
Cours
Introduction au data engineering
4 h
127.6K
Plusieurs techniques facilitent l'ingestion des données. Chacun d'entre eux est conçu pour répondre à des cas d'utilisation et à des besoins de traitement de données différents.
Le choix de la technique que vous choisissez dépend de 3 facteurs :
Dans cette section, j'aborderai trois techniques d'ingestion de données et le moment où elles sont les plus efficaces.
L'ETL est une technique d'ingestion de données traditionnelle et largement utilisée. Dans cette approche, les données sontextraites de divers systèmes sources ( ), transformées dans un format cohérent et propre, et enfin chargées dans un système de stockage de données, tel qu'un entrepôt de données.
Cette méthode est très efficace pour les cas d'utilisation qui nécessitent des données cohérentes et structurées pour l'établissement de rapports, l'analyse et la prise de décision.
Quand utiliser l'ETL :
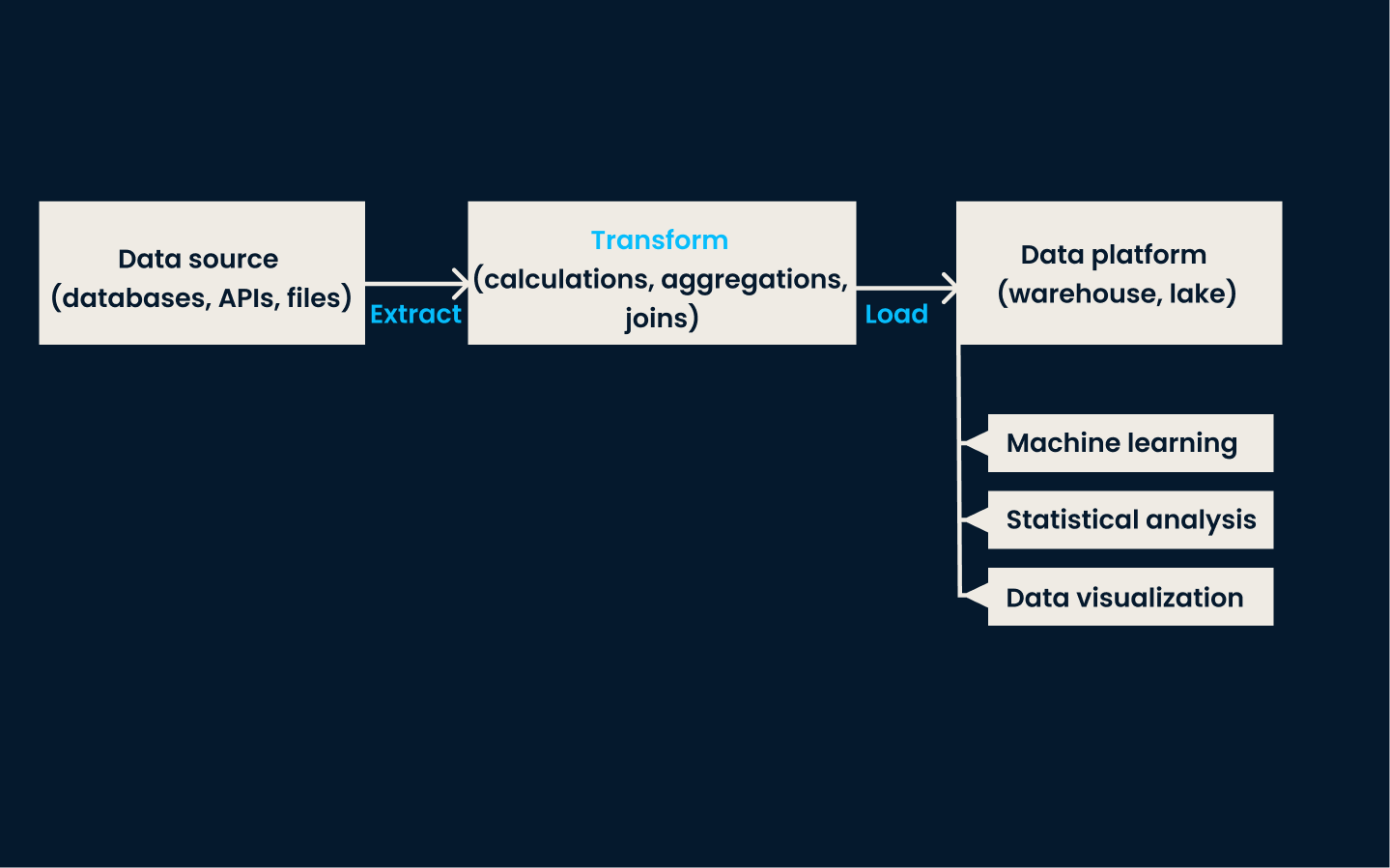
Architecture du pipeline ETL.
