
Course
Linear Algebra for Data Science in R
4 hr
21K
Statistical studies, whether they involve determining population parameters or predicting dependent variables, always involve some uncertainty. The root cause of this uncertainty is the sampling process. It is unrealistic to consider the entire population when conducting a statistical analysis. Thus, it is necessary to choose a representative sample - whether to estimate a population parameter, like the mean or to build a regression model.
To learn or brush up on these basics, refer to the DataCamp introductory course on statistics.
The true value of the population parameter is usually not exactly equal to the value estimated from the sample - this difference is the standard error. To account for this error, it is conventional to estimate an expected value and then specify a range that is expected to contain the actual value.
Similarly, regression studies are also based on random samples instead of the entire population. The relationship between the dependent and independent variables, as estimated by the regression study on the sample, is not exactly equal to the true relationship between those variables in the entire population. Hence, the predicted value of an individual data point is not exactly equal to its true value. The true value is expected to lie within some interval of the predicted value.
This article explains the meaning of both types of intervals and the underlying mathematical methods used to calculate them. It discusses practical examples of when to use each interval. Lastly, it illustrates with hands-on examples how to calculate confidence and prediction intervals in the R programming language.
A confidence interval is the range that is expected - with some level of confidence, to contain the true value of a population parameter, such as the population mean.
A population parameter is a numerical property of the entire population. The mean (of the entire population) is an example of a population parameter. The true value of the regression coefficients between two variables is another example of a population parameter. Inferential statistics is about studying the data points in a random sample to estimate a population parameter.
Suppose, hypothetically, you are a horticulturist or an orange farmer and want to know how thick orange trees become when they are 100 days old. It is impossible to study every single orange tree that is 100 days old. So, you randomly select a few 100-day-old trees and measure their circumference (thickness). The average of these measurements gives you the sample mean. You want to use this sample mean to get the population mean.

A population of orange trees. Created using DALL-E.
The sample mean is a point estimate for the population parameter (in this case, the parameter of interest is the mean). This DataCamp course on inferential statistics discusses these concepts in greater detail.
The sample mean is representative of the population mean but not exactly equal to it. The population mean is expected to lie within a certain interval of the sample mean, which is called the confidence interval.
The previous section explained confidence intervals in inferential statistics. Regression also involves the use of confidence intervals.
As an example, consider a variation of the same orange tree example:
You do this using a regression analysis. The dataset on which you run the regression is based on a sample of orange trees. Thus, the estimated sample mean (average circumference of 100-day-old orange trees) will not precisely equal the population mean. The true value of the population mean lies within a confidence interval of the estimated sample mean.
Later sections show and explain the mathematical expressions for the confidence interval.
A prediction interval is the range that is expected - with some level of confidence, to contain the true value of an individual data point, based on a prediction made using regression analysis.
Consider another variation on the regression example mentioned earlier:
You use the same regression formula as before. The estimated value (i.e., the expected value) of the individual circumference is the same as the estimated mean circumference. However, you must account for the increased variability of individual data points because you are predicting an individual value (and not an average). Thus, the prediction interval is larger than the confidence interval.
Later in the article, you will see the formulae for these intervals and learn how to use R to calculate them.
The two concepts - prediction intervals and confidence intervals are closely related. The same analysis can often involve the use of both kinds of intervals. So, it is helpful to compare them head to head.
When you need to know a population parameter, such as a mean, you use a sample to estimate this parameter. Since the sample size is typically much smaller than the population, the sample’s parameter estimate is imperfect. The confidence interval is the range (of the sample estimate) expected to contain the population parameter.
Regression coefficients are also considered population parameters. Because they are estimated based on a sample (and not the whole population), some error is baked into these parameters. Thus, regression coefficients can also be expressed with a confidence interval.
Furthermore, you can use regression to predict either:
The former uses a confidence interval, and the latter uses a prediction interval. The following section explains this difference in greater detail.
As explained previously, the confidence interval is proportional to the standard deviation and inversely proportional to the sample size. The confidence interval of the population mean, 𝛍, is expressed as:
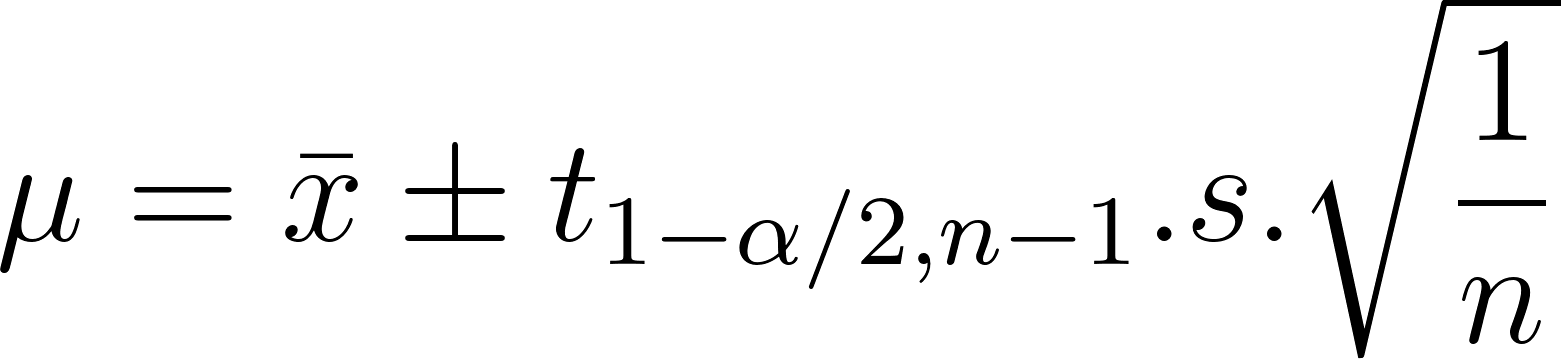
In the above expression:
Thus, the range of 𝛍 is:
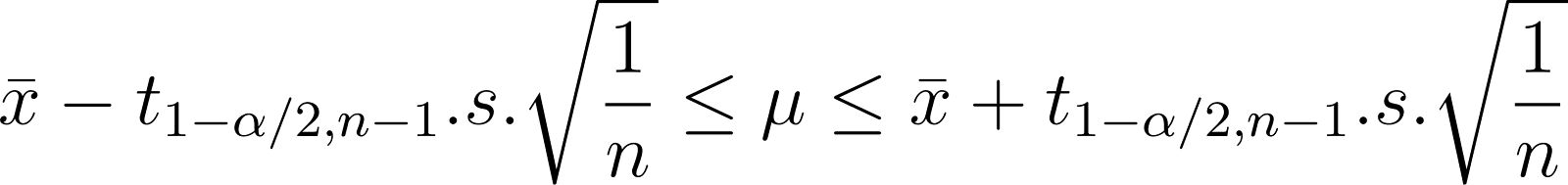
Notice also that the size of the interval is proportional to the t-value. If you want an extremely high degree of confidence (certainty) that the actual value lies within the given range, that range has to be very large. The lower the degree of confidence, the narrower the interval. But, a very low degree of confidence is not very useful. So, in practice, it is common to choose confidence levels of 90%, 95%, 99%, etc.
If you have a confidence level of 95%, it leads to a significance level of 5%. Assuming a two-sided interval, you need to find the t-critical value at 2.5% (0.025).
Conceptually, all intervals are expressed as follows:
![]()
Observe that in all cases, the larger the error, the wider the interval. This error is calculated differently depending on the use case. For inference, the error is the standard deviation. For regression, the error is shown in the next sections.
