
Programa
Engenheiro de machine learning
44 h
Uma rede neural que não consegue convergir, com perdas estagnadas e gradientes que desaparecem ou explodem, muitas vezes acaba não tendo nenhum problema na sua arquitetura. O problema geralmente é bem mais simples: características de entrada que vivem em escalas totalmente diferentes, onde uma coluna vai de 0 a 1, enquanto outra chega a dezenas de milhares.
Pela minha experiência, esse padrão aparece o tempo todo na prática. Cinco minutos de pré-processamento podem resolver o que dias de ajuste de hiperparâmetros não conseguiram.
Neste tutorial, vou te mostrar como normalizar dados. Vou te mostrar diferentes técnicas de normalização e quando cada uma delas se aplica, incluindo implementações em Python. Além disso, você vai aprender sobre erros e equívocos comuns e como evitá-los.
Se você quiser saber mais sobre como preparar dados para algoritmos de machine learning, recomendo fazer nosso Pré-processamento para Machine Learning em Python .
A normalização de dados é o processo de transformar características numéricas para que elas fiquem em intervalos comparáveis ou sigam uma escala consistente.
O termo tem significados diferentes dependendo do contexto: no machine learning, geralmente significa redimensionar valores de recursos para evitar que a magnitude dite a importância, enquanto no design de banco de dados, refere-se à organização de tabelas para eliminar redundâncias.
Vou me concentrar principalmente no significado de machine learning, embora abordemos brevemente a normalização de bancos de dados mais tarde para esclarecer a sobreposição de vocabulário.
Quando as características estão em escalas diferentes, alguns algoritmos dão um peso maior aos valores que são numericamente maiores.
Uma característica que mede a renda em milhares vai dominar uma que mede a idade em décadas, não porque a renda seja mais importante para a tarefa de previsão, mas simplesmente porque os números são maiores. A normalização coloca as características em pé de igualdade para que o modelo possa aprender quais realmente importam.
Além do treinamento do modelo, a normalização também ajuda a:
Então, qual é a diferença entre normalização, escalonamento e padronização? Esses três termos aparecem bastante na documentação, muitas vezes usados de forma intercambiável, mesmo tendo significados diferentes.
A diferença prática é se o seu modelo precisa de valores dentro de limites específicos. A normalização min-max garante limites, enquanto a padronização não. A tabela a seguir mostra as diferenças:
Para uma comparação mais detalhada sobre quando cada abordagem pode dar errado, confira nosso blog sobre Normalização de vs. Explicação sobre padronização fala bem sobre os casos extremos.
Agora que já definimos os termos, vamos ver alguns casos clássicos de uso. A normalização serve para diferentes fins, dependendo do seu caso de uso, desde melhorar a dinâmica do treinamento do modelo até permitir comparações significativas entre fontes de dados diferentes.
Redes neurais e regressão logística atualizam pesos por meio de descida de gradiente, onde a contribuição de cada característica para o erro de previsão determina o quanto o peso correspondente é ajustado.
Quando as magnitudes das características diferem drasticamente, os gradientes resultantes também diferem: características grandes produzem gradientes grandes, características pequenas produzem gradientes pequenos. Esse desequilíbrio faz com que o otimizador dê passos enormes em algumas direções, enquanto mal se move em outras, levando a um treinamento instável ou à falha total na convergência.
Algoritmos baseados em distância, como kNN e K-means enfrentam um problema parecido. Eles calculam a similaridade usando métricas de distância, normalmente a distância euclidiana, onde valores numéricos maiores contribuem mais para o cálculo simplesmente por serem maiores. Uma característica que vai de 0 a 10.000 vai dominar uma que vai de 0 a 1, não importa qual característica realmente importa para a tarefa de previsão.
A escala garante que todas as características contribuam proporcionalmente para o seu valor preditivo real, em vez de para o seu intervalo numérico arbitrário.
