
Kurs
Einführung in das Data Engineering
4 Std.
127.6K
Verschiedene Techniken erleichtern die Datenerfassung. Jede ist für unterschiedliche Anwendungsfälle und Datenverarbeitungsanforderungen konzipiert.
Für welche Technik du dich entscheidest, hängt von 3 Faktoren ab:
In diesem Abschnitt gehe ich auf drei Dateneingabeverfahren ein und zeige, wann sie am effektivsten sind.
ETL ist eine traditionelle und weit verbreitete Technik zur Dateneingabe. Bei diesem Ansatz werden die Daten aus verschiedenen Quellsystemen extrahiert, in ein konsistentes und sauberes Format umgewandelt und schließlich in ein Datenspeichersystem, wie z.B. ein Data Warehouse ,geladen.
Diese Methode ist sehr effektiv für Anwendungsfälle, die konsistente, strukturierte Daten für Berichte, Analysen und Entscheidungen benötigen.
Wann du ETL verwenden solltest:
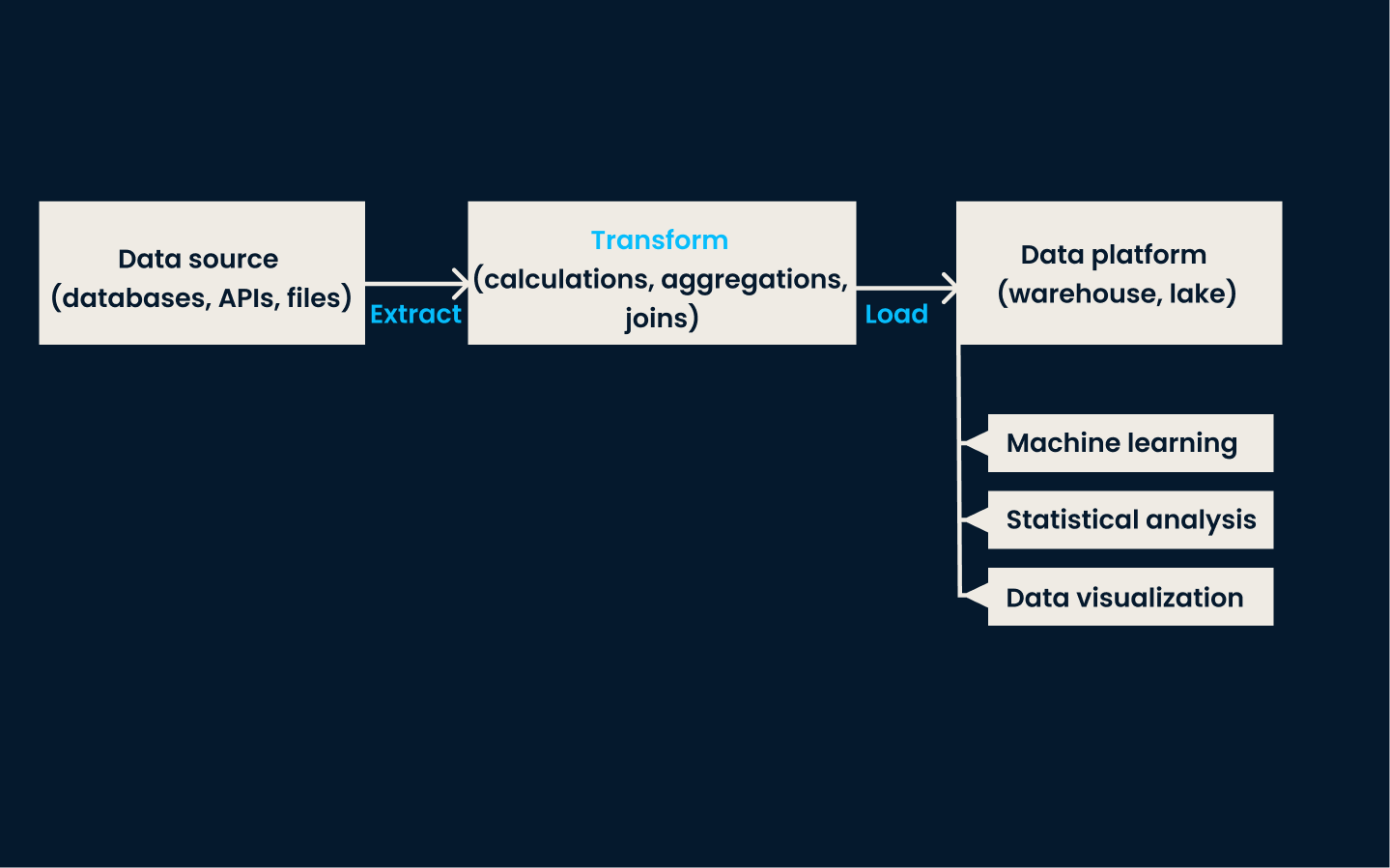
ETL-Pipeline-Architektur.
ELT kehrt die Reihenfolge der Vorgänge im Vergleich zu ETL um. Bei diesem Ansatz werden die Daten aus den Quellsystemen extrahiert und direkt in das Zielsystem (in der Regel ein Data Lake oder eine cloudbasierte Plattform)geladen . Sobald die Daten im Zielspeichersystem sind, werden sie nach Bedarf umgewandelt , oft innerhalb der Zielumgebung .
Der ELT-Ansatz ist besonders effektiv, wenn es um große Mengen unstrukturierter oder halbstrukturierter Daten geht, bei denen die Transformation aufgeschoben werden kann, bis die Analyse erforderlich ist.
Wann du ELT einsetzen solltest:
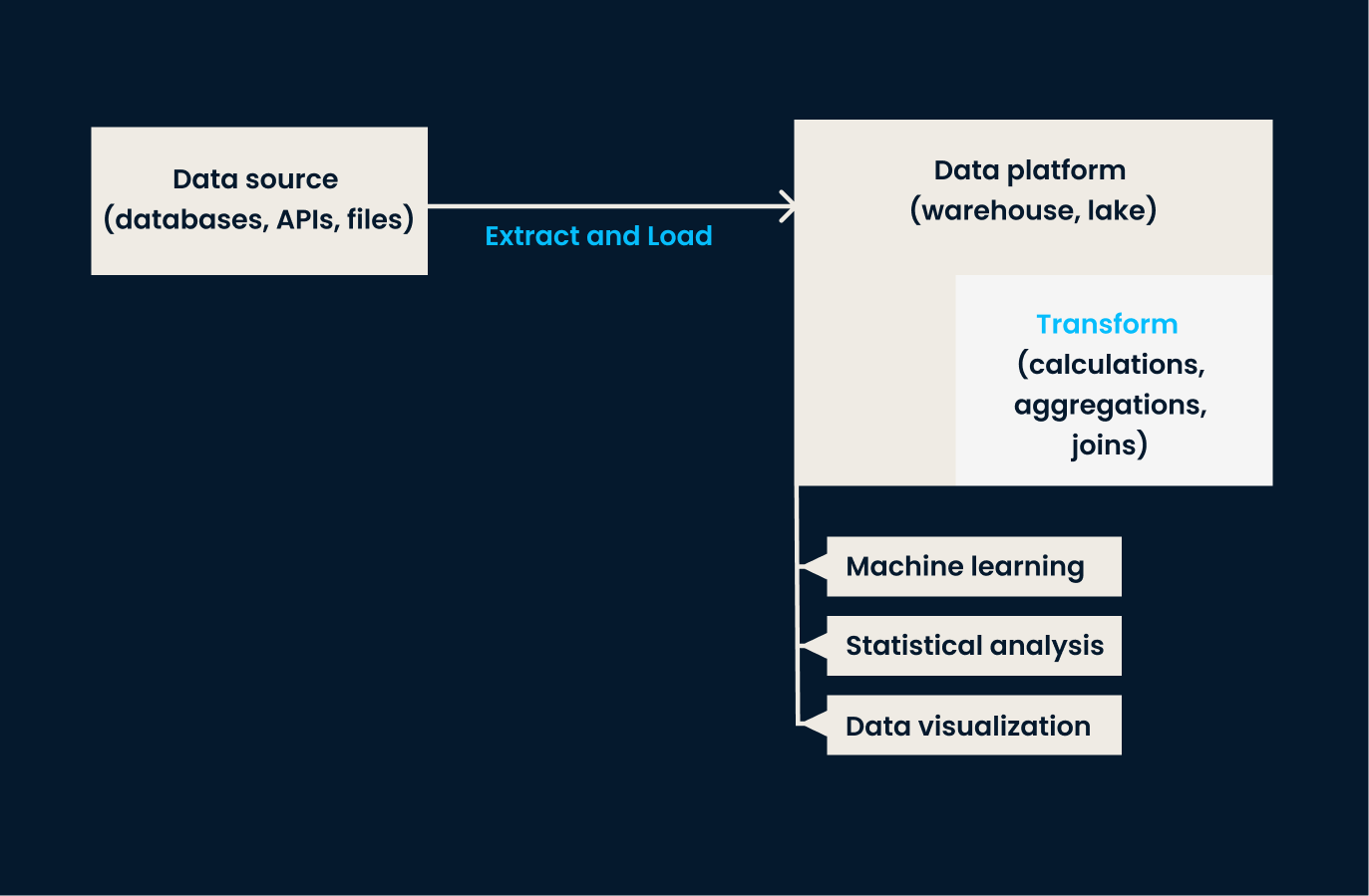
ELT-Pipeline-Architektur.
CDC ist eine Technik zur Identifizierung und Erfassung von Änderungen (z. B. Einfügungen, Aktualisierungen, Löschungen) an Daten in den Quellsystemen und zur anschließenden Replikation dieser Änderungen in Echtzeit in die Zielsysteme.
Diese Technik sorgt dafür, dass die Zielsysteme immer auf dem neuesten Stand sind, ohne dass der gesamte Datensatz neu geladen werden muss. CDC ist sehr effektiv, um die Echtzeitsynchronisation zwischen Datenbanken aufrechtzuerhalten und die Konsistenz zwischen Systemen zu gewährleisten.
Wann du die CDC verwenden solltest:
Wir haben festgestellt, dass die Datenerfassung das Abrufen von Informationen aus verschiedenen Quellen beinhaltet. Aber wir haben noch nicht darüber gesprochen, was diese Strukturen sind - und das werden wir in diesem Abschnitt tun.
Die Datenquellen für die Ingestion lassen sich im Allgemeinen in 3 Haupttypen einteilen:
Wie du bei der Betrachtung der verschiedenen Quellen erfahren wirst, erfordert jede von ihnen unterschiedliche Handhabungs- und Verarbeitungstechniken, um effektiv genutzt werden zu können.
Strukturierte Daten sind hochgradig organisiert und folgen einem vordefinierten Schema, wodurch sie leichter zu verarbeiten und zu analysieren sind. Sie werden in der Regel in relationalen Datenbanken gespeichert, die zusammenhängende Datenpunkte speichern und den Zugriff darauf ermöglichen. Die Daten werden in Tabellen mit klar definierten Zeilen und Spalten angeordnet.
Aufgrund dieser organisierten Natur sind strukturierte Daten am einfachsten zu erfassen.
Herkömmliche Tools wie MySQL und PostgreSQL werden in der Regel für die Verarbeitung strukturierter Daten verwendet. Diese SQL-basierten Tools vereinfachen den Validierungsprozess während der Ingestion, indem sie strenge Schemaregeln durchsetzen. Wenn die Daten in diese Systeme eingespeist werden,stellen sieautomatisch sicher, dass sie der in den Tabellen der Datenbank festgelegten Struktur entsprechen.
Wenn eine Spalte zum Beispiel so eingestellt ist, dass sie nur Integer-Werte akzeptiert, lehnt MySQL oder PostgreSQL alle Daten ab, die diese Anforderung nicht erfüllen.
Andere Dinge, die du über strukturierte Daten wissen solltest, sind:
Halbstrukturierte Daten sind zwar bis zu einem gewissen Grad organisiert, entsprechen aber nicht einem starren, vordefinierten Schema wie strukturierte Daten. Stattdessen werden Tags oder Markierungen verwendet, um eine gewisse Ordnung zu schaffen, aber die Struktur bleibt flexibel.
Dieser Datentyp ist typischerweisein Formaten wie JSON-Dateien, CSV-Dateien und NoSQL-Datenbanken zu finden und wird häufig in Webanwendungen, APIs und Protokollsystemen verwendet.
Da die Struktur variieren kann,bieten halbstrukturierteDaten Flexibilität bei der Speicherung und Verarbeitung und eignen sich daher für Systeme, die mit sich verändernden oder inkonsistenten Datenformaten arbeiten.
Der Umgang mit halbstrukturierten Daten erfordert Werkzeuge, um die eingebetteten Tags oder Markierungen zu analysieren und sinnvolle Informationen daraus zu extrahieren. Eine JSON-Datei kann z. B. eine Sammlung von Schlüssel-Wert-Paaren enthalten, die beim Ingestion-Prozess geparst und in ein geeignetes Format umgewandelt werden müssen.
Halbstrukturierte Daten werden oft in flexible Umgebungen wie Data Lakes oder Cloud-Plattformen eingespeist, wo sie in ihrer Rohform gespeichert und später nach Bedarf verarbeitet werden können.
Andere Dinge, die du bei halbstrukturierten Daten beachten solltest, sind:
Unstrukturierte Daten sind am kompliziertesten zu verwalten, weil sie kein bestimmtes Format und keine Organisationsstruktur haben. Zu dieser Kategorie gehören Daten wie:
Im Gegensatz zu strukturierten oder halbstrukturierten Daten haben unstrukturierte Daten keine klaren Zeilen, Spalten oder Tags, um ihren Inhalt zu definieren, was ihre Verarbeitung und Analyse erschwert.
Trotz ihrer Komplexität können unstrukturierte Daten wertvolle Erkenntnisse liefern, insbesondere wenn sie mit fortschrittlichen Technologien wie maschinellem Lernen oder natürlicher Sprachverarbeitung analysiert werden.
Da unstrukturierte Daten nicht in einer vordefinierten Weise organisiert sind, werden spezielle Tools benötigt, um den Ingestionsprozess zu bewältigen. Diese Tools können relevante Informationen aus rohen, unstrukturierten Quellen extrahieren und in Formate umwandeln, die analysiert werden können.
Schließlich werden unstrukturierte Daten in der Regel in Data Lakes gespeichert, wo sie nach Bedarf verarbeitet werden können.
|
Feature |
Strukturierte Daten |
Semi-strukturierte Daten |
Unstrukturierte Daten |
|
Definition |
Gut organisierte Daten mit einem vordefinierten Schema (z. B. Zeilen und Spalten). |
Teilweise organisierte Daten mit Tags oder Markierungen für Flexibilität (z. B. JSON, CSV). |
Daten ohne vordefinierte Struktur oder Organisation (z. B. Bilder, Videos). |
|
Beispiele |
Relationale Datenbanken wie MySQL, PostgreSQL. |
JSON-Dateien, NoSQL-Datenbanken, CSV-Protokolle. |
Bilder, Videos, Audiodateien, Textdokumente. |
|
Leichte Verarbeitung |
Am einfachsten zu verarbeiten aufgrund des strengen Schemas. |
Mittlerer Schwierigkeitsgrad; erfordert Parsing und Transformation. |
Die größte Herausforderung aufgrund der fehlenden Struktur. |
|
Lagerung |
Relationale Datenbanken oder Data Warehouses. |
Data Lakes, NoSQL-Datenbanken, Cloud-Speicher. |
Data Lakes oder spezielle Speicher für Rohdaten. |
|
Ansatz der Einnahme |
Wird in der Regel in Schüben eingenommen. |
Flexibel; kann in Echtzeit oder in Stapeln aufgenommen werden. |
In erster Linie im Rohformat für die spätere Verarbeitung aufgenommen. |
|
Verwendete Werkzeuge |
SQL-basierte Tools wie MySQL, PostgreSQL. |
Tools, die flexible Schemata verarbeiten, wie MongoDB, Google BigQuery. |
Fortgeschrittene Tools wie Hadoop, Apache Spark oder KI/ML-basierte Verarbeitungstools. |
|
Beispiele für Anwendungsfälle |
Erstellen von Berichten, Transaktionssysteme. |
API-Antworten, Webanwendungsprotokolle. |
Bilderkennung, Sprachanalyse, Stimmungsanalyse. |
Die Datenerfassung bringt einige Herausforderungen mit sich, die du bewältigen musst, um ein effizientes und effektives Datenmanagement zu gewährleisten. In diesem Abschnitt werden wir erörtern, was diese Herausforderungen sind und welche Lösungen es gibt, um sie zu überwinden.
Eine der größten Herausforderungen bei der Datenerfassung ist die schiere Menge an Daten, die verarbeitet werden muss. Wenn Unternehmen wachsen, kann die Menge der von ihnen erzeugten und gesammelten Daten exponentiell ansteigen, insbesondere mit dem Anstieg von Echtzeit-Datenströmen aus Quellen wie IoT-Geräten und Social-Media-Plattformen.
Die Skalierung von Datenerfassungsprozessen zur Bewältigung dieser wachsenden Mengen kann schwierig sein, insbesondere bei Streaming-Daten, die eine kontinuierliche Erfassung erfordern.
Die Teams müssen sicherstellen, dass ihre Infrastruktur die Aufnahme von Batch- und Echtzeitdaten in großem Umfangohne Beeinträchtigung unterstützt. Der Kurs "Streaming Concepts " ist ein toller Einstieg für dich.
Datenqualität und -konsistenz sind eine weitere große Herausforderung, vor allem, wenn die Daten aus mehreren unterschiedlichen Quellen stammen. Jede Quelle kann unterschiedliche Formate, Vollständigkeitsgrade oder sogar widersprüchliche Informationen enthalten.
Das Einlesen von Daten, ohne diese Unstimmigkeiten zu beseitigen, kann zu ungenauen oder unvollständigen Datensätzen führen, die sich schließlich auf nachgelagerte Analysen auswirken.
Während der Dateneingabe müssen Datenvalidierungsprüfungen durchgeführt werden, um sicherzustellen, dass nur qualitativ hochwertige Daten in das System gelangen. Außerdem müssen die Teams die Konsistenz zwischen den verschiedenen Quellen wahren, um Datendiskrepanzen zu vermeiden.
Ich empfehle, mit dem ausgezeichneten Kurs Einführung in die Datenqualität in dieses Thema einzutauchen .
Wenn sensible Daten erfasst werden, haben Sicherheit und Compliance höchste Priorität. Teams, die personenbezogene Daten verarbeiten (z. B. Kundennamen, Adressen, Zahlungsdaten usw.), müssen diese Daten während des gesamten Erfassungsprozesses schützen.
Ein Finanzdienstleistungsunternehmen muss zum Beispiel strenge Vorschriften wie GDPR oder HIPAA einhalten, wenn es Kundendaten erfasst, um rechtliche Konsequenzen zu vermeiden. Werden die Daten während der Erfassung nicht gesichert, kann es zu Datenschutzverletzungen kommen, die das Vertrauen der Kunden gefährden und zu erheblichen finanziellen Strafen führen.
Um dies zu verhindern, sollten die Teams Verschlüsselung und sichere Zugangskontrollen während des Ingestionsprozesses einführen. So wird sichergestellt, dass sensible Daten vor unbefugtem Zugriff geschützt sind. Darüber hinaus müssen die Daten in einer Art und Weise erfasst werden, die denll relevanten gesetzlichen Standards entspricht, und es müssen regelmäßige Audits durchgeführt werden, um die Einhaltung dieser Standards zu überprüfen.
Entdecke mit dem interaktiven Kurs "Datensicherheit ", wie du deine Daten schützen kannst.
In Szenarien, in denen sofortige Erkenntnisse benötigt werden, können Verzögerungen bei der Datenaufnahme zu veralteten oder irrelevanten Informationen führen. Die Datenaufnahme mit niedriger Latenzzeit erfordert die Fähigkeit, Daten fast sofort zu verarbeiten und für die Analyse bereitzustellen, was bei großen Datenmengen eine Herausforderung sein kann.
Die Teams müssen ihre Systeme sorgfältig optimieren, um die Latenzzeit zu verringern und sicherzustellen, dass die Daten verfügbar sind, wenn sie gebraucht werden.
Es gibt ein paar Best Practices, um eine effiziente und effektive Dateneingabe zu gewährleisten.
Die erfassten Daten werden für Analysen, Berichte und Entscheidungsfindungen verwendet und müssen daher vordefinierte Standards für Genauigkeit und Vollständigkeit erfüllen.
Durch die Implementierung von Datenvalidierungsprüfungen während der Dateneingabe kann sichergestellt werden, dass die Daten den erwarteten Formaten und Qualitätsstandards entsprechen. Ich habee schon einmal darüber geschrieben, in einem Tutorial über Große Erwartungen.
Wenn zum Beispiel erwartet wird, dass die Daten in einem bestimmten Bereich liegen oder bestimmte Kriterien erfüllen, verwende Validierungsregeln, um alle Daten, die diesen Standards nicht entsprechen, automatisch abzulehnen oder zu kennzeichnen. So werden Fehler minimiert und sichergestellt, dass nur zuverlässige Daten weiterverarbeitet werden.
Eine weitere Best Practice ist die Auswahl des richtigen Ingestion-Ansatzes für die Bedürfnisse deines Unternehmens.
Die Batch-Ingestion wird in der Regel für weniger zeitkritische Daten verwendet, z. B. für historische oder periodische Berichte. Im Gegensatz dazu wird Echtzeit-Ingestion für Anwendungen verwendet, die sofortigen Zugriff auf die neuesten Daten benötigen, wie z. B. Betrugserkennung oder IoT-Überwachung.
Beurteile deinen Bedarf anhand der Häufigkeit und Dringlichkeit von Datenaktualisierungen.
Dein Datenvolumen wird mit der Zeit wachsen. Daher ist es wichtig, skalierbare Tools und Infrastrukturen zu wählen, um wachsende Datenmengen ohne Leistungseinbußen zu bewältigen. So kannst du deine Datenpipelines und Verarbeitungskapazitäten erweitern, um zukünftiges Wachstum zu ermöglichen.
Weniger benötigter Speicherplatz bedeutet geringere Infrastrukturkosten. Die Komprimierung beschleunigt auch die Datenübertragung, was bedeutet, dass der Ingest schneller geht - vor allem bei großen Datensätzen oder großen Datenströmen. Diese Praxis ist vor allem bei halbstrukturierten oder unstrukturierten Daten von Vorteil, da diese oft sehr groß sind.
Wie du siehst, ist die Datenübernahme ein einfaches Konzept, aber es kann ziemlich schwierig sein, es selbst umzusetzen. Welches sind die besten Tools, die dir bei der Datenerfassung helfen? Ich habe eine Liste der am häufigsten genutzten Methoden zusammengestellt.
Apache Kafka ist eine verteilte Streaming-Plattform, die sich hervorragend für die Aufnahme von Daten in Echtzeit eignet. Sie ist für die Verarbeitung von Datenströmen mit hohem Durchsatz und niedriger Latenz konzipiert und eignet sich daher ideal für Anwendungsfälle, die einen sofortigen Zugriff auf große Mengen kontinuierlich generierter Daten erfordern.
Ein großer Vorteil von Kafka ist, dass es Unternehmen ermöglicht, Streaming-Daten in Echtzeit zu verarbeiten, zu speichern und an verschiedene Systeme weiterzuleiten. Sie wird häufig in Szenarien wie Betrugserkennung, IoT-Datenverarbeitung und Echtzeitanalysen eingesetzt.
Im Kurs "Einführung in Kafka " lernst du,wie du Kafka erstellst, verwaltest und für reale Herausforderungen des Datenstroms einsetzt.
Apache Nifi ist ein Tool zur Dateneingabe, das für seine benutzerfreundliche visuelle Oberfläche bekannt ist. Die leicht zugängliche Oberfläche ermöglicht es Unternehmen, Datenflüsse per Drag-and-Drop zu entwerfen, zu überwachen und zu verwalten.
Nifi unterstützt viele Datenquellen - einschließlich Batch- und Echtzeitdaten - und kann mit Systemen wie Hadoop, relationalen Datenbanken und NoSQL-Speichern integriert werden. Seine Fähigkeit, Arbeitsabläufe zur Dateneingabe zu automatisieren und komplexe Datenweiterleitungs- und -umwandlungsaufgaben zu bewältigen, macht es zu einem flexiblen und leistungsstarken Tool für die Dateneingabe in kleinem Umfang und auf Unternehmensebene.
Amazon Kinesis ist ein Cloud-nativer Service von AWS, der sich auf das Aufnehmen, Verarbeiten und Analysieren von Streaming-Daten spezialisiert hat. Sie wurde für Anwendungen entwickelt, die die Verarbeitung von Datenströmen mit hohem Durchsatz in nahezu Echtzeit erfordern, wie z. B:
Einer der Vorteile von Kinesis ist die Möglichkeit, es mit anderen AWS-Diensten für Speicherung, Analyse und maschinelles Lernen zu integrieren.
Dieses Tool eignet sich besonders gut für Unternehmen, die eine Cloud-Infrastruktur nutzen und eine vollständig verwaltete Lösung für ihre Datenerfassungsanforderungen suchen, ohne sich um Hardware- oder Skalierbarkeitsprobleme kümmern zu müssen.
Google Cloud Dataflow ist ein vollständig verwalteter Dienst von Google Cloud, der sowohl Batch- als auch Echtzeit-Datenverarbeitung unterstützt. Es basiert auf Apache Beam, einem einheitlichen Open-Source-Programmiermodell, und ermöglicht es den Nutzern, komplexe Datenpipelines zu entwerfen, die sowohl große Stapelverarbeitungen als auch Echtzeit-Datenströme verarbeiten können.
Dataflow automatisiert das Ressourcenmanagement und die Skalierung und ist damit ideal für Unternehmen, die Daten ohne manuelles Infrastrukturmanagement verarbeiten und analysieren wollen.
Airbyte ist eine Open-Source-Plattform zur Datenaufnahme, die die Integration von Daten aus verschiedenen Quellen in Speicherlösungen vereinfacht. Es bietet vorgefertigte Konnektoren für Hunderte von Datenquellen und -zielen und unterstützt Batch- und Echtzeit-Ingestion.
Das Tolle an Airbyte ist, dass es sehr anpassungsfähig ist - so können die Nutzer die Anschlüsse nach ihren Bedürfnissen erweitern. Airbyte ist eine flexible Lösung für Unternehmen, die ihre Dateneingabe-Workflows verwalten und rationalisieren wollen. Außerdem bietet das Unternehmen einen Managed Cloud Service für diejenigen, die eine "hands-off"-Lösung suchen.
In diesem Artikel haben wir die Grundlagen der Datenerfassung, ihre Arten und die Techniken, die sie ermöglichen, untersucht. Du hast etwas über Batch- und Echtzeit-Ingestion und beliebte Ansätze wie ETL, ELT und Change Data Capture (CDC) gelernt. Wir haben uns auch mit den besten Praktiken, den verschiedenen Datenquellen und den Herausforderungen beschäftigt, mit denen Unternehmen bei der Durchführung konfrontiert sind.
Wenn du mehr über Datenmanagement und Ingestion-Tools erfahren möchtest, empfehle ich dir die folgenden Ressourcen:
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
