
Track
AI Fundamentals
10 hr
According to Meta’s examples, the models can analyze charts embedded in documents and summarize key trends. They can also interpret maps, determine which part of a hiking trail is the steepest, or calculate the distance between two points.
This integration of text and image reasoning offers a wide range of potential applications, including:
Llama 3.2’s vision models are open and customizable. Developers can fine-tune both pre-trained and aligned versions of these models using Meta’s Torchtune framework.
Moreover, these models can be deployed locally via Torchchat, reducing reliance on cloud infrastructure and providing a solution for developers looking to deploy AI systems on-prem or in resource-constrained environments.
The vision models are also available for testing through Meta AI, Meta’s intelligent assistant.
To enable the Llama 3.2 vision models to understand both text and images, Meta integrated a pre-trained image encoder into the existing language model using special adapters. These adapters link image data with the text processing parts of the model, allowing it to handle both types of input.
The training process started with the Llama 3.1 language model. First, the team trained it on large sets of images paired with text descriptions to teach the model how to connect the two. Then, they refined it using cleaner, more specific data to improve its ability to understand and reason over visual content.
In the final stages, Meta used techniques like fine-tuning and synthetic data generation to ensure the model gives helpful answers and behaves safely.
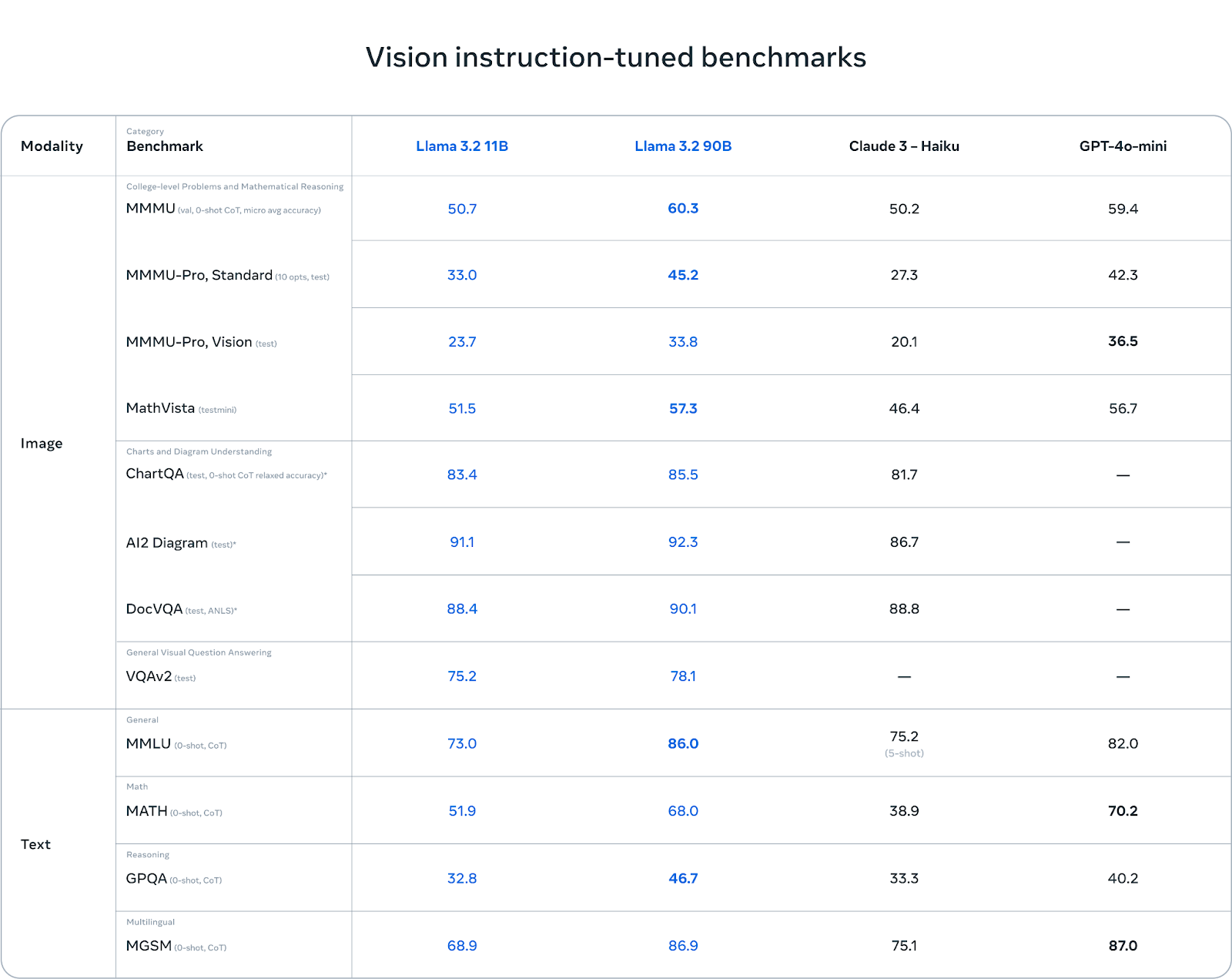
The Llama 3.2 vision models shine in chart and diagram understanding. In benchmarks like AI2 Diagram (92.3) and DocVQA (90.1), Llama 3.2 outperforms Claude 3 Haiku. This makes it an excellent choice for tasks involving document-level understanding, visual question answering, and data extraction from charts.