ELT inverse l'ordre des opérations par rapport à ETL. Dans cette approche, les données sont extraites des systèmes sources et chargées directement dans le système cible (généralement un lac de données ou une plateforme basée sur le cloud). Une fois dans le système de stockage cible, les données sont transformées selon les besoins, souvent dans l'environnement de destination.
L'approche ELT est particulièrement efficace lorsqu'il s'agit de traiter de grands volumes de données non structurées ou semi-structurées, où la transformation peut être différée jusqu'à ce que l'analyse soit nécessaire.
Quand utiliser l'ELT :
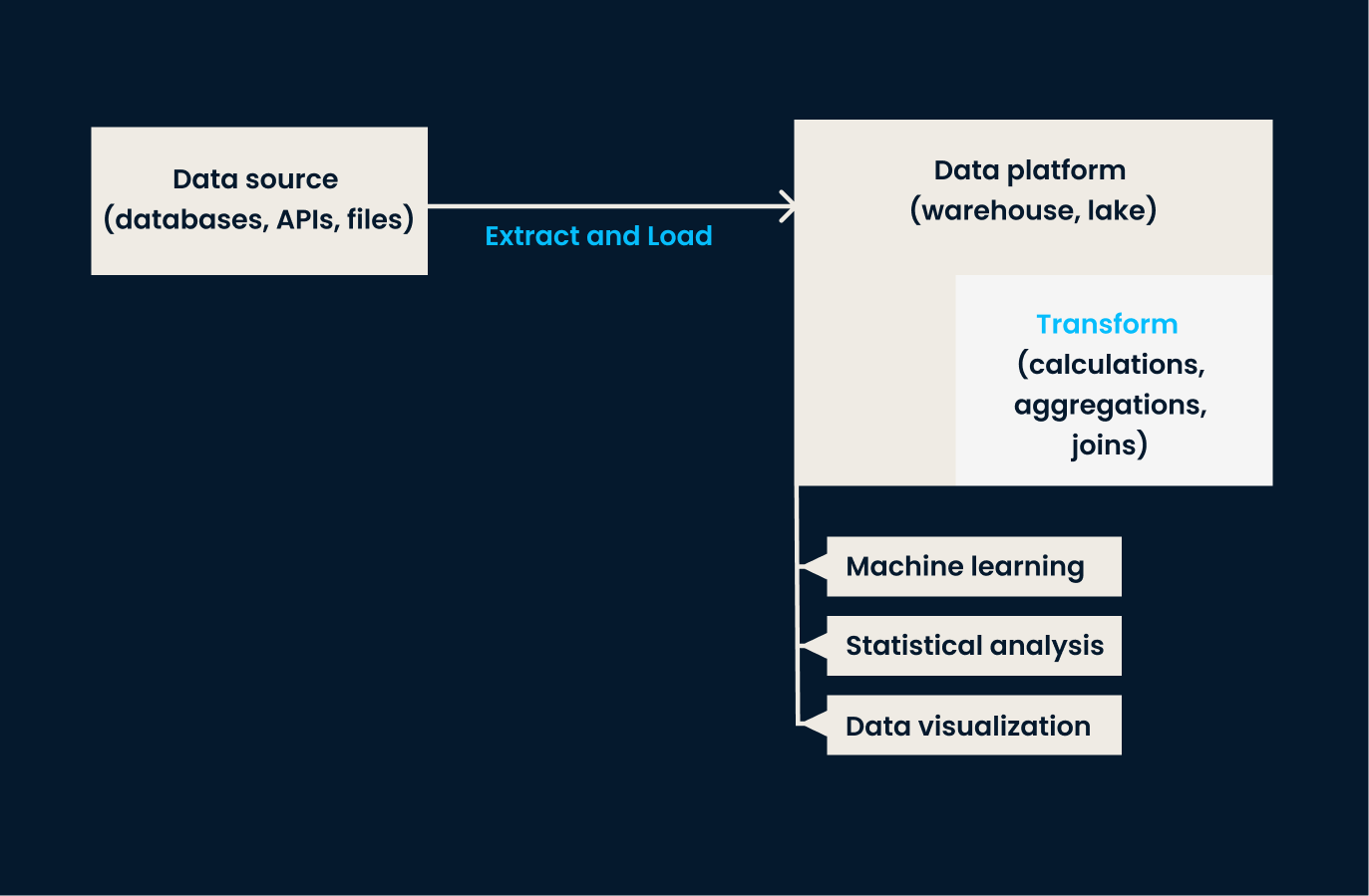
Architecture du pipeline ELT.