When you predict the average value of the dependent variable, you estimate its range using the confidence interval. For example, you want to predict a range for the average weight of 2-year-old dogs based on their age. This is called the confidence interval of the mean response. It is also considered a population parameter because it is a property of the entire population. The interval is expressed as:
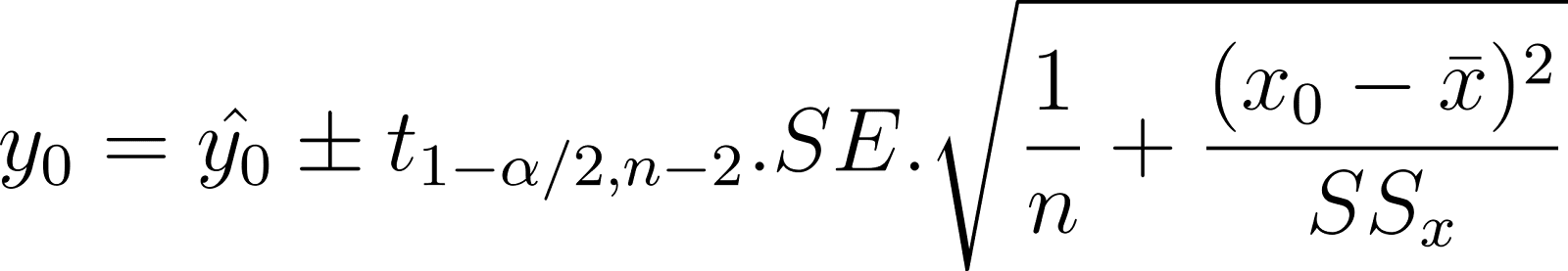
In the above expression:
![]()
![]()
In the above expression, the summation term is also called the sum of squares of the residuals. The residual is the difference between the true value of y and the predicted value of y.
Using the MSE instead of the SE, the confidence interval of the mean response can also be written as:
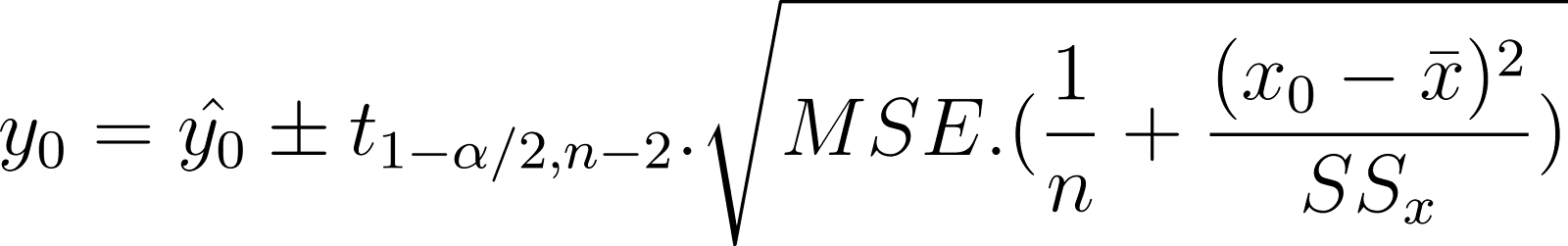
Compare the above expression to the conceptual relation shown earlier.
![]()
Observe that the error takes into account:
To predict the exact value of an individual data point (not the average), you estimate its range using the prediction interval. For example, you want to predict the range for one specific 2-year-old dog's actual weight based on age. This is called the prediction interval, and it is expressed as:
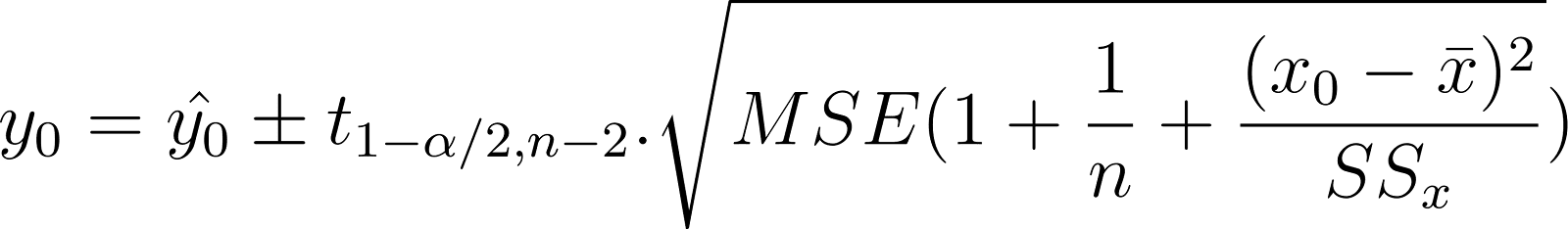
Compare this to the confidence interval shown earlier:
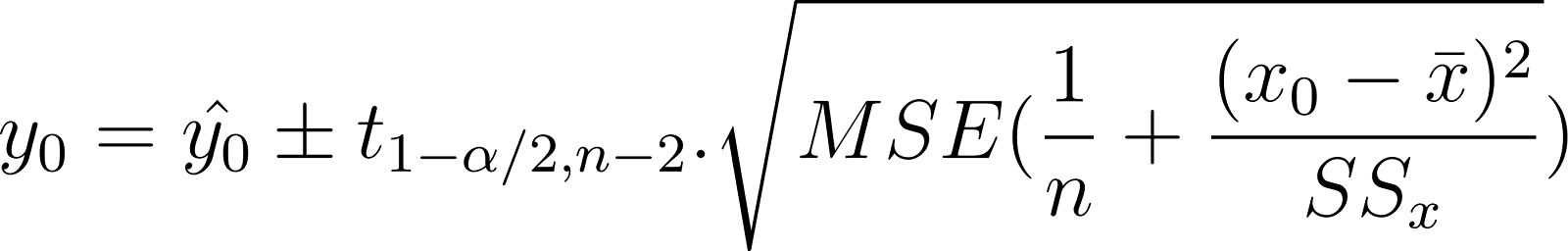
Notice that both expressions are pretty similar. The only difference is the additional error term in the prediction interval. The prediction interval has an additional MSE term inside the square root than the confidence interval. This is to take into account the variability in y values, which you want to predict. This makes the prediction interval wider than the confidence interval.
The sketch below shows the confidence and prediction intervals in relation to the point estimate (predicted value).
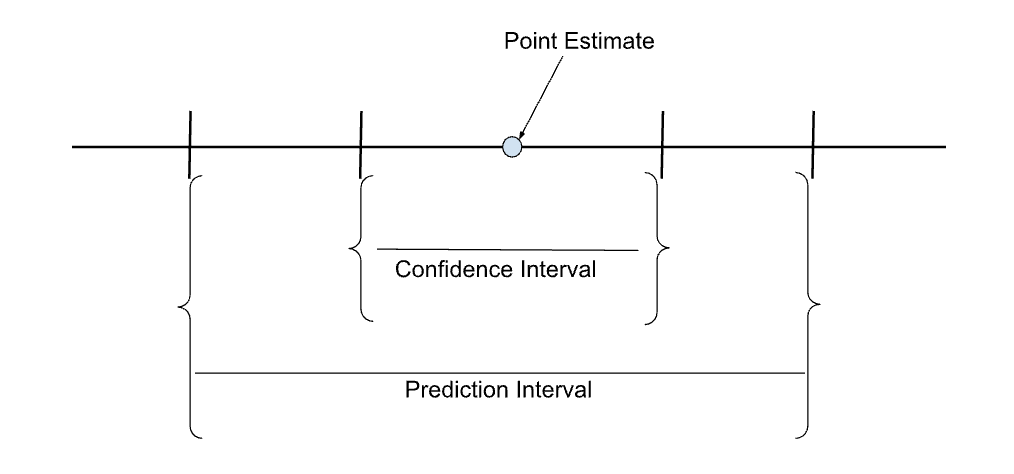
Comparing confidence and prediction intervals of a point estimate. Image by author.
The schematic sketch below shows the confidence and prediction intervals in relation to the regression—notice also that the intervals are the narrowest in the region of the mean.