In multilingual tasks (MGSM), Llama 3.2 also performs well, nearly matching GPT-4o-mini with a score of 86.9, making it a solid option for developers working with multiple languages.
Source: Meta AI
While Llama 3.2 performs well in vision-based tasks, it faces challenges in other areas. In MMMU-Pro Vision, which tests mathematical reasoning over visual data, GPT-4o-mini outperforms Llama 3.2 with a score of 36.5 compared to Llama’s 33.8.
Similarly, in the MATH benchmark, GPT-4o-mini’s performance (70.2) significantly surpasses Llama 3.2 (51.9), showing that Llama still has room for improvement in mathematical reasoning tasks.
Another significant advancement in Llama 3.2 is the introduction of lightweight models designed for edge and mobile devices. These models, with 1 billion and 3 billion parameters, are optimized to run on smaller hardware while maintaining a reasonable compromise on performance.
These models are designed to run on mobile devices, providing fast, local processing without the need to send data to the cloud. Running models locally on edge devices offers two main benefits:
Llama 3.2’s lightweight models are optimized for Arm processors and are enabled on Qualcomm and MediaTek hardware, which power many mobile and edge devices today.
The lightweight models are designed for a variety of practical, on-device applications, such as:
1. Summarization: Users can summarize large amounts of text, such as emails or meeting notes, directly on their device without relying on cloud services.
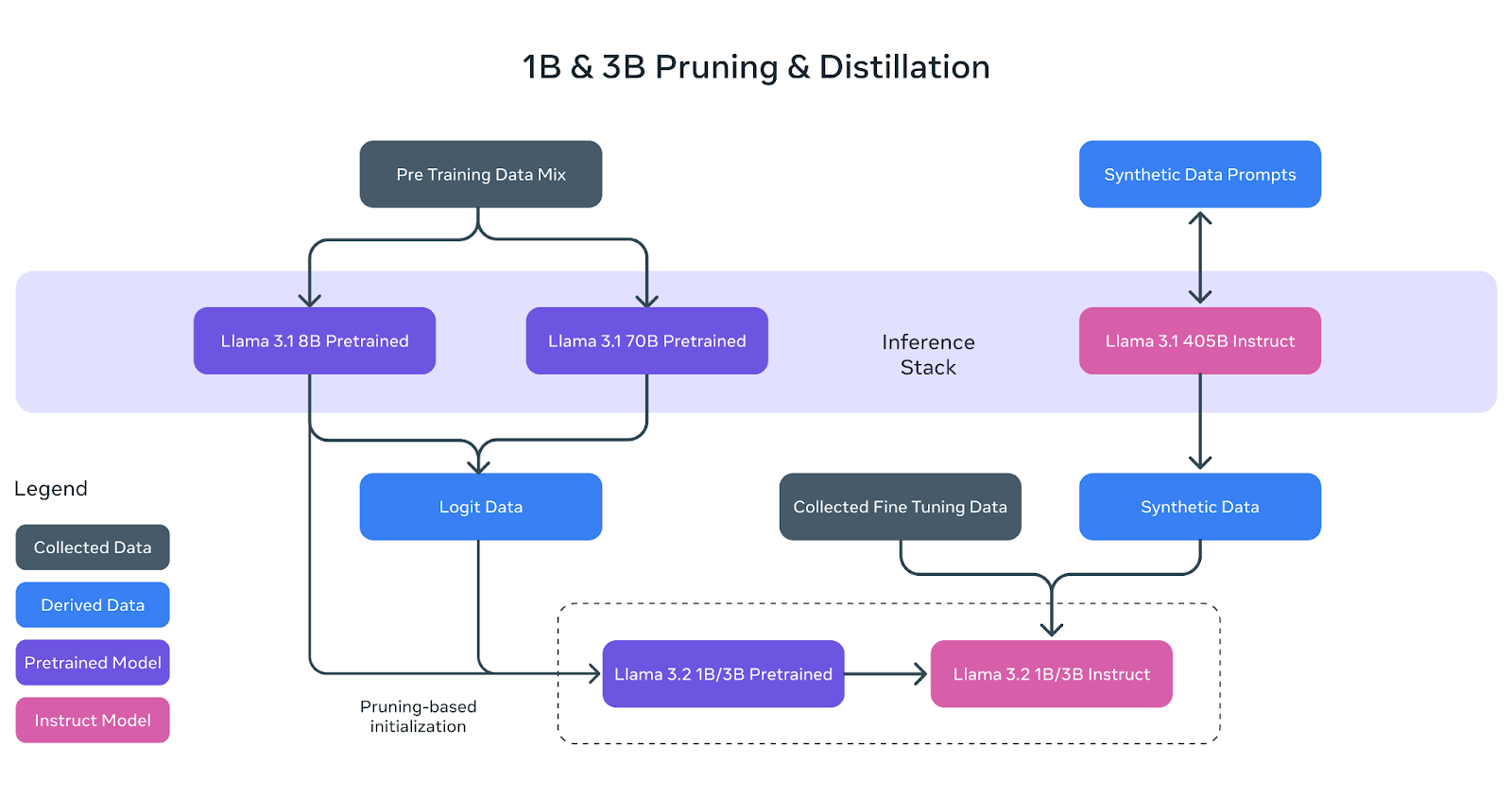
The Llama 3.2 lightweight models (1B and 3B) were built to fit efficiently on mobile and edge devices while maintaining strong performance. To achieve this, Meta used two key techniques: pruning and distillation.