Le CDC est une technique permettant d'identifier et de capturer les changements (par exemple, les insertions, les mises à jour, les suppressions) apportés aux données dans les systèmes sources, puis de reproduire ces changements en temps réel dans les systèmes de destination.
Cette technique garantit que les systèmes cibles sont toujours à jour sans avoir à recharger l'ensemble des données. CDC est très efficace pour maintenir la synchronisation en temps réel entre les bases de données et assurer la cohérence entre les systèmes.
Quand utiliser le CDC :
Nous avons établi que l'ingestion de données consiste à extraire des informations de diverses sources. Mais nous n'avons pas discuté de la nature de ces structures - et c'est ce que nous allons faire dans cette section.
Les sources de données à ingérer se répartissent généralement en trois grands types :
Comme vous le verrez lorsque nous examinerons les différentes sources, chacune d'entre elles nécessite des techniques de manipulation et de traitement différentes pour être utilisée efficacement.
Les données structurées sont très organisées et suivent un schéma prédéfini, ce qui facilite leur traitement et leur analyse. Elles sont généralement stockées dans des bases de données relationnelles, qui stockent des points de données connexes et permettent d'y accéder. Les données sont classées dans des tableaux dont les lignes et les colonnes sont clairement définies.
En raison de cette nature organisée, les données structurées sont les plus simples à ingérer.
Les outils traditionnels tels que MySQL et PostgreSQL sont généralement utilisés pour traiter les données structurées. Ces outils basés sur le langage SQL simplifient le processus de validation lors de l'ingestion en appliquant des règles de schéma strictes. Lorsque les données sont introduites dans ces systèmes, ilsveillent automatiquement à ce qu'elles respectent la structure définie par les tableaux de la base de données.
Par exemple, si une colonne est configurée pour n'accepter que des valeurs entières, MySQL ou PostgreSQL rejettera toutes les données qui ne répondent pas à cette exigence.
D'autres éléments à noter concernant les données structurées sont les suivants :
Les données semi-structurées, bien que toujours organisées dans une certaine mesure, ne se conforment pas à un schéma rigide et prédéfini comme les données structurées. Au lieu de cela, il utilise des balises ou des marqueurs pour fournir une certaine organisation, mais la structure reste flexible.
Ce type de donnéesse trouve généralement dans des formats tels que les fichiers JSON, les fichiers CSV et les bases de données NoSQL, et il est couramment utilisé dans les applications web, les API et les systèmes de journaux.
La structure pouvant varier, lesdonnées semi-structuréesoffrent une certaine souplesse en matière de stockage et de traitement, ce qui les rend adaptées aux systèmes qui gèrent des formats de données évolutifs ou incohérents.
Le traitement des données semi-structurées nécessite des outils pour analyser et extraire des informations significatives à partir des balises ou marqueurs intégrés. Par exemple, un fichier JSON peut contenir une collection de paires clé-valeur, et le processus d'ingestion impliquerait d'analyser ces paires et de les transformer dans un format approprié.
