
Lernpfad
Ingenieur für maschinelles Lernen
44 Std.
Ein neuronales Netzwerk, das einfach nicht konvergieren will, bei dem der Verlust flach bleibt und die Gradienten entweder verschwinden oder explodieren, hat oft überhaupt kein Problem mit seiner Architektur. Das Problem ist oft viel einfacher: Eingabefunktionen, die auf völlig unterschiedlichen Skalen liegen, wobei eine Spalte von 0 bis 1 reicht, während eine andere bis in die Zehntausende reicht.
Meiner Erfahrung nach taucht dieses Muster in der Praxis ständig auf. Fünf Minuten Vorverarbeitung können das lösen, was tagelanges Hyperparameter-Tuning nicht geschafft hat.
In diesem Tutorial zeige ich dir, wie du Daten normalisierst. Ich zeig dir verschiedene Normalisierungstechniken und wann man sie anwendet, inklusive Python-Implementierungen. Außerdem lernst du, welche Fehler und Missverständnisse oft passieren und wie du sie vermeiden kannst.
Wenn du mehr darüber erfahren möchtest, wie man Daten für Algorithmen des maschinellen Lernens vorbereitet, empfehle ich dir unseren Kurs „Vorverarbeitung für maschinelles Lernen in Python” zu machen.
Datennormalisierung ist der Prozess, bei dem numerische Merkmale so umgewandelt werden, dass sie vergleichbare Bereiche abdecken oder einer einheitlichen Skala folgen.
Der Begriff hat je nach Kontext unterschiedliche Bedeutungen: Im maschinellen Lernen geht's meistens darum, Merkmalswerte neu zu skalieren, damit die Größe nicht die Wichtigkeit bestimmt, während es beim Datenbankdesign darum geht, Tabellen so zu organisieren, dass Redundanzen vermieden werden.
Ich werde mich hauptsächlich auf die Bedeutung des maschinellen Lernens konzentrieren, aber später kurz auf die Datenbanknormalisierung eingehen, um die Überschneidungen im Vokabular zu klären.
Wenn Merkmale auf verschiedenen Skalen vorkommen, geben manche Algorithmen den Werten, die gerade größer sind, ein übertriebenes Gewicht.
Ein Merkmal, das das Einkommen in Tausend misst, wird eines dominieren, das das Alter in Jahrzehnten misst, nicht weil das Einkommen für die Vorhersage wichtiger ist, sondern einfach weil die Zahlen größer sind. Durch die Normalisierung werden Merkmale gleich behandelt, damit das Modell lernen kann, welche wirklich wichtig sind.
Neben dem Modelltraining hilft die Normalisierung auch bei:
Also, was ist der Unterschied zwischen Normalisierung, Skalierung und Standardisierung? Diese drei Begriffe tauchen oft in Dokumentationen auf und werden häufig synonym benutzt, obwohl sie unterschiedliche Bedeutungen haben.
Der praktische Unterschied ist, ob dein Modell Werte innerhalb bestimmter Grenzen braucht. Die Min-Max-Normalisierung sorgt für Grenzen, die Standardisierung nicht. Die folgende Tabelle zeigt die Unterschiede:
Für einen tiefergehenden Vergleich, wann jeder Ansatz nach hinten losgeht, check unseren Blogbeitrag „ : Normalisierung vs. Standardisierung erklärt erklärt die Sonderfälle gut.
Nachdem wir jetzt die Begriffe geklärt haben, schauen wir uns ein paar typische Anwendungsfälle an. Die Normalisierung kann je nach Situation ganz unterschiedlich nützlich sein, von der Verbesserung der Dynamik beim Modelltraining bis hin zu sinnvollen Vergleichen zwischen verschiedenen Datenquellen.
Neuronale Netze und logistische Regression aktualisieren Gewichte durch Gradientenabstieg, wobei der Beitrag jedes Merkmals zum Vorhersagefehler bestimmt, wie stark das entsprechende Gewicht angepasst wird.
