
Curso
Introducción a la ingeniería de datos
4 h
127.6K
Varias técnicas facilitan la ingestión de datos. Cada uno está diseñado para abordar diferentes casos de uso y necesidades de procesamiento de datos.
La elección de la técnica que elijas depende de 3 factores:
En esta sección, abordaré tres técnicas de ingestión de datos y cuándo son más eficaces.
ETL es una técnica de ingestión de datos tradicional y muy utilizada. En este enfoque, los datos seextraen de varios sistemas fuente, se transforman en un formato coherente y limpio, y finalmente se cargan en un sistema de almacenamiento de datos, como un almacén de datos .
Este método es muy eficaz para los casos de uso que requieren datos coherentes y estructurados para la elaboración de informes, análisis y toma de decisiones.
Cuándo utilizar ETL:
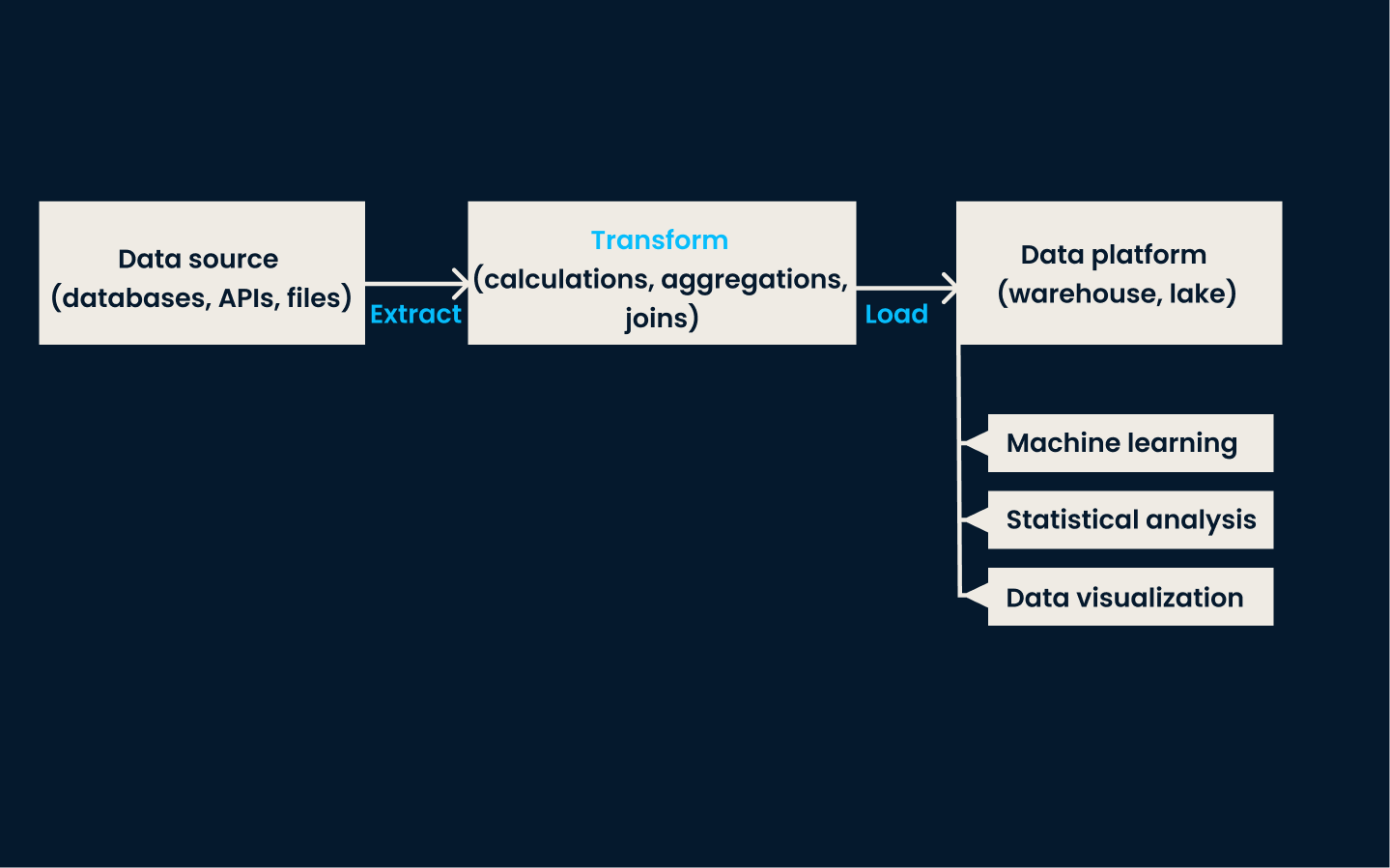
Arquitectura de canalización ETL.
ELT invierte el orden de las operaciones en comparación con ETL. En este enfoque, los datos seextraen de los sistemas de origen y se cargan directamente en el sistema de destino (normalmente un lago de datos o una plataforma basada en la nube). Una vez en el sistema de almacenamiento de destino, los datos setransforman en según sea necesario, a menudo dentro del entorno de destino .
El enfoque ELT es especialmente eficaz cuando se trata de grandes volúmenes de datos no estructurados o semiestructurados, en los que la transformación puede aplazarse hasta que sea necesario el análisis.
Cuándo utilizar el ELT:
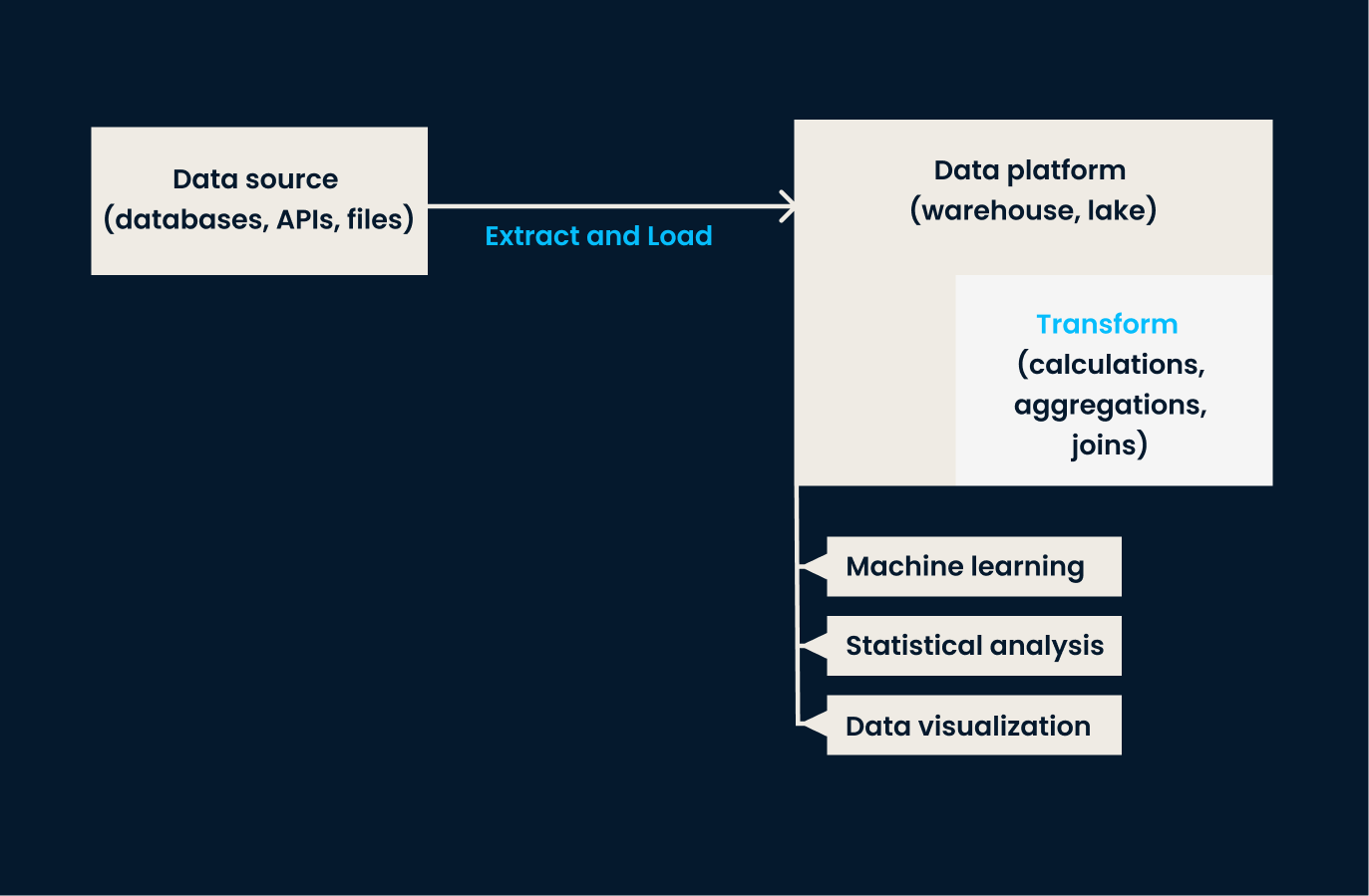
Arquitectura de canalización ELT.
CDC es una técnica para identificar y capturar los cambios (por ejemplo, inserciones, actualizaciones, eliminaciones) realizados en los datos de los sistemas de origen y, a continuación, replicar esos cambios en tiempo real en los sistemas de destino.
Esta técnica garantiza que los sistemas de destino estén siempre actualizados sin recargar todo el conjunto de datos. CDC es muy eficaz para mantener la sincronización en tiempo real entre bases de datos y garantizar la coherencia entre sistemas.
Cuándo utilizar el CDC:
Hemos establecido que la ingesta de datos implica extraer información de varias fuentes. Pero no hemos hablado de cuáles son esas estructuras, y eso es lo que haremos en esta sección.
Las fuentes de datos para la ingesta se clasifican generalmente en 3 tipos principales:
Como aprenderás cuando examinemos las distintas fuentes, cada una de ellas requiere técnicas de manipulación y procesamiento diferentes para ser utilizada con eficacia.
Los datos estructurados están muy organizados y siguen un esquema predefinido, lo que facilita su tratamiento y análisis. Suele almacenarse en bases de datos relacionales, que almacenan y proporcionan acceso a puntos de datos relacionados. Los datos se organizan en tablas con filas y columnas claramente definidas.
Debido a esta naturaleza organizada, los datos estructurados son los más sencillos de ingerir.
Las herramientas tradicionales como MySQL y PostgreSQL se utilizan normalmente para manejar datos estructurados. Estas herramientas basadas en SQL simplifican el proceso de validación durante la ingesta, aplicando estrictas reglas de esquema. Cuando se introducen datos en estos sistemas,se aseguran automáticamente de que se ajustan a la estructura definida por las tablas de la base de datos.
Por ejemplo, si una columna está configurada para aceptar sólo valores enteros, MySQL o PostgreSQL rechazarán cualquier dato que no cumpla este requisito.
Otras cosas que hay que tener en cuenta sobre los datos estructurados son
Los datos semiestructurados, aunque siguen estando organizados hasta cierto punto, no se ajustan a un esquema rígido y predefinido como los datos estructurados. En su lugar, utiliza etiquetas o marcadores para proporcionar cierta organización, pero la estructura sigue siendo flexible.
Este tipo de datos sueleencontrarse en formatos como archivos JSON, archivos CSV y bases de datos NoSQL, y se utiliza habitualmente en aplicaciones web, API y sistemas de registro.
Como la estructura puede variar,los datos semiestructuradosofrecen flexibilidad de almacenamiento y procesamiento, por lo que son adecuados para sistemas que manejan formatos de datos cambiantes o incoherentes.
Manejar datos semiestructurados requiere herramientas para analizar y extraer información significativa de las etiquetas o marcadores incrustados. Por ejemplo, un archivo JSON puede contener una colección de pares clave-valor, y el proceso de ingestión implicaría analizar estos pares y transformarlos en un formato adecuado.
Los datos semiestructurados a menudo se ingieren en entornos flexibles como lagos de datos o plataformas en la nube, donde pueden almacenarse en su forma bruta y procesarse posteriormente según sea necesario.
Otras cosas que hay que tener en cuenta sobre los datos semiestructurados son:
Los datos no estructurados son el tipo más complejo de gestionar, porque carecen de un formato específico o de una estructura organizativa. Esta categoría incluye datos como:
A diferencia de los datos estructurados o semiestructurados, los datos no estructurados no tienen filas, columnas o etiquetas claras para definir su contenido, lo que hace más difícil procesarlos y analizarlos.
A pesar de su complejidad, los datos no estructurados pueden contener información valiosa, sobre todo cuando se analizan utilizando tecnologías avanzadas como el aprendizaje automático o el procesamiento del lenguaje natural.
Dado que los datos no estructurados no están organizados de una forma predefinida, se necesitan herramientas especializadas para gestionar el proceso de ingestión. Estas herramientas pueden extraer información relevante de fuentes brutas y no estructuradas y transformarla en formatos que puedan analizarse.
Por último, los datos no estructurados suelen almacenarse en lagos de datos, donde pueden procesarse según sea necesario.
|
Función |
Datos estructurados |
Datos semiestructurados |
Datos no estructurados |
|
Definición |
Datos muy organizados con un esquema predefinido (por ejemplo, filas y columnas). |
Datos parcialmente organizados con etiquetas o marcadores para mayor flexibilidad (por ejemplo, JSON, CSV). |
Datos sin ninguna estructura u organización predefinida (por ejemplo, imágenes, vídeos). |
|
Ejemplos |
Bases de datos relacionales como MySQL, PostgreSQL. |
Archivos JSON, bases de datos NoSQL, registros CSV. |
Imágenes, vídeos, archivos de audio, documentos de texto. |
|
Facilidad de procesamiento |
Más fácil de procesar debido a su esquema estricto. |
Dificultad moderada; requiere análisis sintáctico y transformación. |
El mayor reto debido a la falta de estructura. |
|
Almacenamiento |
Bases de datos relacionales o almacenes de datos. |
Lagos de datos, bases de datos NoSQL, almacenamiento en la nube. |
Lagos de datos o almacenamiento especializado para archivos en bruto. |
|
Enfoque por ingestión |
Suelen ingerirse por tandas. |
Flexible; se puede ingerir en tiempo real o por lotes. |
Principalmente se ingiere en formato bruto para su posterior procesamiento. |
|
Herramientas utilizadas |
Herramientas basadas en SQL como MySQL, PostgreSQL. |
Herramientas que manejan esquemas flexibles, como MongoDB, Google BigQuery. |
Herramientas avanzadas como Hadoop, Apache Spark o herramientas de procesamiento basadas en IA/ML. |
|
Ejemplos de casos prácticos |
Generación de informes, sistemas transaccionales. |
Respuestas API, registros de aplicaciones web. |
Reconocimiento de imágenes, análisis del habla, análisis de sentimientos. |
La ingesta de datos conlleva varios retos que debes abordar para garantizar una gestión de datos eficiente y eficaz. En esta sección, hablaremos de cuáles son estos retos y de las soluciones que pueden emplearse para superarlos.
Uno de los principales retos de la ingesta de datos es el enorme volumen de datos que hay que procesar. A medida que las empresas crecen, la cantidad de datos que generan y recopilan puede aumentar exponencialmente, sobre todo con el auge de los flujos de datos en tiempo real procedentes de fuentes como los dispositivos IoT y las plataformas de medios sociales.
Escalar los procesos de ingestión de datos para manejar estos volúmenes crecientes puede ser difícil, especialmente con datos en flujo que requieren una ingestión continua.
Los equipos deben asegurarse de que su infraestructura puede soportar la ingestión de datos por lotes y en tiempo real a escalasin degradación. El curso Conceptos de Streaming es una forma estupenda de empezar.
La calidad y coherencia de los datos son otro reto importante, sobre todo cuando los datos se ingieren desde múltiples fuentes dispares. Cada fuente puede tener formatos diferentes, niveles de exhaustividad o incluso información contradictoria.
Ingerir datos sin abordar estas incoherencias puede dar lugar a conjuntos de datos inexactos o incompletos, que a la larga repercuten en los análisis posteriores.
Deben aplicarse comprobaciones de validación de datos durante la ingesta para garantizar que sólo entren en el sistema datos de alta calidad. Además, los equipos deben mantener la coherencia entre las distintas fuentes para evitar discrepancias en los datos.
Recomiendo profundizar en este tema con el excelente curso Introducción a la Calidad de Datos.
Cuando se ingieren datos sensibles, la seguridad y el cumplimiento de las normas se convierten en prioridades absolutas. Los equipos que manejan información personal (por ejemplo, nombres de clientes, direcciones, detalles de pago, etc.) deben proteger estos datos durante todo el proceso de ingestión.
Por ejemplo, una empresa de servicios financieros debe cumplir normativas estrictas como la GDPR o la HIPAA al incorporar datos de clientes para evitar repercusiones legales. Si no se protegen los datos durante la ingestión, podrían producirse violaciones de datos, comprometiendo la confianza de los clientes y dando lugar a importantes sanciones económicas.
Para solucionarlo, los equipos deben implantar la encriptación y los controles de acceso seguro durante el proceso de ingestión. Esto garantiza que los datos sensibles estén protegidos de accesos no autorizados. Además, los datos deben ingestarse de forma que cumplanll normas reglamentarias pertinentes, con auditorías periódicas para verificar el cumplimiento continuo.
Descubre cómo mantener los datos seguros y protegidos con el curso interactivo Seguridad de los Datos para principiantes.
En situaciones en las que se necesitan conocimientos inmediatos, los retrasos en la ingestión de datos pueden dar lugar a información obsoleta o irrelevante. La ingestión de datos de baja latencia requiere la capacidad de procesar y hacer que los datos estén disponibles para el análisis casi instantáneamente, lo que puede ser un reto cuando se trata de grandes volúmenes de datos.
Los equipos deben optimizar cuidadosamente sus sistemas para reducir la latencia y garantizar que los datos estén disponibles cuando se necesiten.
Existen algunas prácticas recomendadas para garantizar una ingestión de datos eficiente y eficaz.
Los datos ingestados se utilizarán para análisis, informes y toma de decisiones, por lo que deben cumplir unas normas predefinidas de precisión e integridad.
Implantar comprobaciones de validación de datos durante la ingesta puede ayudar a verificar que los datos se ajustan a los formatos y normas de calidad esperados. Ya he escrito sobre esto enen un tutorial sobre Grandes esperanzas.
Por ejemplo, si se espera que los datos estén dentro de un rango determinado o cumplan unos criterios específicos, utiliza reglas de validación para rechazar o marcar automáticamente cualquier dato que no cumpla estas normas. Esto minimiza los errores y garantiza que sólo se procesen datos fiables.
Otra buena práctica es asegurarte de que seleccionas el enfoque de ingestión adecuado a tus necesidades empresariales.
La ingesta por lotes se suele utilizar para datos menos sensibles al tiempo, como informes históricos o periódicos. En cambio, la ingesta en tiempo real se utiliza para aplicaciones que requieren acceso instantáneo a los datos más recientes, como la detección de fraudes o la monitorización del IoT.
Evalúa tus necesidades en función de la frecuencia y urgencia de las actualizaciones de datos.
Tu volumen de datos crecerá con el tiempo. Por tanto, es importante seleccionar herramientas e infraestructuras escalables para manejar cantidades crecientes de datos sin comprometer el rendimiento. Esto te permite ampliar tus canalizaciones de datos y capacidades de procesamiento para acomodar el crecimiento futuro.
Menos espacio de almacenamiento necesario significa menores costes de infraestructura. La compresión también acelera la transferencia de datos, lo que significa que la ingestión será más rápida, sobre todo cuando se trate de grandes conjuntos de datos o flujos de gran volumen. Esta práctica es especialmente beneficiosa cuando se trata de datos semiestructurados o no estructurados, ya que suelen tener un gran tamaño.
Como puedes ver, la ingestión de datos es un concepto sencillo, pero puede ser bastante difícil de aplicar por tu cuenta. ¿Cuáles son las mejores herramientas para ayudarte con la ingesta de datos? He elaborado una lista de los más utilizados.
Apache Kafka es una plataforma de streaming distribuido que destaca en la ingestión de datos en tiempo real. Está diseñado para manejar flujos de datos de alto rendimiento y baja latencia, lo que lo hace ideal para casos de uso que requieren acceso instantáneo a grandes volúmenes de datos generados continuamente.
Una ventaja importante de Kafka es que permite a las empresas procesar, almacenar y reenviar datos en streaming a varios sistemas en tiempo real. Se utiliza ampliamente en escenarios como la detección de fraudes, el procesamiento de datos IoT y el análisis en tiempo real.
El curso Introducción a Kafka puede enseñartea crear, gestionar y solucionar problemas de Kafka para los retos del flujo de datos del mundo real.
Apache Nifi es una herramienta de ingestión de datos conocida por su interfaz visual fácil de usar. Su accesible interfaz permite a las empresas diseñar, supervisar y gestionar flujos de datos mediante un mecanismo de arrastrar y soltar.
Nifi admite muchas fuentes de datos -incluidos datos por lotes y en tiempo real- y puede integrarse con sistemas como Hadoop, bases de datos relacionales y almacenes NoSQL. Su capacidad para automatizar los flujos de trabajo de ingestión de datos y gestionar tareas complejas de enrutamiento y transformación de datos la convierte en una herramienta flexible y potente para las necesidades de ingestión de datos a pequeña escala y a nivel empresarial.
Amazon Kinesis es un servicio nativo en la nube de AWS especializado en la ingesta, procesamiento y análisis de datos de streaming. Está diseñado para aplicaciones que requieren un procesamiento casi en tiempo real de flujos de datos de alto rendimiento, como:
Una de las ventajas de Kinesis es su capacidad para integrarse con otros servicios de AWS de almacenamiento, análisis y aprendizaje automático.
Esta herramienta es especialmente adecuada para las organizaciones que aprovechan la infraestructura de la nube y buscan una solución totalmente gestionada para manejar sus requisitos de ingestión de datos sin preocuparse por cuestiones de hardware o escalabilidad.
Google Cloud Dataflow es un servicio totalmente gestionado proporcionado por Google Cloud que admite el procesamiento de datos por lotes y en tiempo real. Se basa en Apache Beam, un modelo de programación unificado de código abierto, y permite a los usuarios diseñar complejas canalizaciones de datos que pueden manejar tanto el procesamiento por lotes a gran escala como el flujo de datos en tiempo real.
Dataflow automatiza la gestión y el escalado de recursos, por lo que es ideal para las empresas que quieren procesar y analizar datos sin una gestión manual de la infraestructura.
Airbyte es una plataforma de ingesta de datos de código abierto que simplifica la integración de datos de diversas fuentes en soluciones de almacenamiento. Ofrece conectores preconstruidos para cientos de fuentes y destinos de datos y admite la ingesta por lotes y en tiempo real.
Lo bueno de Airbyte es que es altamente personalizable, lo que permite a los usuarios ampliar los conectores para adaptarlos a sus necesidades. Airbyte es una solución flexible para las empresas que desean gestionar y agilizar los flujos de trabajo de ingestión de datos. Además, ofrece un servicio de nube gestionada para quienes buscan una solución sin intervención.
En este artículo, hemos explorado los fundamentos de la ingesta de datos, sus tipos y las técnicas que la hacen posible. Has aprendido sobre la ingesta por lotes y en tiempo real, y sobre enfoques populares como ETL, ELT y Captura de Datos de Cambios (CDC). También hemos tratado las mejores prácticas, las distintas fuentes de datos y los retos a los que se enfrentan las organizaciones al realizarlas.
Para obtener más información sobre la gestión de datos y las herramientas de ingestión, te recomiendo que explores los siguientes recursos:
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Tim Lu
12 min
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
14 min
blog
Javier Canales Luna
12 min

