virtual Machines (VMs) vs containers
Virtual machines abstract physical hardware, turning one server into many via a hypervisor, allowing multiple VMs to share the same host. Each VM has a guest operating system (OS).
Containers are an abstraction at the application layer. A server with a container engine installed can run multiple containers at the same time all sharing the underlying OS. You can learn more about Containers in our containerization tutorial.
The key difference here is that containers use the host OS and do not come packaged with their own, unlike a VM. This makes them much more lightweight and fast to replicate, run, and destroy whilst still providing the benefits of security isolation and fault tolerance between containers (if a container crashes, it has no impact on any other containers running).
It also means better resource utilization so more containers can run on a single docker engine than VMs could run on a hypervisor given the comparable underlying hardware specifications.
Docker image vs container
A Docker Image packages configuration, code, dependencies, and the runtime engine. Images act as a template from which to replicate and run container instances within Docker. A container can run on any platform that supports Docker.
Container orchestration
Now we know all about containers, we need a way to manage them. There are several orchestrators out there, but for this article, we are going to focus on Kubernetes running in the AWS cloud under Elastic Kubernetes Service (EKS).
Some of the key tasks managed by EKS are:
- Deployment
- Scaling
- Load balancing
- Monitoring
- Service discovery
- Self-healing
AWS services
Before we start explaining EKS, we need to understand some AWS cloud services that underpin EKS.
CloudWatch
Monitoring and observability service that collects data in the form of logs, metrics, and events.
VPC
A Virtual Private Cloud is a logically isolated network securely protected and managed per AWS account.
ELB
An elastic load balancer is a highly available networking component that can distribute traffic across multiple targets.
IAM
Identity and Access Management provides fine-grained access control for AWS accounts.
ECR
The Elastic Container Registry is a fully managed docker image container registry.
EC2
Elastic Cloud Compute (abbreviated due to the 2 C’s) is a core AWS service that underpins numerous others. It allows the rental of virtual servers upon which customers can run their applications.
Region
A physical location around which data centers can be clustered, for example, EU-WEST-1 (Ireland) and EU-WEST-2 (London).
AZ
An availability zone is one or more discrete data centers with their own redundant power, networking, and connectivity. A region consists of multiple AZs.
Route53
A highly available DNS service.
WAF
Web Application Firewall that helps protect applications against common exploits and bots that might affect availability, compromise security or consume excessive resources.
Kubernetes Fundamentals
Kubernetes is sometimes referred to as K8s. This is because there are eight letters between the letter K and the letter S in Kubernetes.
Cluster
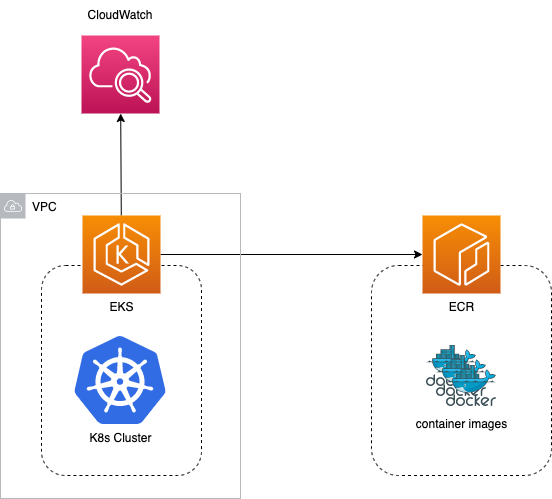
EKS will provision a managed K8s cluster. This is the highest-level component and acts as a container for all of the services, nodes, and pods.
EKS has tight integration with CloudWatch, Elastic Container Repository (ECR), IAM, API gateway, Elastic Load Balancer (ELB), CodePipeline, Secrets Manager, and more.
Taking the most basic example, we can store container images in ECR and have our application managed and run by EKS, which is deployed into a VPC across multiple availability zones, with all system and application logs published to CloudWatch.
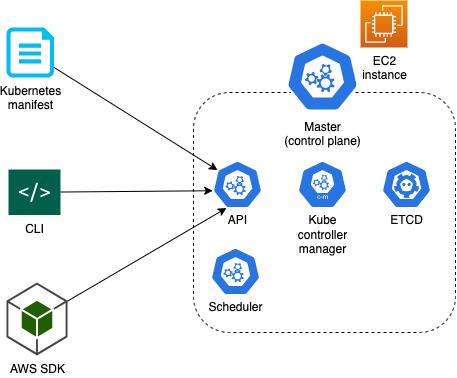
Master/control plane
The master node is the heart of K8s and helps to manage, monitor, schedule, and plan nodes. It has several subcomponents.
ETCD
This is a key value store that persists all critical cluster data
Kube scheduler
The scheduler deploys containers into nodes
Kube controller manager
This ensures the proper state of cluster components, making sure the desired workload equals the actual workload.
API
All interactions from outside the cluster go via the K8s API.
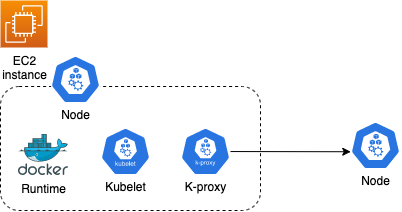
Nodes (worker nodes)
An EKS worker node is an EC2 instance. Each node has the docker runtime installed to run containers, the Kubelet agent that handles all communications to and from the master, and the K-proxy, which allows inter-node communication.
In order for nodes to integrate with CloudWatch, the IAM role for the node needs to include the CloudWatchLogsFullAccess policy.
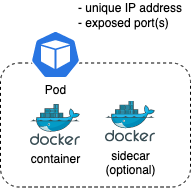
Pod
A pod is the smallest deployable unit. It runs a single application container plus any sidecar containers that may be required. Each pod is ephemeral and will have a unique IP address.
Deployments and Replica sets
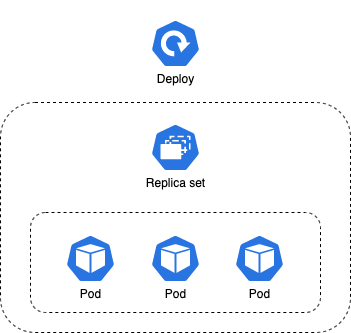
A replica set manages a set of pods by label and ensures that there is always a stable set of running pods for a specified workload. If a pod goes down, then it is the job of the replica set to restore that pod.
Deployments manage replica sets. If a replica set goes down then it is the job of the deployment to restore it. Deployments can be configured as rolling, ramped, re-create, or canary (details of deployment types are out of scope for this article).
Services
For the purpose of this article, we can consider a service to map directly to an AWS Application Load Balancer (ALB), which is a type of ELB. There is a bit more to it than that, but it's important to understand some of the benefits that ALB can bring to the table:
- Associate a DNS name
- Health checks
- High availability across multiple AZs
- WAF
- Access logs
The primary function of a service is to distribute traffic between nodes/pods.
Container Scaling
ASG and EC2
A core component of EC2 is the Auto Scaling Group (ASG). This AWS component will maintain a fleet of EC2 instances at a desired workload across multiple AZs within a region, usually behind a load balancer.
CloudWatch metrics provide the triggers for which to scale in or out.
This type of scaling is known as horizontal scaling due to the fact that the fleet of application servers can expand and contract “horizontally” in order to meet traffic demands. An example scaling policy could be to maintain all instances below 50% CPU utilization. At this level, the ASG would normally be configured to manage an equal number of EC2 instances per AZ, but there are other configurations available beyond the scope of this article to discuss.
HPA
It is very important to distinguish between scaling at the EC2 level and at the pod level. The Horizontal Pod Autoscaler is responsible for scaling pods within each node. The HPA uses K8s metrics gathered via the Metrics Server (this needs to be installed within the cluster and is not part of the default cluster deployment for EKS) and scales pods based on node metrics. An example scaling policy could be to target vCPU usage at 50%.
EKS Cluster autoscaler
Cluster autoscaling requires the installation of an open-source EKS cluster autoscaler, which is responsible for scaling the K8s service alongside an AWS ASG, which in turn manages the scaling of the physical instances that are provisioned for the cluster.
When a node reaches its maximum capacity based on the HPA scale policy, the cluster autoscaler will create another EC2 instance and add it to the ASG.
The Full Picture
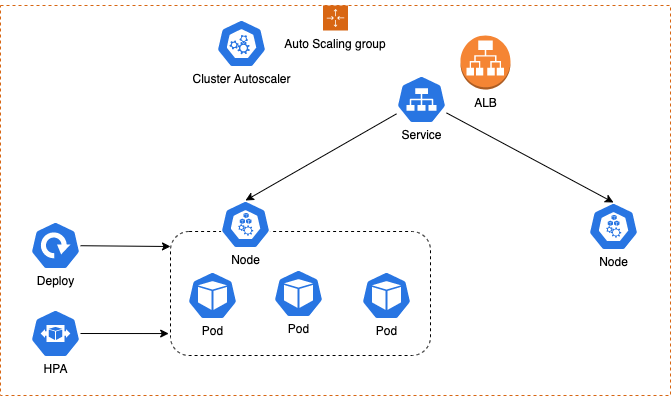
Scaling policies are highly flexible, customizable, and configurable but normally come with a cool-down period before a scale-down / in occurs to prevent unnecessary scaling due to erratic, fluctuating traffic demands.
It is important to note that If a pod exceeds its vCPU limit, then Kubernetes will throttle the application running in that pod, but if a pod exceeds its memory limits, then Kubernetes will restart the container.
Cost optimization
An example of how to restrict pods within instances using an m5.large instance type:
2 * vCPU = 2000m (millicore)
8 GiB memory
Pod resource restrictions:
- Reserved amount of vCPU, e.g. 500m
- Limit of vCPU, e.g. 1000m
- Reserved amount of memory, e.g. 256Mi
- Limit of memory, e.g. 512Mi
Observability
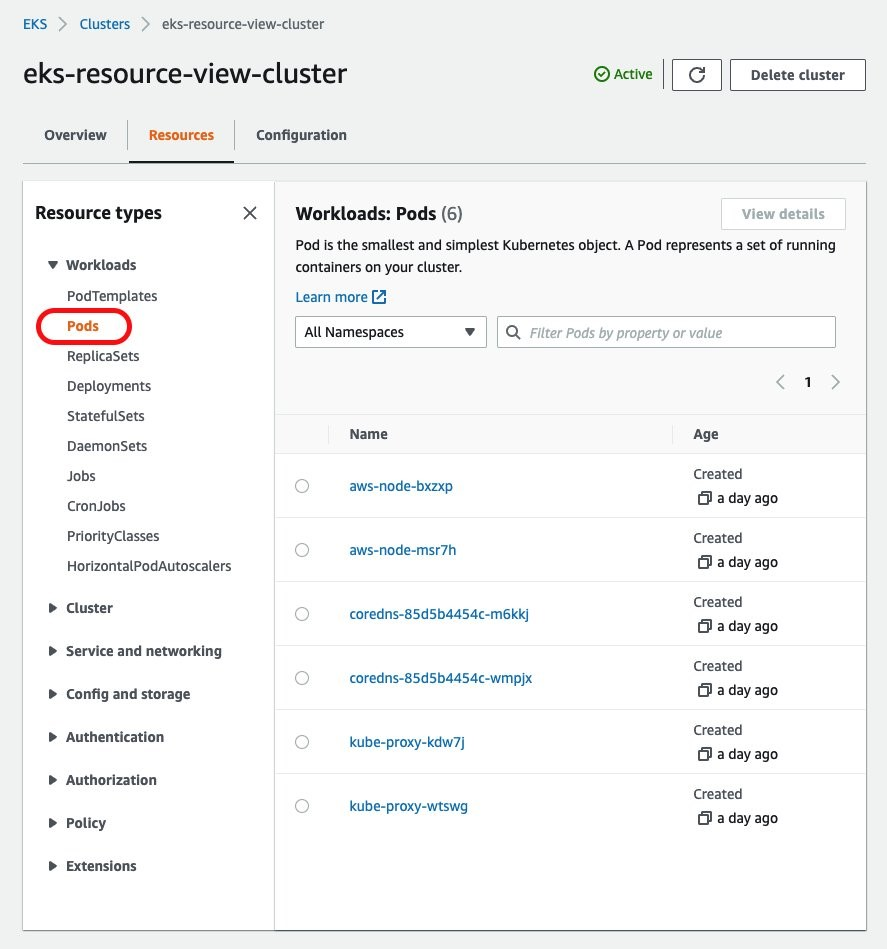
EKS Resource View
Shows all resources running on the cluster.
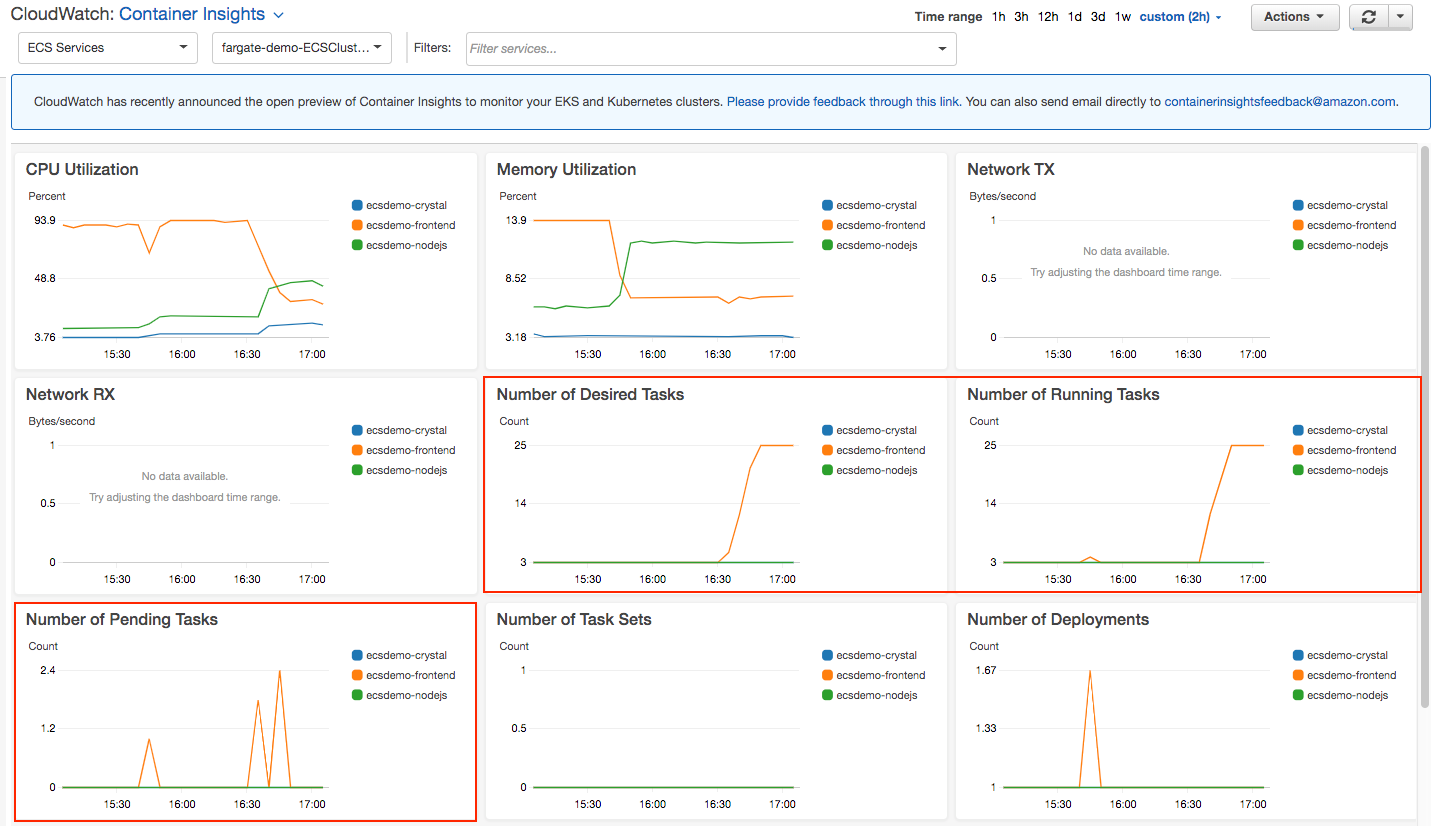
CloudWatch Container Insights
- Monitors
- Alarms
- Trigger lambda functions
- Pre created dashboards and metrics
- One click installation
Helm
Helm is a package manager for Kubernetes that automates the packaging, configuration, and deployment of applications. Helm charts allow you to create, share, version, and publish complex Kubernetes applications.
Some interesting chart examples in the domain of data science and machine learning are:
- Ml-workspace
- Mlflow
- Tensorflow
- Hive
- Spark
These K8s applications can be deployed to your EKS cluster via Helm with a single command!
Conclusion
In this comprehensive guide, we've explored the fundamentals of container orchestration with AWS Elastic Kubernetes Service (EKS). From understanding the basics of containers and their real-world applications in data science and machine learning, to diving deep into the intricacies of AWS services and Kubernetes components, we've covered a lot of ground. The world of container orchestration is complex but incredibly rewarding, offering scalability, maintainability, and cost-effectiveness.
Whether you're a developer, a data scientist, or an IT professional, mastering container orchestration will undoubtedly be a valuable skill in your toolkit. As businesses continue to migrate to cloud-based solutions and adopt microservices architectures, the demand for professionals with expertise in these areas is only going to grow.
Ready to put your knowledge into practice? DataCamp offers a range of courses that can help you deepen your understanding of Kubernetes, Docker, and cloud computing. From beginner to advanced levels, you'll find interactive lessons, real-world challenges, and expert-led tutorials to enhance your skills.
- Introduction to Docker
- Machine Learning, Pipelines, Deployment and MLOps Tutorial
- AWS Cloud Concepts Course
Useful links
- Kubectl cheat sheet with the most commonly used commands
- HPA tutorial explains the HPA and walks you through an application with managed scaling
- Cluster autoscaler tutorial to setup and run a simple application with cluster autoscaling
- Helm charts
- AWS pricing calculator