Wenn sich die Größen der Merkmale stark unterscheiden, tun das auch die resultierenden Gradienten: Große Merkmale erzeugen große Gradienten, kleine Merkmale erzeugen kleine Gradienten. Dieses Ungleichgewicht führt dazu, dass der Optimierer in manchen Richtungen große Schritte macht, während er sich in anderen kaum bewegt, was zu instabilem Training oder gar keiner Konvergenz führt.
Entfernungsbasierte Algorithmen wie kNN und K-Means haben ein ähnliches Problem. Sie berechnen die Ähnlichkeit mithilfe von Distanzmetriken, typischerweise der euklidischen Distanz, wobei größere numerische Werte allein aufgrund ihrer Größe stärker in die Berechnung einfließen. Ein Merkmal von 0 bis 10.000 wird ein Merkmal von 0 bis 1 übertrumpfen, egal welches Merkmal für die Vorhersage wirklich wichtig ist.
Durch Skalierung wird sichergestellt, dass alle Merkmale proportional zu ihrem tatsächlichen Vorhersagewert beitragen und nicht zu ihrem willkürlichen numerischen Bereich.
Wenn man zusammengesetzte Werte erstellt oder Messungen mit unterschiedlichen Einheiten kombiniert, können Rohwerte zu irreführenden Vergleichen führen.
Eine Kennzahl zur Kundenzufriedenheit, die die monatlichen Ausgaben in Dollar, die Anzahl der Logins und das Alter des Kontos in Tagen zusammenfasst, wird den Dollarbeträgen mehr Gewicht geben, einfach weil diese Zahlen zufällig größer sind.
Durch die Normalisierung kannst du diese Messungen so zusammenfassen, dass sie ihre tatsächliche Bedeutung widerspiegeln und nicht nur ihre zufällige Größe.
Das gilt auch für die explorative Analyse und Visualisierung. Das Zeichnen von Merkmalen in verschiedenen Maßstäben macht es schwieriger, Muster zu erkennen oder Verteilungen zu vergleichen. Normalisierte Daten zeigen besser, wie die Features miteinander hängen.
Produktionspipelines beziehen ihre Daten oft aus mehreren Quellen mit unterschiedlichen Konventionen. Der Umsatz kann in einem System in Dollar und in einem anderen in Tausend angegeben werden. Daten werden in einer API als Unix-Zeitstempel und in einer anderen als formatierte Zeichenfolgen angezeigt.
Wenn du vor der Weiterverarbeitung eine einheitliche Skala und ein einheitliches Format festlegst, vermeidest du kleine Fehler, die später schwer zu finden sind.
In Datenbankkontexten hat Normalisierung eine andere, aber ähnliche Bedeutung: Tabellen so organisieren, dass jede Information genau an einem Ort gespeichert ist.
Das verhindert Probleme bei der Aktualisierung, wo das Ändern eines Werts an einer Stelle zu widersprüchlichen Werten an anderen Stellen führt. Auch wenn die Techniken sich von der Feature-Skalierung unterscheiden, ist der Grund dafür ähnlich: Daten konsistent und vorhersehbar halten.
Jeder Normalisierungsansatz geht von unterschiedlichen Annahmen über deine Daten aus und führt zu unterschiedlichen Ausgabemerkmalen. Die richtige Wahl hängt davon ab, wie deine Daten verteilt sind, ob es Ausreißer gibt und was dein nachgelagertes Modell erwartet.
Bei der Min-Max-Normalisierung werden Werte auf einen festen Bereich komprimiert, normalerweise von 0 bis 1, indem man das Minimum abzieht und durch den Bereich teilt. Dieser Ansatz behält die ursprüngliche Verteilungsform bei und stellt gleichzeitig sicher, dass alle Werte innerhalb bekannter Grenzen liegen.
So geht's: Zieh das Minimum ab und teil durch den Bereich. Das ist es.
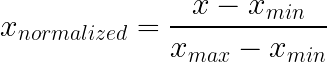
Was es macht:
Am besten geeignet für:
Was du beachten solltest:
Ausreißer können die Min-Max-Normalisierung komplett kaputt machen. Stell dir vor, die meisten Daten liegen zwischen 10 und 100, aber ein Wert liegt bei 99.999? Dieser eine Punkt vergrößert deinen Bereich so sehr, dass alles Normale zu einem winzigen Streifen nahe Null zusammengedrückt wird. Eine schlechte Beobachtung, und schon ist das ganze Feature ruiniert.