Ao criar pontuações compostas ou juntar medições com unidades diferentes, os valores brutos podem levar a comparações enganosas.
Uma métrica de saúde do cliente que junta os gastos mensais em dólares, a frequência de login como uma contagem e a idade da conta em dias vai dar mais peso aos valores em dólares só porque esses números são maiores.
A normalização permite combinar essas medições de uma forma que reflete sua importância real, em vez de sua magnitude acidental.
Isso também vale para análises exploratórias e visualização. Plotar recursos em diferentes escalas torna mais difícil identificar padrões ou comparar distribuições. Os dados normalizados mostram de forma mais clara como as características se relacionam entre si.
Os pipelines de produção geralmente usam várias fontes de dados com convenções diferentes. A receita pode ser reportada em dólares em um sistema e em milhares em outro. As datas aparecem como carimbos de data/hora Unix em uma API e como strings formatadas em outra.
Definir uma escala e um formato consistentes antes do processamento posterior evita pequenos erros que são difíceis de diagnosticar mais tarde.
Em bancos de dados, a normalização tem um significado diferente, mas relacionado: organizar tabelas de forma que cada informação fique em um único lugar.
Isso evita anomalias de atualização, em que a alteração de um valor em um local deixa valores contraditórios em outros locais. Embora as técnicas sejam diferentes do dimensionamento de recursos, a ideia por trás é parecida: manter os dados consistentes e previsíveis.
Cada abordagem de normalização faz suposições diferentes sobre seus dados e produz características de saída diferentes. A escolha certa depende de como seus dados estão distribuídos, se tem valores fora do normal e o que seu modelo a jusante espera.
A normalização min-max comprime os valores em um intervalo fixo, normalmente de 0 a 1, subtraindo o mínimo e dividindo pelo intervalo. Essa abordagem mantém a forma original da distribuição e ainda garante que todos os valores fiquem dentro dos limites conhecidos.
Como funciona: Tira o mínimo e divide pelo intervalo. É isso mesmo.
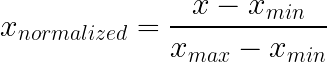
O que faz:
Ideal para:
O que você precisa ficar de olho:
Os valores atípicos podem estragar completamente a normalização min-max. Imagina alguns dados que ficam entre 10 e 100, mas um valor em 99.999? Esse único ponto amplia tanto o seu alcance que tudo o que é normal se comprime em uma pequena fatia próxima de zero. Uma observação ruim, e todo o recurso vai por água abaixo.
Também pense no que rola quando novos dados ficam fora do intervalo de treinamento. Valores de teste além do máximo de treinamento produzem resultados acima de 1. Se isso vai quebrar alguma coisa depende do seu modelo.
Padronização do Z-score transforma os dados de forma que a média seja zero e o desvio padrão seja um, sem impor limites fixos na saída. Essa abordagem funciona bem para dados sem limites naturais óbvios e é amplamente aceita ou recomendada por muitas implementações de algoritmos.
Como funciona: Tira a média e divide pelo desvio padrão.
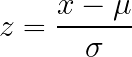
O que faz:
Ideal para:
Compromisso:
A interpretabilidade leva uma pancada. “Essa observação está 1,7 desvios padrão acima da média” exige mais esforço mental do que “isso está em 80% do intervalo”. Se as partes interessadas precisarem entender os valores escalonados diretamente, o min-max pode ser mais fácil de entender.
Os valores atípicos ainda aumentam a média e o desvio padrão, distorcendo a escala dos dados em massa, mas são menos problemáticos do que na normalização min-max.
A escala robusta resolve a sensibilidade aos valores atípicos das abordagens min-max e z-score usando mediana e o intervalo interquartil (IQR) em vez da média e do desvio padrão. Essas estatísticas continuam estáveis, mesmo com valores extremos nas extremidades da sua distribuição.
Como funciona: Tira a mediana, divide pelo IQR (diferença entre o 25º e o 75º percentil).
