Curso
Álgebra Linear para Data Science em R
4 h
21K
Os estudos estatísticos, quer envolvam a determinação de parâmetros populacionais ou a previsão de variáveis dependentes, sempre envolvem alguma incerteza. A causa principal dessa incerteza é o processo de amostragem. Não é realista considerar toda a população ao realizar uma análise estatística. Portanto, é necessário escolher uma amostra representativa, seja para estimar um parâmetro populacional, como a média, ou para criar um modelo de regressão.
Para aprender ou aperfeiçoar esses conceitos básicos, consulte o curso introdutório de estatística do DataCamp.
O valor real do parâmetro da população geralmente não é exatamente igual ao valor estimado da amostra - essa diferença é o erro padrão. Para levar em conta esse erro, é convencional estimar um valor esperado e, em seguida, especificar um intervalo que deverá conter o valor real.
Da mesma forma, os estudos de regressão também se baseiam em amostras aleatórias em vez de toda a população. A relação entre as variáveis dependentes e independentes, conforme estimada pelo estudo de regressão na amostra, não é exatamente igual à verdadeira relação entre essas variáveis em toda a população. Portanto, o valor previsto de um ponto de dados individual não é exatamente igual ao seu valor real. Espera-se que o valor real esteja dentro de algum intervalo do valor previsto.
Este artigo explica o significado dos dois tipos de intervalos e os métodos matemáticos subjacentes usados para calculá-los. Ele discute exemplos práticos de quando você deve usar cada intervalo. Por fim, ele ilustra com exemplos práticos como calcular intervalos de confiança e previsão na linguagem de programação R.
Um intervalo de confiança é o intervalo que se espera, com algum nível de confiança, que contenha o valor verdadeiro de um parâmetro populacional, como a média da população.
Um parâmetro populacional é uma propriedade numérica de toda a população. A média (de toda a população) é um exemplo de um parâmetro populacional. O valor real dos coeficientes de regressão entre duas variáveis é outro exemplo de um parâmetro populacional. A estatística inferencial consiste em estudar os pontos de dados em uma amostra aleatória para estimar um parâmetro populacional.
Suponha, hipoteticamente, que você seja um horticultor ou um produtor de laranjas e queira saber qual é a espessura das laranjeiras quando elas têm 100 dias de idade. É impossível estudar cada laranjeira com 100 dias de idade. Então, você seleciona aleatoriamente algumas árvores com 100 dias de idade e mede a circunferência (espessura) delas. A média dessas medições dá a você a média da amostra. Você deseja usar essa média amostral para obter a média populacional.

Uma população de laranjeiras. Criado usando o DALL-E.
A média da amostra é uma estimativa pontual do parâmetro da população (nesse caso, o parâmetro de interesse é a média). Este curso do DataCamp sobre estatística inferencial discute esses conceitos com mais detalhes.
A média da amostra é representativa da média da população, mas não exatamente igual a ela. Espera-se que a média da população esteja dentro de um determinado intervalo da média da amostra, que é chamado de intervalo de confiança.
A seção anterior explicou os intervalos de confiança na estatística inferencial. A regressão também envolve o uso de intervalos de confiança.
Como exemplo, considere uma variação do mesmo exemplo da laranjeira:
Você faz isso usando uma análise de regressão. O conjunto de dados no qual você executa a regressão é baseado em uma amostra de laranjeiras. Portanto, a média estimada da amostra (circunferência média de laranjeiras com 100 dias de idade) não será exatamente igual à média da população. O valor real da média populacional está dentro de um intervalo de confiança da média amostral estimada.
As seções posteriores mostram e explicam as expressões matemáticas do intervalo de confiança.
Um intervalo de previsão é o intervalo que se espera, com algum nível de confiança, que contenha o valor real de um ponto de dados individual, com base em uma previsão feita por meio de análise de regressão.
Considere outra variação do exemplo de regressão mencionado anteriormente:
Você usa a mesma fórmula de regressão de antes. O valor estimado (ou seja, o valor esperado) da circunferência individual é o mesmo que a circunferência média estimada. No entanto, você deve levar em conta a maior variabilidade dos pontos de dados individuais porque está prevendo um valor individual (e não uma média). Assim, o intervalo de previsão é maior do que o intervalo de confiança.
Mais adiante neste artigo, você verá as fórmulas para esses intervalos e aprenderá a usar o R para calculá-los.
Os dois conceitos - intervalos de previsão e intervalos de confiança - estão intimamente relacionados. A mesma análise pode frequentemente envolver o uso de ambos os tipos de intervalos. Portanto, é útil compará-los frente a frente.
Quando você precisa conhecer um parâmetro populacional, como uma média, você usa uma amostra para estimar esse parâmetro. Como o tamanho da amostra é normalmente muito menor do que a população, a estimativa do parâmetro da amostra é imperfeita. O intervalo de confiança é o intervalo (da estimativa da amostra) que se espera que contenha o parâmetro da população.
Os coeficientes de regressão também são considerados parâmetros populacionais. Como eles são estimados com base em uma amostra (e não em toda a população), alguns erros são incorporados a esses parâmetros. Assim, os coeficientes de regressão também podem ser expressos com um intervalo de confiança.
Além disso, você pode usar a regressão para prever qualquer um deles:
O primeiro usa um intervalo de confiança, e o segundo usa um intervalo de previsão. A seção a seguir explica essa diferença em mais detalhes.
Conforme explicado anteriormente, o intervalo de confiança é proporcional ao desvio padrão e inversamente proporcional ao tamanho da amostra. O intervalo de confiança da média da população, 𝛍, é expresso como:
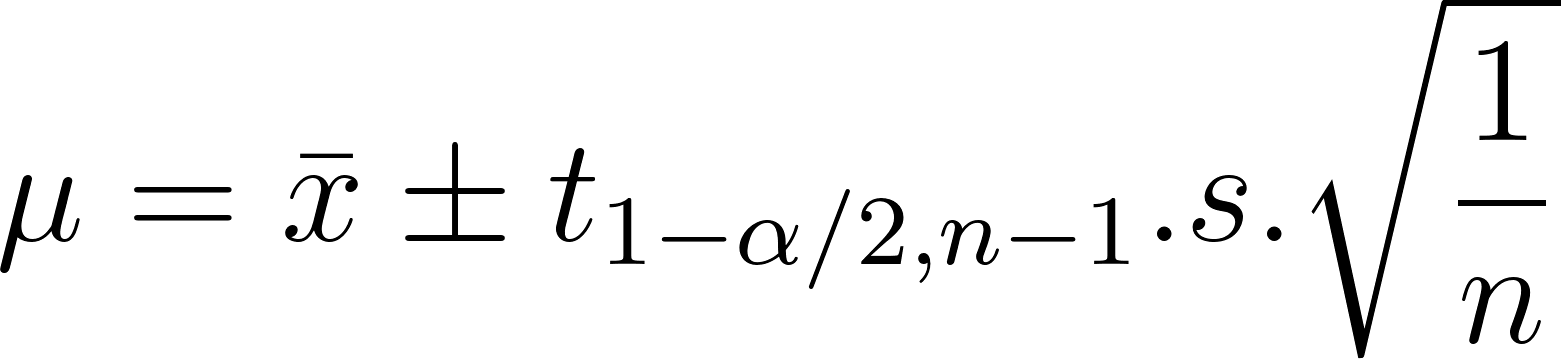
Na expressão acima:
Assim, o intervalo de 𝛍 é:
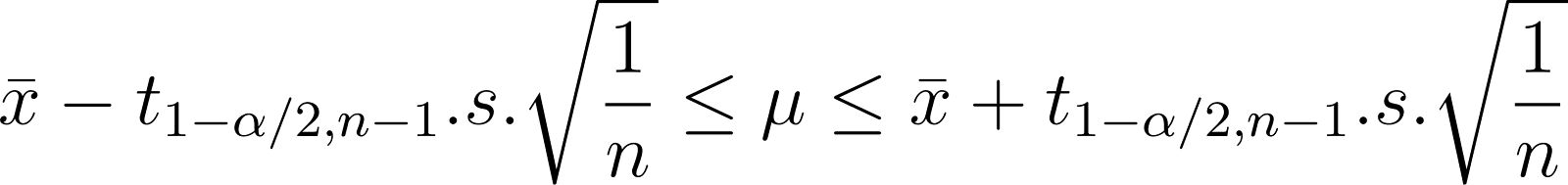
Observe também que o tamanho do intervalo é proporcional ao valor t. Se você quiser um grau extremamente alto de confiança (certeza) de que o valor real está dentro de um determinado intervalo, esse intervalo deverá ser muito grande. Quanto menor for o grau de confiança, mais estreito será o intervalo. Porém, um grau de confiança muito baixo não é muito útil. Portanto, na prática, é comum escolher níveis de confiança de 90%, 95%, 99%, etc.
Se você tem um nível de confiança de 95%, isso leva a um nível de significância de 5%. Supondo um intervalo bilateral, você precisa encontrar o valor crítico t em 2,5% (0,025).
Conceitualmente, todos os intervalos são expressos da seguinte forma:
![]()
Observe que, em todos os casos, quanto maior o erro, maior o intervalo. Esse erro é calculado de forma diferente, dependendo do caso de uso. Para inferência, o erro é o desvio padrão. Para regressão, o erro é mostrado nas próximas seções.
Ao prever o valor médio da variável dependente, você estima seu intervalo usando o intervalo de confiança. Por exemplo, você deseja prever um intervalo para o peso médio de cães de 2 anos de idade com base na idade deles. Isso é chamado de intervalo de confiança da resposta média. Ele também é considerado um parâmetro populacional porque é uma propriedade de toda a população. O intervalo é expresso como:
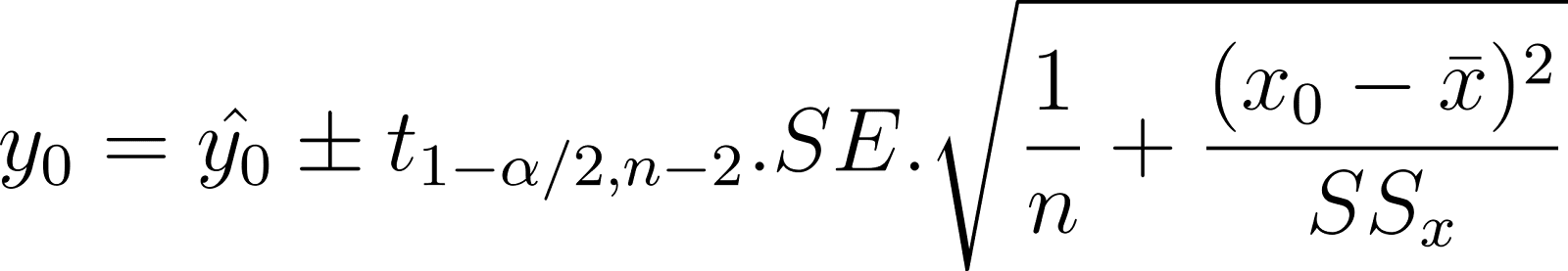
Na expressão acima:
![]()
![]()
Na expressão acima, o termo de soma também é chamado de soma dos quadrados dos resíduos. O resíduo é a diferença entre o valor real de y e o valor previsto de y.
Usando o MSE em vez do SE, o intervalo de confiança da resposta média também pode ser escrito como:
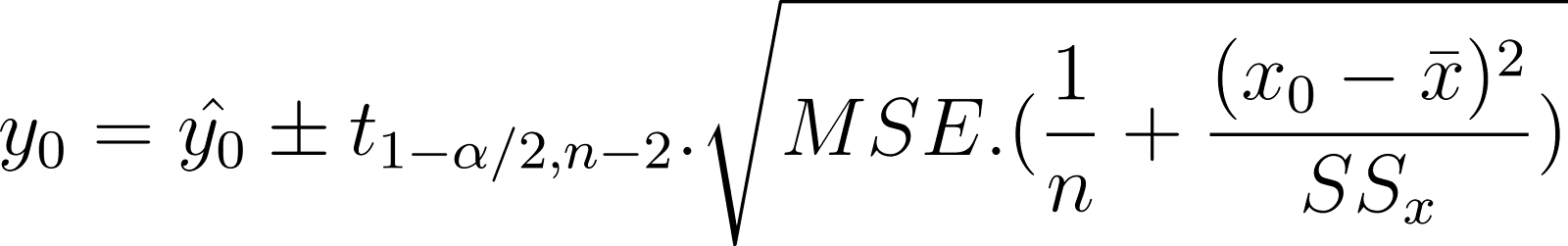
Compare a expressão acima com a relação conceitual mostrada anteriormente.
![]()
Observe que o erro leva em conta:
Para prever o valor exato de um ponto de dados individual (não a média), você estima seu intervalo usando o intervalo de previsão. Por exemplo, você deseja prever o intervalo para o peso real de um cão específico de 2 anos de idade com base na idade. Isso é chamado de intervalo de previsão e é expresso como:
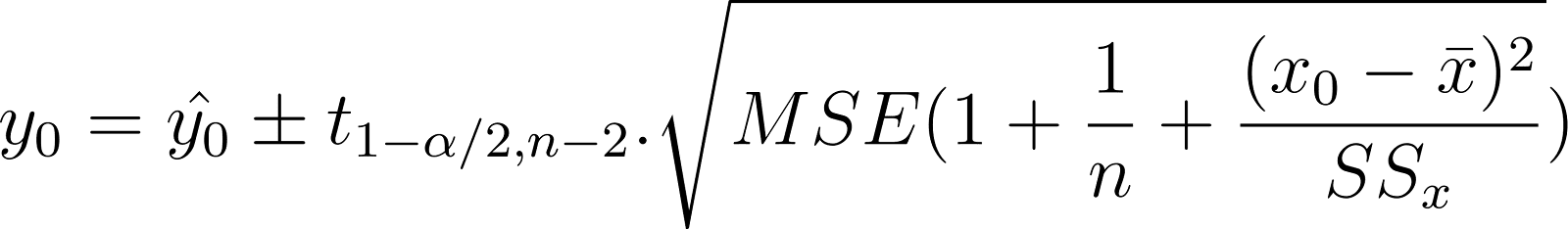
Compare isso com o intervalo de confiança mostrado anteriormente:
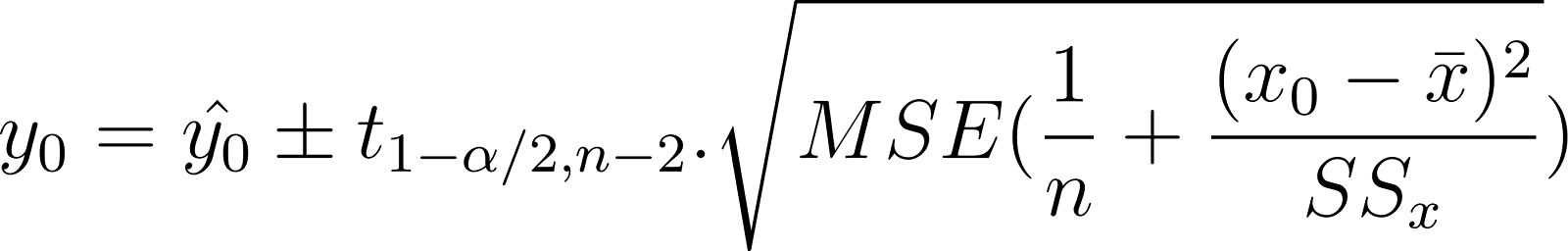
Observe que as duas expressões são bastante semelhantes. A única diferença é o termo de erro adicional no intervalo de previsão. O intervalo de previsão tem um termo MSE adicional dentro da raiz quadrada do que o intervalo de confiança. Isso é para levar em conta a variabilidade dos valores y que você deseja prever. Isso faz com que o intervalo de previsão seja mais amplo do que o intervalo de confiança.
O esboço abaixo mostra os intervalos de confiança e de previsão em relação à estimativa pontual (valor previsto).
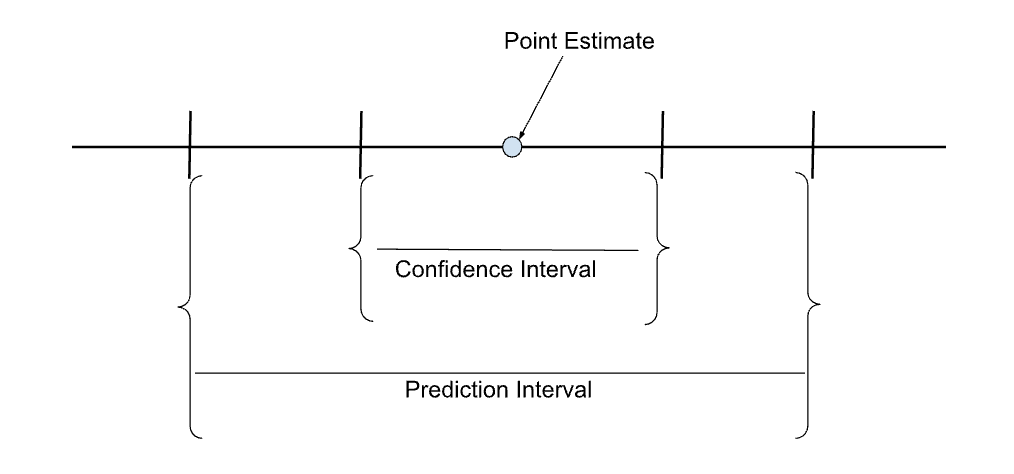
Comparação dos intervalos de confiança e de previsão de uma estimativa pontual. Imagem do autor.
O esboço esquemático abaixo mostra os intervalos de confiança e de previsão em relação à regressão - observe também que os intervalos são mais estreitos na região da média.
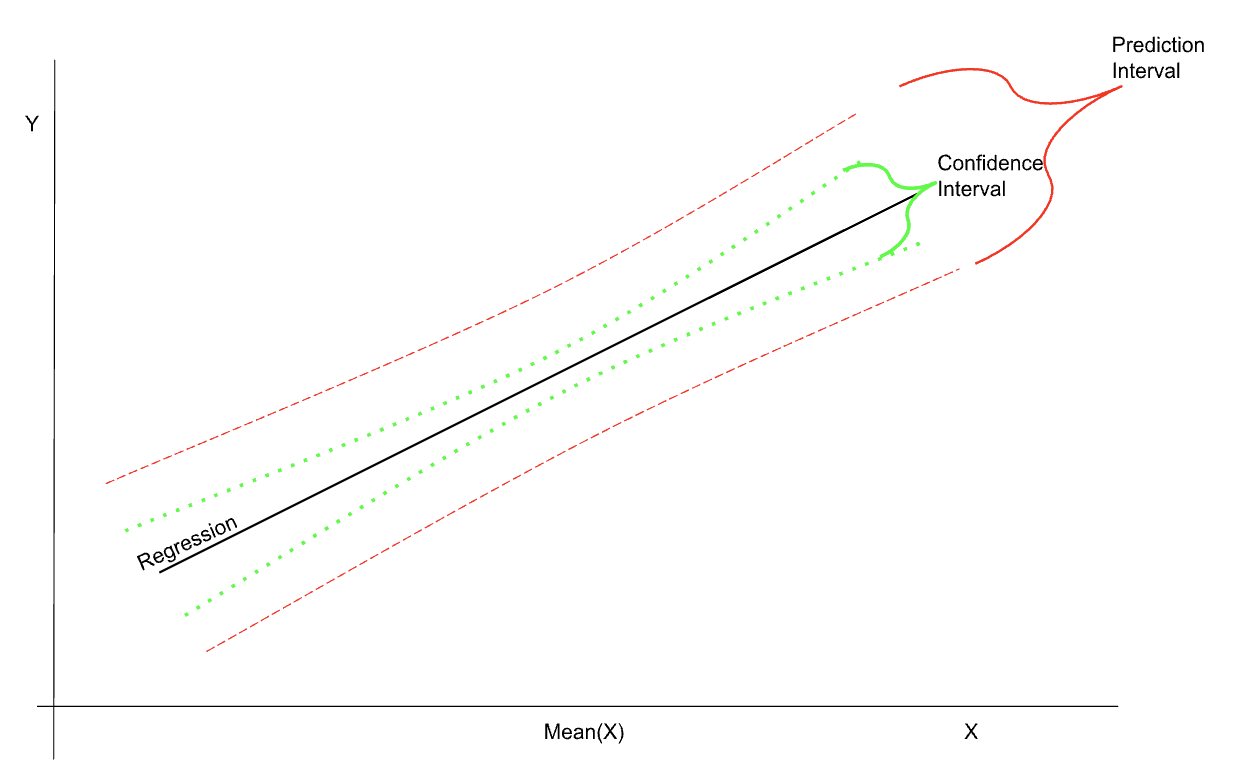
Ilustração dos intervalos de confiança e previsão na regressão. Imagem do autor.
As seções anteriores discutiram os conceitos básicos de intervalos de confiança e de previsão, seus usos e as fórmulas usadas para calculá-los. Esta seção fornece exemplos práticos de quando usar intervalos de confiança e de previsão.
Um intervalo de confiança é usado ao estimar um parâmetro populacional. Para estimar o parâmetro da população, você pode:
Alguns exemplos de casos de uso do intervalo de confiança são:
Os intervalos de previsão são usados sempre que você prevê o valor esperado de um ponto de dados individual com base em observações de (e análise de regressão em) uma amostra aleatória.
Alguns exemplos práticos incluem:
Os intervalos de confiança e os intervalos de previsão são usados com frequência no mesmo contexto, o que torna importante entender a diferença entre eles.
Esta tabela resume as diferenças com base na discussão das seções anteriores:
|
Intervalo de confiança |
Intervalo de previsão |
|
Usado para determinar os parâmetros da população com base nas estatísticas da amostra |
Não é usado para determinar parâmetros populacionais com base em amostras |
|
Usado para prever a resposta média (valor médio da variável dependente para uma determinada variável independente) com base em regressões. |
Usado para prever o valor futuro (de um ponto de dados individual para uma determinada variável independente) com base em regressões. |
|
Geralmente mais restrito para uma determinada análise |
Geralmente mais amplo para uma determinada análise |
Esta seção mostra exemplos práticos de como usar a linguagem de programação R para estimar intervalos de confiança e previsão. O R é uma linguagem projetada para aplicativos estatísticos e vem com conjuntos de dados e funções estatísticas incorporados.
Para saber mais sobre regressões usando o R, siga o tutorial do DataCamp sobre regressões lineares no R.
Os exemplos abaixo usam o conjunto de dados Orange incorporado. Esse conjunto de dados rastreia a circunferência (em milímetros) e a idade (em dias) das laranjeiras. Naturalmente, seria de se esperar que, quanto mais velha a árvore, maior seria sua circunferência.
Os exemplos abaixo mostram como estimar intervalos de confiança para estatísticas resumidas e análises de regressão.
Para obter o intervalo de confiança da média, execute o teste T padrão usando a função t.test() no conjunto de dados:
t.test(Orange$circumference)O resultado é parecido com o exemplo abaixo:
t = 11.923, df = 34, p-value = 1.076e-13
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
96.10926 135.60502
sample estimates:
mean of x
115.8571 Ele fornece a você a estimativa média e o intervalo de confiança de 95%. Por padrão, a função T-Test usa um nível de confiança de 95%. Use o parâmetro conf.level para especificar um intervalo de confiança diferente, como 99%.
> t.test(Orange$circumference, conf.level = 0.99)Esse comando produz a seguinte saída:
t = 11.923, df = 34, p-value = 1.076e-13
alternative hypothesis: true mean is not equal to 0
99 percent confidence interval:
89.34458 142.36970
sample estimates:
mean of x
115.8571 Observe que a média estimada é a mesma em ambos os casos. No entanto, o intervalo precisa ser maior para que você tenha um nível de confiança mais alto. Com base nos dados, tenho 99% de certeza de que a média está entre 89,3 e 142,4, mas apenas 95% de certeza de que está entre 96,1 e 135,6. Para um parâmetro estimado a partir de uma determinada amostra, quanto mais estreito for o intervalo de confiança, menor será o nível de confiança.
Nas análises de regressão, você precisa dos intervalos de confiança para os coeficientes de regressão e valores previstos.
Para que você entenda em profundidade como fazer regressões em R, siga o curso do DataCamp sobre Inferência para regressão linear em R.
Os coeficientes de regressão são estimados por meio da análise de uma amostra aleatória. Portanto, eles não são os coeficientes verdadeiros para toda a população. As estimativas dos parâmetros de regressão têm alguns erros associados a elas. Além de seus valores estimados, é útil fornecer um intervalo de confiança para os parâmetros.
Use the lm() function to build a linear model based on the Orange dataset to predict the circumference (in mm) of orange trees given their age (in days):-
model_orange <- lm(circumference ~ age, data = Orange)Verifique os coeficientes desse modelo linear:
model_orangeEsse comando mostra os parâmetros do modelo (interceptação e inclinação) conforme abaixo:
Coefficients: (Intercept) age
17.3997 0.1068 Use a função confint() para calcular os intervalos de confiança de 95%:
confint(model_orange, level = 0.95)Agora você pode ver os intervalos de confiança de 95% da inclinação e da interceptação estimadas pelo modelo:
2.5 % 97.5 %
(Intercept) -0.14328303 34.9425835
age 0.08993141 0.1236092Use o modelo de regressão criado acima para prever a circunferência média esperada de árvores com 900 dias de idade. Use o parâmetro interval para especificar um intervalo de confiança.
predict(model_orange, data.frame(age = 900), interval = "confidence", level = 0.95) O resultado inclui a previsão (fit) e o intervalo de confiança (lwr e upr para os limites inferior e superior), conforme mostrado abaixo:
fit lwr upr
1 113.4929 105.3211 121.6647Use o mesmo modelo acima para prever a circunferência específica de uma laranjeira individual com 900 dias de idade. Use o parâmetro interval para especificar que você deseja o intervalo de previsão.
> predict(model, data.frame(age = 900), interval = "prediction", level = 0.95) O resultado é semelhante ao exemplo abaixo:
fit lwr upr
1 113.4929 64.5118 162.4741Observe que, em ambos os casos, o valor previsto da circunferência é o mesmo - 113,49. Entretanto, o intervalo de previsão é muito maior do que o intervalo de confiança. O intervalo de confiança da previsão é o intervalo que se espera que contenha a circunferência média das árvores com 900 dias de idade. O intervalo de previsão é o intervalo esperado da circunferência de uma árvore individual com 900 dias de idade. Isso ocorre porque pode haver uma variação consideravelmente maior em árvores individuais, que é suavizada quando se considera o valor médio.
Os intervalos estatísticos são comumente usados em campos estatísticos aplicados, como análise de dados, produtos farmacêuticos, econometria, etc. Para quem não tem formação acadêmica em estatística, é fácil confundir intervalos de confiança e intervalos de previsão.
Alguns equívocos comuns são discutidos abaixo:
Este artigo apresentou uma visão geral dos intervalos de confiança e intervalos de previsão. Ele também explica a diferença entre esses conceitos de aparência semelhante e oferece exemplos práticos de quando você deve usar cada tipo de intervalo. O artigo também mostrou como calcular a previsão e os intervalos de confiança usando a linguagem de programação R.
Para saber como aplicar fórmulas estatísticas usando Python, consulte o curso DataCamp sobre estatísticas em Python. Por fim, se você estiver se preparando para entrevistas de emprego que envolvam estatística, confira o curso do DataCamp sobre perguntas de entrevista sobre estatística em Python.
Aprenda mais sobre estatística e ciência de dados com estes cursos!
Curso
Curso
Curso
Tutorial
Eladio Montero Porras
Tutorial
Vidhi Chugh
Tutorial
Somil Asthana
Tutorial
Zoumana Keita
Tutorial
Kevin Babitz
Tutorial
Karlijn Willems