Überleg dir auch, was passiert, wenn neue Daten außerhalb des Trainingsbereichs liegen. Testwerte, die über dem Trainingsmaximum liegen, führen zu einer Ausgabe über 1. Ob das irgendwas kaputt macht, hängt von deinem Modell ab.
Z-Score-Standardisierung verändert die Daten so, dass der Mittelwert Null und die Standardabweichung Eins ist, ohne dass man feste Grenzen für das Ergebnis festlegen muss. Dieser Ansatz funktioniert gut bei Daten ohne offensichtliche natürliche Grenzen und wird von vielen Algorithmusimplementierungen allgemein angenommen oder empfohlen.
So geht's: Zieh den Mittelwert ab und teil durch die Standardabweichung.
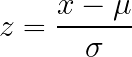
Was es macht:
Am besten geeignet für:
Kompromiss:
Die Interpretierbarkeit leidet darunter. „Diese Beobachtung liegt 1,7 Standardabweichungen über dem Durchschnitt“ ist komplizierter zu verstehen als „das liegt bei 80 % des Bereichs“. Wenn die Beteiligten die skalierten Werte direkt verstehen müssen, könnte Min-Max besser rüberkommen.
Ausreißer blasen immer noch den Mittelwert und die Standardabweichung auf und verzerren die Skalierung für Massendaten, sind aber weniger ein Problem als bei der Min-Max-Normalisierung.
Robuste Skalierung geht die Ausreißersensitivität sowohl des Min-Max- als auch des Z-Score-Ansatzes an, indem sie Median und Interquartilsabstand (IQR) anstelle von Mittelwert und Standardabweichung. Diese Statistiken bleiben stabil, egal wie extrem die Werte an den Rändern deiner Verteilung sind.
So geht's: Zieh den Median ab und teil durch den IQR (Unterschied zwischen dem 25. und 75. Perzentil).
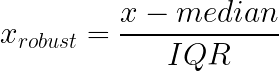
Was es macht:
Am besten geeignet für:
Warum das bei verzerrten Daten hilft:
Die Einkommensverteilung ist ein gutes Beispiel dafür. Die meisten Leute verdienen ganz normal, und ein paar verdienen echt viel: eine klassische rechtsverschobene Verteilung. Die Standardabweichung wird durch die Leute mit hohen Einkommen aufgebläht, was die Standardisierung für die meisten Beobachtungen weniger nützlich macht. Median und IQR bleiben trotzdem in der Mitte der Verteilung.
Die Normalisierung nach der Einheitsnorm (L1/L2) funktioniert anders als die oben genannten Techniken: Anstatt Merkmale (Spalten) zu skalieren, werden in der Regel einzelne Stichproben (Zeilen) skaliert. Jeder Sample-Vektor wird neu skaliert, sodass seine Länge unter einer gewählten Norm (oft L2) 1 ist. Dadurch wird die Gesamtgröße entfernt und nur die Richtung/die Proportionen bleiben erhalten.
Verwechsle das nicht mit der L1/L2-Regulierung. Regularisierung (Lasso/Ridge): Die Regularisierung ändert das Trainingsziel, indem sie eine Strafe auf die Modellgewichte legt, um Überanpassung zu reduzieren, und nicht, indem sie die Eingabevektoren neu skaliert.
So geht's: Bei der L2-Normalisierung wird jede Zeile durch ihre euklidische Norm geteilt, sodass die quadrierten Werte zusammen eins ergeben. L1 nimmt stattdessen die Summe der absoluten Werte.
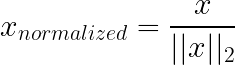
Was es macht:
Am besten geeignet für:
Nicht nützlich für:
Situationen, in denen es wirklich auf die Größe ankommt. Wenn die Gesamtwortzahl für deine Aufgabe wichtig ist, geht durch die Normalisierung Information verloren.
Datenbanknormalisierung heißt, relationale Tabellen neu zu ordnen, um Redundanzen zu vermeiden und die Datenintegrität zu verbessern – zum Beispiel, indem man sicherstellt, dass die E-Mail-Adresse eines Kunden nur an einer Stelle gespeichert wird und nicht in jedem Bestelldatensatz wiederholt wird.
Es hat nichts mit der Skalierung von Funktionen zu tun.
Der Begriff überschneidet sich einfach. Beim maschinellen Lernen geht es bei der „Normalisierung“ meistens darum, Zahlenwerte zu skalieren. Im Bereich Data Engineering oder SQL geht's darum, Strukturen von Tabellen zu organisieren (oft als 1NF, 2NF oder 3NF bezeichnet).
Wichtigster Unterschied:
Wenn ein Dateningenieur dich bittet, „die Datenbank zu normalisieren“, will er, dass du die Struktur der Tabellen korrigierst und nicht „ MinMaxScaler “ ausführst.
Wenn du mehr wissen willst, schau dir diesen Leitfaden zur Datenbanknormalisierung in SQL.
Um die Normalisierung richtig hinzukriegen, muss man auf die Reihenfolge der Schritte achten, vor allem bei der Aufteilung in Trainings- und Testdaten. Der Code selbst ist einfach, aber kleine Fehler in der Reihenfolge können deine ganze Auswertung zunichte machen.
Scikit-learn gibt dir die Skalierer, aber die Hauptregel ist eher prozedural als mathematisch: zuerst teilen, nur auf das Training anpassen und dann den angepassten Transformator überall sonst wiederverwenden.
Wieso die ganze Aufregung? Weil die Skalierung Zahlen aus Daten lernt: Min/Max, Mittelwert/Standardabweichung, Median/IQR. Wenn diese Zahlen mit dem Testsatz berechnet werden, hast du stillschweigend zukünftige Informationen in das Training einfließen lassen. Nichts stürzt ab, aber deine Metriken haben einfach nicht mehr die Bedeutung, die du ihnen gibst.
Ein kleines Beispiel:
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
from sklearn.model_selection import train_test_split
# Example data
data = pd.DataFrame({
'age': [25, 32, 47, 51, 62, 28, 35, 44],
'income': [30000, 45000, 72000, 85000, 120000, 38000, 55000, 67000],
'score': [0.2, 0.5, 0.7, 0.4, 0.9, 0.3, 0.6, 0.8]
})
# Split happens before any scaling
train_data, test_data = train_test_split(data, test_size=0.25, random_state=42)An dieser Stelle siehst du den Trainingssplit als „das Bild, wie die Welt aussah, als ich das Modell erstellt habe“. Der Test-Split besteht aus „neuen, unbekannten Daten“. Dein Scaler muss die Welt nur vom ersten lernen.
Die Min-Max-Standardisierung ist ziemlich einfach: Sie speichert das Trainingsminimum und -maximum für jede Spalte und wendet dann später dieselbe Zuordnung an.
scaler = MinMaxScaler()
scaler.fit(train_data) # training only
train_scaled = scaler.transform(train_data)
test_scaled = scaler.transform(test_data)Wenn du dich dabei erwischst, wie du „ fit() “ auf dem Testsatz sagst, halt kurz inne. Das macht den ganzen Sinn eines Tests irgendwie zunichte.
StandardScaler Speichert den Mittelwert und die Standardabweichung aus dem Trainingssatz und nutzt dann dieselben Werte, um sowohl das Training als auch den Test zu transformieren.
scaler = StandardScaler()
scaler.fit(train_data)
train_standardized = scaler.transform(train_data)
test_standardized = scaler.transform(test_data)Das ist der Typ, der leise kaputtgeht, wenn was schiefgeht, weil man den Mittelwert und die Standardabweichung leicht „stabilisieren“ kann, indem man aus Versehen mehr Daten nimmt, als man sollte.
RobustScaler macht das Gleiche wie „einmal anpassen, immer wieder verwenden“, nutzt aber Median und IQR, sodass ein paar extreme Punkte nicht die Skala bestimmen.
scaler = RobustScaler()
scaler.fit(train_data)
train_robust = scaler.transform(train_data)
test_robust = scaler.transform(test_data)Ein praktischer Hinweis darauf, dass sich eine robuste Skalierung lohnt: Du hast einen Long Tail, den du wirklich behalten möchtest (Zahlungen, Ansprüche, Sensorspitzen), und du willst nicht, dass ein einziger seltsamer Tag den Rest der Funktion fast auf Null drückt.
Für schnelle Erkundungen ist es okay, die Berechnungen direkt in Pandas zu machen, solange du ehrlich bist, was du tust: Das ist zum Anschauen von Verteilungen, nicht zum Bewerten von Modellen.
# Min-max
df_minmax = (data - data.min()) / (data.max() - data.min())
# Z-score
df_zscore = (data - data.mean()) / data.std()Vorsicht: Die Statistiken basieren auf dem gesamten Datensatz. Mach das vor dem Teilen, und die Testwerte beeinflussen die Umwandlung. Deine Bewertung verliert an Bedeutung, weil bei der Vorverarbeitung bereits Antworten eingesehen wurden, die nicht hätten eingesehen werden dürfen.
Das Leckmuster sieht normalerweise so aus:
So machst du es nicht:
scaler = MinMaxScaler()
scaled_all = scaler.fit_transform(full_data) # problem
train, test = split(scaled_all)Bei diesem Ansatz werden die Daten vor dem Aufteilen normalisiert, sodass die Testdaten die Transformation schon beeinflusst haben.
So machst du es richtig:
Indem wir die Daten zuerst aufteilen, stellen wir sicher, dass der Scaler die Statistiken nur aus dem Trainingssatz lernt und die Testdaten wirklich unbekannt bleiben.
scaler = MinMaxScaler()
scaler.fit(train_data)
train_scaled = scaler.transform(train_data)
test_scaled = scaler.transform(test_data)Gleiche Vorgänge, andere Reihenfolge. Und die Reihenfolge ist das Wichtigste.
Wenn du lieber die End-to-End-Vorverarbeitung üben möchtest (einschließlich korrekter Standardisierung und Vermeidung von Datenverlusten), ist dieser Kurs genau das Richtige für dich: Vorverarbeitung für maschinelles Lernen in Python.
Wie wir schon gesagt haben, gibt's verschiedene Bedeutungen für dasselbe Wort. Hier ist „Normalisierung“ keine numerische Transformation. Es ist eine strukturelle Entscheidung, keine doppelten Fakten mehr zu machen.
Wenn deine Auftragstabelle in jeder Zeile die Spalte „ customer_email “ hat, kannst du das in der Datenbank machen. Die Datenbank kann auch später noch gut mit Widersprüchen klarkommen: eine E-Mail in einer Zeile, eine andere E-Mail in einer anderen Zeile, und keine offensichtliche Möglichkeit, zu wissen, welche davon „echt” ist.
Vor der Normalisierung:
CREATE TABLE orders_denormalized (
order_id INT,
customer_name VARCHAR(100),
customer_email VARCHAR(100),
product_name VARCHAR(100),
product_price DECIMAL(10,2),
quantity INT
);Die Kundendaten werden in jeder Zeile wiederholt. E-Mail-Adressen zu aktualisieren heißt, alle Bestellungen zu suchen und zu ändern.
Nach der Normalisierung:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE products (
product_id INT PRIMARY KEY,
name VARCHAR(100),
price DECIMAL(10,2)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT REFERENCES customers(customer_id),
product_id INT REFERENCES products(product_id),
quantity INT
);Kundeninfos gibt's nur einmal. Abfragen brauchen Verknüpfungen, aber Updates werden an einer Stelle gemacht.
Zum Schluss möchte ich dir einen Entscheidungsrahmen geben, den du nutzen kannst, wenn du dich das nächste Mal fragst, welche Normalisierungstechnik du verwenden sollst.
Die Min-Max-Skalierung klappt am besten, wenn deine Daten bekannte, stabile Grenzen haben, die sich zwischen Training und Einsatz nicht ändern. Pixelwerte liegen immer zwischen 0 und 255. Die Wahrscheinlichkeitswerte können nicht größer als 1 sein. Die Noten für Prüfungen haben festgelegte Mindest- und Höchstwerte.
Dieser Ansatz passt auch, wenn dein Modell wie manche neuronale Netzwerkarchitekturen bestimmte Eingabegrenzen braucht. Vermeide aber die Min-Max-Skalierung, wenn es Ausreißer gibt, weil ein einziger Extremwert alle normalen Beobachtungen in einen engen Bereich um Null herum quetschen kann.
Standardisierung ist eine vernünftige Standardoption, wenn du keine klaren Annahmen über die Grenzen oder die Verteilung deiner Daten hast. Das funktioniert gut bei Merkmalen mit unterschiedlichen Bereichen, unbekannten Grenzen oder ungefähr glockenförmigen Verteilungen.
Viele Algorithmus-Implementierungen gehen von standardisierten Eingaben aus oder empfehlen diese, darunter die meisten Frameworks für neuronale Netze und Bibliotheken für logistische Regression. Wenn du dir nicht sicher bist, welchen Ansatz du wählen sollst, und deine Daten keine offensichtlichen natürlichen Grenzen haben, ist die Standardisierung normalerweise eine sichere Wahl.
Robuste Skalierung ist die richtige Wahl, wenn deine Daten erhebliche Ausreißer enthalten, die legitime Werte und keine Fehler darstellen. Finanztransaktionsdaten haben meistens diese Eigenschaft: Die meisten Einkäufe sind klein, aber ab und zu gibt's auch mal große Beträge, die echt sind und im Datensatz bleiben sollten.
Einkommensverteilungen, Sensorwerte mit gelegentlichen Spitzen und alle Daten mit starker Verzerrung oder langen Schwänzen profitieren von einer robusten Skalierung. Der Median und der Interquartilsabstand bleiben an den Großteil deiner Verteilung gebunden, egal was an den Extremen passiert.
Baumbasierte Modelle wie Random Forests, XGBoost und Gradient Boosted Trees teilen sich nach Schwellenwerten auf und berechnen nie Abstände oder Gradienten zwischen Merkmalen. Die Skalierung ist für sie nicht sichtbar, daher macht die Normalisierung die Sache nur komplizierter, ohne dass es einen Vorteil bringt.
One-Hot-codierte Merkmale sind schon binär (0en und 1en), also bringt es nichts, sie zu skalieren. Nur kategoriale Datensätze gehören zur gleichen Kategorie.
Manchmal funktionieren domänenspezifische Transformationen besser als allgemeine Normalisierung:
Hier ist ein Überblick über die Techniken und ihre Anwendungsfälle:
Skalierungsunterschiede machen Modellen, die sich darum kümmern, echt Probleme. Entfernungsmetriken bevorzugen Merkmale mit großer Ausdehnung. Der Gradientenabstieg hat Probleme, wenn die Gradienten mehrere Größenordnungen umfassen. Das Training bleibt stehen oder geht voll daneben, und man kann nicht einfach aus dem Code oder der Architektur erkennen, warum.
Die Normalisierung kümmert sich darum. Verwende die Min-Max-Normalisierung für begrenzte Daten, robuste Skalierung, wenn Ausreißer echt sind und nicht entfernt werden können, und Standardisierung als vernünftige Standardeinstellung. Die Mechanik ist einfach: Trainier dich fit und wende das Gelernte überall konsequent an.
Meiner Erfahrung nach kostet es Zeit, wenn man nicht erkennt, wann Skalierung wichtig ist, und dann tagelang das Modellverhalten debuggt, obwohl die Lösung eigentlich in der Vorverarbeitung liegt. Oder der umgekehrte Fehler, wie zum Beispiel das reflexartige Anwenden von Skalierung auf Modelle, bei denen das gar nicht nötig ist, was die Komplexität erhöht, ohne dass es was bringt.
Bereit für das nächste Level? Unser umfassendes Angebot Machine Learning Engineer Der Lernpfad führt durch alle Schritte des Machine-Learning-Workflows.
Kurse zur Datennormalisierung
Lernpfad
Kurs
Kurs
Tutorial
Allan Ouko
Tutorial
Moez Ali
Tutorial
Derrick Mwiti
Tutorial
DataCamp Team
Tutorial
Matt Crabtree