Source: Meta AI
Pruning helps reduce the size of the original Llama models by removing less critical parts of the network while retaining as much knowledge as possible. In the case of Llama 3.2’s 1B and 3B models, this process started with the larger Llama 3.1 8B pre-trained model.
By systematically pruning, the Meta AI team was able to create smaller, more efficient versions of the model without significant loss of performance. This is represented in the diagram above where the 8B pre-trained model (purple box) is pruned and refined to become the base for the smaller Llama 3.2 1B/3B models.
Distillation is the process of transferring knowledge from a larger, more powerful model (the “teacher”) to a smaller model (the “student”). In Llama 3.2, logits (predictions) from the larger Llama 3.1 8B and Llama 3.1 70B models were used to teach the smaller models.
This way, the smaller 1B and 3B models could learn to perform tasks more effectively, despite their reduced size. The diagram above shows how this process uses logits data from the larger models to guide the 1B and 3B models during pre-training.
After pruning and distillation, the 1B and 3B models underwent post-training, similar to previous Llama models. This involved techniques like supervised fine-tuning, rejection sampling, and direct preference optimization to align the models’ outputs with user expectations.
Synthetic data was also generated to ensure the models could handle a wide range of tasks, such as summarization, rewriting, and instruction following.
As shown in the diagram, the final Llama 3.2 1B/3B instruct models are the result of pruning, distillation, and extensive post-training.