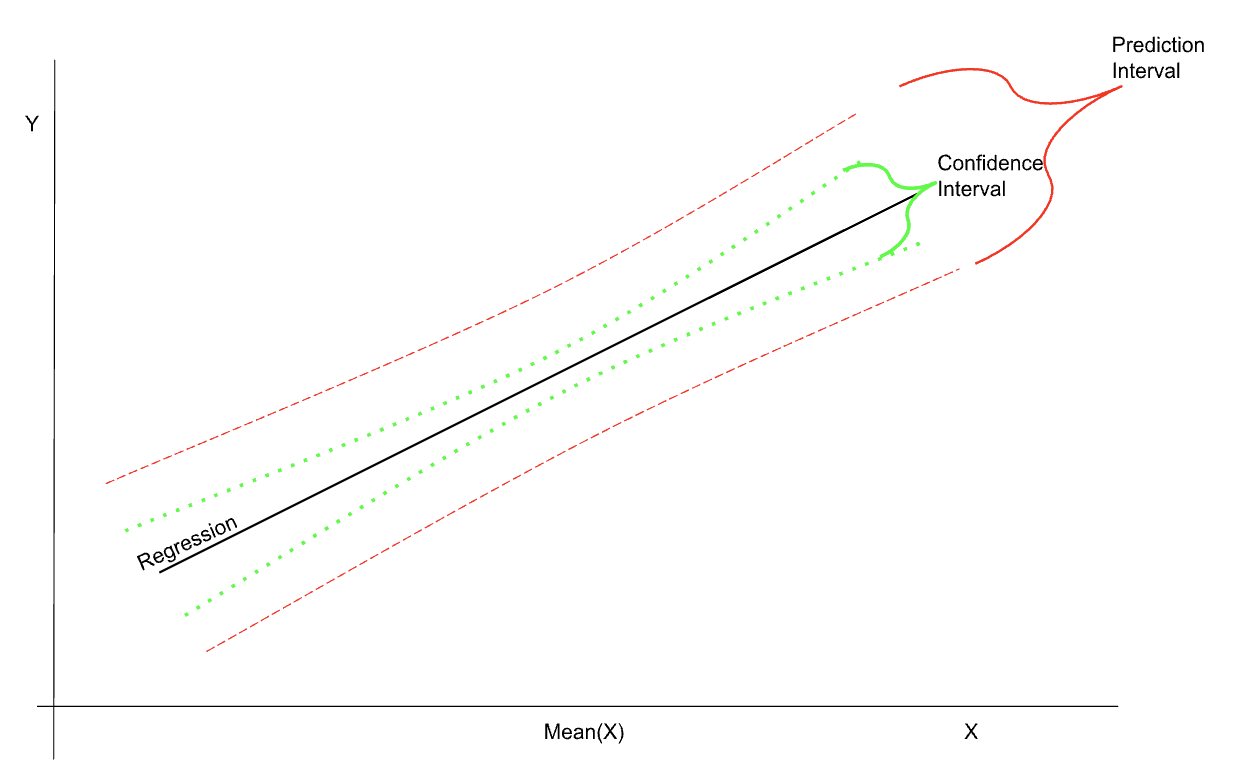
Illustration of confidence and prediction intervals in regression. Image by author.
The previous sections discussed the basics of confidence and prediction intervals, their uses, and the formulae used to calculate them. This section gives practical examples of when to use confidence and prediction intervals.
A confidence interval is used when estimating a population parameter. To estimate the population parameter, you can either:
Some example use cases of the confidence interval are:
Prediction intervals are used whenever you predict the expected value of an individual data point based on observations of (and regression analysis on) a random sample.
Some practical examples include:
Confidence intervals and prediction intervals are often used in the same context, making it important to understand how they differ.
This table summarizes the differences based on the discussion in the previous sections:
|
Confidence Interval |
Prediction Interval |
|
Used in determining population parameters based on sample statistics |
Not used in determining population parameters based on samples |
|
Used to predict the mean response (average value of the dependent variable for a given independent variable) based on regressions. |
Used to predict the future value (of an individual data point for a given independent variable) based on regressions. |
|
Usually narrower for a given analysis |
Usually wider for a given analysis |
This section shows hands-on examples of using the R programming language to estimate confidence and prediction intervals. R is a language designed for statistical applications, and it comes with inbuilt datasets and statistical functions.
To learn more about regressions using R, follow the DataCamp tutorial on linear regressions in R.
The examples below use the inbuilt Orange dataset. This dataset tracks the circumference (in millimeters) and age (in days) of orange trees. Naturally, one would expect that the older the tree, the larger its circumference.
The examples below show how to estimate confidence intervals for summary statistics and regression analyses.
To get the confidence interval for the mean, run the standard T-test using the t.test() function on the dataset:
t.test(Orange$circumference)The output looks like the example below:
t = 11.923, df = 34, p-value = 1.076e-13
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
96.10926 135.60502
sample estimates:
mean of x
115.8571 It gives you the mean estimate and the 95% confidence interval. By default, the T-Test function uses a confidence level of 95%. Use the conf.level parameter to specify a different confidence interval, such as 99%.
> t.test(Orange$circumference, conf.level = 0.99)This command yields the following output:
t = 11.923, df = 34, p-value = 1.076e-13
alternative hypothesis: true mean is not equal to 0
99 percent confidence interval:
89.34458 142.36970
sample estimates:
mean of x
115.8571 Notice that the estimated mean is the same in either case. However, the interval needs to be wider to have a higher confidence level. Based on the data, I am 99% confident that the mean lies between 89.3 and 142.4, but only 95% confident that it lies between 96.1 and 135.6. For a parameter estimated from a given sample, the narrower the confidence interval, the lower the confidence level.
In regression analyses, you need the confidence intervals for the regression coefficients and predicted values.
For an in-depth understanding of how to do R regressions, follow the DataCamp course on Inference for Linear Regression in R.
Regression coefficients are estimated by analyzing a random sample. Thus, they are not the true coefficients for the entire population. The estimates of the regression parameters have some errors associated with them. In addition to their estimated values, it is helpful to give a confidence interval for the parameters.
Use the lm() function to build a linear model based on the Orange dataset to predict the circumference (in mm) of orange trees given their age (in days):
model_orange <- lm(circumference ~ age, data = Orange)Check the coefficients of this linear model:
model_orangeThis command shows the model’s parameters (intercept and slope) as below:
Coefficients: (Intercept) age
17.3997 0.1068 Use the confint() function to calculate the 95% confidence intervals:
confint(model_orange, level = 0.95)You can now see the 95% confidence intervals of the slope and intercept estimated by the model:
2.5 % 97.5 %
(Intercept) -0.14328303 34.9425835
age 0.08993141 0.1236092Use the regression model created above to predict the expected average circumference of 900-day-old trees. Use the interval parameter to specify a confidence interval.
predict(model_orange, data.frame(age = 900), interval = "confidence", level = 0.95) The output includes the prediction (fit) and the confidence interval (lwr and upr for lower and upper limits), as shown below:
fit lwr upr
1 113.4929 105.3211 121.6647Use the same model as above to predict the specific circumference of an individual orange tree that is 900 days old. Use the interval parameter to specify that you want the prediction interval.
> predict(model, data.frame(age = 900), interval = "prediction", level = 0.95) The output resembles the example below:
fit lwr upr
1 113.4929 64.5118 162.4741Notice that in both cases, the predicted value of the circumference is the same - 113.49. However, the prediction interval is much wider than the confidence interval. The confidence interval of the prediction is the range that is expected to contain the average circumference of 900-day-old trees. The prediction interval is the expected range of the circumference of an individual 900-day-old tree. This is because there can be considerably more variation in individual trees which is smoothened out when considering the average value.
Statistical intervals are commonly used in applied statistical fields like data analysis, pharmaceuticals, econometrics, etc. For those without an academic background in statistics, it is easy to confuse confidence intervals and prediction intervals.
Some common misconceptions are discussed below:
This article provided an overview of confidence intervals and prediction intervals. It also explains the difference between these similar-sounding concepts and offers practical examples of when to use each type of interval. The article also showed how to calculate prediction and confidence intervals using the R programming language.
To learn how to apply statistical formulas using Python, refer to the DataCamp course on statistics in Python. Lastly, if you are preparing for job interviews involving statistics, check out the DataCamp course on statistics interview questions in Python.
Learn more about statistics and data science with these courses!
Course
Course
Course
blog
Joleen Bothma
10 min
Tutorial
Łukasz Deryło
Tutorial
Arunn Thevapalan
Tutorial
Debbie Liske
Tutorial
Vidhi Chugh
Tutorial
Ryan Sheehy