Les données semi-structurées sont souvent ingérées dans des environnements flexibles tels que des lacs de données ou des plateformes cloud, où elles peuvent être stockées sous leur forme brute et traitées ultérieurement en fonction des besoins.
Les données semi-structurées présentent d'autres particularités :
Les données non structurées sont les plus complexes à gérer car elles n'ont pas de format spécifique ni de structure organisationnelle. Cette catégorie comprend des données telles que
Contrairement aux données structurées ou semi-structurées, les données non structurées n'ont pas de lignes, de colonnes ou d'étiquettes claires pour définir leur contenu, ce qui rend leur traitement et leur analyse plus difficiles.
Malgré leur complexité, les données non structurées peuvent contenir des informations précieuses, en particulier lorsqu'elles sont analysées à l'aide de technologies avancées telles que l'apprentissage automatique ou le traitement du langage naturel.
Les données non structurées n'étant pas organisées d'une manière prédéfinie (), des outils spécialisés sont nécessaires pour gérer le processus d'ingestion. Ces outils peuvent extraire des informations pertinentes à partir de sources brutes et non structurées et les transformer dans des formats qui peuvent être analysés.
Enfin, les données non structurées sont généralement stockées dans des lacs de données, où elles peuvent être traitées selon les besoins.
|
Fonctionnalité |
Données structurées |
Données semi-structurées |
Données non structurées |
|
Définition |
Données hautement organisées avec un schéma prédéfini (par exemple, des lignes et des colonnes). |
Données partiellement organisées avec des étiquettes ou des marqueurs pour plus de flexibilité (par exemple, JSON, CSV). |
Données sans structure ou organisation prédéfinie (par exemple, images, vidéos). |
|
Exemples |
Bases de données relationnelles telles que MySQL, PostgreSQL. |
Fichiers JSON, bases de données NoSQL, journaux CSV. |
Images, vidéos, fichiers audio, documents textuels. |
|
Facilité de traitement |
Plus facile à traiter en raison de son schéma strict. |
Difficulté modérée ; nécessite une analyse et une transformation. |
Le plus difficile en raison du manque de structure. |
|
Stockage |
Bases de données relationnelles ou entrepôts de données. |
Les lacs de données, les bases de données NoSQL, le stockage dans le cloud. |
Les lacs de données ou le stockage spécialisé de fichiers bruts. |
|
Approche par ingestion |
Généralement ingérés par lots. |
Flexible ; peut être ingéré en temps réel ou par lots. |
Les images sont principalement ingérées en format brut en vue d'un traitement ultérieur. |
|
Outils utilisés |
Outils basés sur SQL comme MySQL, PostgreSQL. |
Outils qui gèrent des schémas flexibles, tels que MongoDB, Google BigQuery. |
Des outils avancés comme Hadoop, Apache Spark, ou des outils de traitement basés sur l'IA/ML. |
|
Exemples de cas d'utilisation |
Générer des rapports, des systèmes transactionnels. |
Réponses API, journaux d'applications web. |
Reconnaissance d'images, analyse de la parole, analyse des sentiments. |
L'ingestion de données s'accompagne de plusieurs défis que vous devez relever pour garantir une gestion efficace des données. Dans cette section, nous examinerons ces défis et les solutions qui peuvent être mises en œuvre pour les surmonter.
L'un des principaux défis de l'ingestion de données est le volume de données à traiter. Au fur et à mesure que les entreprises se développent, la quantité de données qu'elles génèrent et collectent peut augmenter de façon exponentielle, en particulier avec l'augmentation des flux de données en temps réel provenant de sources telles que les appareils IoT et les plateformes de médias sociaux.
Il peut être difficile de faire évoluer les processus d'ingestion de données pour gérer ces volumes croissants, en particulier pour les données en continu qui nécessitent une ingestion continue.
Les équipes doivent s'assurer que leur infrastructure peut prendre en charge l'ingestion de données par lots et en temps réel à grande échellesans dégradation. Le cours " Streaming Concepts" est un excellent moyen de commencer.
La qualité et la cohérence des données constituent un autre défi de taille, en particulier lorsque les données proviennent de sources multiples et disparates. Chaque source peut avoir des formats différents, des niveaux d'exhaustivité différents, voire des informations contradictoires.