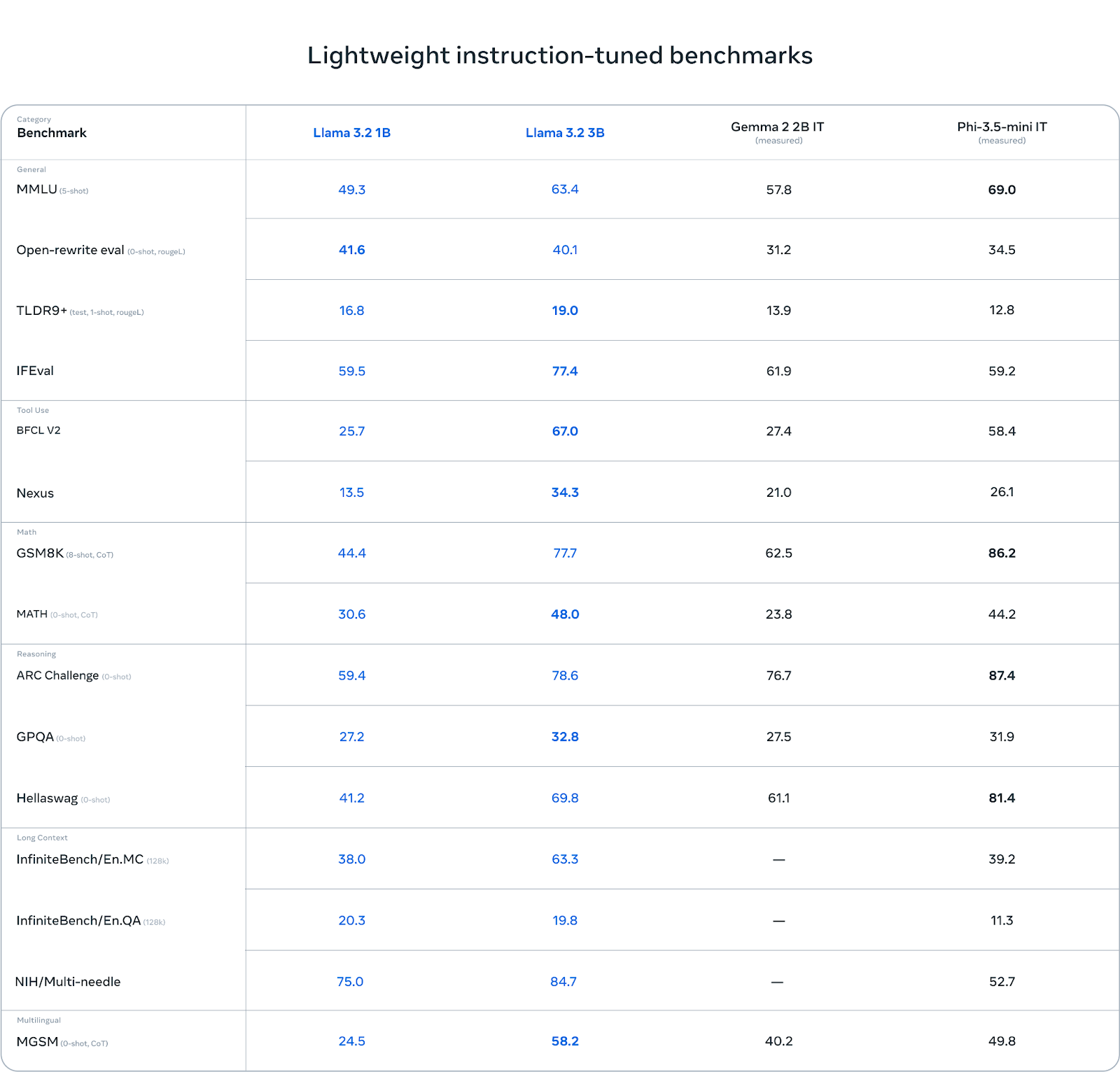
Llama 3.2 3B stands out in certain categories, especially in tasks involving reasoning. For example, in the ARC Challenge, it scores 78.6, outperforming both Gemma (76.7) and trailing slightly behind Phi-3.5-mini (87.4). Similarly, it does well in the Hellawag benchmark, achieving 69.8, beating Gemma, and remaining competitive with Phi.
In tool use tasks like BFCL V2, Llama 3.2 3B also shines with a score of 67.0, ahead of both competitors. This shows that the 3B model handles instruction-following and tool-related tasks effectively.
Source: Meta AI
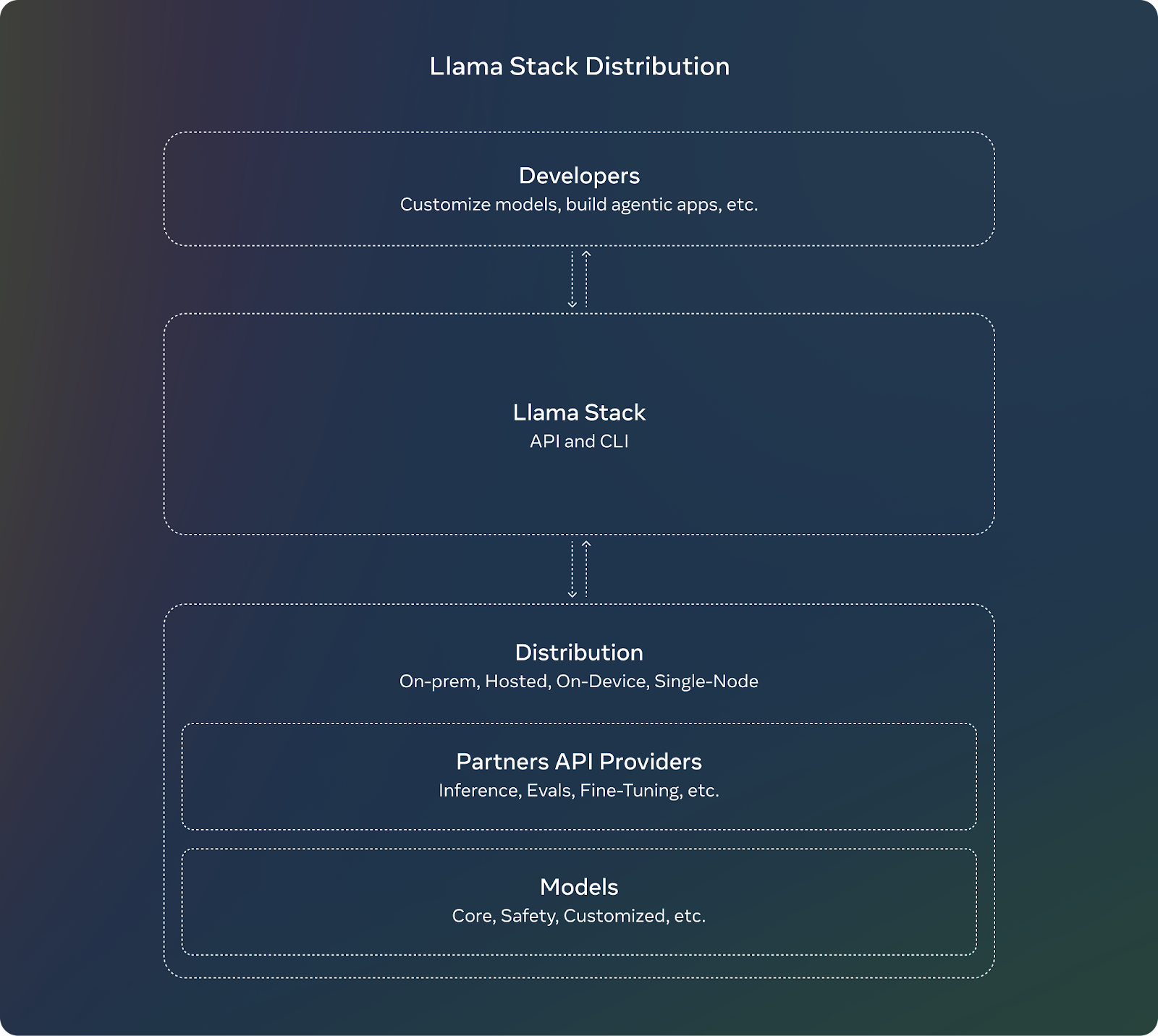
To complement the release of Llama 3.2, Meta is introducing the Llama Stack. For developers, using the Llama Stack means they don’t need to worry about the complex details of setting up or deploying large models. They can focus on building their applications and trust that the Llama Stack will handle much of the heavy lifting.
These are the key features of the Llama Stack:
Source: Meta AI
Meta continues its focus on responsible AI with Llama 3.2. Llama Guard 3 has been updated to include a vision-enabled version that supports the new multimodal capabilities of Llama 3.2. This ensures that applications using the new image understanding features remain safe and compliant with ethical guidelines.
Additionally, Llama Guard 3 1B has been optimized for deployment in more resource-constrained environments, making it smaller and more efficient than previous versions.
Accessing and downloading the Llama 3.2 models is fairly straightforward. Meta has made these models available on multiple platforms, including their own website and Hugging Face, a popular platform for hosting and sharing AI models.
You can download Llama 3.2 models directly from the official Llama website. Meta offers both the smaller, lightweight models (1B and 3B) and the larger vision-enabled models (11B and 90B) for developers to use.
Hugging Face is another platform where Llama 3.2 models are available. It provides easy access and is commonly used by developers in the AI community.
The Llama 3.2 models are available for immediate development on our broad ecosystem of partner platforms, including AMD, AWS, Databricks, Dell, Google Cloud, Groq, IBM, Intel, Microsoft Azure, NVIDIA, Oracle Cloud, Snowflake, and others.
Meta’s release of Llama 3.2 introduces the first multimodal models in the series, focusing on two key areas: vision-enabled models and lightweight models for edge and mobile devices.
The 11B and 90B multimodal models can now handle both text and image processing, while the 1B and 3B models are optimized for efficient local use on smaller devices.
In this article, I’ve laid out the essentials—how these models function, their practical applications, and how you can access them.
Learn AI with these courses!
Track
Course
Course
blog
Alex Olteanu
8 min
blog
Richie Cotton
8 min
blog
Richie Cotton
5 min
Tutorial
Hesam Sheikh Hassani
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt