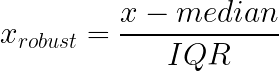
O que faz:
Ideal para:
Por que isso ajuda com dados distorcidos:
A distribuição de renda é um bom exemplo. A maioria das pessoas ganha valores moderados e algumas ganham valores enormes: uma distribuição clássica com inclinação para a direita. O desvio padrão fica inflacionado pelos que ganham muito, o que torna a padronização menos útil para a maioria das observações. A mediana e o intervalo interquartil continuam no meio da distribuição, não importa o que aconteça.
A normalização da norma unitária (L1/L2) funciona de forma diferente das técnicas acima: em vez de dimensionar características (colunas), ela geralmente dimensiona amostras individuais (linhas). Cada vetor de amostra é redimensionado, de modo que seu comprimento seja 1 sob uma norma escolhida (geralmente L2), o que remove a magnitude geral e mantém apenas a direção/proporções.
Não confunda isso com a regularização L1/L2 regularização (Lasso/Ridge): a regularização modifica o objetivo do treinamento adicionando uma penalidade aos pesos do modelo para reduzir o sobreajuste, e não redimensionando os vetores de entrada.
Como funciona: Na normalização L2, cada linha é dividida pela sua norma euclidiana, de modo que os valores ao quadrado somam um. L1 usa a soma dos valores absolutos.
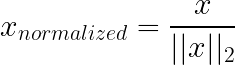
O que faz:
Ideal para:
Não é útil para:
Situações em que a magnitude realmente importa. Se a contagem total de palavras for importante para a sua tarefa, normalizá-la faz com que se perca informação.
A normalização do banco de dados é quando a gente reorganiza as tabelas relacionais pra eliminar redundâncias e melhorar a integridade dos dados — tipo, garantir que o e-mail de um cliente fique guardado só em um lugar, em vez de aparecer repetido em todos os registros de pedidos.
Não tem nada a ver com o dimensionamento de recursos.
O termo simplesmente se sobrepõe. In machine learning, “normalização” quase sempre se refere a escalonar valores numéricos. Na engenharia de dados ou SQL, isso se refere à organização de estruturas de tabelas (frequentemente discutidas como 1NF, 2NF ou 3NF).
Diferença principal:
Se um engenheiro de dados te pedir para “normalizar o banco de dados”, ele quer que você conserte a estrutura da tabela, não que execute um MinMaxScaler.
Para saber mais, dá uma olhada neste guia sobre normalização de banco de dados em SQL.
Para implementar a normalização da maneira certa, é preciso prestar atenção na ordem das operações, principalmente nas divisões entre treinamento e teste. O código em si é simples, mas erros sutis na sequência podem invalidar toda a sua avaliação.
O Scikit-learn te dá os escaladores, mas a regra principal é processual, não matemática: primeiro divida, ajuste apenas no treinamento e, em seguida, reutilize esse transformador ajustado em todos os outros lugares.
Por que tanto alarde? Porque a escala aprende números a partir dos dados: mínimo/máximo, média/desvio padrão, mediana/intervalo interquartil. Se esses números forem calculados usando o conjunto de testes, você acabou deixando informações futuras vazarem para o treinamento. Nada trava, mas suas métricas simplesmente deixam de ter o significado que você acha que elas têm.
Um exemplo simples:
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
from sklearn.model_selection import train_test_split
# Example data
data = pd.DataFrame({
'age': [25, 32, 47, 51, 62, 28, 35, 44],
'income': [30000, 45000, 72000, 85000, 120000, 38000, 55000, 67000],
'score': [0.2, 0.5, 0.7, 0.4, 0.9, 0.3, 0.6, 0.8]
})
# Split happens before any scaling
train_data, test_data = train_test_split(data, test_size=0.25, random_state=42)Nesse ponto, você encara a divisão do treinamento como “como o mundo era quando eu criei o modelo”. A divisão do teste é “dados novos, nunca vistos”. Seu escalador precisa aprender o mundo apenas a partir do primeiro.
A padronização min-max é simples: ela guarda o mínimo e o máximo do treinamento para cada coluna e, depois, aplica o mesmo mapeamento.
scaler = MinMaxScaler()
scaler.fit(train_data) # training only
train_scaled = scaler.transform(train_data)
test_scaled = scaler.transform(test_data)Se você se pegar chamando fit() no conjunto de testes, pare. Isso acaba com o sentido de fazer um teste, né?
StandardScaler armazena a média e o desvio padrão da divisão de treinamento e, em seguida, usa esses mesmos valores para transformar tanto o treinamento quanto o teste.
scaler = StandardScaler()
scaler.fit(train_data)
train_standardized = scaler.transform(train_data)
test_standardized = scaler.transform(test_data)É aquele que quebra silenciosamente quando ocorre um vazamento, porque a média/desvio padrão são fáceis de “estabilizar” usando acidentalmente mais dados do que você deveria.
RobustScaler faz a mesma coisa de “ajustar uma vez, reutilizar para sempre”, mas usa a mediana e o IQR, então alguns pontos extremos não ditam a escala.
scaler = RobustScaler()
scaler.fit(train_data)
train_robust = scaler.transform(train_data)
test_robust = scaler.transform(test_data)Uma dica prática de que vale a pena fazer um escalonamento robusto: você tem uma cauda longa que realmente quer manter (pagamentos, reclamações, picos de sensores) e não quer que um dia estranho reduza o resto do recurso a quase zero.
Para um trabalho exploratório rápido, fazer os cálculos diretamente no pandas é uma boa, desde que você seja sincero sobre o que está fazendo: isso serve para dar uma olhada nas distribuições, não para avaliar modelos.
# Min-max
df_minmax = (data - data.min()) / (data.max() - data.min())
# Z-score
df_zscore = (data - data.mean()) / data.std()Cuidado aqui: as estatísticas são baseadas em todo o conjunto de dados. Faça isso antes de dividir, e os valores de teste influenciam a transformação. Sua avaliação perde o sentido porque o pré-processamento já deu uma espiada nas respostas que não deveria ter visto.
O padrão de vazamento geralmente é assim:
Fazendo da maneira errada:
scaler = MinMaxScaler()
scaled_all = scaler.fit_transform(full_data) # problem
train, test = split(scaled_all)Essa abordagem normaliza os dados antes da divisão, então os dados de teste já influenciaram a transformação.
Fazendo da maneira certa:
Ao dividir os dados primeiro, garantimos que o escalador aprenda estatísticas só a partir do conjunto de treinamento, mantendo os dados de teste realmente ocultos.
scaler = MinMaxScaler()
scaler.fit(train_data)
train_scaled = scaler.transform(train_data)
test_scaled = scaler.transform(test_data)Mesmas operações, ordem diferente. E a ordem é o ponto principal.
Se você prefere praticar o pré-processamento de ponta a ponta (incluindo padronizar corretamente e evitar vazamentos), este curso foi feito pra isso: Pré-processamento para machine learning em Python.
Como falamos antes, temos diferentes significados para a mesma palavra. Aqui, “normalização” não é uma transformação numérica. É uma decisão estrutural para parar de duplicar fatos.
Se a sua tabela de pedidos guarda um customer_email e em cada linha, o banco de dados vai deixar você fazer isso. O banco de dados também aceitará contradições posteriormente: um e-mail em uma linha, um e-mail diferente em outra, sem nenhuma maneira óbvia de saber qual deles é o “verdadeiro”.
Antes da normalização:
CREATE TABLE orders_denormalized (
order_id INT,
customer_name VARCHAR(100),
customer_email VARCHAR(100),
product_name VARCHAR(100),
product_price DECIMAL(10,2),
quantity INT
);Os detalhes do cliente aparecem em todas as linhas. Atualizar o e-mail significa encontrar e modificar todos os pedidos deles.
Depois da normalização:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE products (
product_id INT PRIMARY KEY,
name VARCHAR(100),
price DECIMAL(10,2)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT REFERENCES customers(customer_id),
product_id INT REFERENCES products(product_id),
quantity INT
);As informações do cliente só existem uma vez. As consultas precisam de junções, mas as atualizações rolam num só lugar.
Por fim, quero te dar uma estrutura de decisão para a próxima vez que você se perguntar qual técnica de normalização usar.
A escala mínima-máxima funciona melhor quando seus dados têm limites conhecidos e estáveis que não mudam entre o treinamento e a implantação. Os valores dos pixels sempre ficam entre 0 e 255. As pontuações de probabilidade não podem passar de 1. As notas dos exames têm mínimos e máximos definidos.
Essa abordagem também funciona quando seu modelo espera especificamente entradas limitadas, como acontece com algumas arquiteturas de redes neurais. Mas, evite usar a escala min-max quando tiver valores fora do normal, porque um único valor extremo pode comprimir todas as observações normais em uma faixa estreita perto de zero.
A padronização é uma boa opção padrão quando você não tem muitas certezas sobre os limites ou a distribuição dos seus dados. Funciona bem para características com intervalos variáveis, limites desconhecidos ou distribuições aproximadamente em forma de sino.
Muitas implementações de algoritmos assumem ou recomendam entradas padronizadas, incluindo a maioria das estruturas de redes neurais e bibliotecas de regressão logística. Se você não tem certeza de qual abordagem usar e seus dados não têm limites naturais óbvios, a padronização geralmente é uma escolha segura.
O dimensionamento robusto é a escolha certa quando seus dados têm valores atípicos significativos que são legítimos, e não erros. Os dados de transações financeiras geralmente têm essa característica: a maioria das compras é pequena, mas às vezes tem cobranças grandes que são reais e devem continuar no conjunto de dados.
Distribuições de renda, leituras de sensores com picos ocasionais e quaisquer dados com grande distorção ou caudas longas se beneficiam de um dimensionamento robusto. A mediana e o intervalo interquartil ficam presos à maior parte da sua distribuição, não importa o que aconteça nos extremos.
Modelos baseados em árvores, como florestas aleatórias, XGBoost e árvores impulsionadas por gradiente, dividem-se em valores limite e nunca calculam distâncias ou gradientes entre características. A escala é invisível para eles, então a normalização só adiciona complexidade sem trazer nenhum benefício.
Os recursos codificados como one-hot já são binários (0s e 1s), então escalá-los não traz nada de útil. Os conjuntos de dados apenas categóricos se enquadram na mesma categoria.
Às vezes, as transformações específicas do domínio funcionam melhor do que a normalização genérica:
Aqui está uma visão geral das técnicas e seus casos de uso:
As diferenças de escala causam problemas reais para os modelos que se preocupam com elas. As métricas de distância favorecem características de grande magnitude. O gradiente descendente tem dificuldades quando os gradientes abrangem ordens de magnitude. O treinamento trava ou explode por motivos que não ficam claros só de olhar o código ou a arquitetura.
A normalização resolve isso. Use a normalização min-max para dados limitados, escalonamento robusto quando os outliers são reais e não podem ser removidos e padronização como padrão razoável. A mecânica é simples: encaixe no treinamento, aplique em todos os lugares de forma consistente.
Na minha experiência, o que leva tempo é não perceber quando é importante escalar e depois passar dias a depurar o comportamento do modelo, quando a solução era o pré-processamento. Ou o erro oposto, como aplicar o dimensionamento de forma reflexiva a modelos que não se importam, adicionando complexidade sem benefício.
Pronto pra subir de nível? Nosso abrangente Engenheiro de Machine Learning ensina tudo o que você precisa saber sobre o fluxo de trabalho do machine learning.
Cursos de Normalização de Dados
Programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Kevin Babitz
Tutorial
Avinash Navlani
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan

