The state of data-driven digital transformation
As organizations undergo accelerated digital transformations amid the COVID-19 pandemic, the case for leveraging data, machine learning and analytics has never been more important.
The 2020 McKinsey Global Survey on the State of Artificial Intelligence reported that 50% of businesses have adopted artificial intelligence in at least one business function, and 22% of organizations attribute at least 5% of earnings before interest and tax to artificial intelligence initiatives.
However, in order to unlock the value of data and artificial intelligence at scale, organizations must democratize their data and unlock organization-wide data fluency. One of the ways to do so is by providing access to trusted and actionable data across teams and skill levels so that everyone can make data-informed business decisions.
Data infrastructure at the core of data democratization
Before achieving data fluency, organizations need to get the foundations right. This starts with understanding how data flows through an organization and then building toward an organized and unified data infrastructure.
In a webinar on 2021 data trends and predictions, Ramnath Vaidyanathan, Vice President of Product Research at DataCamp, described how data typically flows through an organization. This flow requires data engineering tools to take in raw data, ingest and transform them, store them in a centralized location, and produce data insights in the form of dashboards and reports, machine learning outputs, and more.
Scaling access to data within the organization depends heavily on the presence of a solid data infrastructure architecture and the use of the latest data infrastructure tooling, which enables organizations to transform raw data into accessible and valuable data insights.
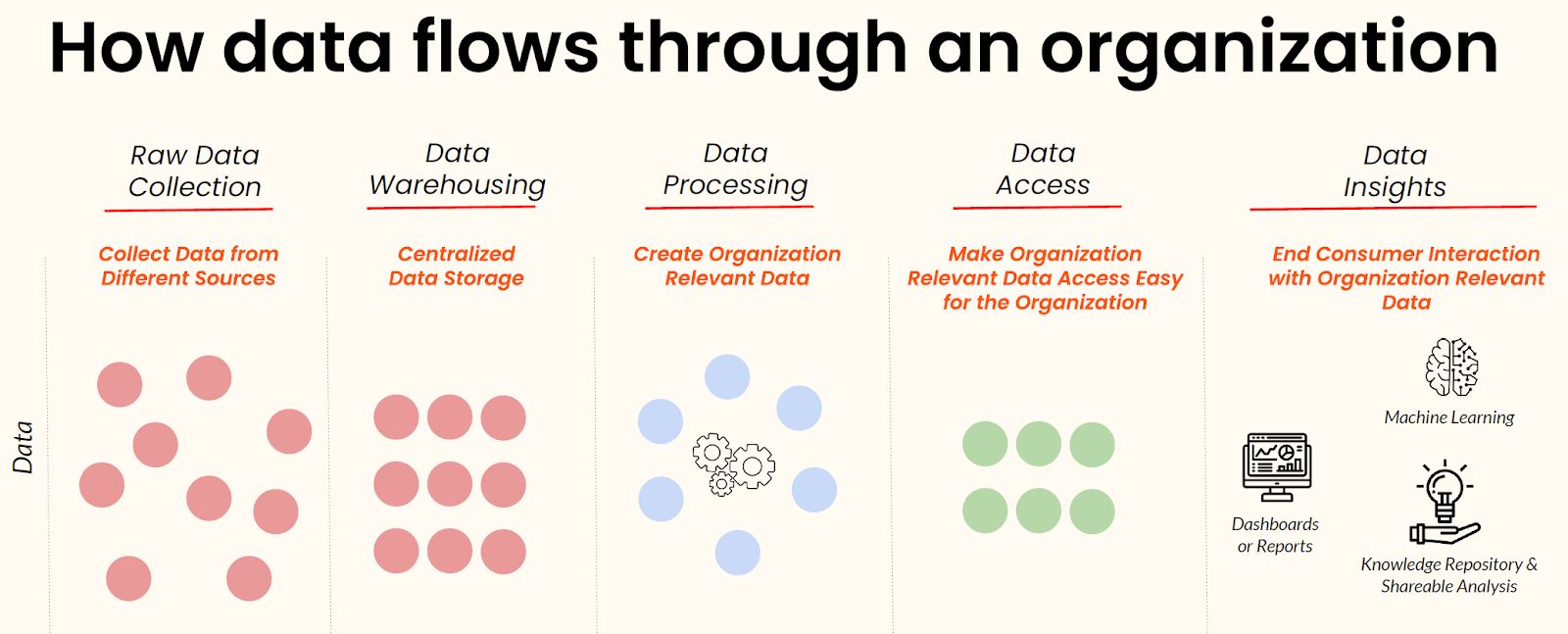
The state of data infrastructure tooling
The importance of data infrastructure and tooling is evidenced by the rapid growth and evolution of the data infrastructure market. Many solutions are meant to streamline working with a particular element of an organization’s data infrastructure, which has resulted in an increasingly fragmented landscape of tooling that can be challenging to navigate.
The following visual created by Dataiku aptly illustrates how the data infrastructure market has been segmented into numerous granular categories, with an expanding list of competing solutions present within each segment.
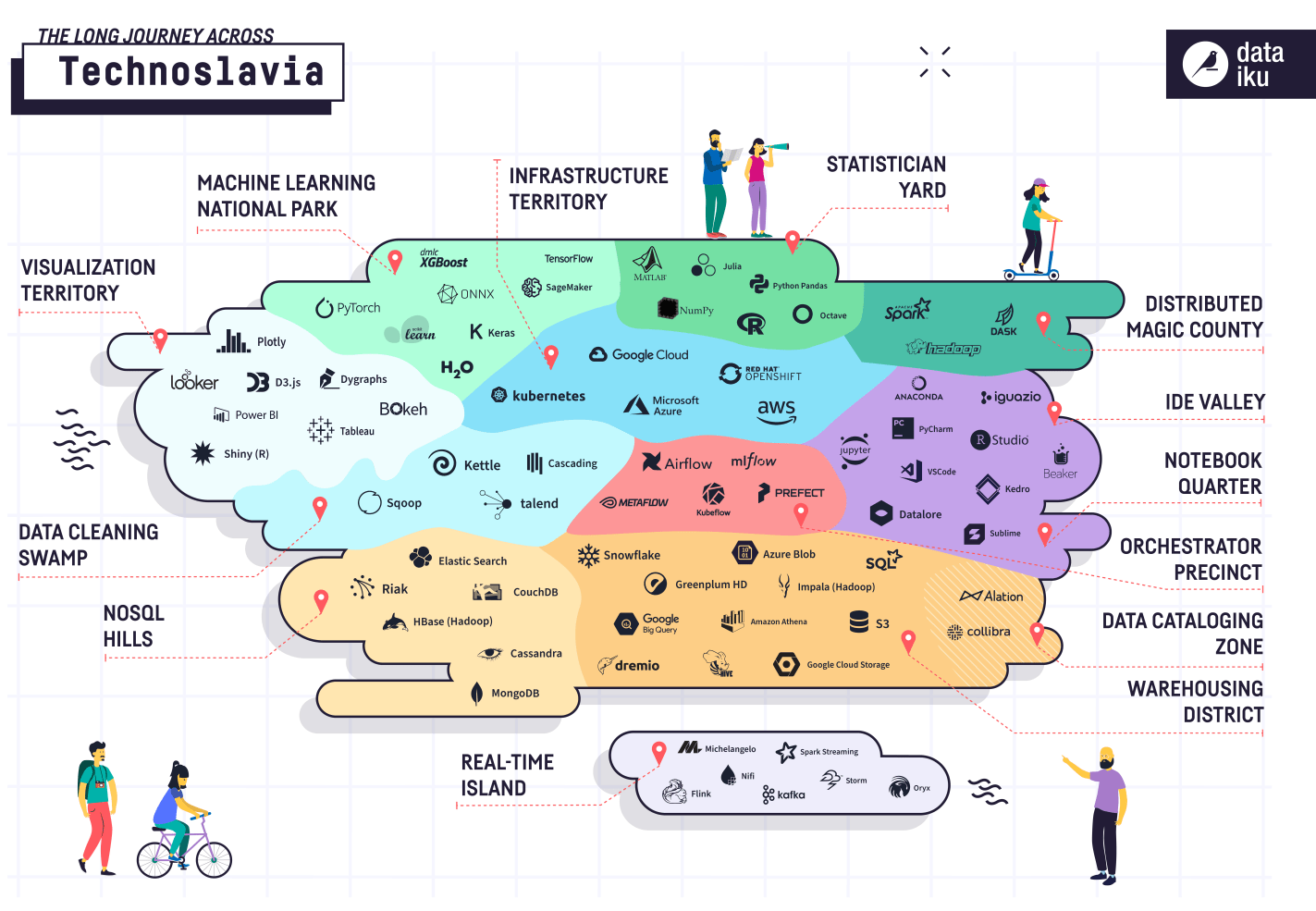
Source: Dataiku
The future of data infrastructure tooling
Late last year, Andreessen Horowitz sought to provide some clarity in this confusing data infrastructure landscape by developing a unified architecture framework. With the growing need to work with large volumes of data and the plethora of available solutions, this framework offers a practical reference when modernizing, mapping, and building an organization’s data stack.
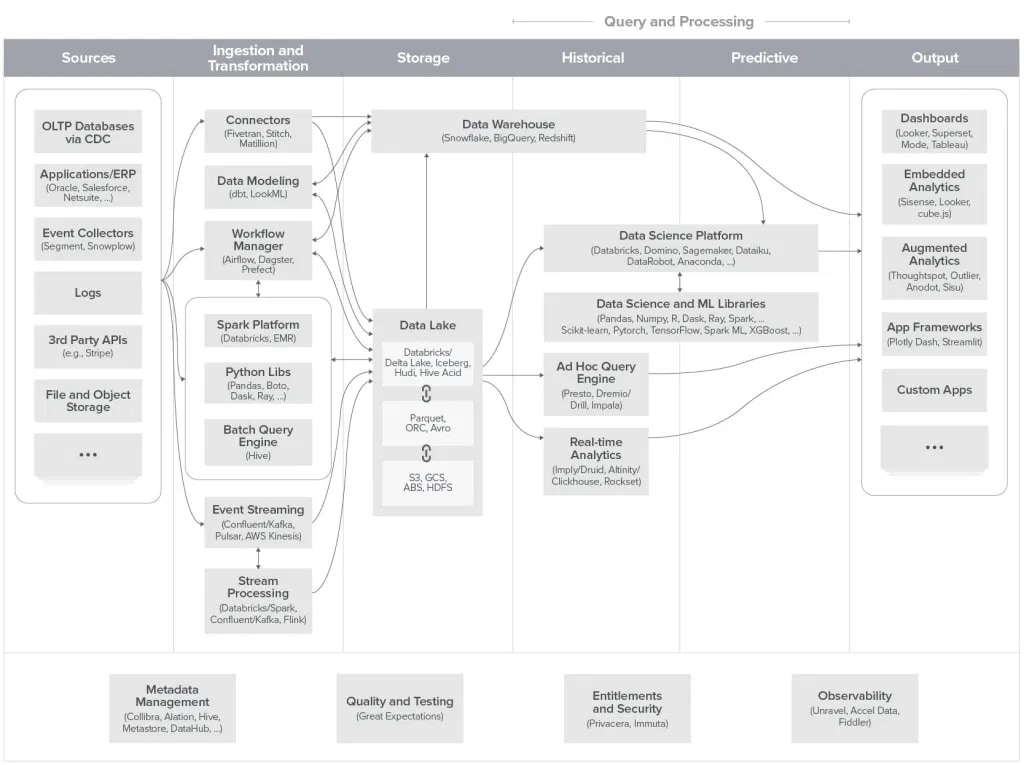
Source: Andreessen Horowitz
As this space and trend evolves, we will see the consolidation and standardization of various tools in the data infrastructure stack. This alongside cloud adoption, data discovery tools, and centralized data governance platforms will allow organizations to provide scalable access to data across teams and functions.
So what does an ideal future data infrastructure deliver? According to Maksim Pecherskiy, Data Engineer at the World Bank and former CDO of the city of San Diego, data must be collected, discoverable, reliable, understood, compliant, and actionable. Ultimately, the goal is to make data usable and trustworthy, which in turn drives organization-wide data fluency.

Mature data infrastructure includes cloud adoption, data discovery tools, and centralized data governance platforms
As data infrastructure tooling matures around data democratization in 2021 and beyond, so will the adoption and growth of the following technologies:
1. Cloud Adoption
The use of cloud technologies is becoming the norm, especially in the wake of the accelerated data-driven digital transformation we’ve seen in 2020.
Besides improving data storage and access, cloud solutions also offer numerous user-friendly products for collecting, ingesting, transforming, storing, and creating insights from data.
There are numerous providers in the cloud platform space, and one of the key players is Amazon Web Services (AWS), which has more than 100 products that enable enterprises to make the most out of their data at high speed, at scale, and at low cost.
2. Data Discovery Tools
Scaling data infrastructure will be crucial as data tables, reports, and models are added to organizational data landscapes. Stakeholders must be readily able to locate reliable, understood, compliant, and actionable data and insights to do their best work.
To tackle this challenge, (also referred to as metadata management tools or data catalogs) can act as versatile search engines for these troves of data within the organization. Metadata essentially refers to a set of data describing the particular data, and is useful for indexing the large variety of data available.
Lyft open-sourced their own data discovery tool Amundsen, to offer metadata engine solutions that aim to help organizations discover, understand, share, and trust the data they use for their analyses. This capability is paramount for any organization looking to scale its data competencies.
3. Centralized Data Governance Platforms
As mentioned earlier, creating trust in data is essential for driving data democratization. This is where data governance plays a major role. With the ever-growing volume and variety of data, centralized oversight of the data quality, consistency, and relevance is crucial.
Centralized data governance platform services offered by companies like Collibra and Alation help organizations effectively manage the availability, consistency, and integrity of their data. This then allows all stakeholders to work from a reliable single source of truth.
A maturing data infrastructure is only one of the data trends we foresee for 2021 and beyond. For more, download our white paper on Data Trends and Predictions 2021: The Year of Data Fluency or watch our webinar.