L'ingestion de données sans tenir compte de ces incohérences peut conduire à des ensembles de données inexacts ou incomplets, ce qui peut avoir un impact sur les analyses en aval.
Des contrôles de validation des données doivent être mis en œuvre lors de l'ingestion afin de garantir que seules des données de haute qualité entrent dans le système. En outre, les équipes doivent maintenir la cohérence entre les différentes sources afin d'éviter les divergences de données.
Je vous recommande de vous plonger dans ce sujet avec l'excellent cours Introduction à la qualité des données.
Lorsque des données sensibles sont ingérées, la sécurité et la conformité deviennent des priorités absolues. Les équipes qui traitent des informations personnelles (noms des clients, adresses, détails de paiement, etc.) doivent protéger ces données tout au long du processus d'ingestion.
Par exemple, une société de services financiers doit respecter des réglementations strictes telles que GDPR ou HIPAA lorsqu'elle ingère des données clients afin d'éviter des répercussions juridiques. L'absence de sécurisation des données lors de l'ingestion peut entraîner des violations de données, compromettant la confiance des clients et entraînant des pénalités financières substantielles.
Pour y remédier, les équipes doivent mettre en place un cryptage et des contrôles d'accès sécurisés au cours du processus d'ingestion. Les données sensibles sont ainsi protégées contre tout accès non autorisé. En outre, les données doivent être intégrées d'une manière conforme àtoutes les normes réglementaires pertinentes, avec des audits réguliers pour vérifier la conformité continue.
Découvrez comment préserver la sécurité des données grâce au cours interactif sur la sécurité des données, qui s'adresse aux débutants.
Dans les scénarios où des informations immédiates sont nécessaires, les retards dans l'ingestion des données peuvent se traduire par des informations obsolètes ou non pertinentes. L'ingestion de données à faible latence nécessite la capacité de traiter et de rendre les données disponibles pour l'analyse presque instantanément, ce qui peut s'avérer difficile lorsqu'il s'agit de gros volumes de données.
Les équipes doivent soigneusement optimiser leurs systèmes afin de réduire la latence et de garantir la disponibilité des données en cas de besoin.
Il existe quelques bonnes pratiques pour garantir l'efficacité de l'ingestion des données.
Les données ingérées seront utilisées à des fins d'analyse, de reporting et de prise de décision, et doivent donc répondre à des normes prédéfinies d'exactitude et d'exhaustivité.
La mise en œuvre de contrôles de validation des données lors de l'ingestion permet de vérifier que les données sont conformes aux formats et aux normes de qualité attendus. J'ai déjà écrit à ce sujet sure dans un tutoriel sur Les grandes espérances.
Par exemple, si les données doivent se situer dans une certaine fourchette ou répondre à des critères spécifiques, utilisez des règles de validation pour rejeter ou signaler automatiquement toutes les données qui ne répondent pas à ces normes. Cela permet de minimiser les erreurs et de garantir que seules des données fiables sont traitées en aval.
Une autre bonne pratique consiste à s'assurer que vous sélectionnez l'approche d'ingestion appropriée aux besoins de votre entreprise.
L'ingestion par lots est généralement utilisée pour les données moins sensibles au temps, telles que les rapports historiques ou périodiques. En revanche, l'ingestion en temps réel est utilisée pour les applications qui nécessitent un accès instantané aux données les plus récentes, comme la détection des fraudes ou la surveillance de l'IoT.
Évaluez vos besoins en fonction de la fréquence et de l'urgence des mises à jour de données.
Votre volume de données augmentera avec le temps. Il est donc important de choisir des outils et une infrastructure évolutifs pour traiter des quantités croissantes de données sans compromettre les performances. Vous pouvez ainsi développer vos pipelines de données et vos capacités de traitement pour faire face à la croissance future.
La réduction de l'espace de stockage nécessaire se traduit par une diminution des coûts d'infrastructure. La compression accélère également le transfert des données, ce qui signifie que l'ingestion sera plus rapide - principalement lorsqu'il s'agit d'ensembles de données volumineux ou de flux à haut volume. Cette pratique est particulièrement utile lorsqu'il s'agit de données semi-structurées ou non structurées, car elles sont souvent volumineuses.
Comme vous pouvez le constater, l'ingestion de données est un concept simple, mais il peut être assez difficile à mettre en œuvre par vous-même. Quels sont les meilleurs outils pour vous aider à ingérer des données ? J'ai dressé une liste des plus couramment utilisés.
Apache Kafka est une plateforme de streaming distribuée qui excelle dans l'ingestion de données en temps réel. Il est conçu pour traiter des flux de données à haut débit et à faible latence, ce qui le rend idéal pour les cas d'utilisation qui nécessitent un accès instantané à de grands volumes de données générées en continu.
L'un des principaux avantages de Kafka est qu'il permet aux entreprises de traiter, de stocker et de transmettre des données en continu à différents systèmes en temps réel. Elle est largement utilisée dans des scénarios tels que la détection des fraudes, le traitement des données IoT et l'analyse en temps réel.
Le cours Introduction à Kafka peut vous apprendreà créer, gérer et dépanner Kafka pour relever des défis réels en matière de flux de données.
Apache Nifi est un outil d'ingestion de données connu pour son interface visuelle conviviale. Son interface accessible permet aux entreprises de concevoir, de contrôler et de gérer les flux de données à l'aide d'un mécanisme de glisser-déposer.
Nifi prend en charge de nombreuses sources de données - y compris les données par lots et en temps réel - et peut s'intégrer à des systèmes tels que Hadoop, les bases de données relationnelles et les magasins NoSQL. Sa capacité à automatiser les flux de travail d'ingestion de données et à gérer des tâches complexes de routage et de transformation de données en fait un outil flexible et puissant pour les besoins d'ingestion de données à petite échelle et au niveau de l'entreprise.
Amazon Kinesis est un service cloud-native d'AWS spécialisé dans l'ingestion, le traitement et l'analyse des données en continu. Il est conçu pour les applications qui nécessitent un traitement en temps quasi réel de flux de données à haut débit, comme par exemple :
L'un des avantages de Kinesis est sa capacité à s'intégrer à d'autres services AWS pour le stockage, l'analyse et l'apprentissage automatique.
Cet outil est particulièrement bien adapté aux organisations qui exploitent une infrastructure cloud et recherchent une solution entièrement gérée pour répondre à leurs besoins d'ingestion de données sans se préoccuper des problèmes de matériel ou d'évolutivité.
Google Cloud Dataflow est un service entièrement géré fourni par Google Cloud qui prend en charge le traitement des données par lots et en temps réel. Il s'appuie sur Apache Beam, un modèle de programmation unifié open-source, et permet aux utilisateurs de concevoir des pipelines de données complexes capables de gérer à la fois le traitement par lots à grande échelle et les données en flux continu en temps réel.
Dataflow automatise la gestion et la mise à l'échelle des ressources, ce qui le rend idéal pour les entreprises qui souhaitent traiter et analyser des données sans gestion manuelle de l'infrastructure.
Airbyte est une plateforme d'ingestion de données open-source qui simplifie l'intégration de données provenant de diverses sources dans des solutions de stockage. Il propose des connecteurs prédéfinis pour des centaines de sources de données et de destinations et prend en charge l'ingestion par lots et en temps réel.
Ce qui est intéressant avec Airbyte, c'est qu'il est hautement personnalisable, ce qui permet aux utilisateurs d'étendre les connecteurs en fonction de leurs besoins. Airbyte est une solution flexible pour les entreprises qui souhaitent gérer et rationaliser les flux de travail d'ingestion de données. En outre, elle propose un service de cloud géré pour ceux qui recherchent une solution non interventionniste.
Dans cet article, nous avons exploré les principes fondamentaux de l'ingestion de données, ses types et les techniques qui la permettent. Vous avez appris ce qu'est l'ingestion par lots et en temps réel, ainsi que les approches les plus courantes telles que l'ETL, l'ELT et la capture des données de changement (CDC). Nous avons également abordé les meilleures pratiques, les différentes sources de données et les défis auxquels les organisations sont confrontées lors de l'exécution.
Pour en savoir plus sur les outils de gestion et d'ingestion des données, je vous recommande d'explorer les ressources suivantes :
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach