
Curso
Introdução à Engenharia de Dados
4 h
127.6K
Várias técnicas facilitam a ingestão de dados. Cada um deles foi projetado para atender a diferentes casos de uso e necessidades de processamento de dados.
A escolha da técnica que você escolher depende de três fatores:
Nesta seção, abordarei três técnicas de ingestão de dados e quando elas são mais eficazes.
A ETL é uma técnica de ingestão de dados tradicional e amplamente usada. Nessa abordagem, os dados são extraídos de vários sistemas de origem, transformados em um formato consistente e limpo e, por fim, carregados em um sistema de armazenamento de dados, como um data warehouse .
Esse método é altamente eficaz para casos de uso que exigem dados consistentes e estruturados para relatórios, análises e tomada de decisões.
Quando você deve usar o ETL:
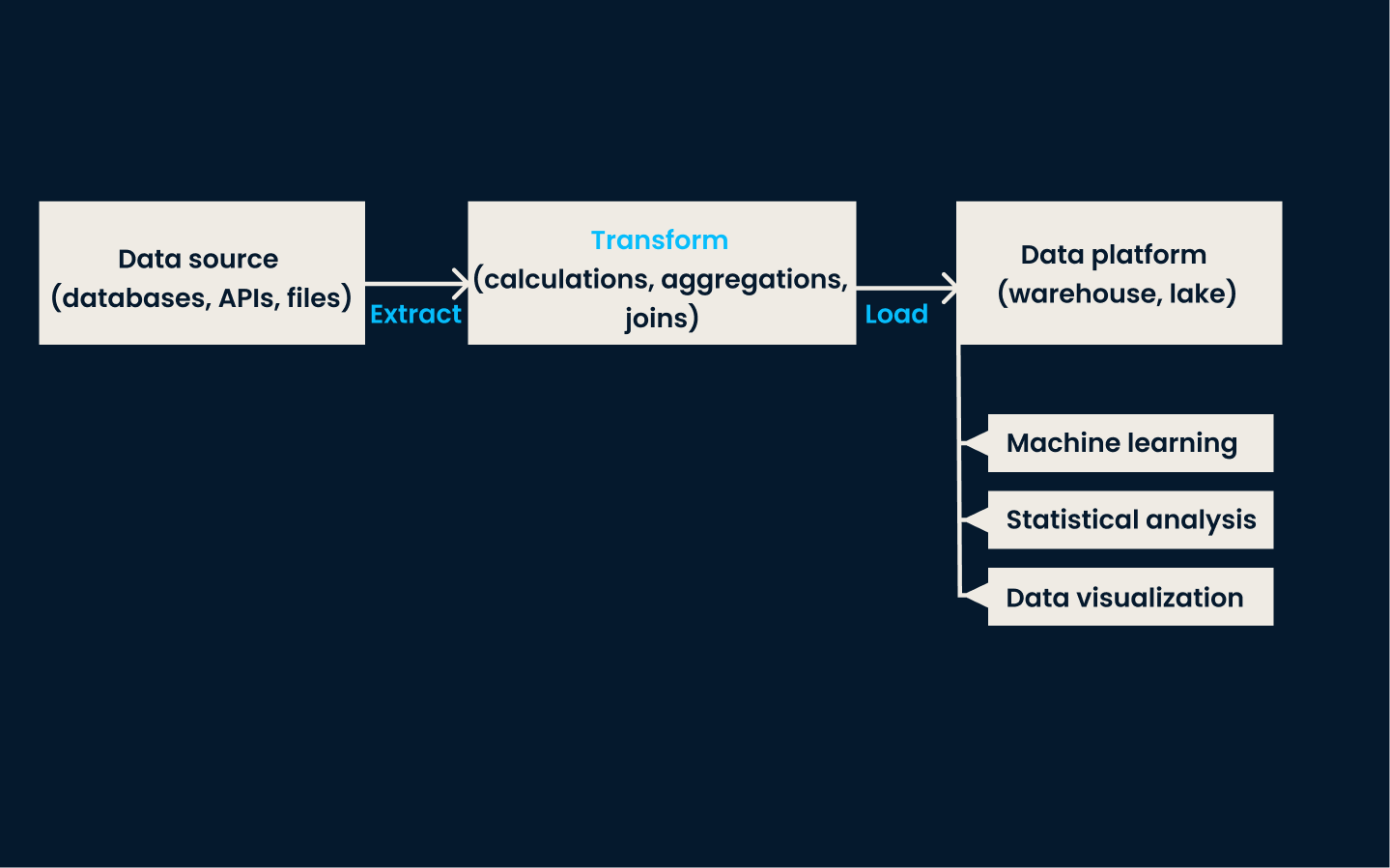
Arquitetura do pipeline de ETL.
O ELT inverte a ordem das operações em comparação com o ETL. Nessa abordagem, os dados são extraídos dos sistemas de origem e carregados diretamente no sistema de destino (geralmente um lago de dados ou uma plataforma baseada em nuvem). Uma vez no sistema de armazenamento de destino, os dados são transformados conforme necessário, geralmente no ambiente de destino .
A abordagem ELT é particularmente eficaz ao lidar com grandes volumes de dados não estruturados ou semiestruturados, em que a transformação pode ser adiada até que a análise seja necessária.
Quando usar o ELT:
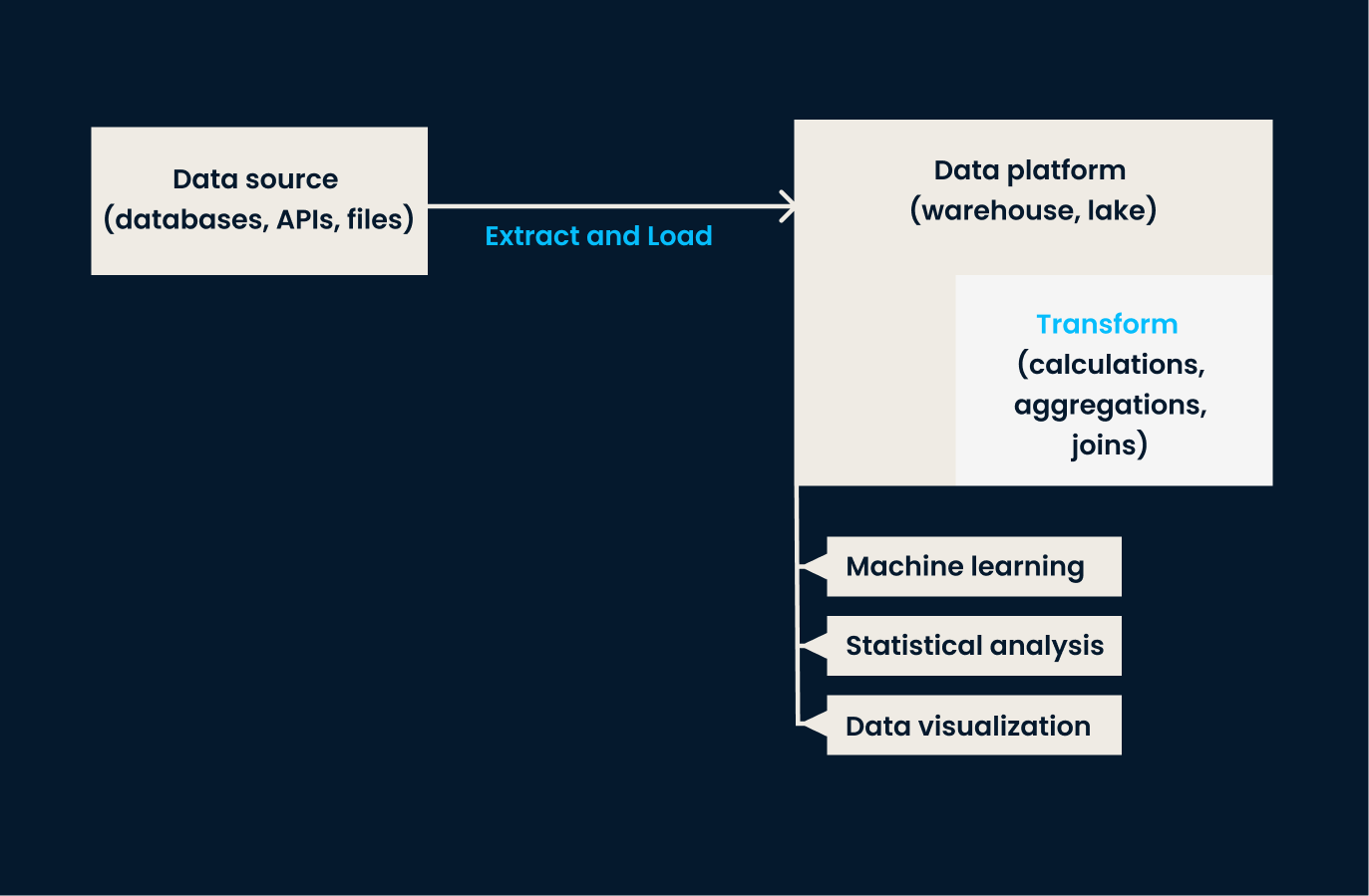
Arquitetura do pipeline ELT.
O CDC é uma técnica para identificar e capturar alterações (por exemplo, inserções, atualizações, exclusões) feitas nos dados dos sistemas de origem e, em seguida, replicar essas alterações em tempo real para os sistemas de destino.
Essa técnica garante que os sistemas de destino estejam sempre atualizados sem recarregar todo o conjunto de dados. O CDC é altamente eficaz para manter a sincronização em tempo real entre bancos de dados e garantir a consistência entre os sistemas.
Quando usar o CDC:
Já estabelecemos que a ingestão de dados envolve a extração de informações de várias fontes. Mas ainda não discutimos quais são essas estruturas, e é isso que faremos nesta seção.
As fontes de dados para ingestão geralmente se enquadram em três tipos principais:
Como você aprenderá quando examinarmos as diferentes fontes, cada uma delas exige diferentes técnicas de manuseio e processamento para ser utilizada de forma eficaz.
Os dados estruturados são altamente organizados e seguem um esquema predefinido, o que facilita o processamento e a análise. Normalmente, ele é armazenado em bancos de dados relacionais, que armazenam e fornecem acesso a pontos de dados relacionados. Os dados são organizados em tabelas com linhas e colunas claramente definidas.
Devido a essa natureza organizada, os dados estruturados são os mais simples de serem ingeridos.
As ferramentas tradicionais, como MySQL e PostgreSQL, são normalmente usadas para lidar com dados estruturados. Essas ferramentas baseadas em SQL simplificam o processo de validação durante a ingestão, impondo regras rígidas de esquema. Quando os dados são ingeridos nesses sistemas, elesautomaticamente garantem que eles sigam a estrutura definida pelas tabelas do banco de dados.
Por exemplo, se uma coluna for definida para aceitar somente valores inteiros, o MySQL ou o PostgreSQL rejeitará todos os dados que não atenderem a esse requisito.
Outros aspectos a serem observados sobre os dados estruturados são:
Os dados semiestruturados, embora ainda estejam organizados até certo ponto, não estão em conformidade com um esquema rígido e predefinido como os dados estruturados. Em vez disso, ele usa tags ou marcadores para fornecer alguma organização, mas a estrutura permanece flexível.
Esse tipo de dados é normalmenteencontrado em formatos como arquivos JSON, arquivos CSV e bancos de dados NoSQL, e é comumente usado em aplicativos da Web, APIs e sistemas de registro.
Como a estrutura pode variar,os dados semiestruturadosoferecem flexibilidade no armazenamento e no processamento, tornando-os adequados para sistemas que lidam com formatos de dados em evolução ou inconsistentes.
O tratamento de dados semiestruturados requer ferramentas para analisar e extrair informações significativas das tags ou marcadores incorporados. Por exemplo, um arquivo JSON pode conter uma coleção de pares de valores-chave, e o processo de ingestão envolveria a análise desses pares e sua transformação em um formato adequado.
Os dados semiestruturados geralmente são ingeridos em ambientes flexíveis, como lagos de dados ou plataformas de nuvem, onde podem ser armazenados em sua forma bruta e processados posteriormente, conforme necessário.
Outros aspectos a serem observados sobre os dados semiestruturados incluem:
Os dados não estruturados são o tipo mais complexo de gerenciar porque não têm nenhum formato ou estrutura organizacional específica. Essa categoria inclui dados como:
Diferentemente dos dados estruturados ou semiestruturados, os dados não estruturados não têm linhas, colunas ou tags claras para definir seu conteúdo, o que torna o processamento e a análise mais desafiadores.
Apesar de sua complexidade, os dados não estruturados podem conter insights valiosos, principalmente quando analisados por meio de tecnologias avançadas, como aprendizado de máquina ou processamento de linguagem natural.
Como os dados não estruturados não são organizados de uma forma pré-definida, são necessárias ferramentas especializadas para lidar com o processo de ingestão. Essas ferramentas podem extrair informações relevantes de fontes brutas e não estruturadas e transformá-las em formatos que podem ser analisados.
Por fim, os dados não estruturados são normalmente armazenados em lagos de dados, onde podem ser processados conforme necessário.
|
Recurso |
Dados estruturados |
Dados semiestruturados |
Dados não estruturados |
|
Definição |
Dados altamente organizados com um esquema predefinido (por exemplo, linhas e colunas). |
Dados parcialmente organizados com tags ou marcadores para flexibilidade (por exemplo, JSON, CSV). |
Dados sem nenhuma estrutura ou organização predefinida (por exemplo, imagens, vídeos). |
|
Exemplos |
Bancos de dados relacionais como MySQL, PostgreSQL. |
Arquivos JSON, bancos de dados NoSQL, registros CSV. |
Imagens, vídeos, arquivos de áudio, documentos de texto. |
|
Facilidade de processamento |
Mais fácil de processar devido ao seu esquema rígido. |
Dificuldade moderada; requer análise e transformação. |
Mais desafiador devido à falta de estrutura. |
|
Armazenamento |
Bancos de dados relacionais ou data warehouses. |
Lagos de dados, bancos de dados NoSQL, armazenamento em nuvem. |
Lagos de dados ou armazenamento especializado para arquivos brutos. |
|
Abordagem de ingestão |
Normalmente, é ingerido em lotes. |
Flexível; pode ser ingerido em tempo real ou em lotes. |
Principalmente ingerido em formato bruto para processamento posterior. |
|
Ferramentas utilizadas |
Ferramentas baseadas em SQL, como MySQL, PostgreSQL. |
Ferramentas que lidam com esquemas flexíveis, como MongoDB, Google BigQuery. |
Ferramentas avançadas como Hadoop, Apache Spark ou ferramentas de processamento baseadas em IA/ML. |
|
Exemplos de casos de uso |
Geração de relatórios, sistemas transacionais. |
Respostas de API, registros de aplicativos da Web. |
Reconhecimento de imagens, análise de fala, análise de sentimentos. |
A ingestão de dados traz vários desafios que você deve enfrentar para garantir um gerenciamento de dados eficiente e eficaz. Nesta seção, discutiremos quais são esses desafios e as soluções que podem ser empregadas para superá-los.
Um dos principais desafios da ingestão de dados é o grande volume de dados que precisa ser processado. À medida que as empresas crescem, a quantidade de dados que elas geram e coletam pode aumentar exponencialmente, principalmente com o aumento dos fluxos de dados em tempo real de fontes como dispositivos de IoT e plataformas de mídia social.
O dimensionamento dos processos de ingestão de dados para lidar com esses volumes crescentes pode ser difícil, especialmente com dados de streaming que exigem ingestão contínua.
As equipes devem garantir que sua infraestrutura possa suportar a ingestão de dados em lote e em tempo real em escalasem degradação. O curso Streaming Concepts é uma ótima maneira de você começar.
A qualidade e a consistência dos dados são outro desafio significativo, especialmente quando os dados são ingeridos de várias fontes diferentes. Cada fonte pode ter diferentes formatos, níveis de integridade ou até mesmo informações conflitantes.
A ingestão de dados sem abordar essas inconsistências pode levar a conjuntos de dados imprecisos ou incompletos, o que acaba afetando a análise downstream.
As verificações de validação de dados devem ser implementadas durante a ingestão para garantir que somente dados de alta qualidade entrem no sistema. Além disso, as equipes precisam manter a consistência em várias fontes para evitar discrepâncias nos dados.
Recomendo que você se aprofunde nesse tópico com o excelente curso Introduction to Data Quality.
Quando dados confidenciais são ingeridos, a segurança e a conformidade tornam-se as principais prioridades. As equipes que lidam com informações pessoais (por exemplo, nomes de clientes, endereços, detalhes de pagamento etc.) devem proteger esses dados durante todo o processo de ingestão.
Por exemplo, uma empresa de serviços financeiros deve aderir a regulamentações rigorosas, como o GDPR ou a HIPAA, ao ingerir dados de clientes para evitar repercussões legais. A falta de segurança dos dados durante a ingestão pode resultar em violações de dados, comprometendo a confiança do cliente e levando a penalidades financeiras substanciais.
Para resolver isso, as equipes devem implementar criptografia e controles de acesso seguro durante o processo de ingestão. Isso garante que os dados confidenciais sejam protegidos contra acesso não autorizado. Além disso, os dados devem ser ingeridos de forma que estejam em conformidade comtodos os padrões normativos relevantes, com auditorias regulares para verificar a conformidade contínua.
Descubra como manter os dados seguros e protegidos com o curso interativo de segurança de dados para iniciantes.
Em cenários em que são necessários insights imediatos, atrasos na ingestão de dados podem resultar em informações desatualizadas ou irrelevantes. A ingestão de dados de baixa latência requer a capacidade de processar e disponibilizar dados para análise quase instantaneamente, o que pode ser um desafio ao lidar com grandes volumes de dados.
As equipes devem otimizar cuidadosamente seus sistemas para reduzir a latência e garantir que os dados estejam disponíveis quando necessário.
Existem algumas práticas recomendadas para garantir uma ingestão de dados eficiente e eficaz.
Os dados ingeridos serão usados para análises, relatórios e tomada de decisões, portanto, devem atender a padrões predefinidos de precisão e integridade.
A implementação de verificações de validação de dados durante a ingestão pode ajudar a verificar se os dados estão em conformidade com os formatos e padrões de qualidade esperados. Eue escrevi sobre isso antes em um tutorial de Great Expectations.
Por exemplo, se você espera que os dados estejam em um determinado intervalo ou atendam a critérios específicos, use regras de validação para rejeitar ou sinalizar automaticamente qualquer dado que não atenda a esses padrões. Isso minimiza os erros e garante que somente dados confiáveis sejam processados no downstream.
Outra prática recomendada é garantir que você selecione a abordagem de ingestão adequada às suas necessidades comerciais.
A ingestão em lote é normalmente usada para dados menos sensíveis ao tempo, como relatórios históricos ou periódicos. Por outro lado, a ingestão em tempo real é usada para aplicativos que exigem acesso instantâneo aos dados mais recentes, como detecção de fraudes ou monitoramento de IoT.
Avalie suas necessidades com base na frequência e na urgência das atualizações de dados.
Seu volume de dados crescerá com o tempo. Portanto, é importante selecionar ferramentas e infraestrutura escaláveis para lidar com quantidades crescentes de dados sem comprometer o desempenho. Isso permite que você expanda seus pipelines de dados e recursos de processamento para acomodar o crescimento futuro.
Menos espaço de armazenamento necessário significa custos de infraestrutura mais baixos. A compactação também acelera a transferência de dados, o que significa que a ingestão será mais rápida, principalmente ao lidar com grandes conjuntos de dados ou fluxos de alto volume. Essa prática é especialmente vantajosa quando você lida com dados semiestruturados ou não estruturados, pois eles geralmente são grandes.
Como você pode ver, a ingestão de dados é um conceito simples, mas pode ser bastante difícil de implementar por conta própria. Quais são as melhores ferramentas para ajudar você com a ingestão de dados? Elaborei uma lista dos mais usados.
O Apache Kafka é uma plataforma de streaming distribuído que se destaca na ingestão de dados em tempo real. Ele foi projetado para lidar com fluxos de dados de alta taxa de transferência e baixa latência, o que o torna ideal para casos de uso que exigem acesso instantâneo a grandes volumes de dados gerados continuamente.
Um benefício significativo do Kafka é que ele permite que as empresas processem, armazenem e encaminhem dados de streaming para vários sistemas em tempo real. Ele é amplamente usado em cenários como detecção de fraude, processamento de dados de IoT e análise em tempo real.
O curso Introduction to Kafka pode ensinar a vocêcomo criar, gerenciar e solucionar problemas do Kafka para desafios de streaming de dados do mundo real.
O Apache Nifi é uma ferramenta de ingestão de dados conhecida por sua interface visual fácil de usar. Sua interface acessível permite que as empresas projetem, monitorem e gerenciem fluxos de dados usando um mecanismo de arrastar e soltar.
O Nifi é compatível com muitas fontes de dados, incluindo dados em lote e em tempo real, e pode ser integrado a sistemas como o Hadoop, bancos de dados relacionais e armazenamentos NoSQL. Sua capacidade de automatizar fluxos de trabalho de ingestão de dados e lidar com tarefas complexas de roteamento e transformação de dados faz dele uma ferramenta flexível e avançada para as necessidades de ingestão de dados em pequena escala e em nível empresarial.
O Amazon Kinesis é um serviço nativo da nuvem da AWS especializado em ingestão, processamento e análise de dados de fluxo contínuo. Ele foi projetado para aplicativos que exigem processamento quase em tempo real de fluxos de dados de alto rendimento, como:
Um dos benefícios do Kinesis é sua capacidade de integração com outros serviços da AWS para armazenamento, análise e aprendizado de máquina.
Essa ferramenta é particularmente adequada para organizações que utilizam a infraestrutura de nuvem e buscam uma solução totalmente gerenciada para lidar com os requisitos de ingestão de dados sem se preocupar com problemas de hardware ou escalabilidade.
O Google Cloud Dataflow é um serviço totalmente gerenciado fornecido pelo Google Cloud que oferece suporte ao processamento de dados em lote e em tempo real. Ele foi desenvolvido com base no Apache Beam, um modelo de programação unificado de código aberto, e permite que os usuários criem pipelines de dados complexos que podem lidar com processamento em lote em grande escala e dados de streaming em tempo real.
O Dataflow automatiza o gerenciamento e o dimensionamento de recursos, tornando-o ideal para empresas que desejam processar e analisar dados sem o gerenciamento manual da infraestrutura.
A Airbyte é uma plataforma de ingestão de dados de código aberto que simplifica a integração de dados de várias fontes em soluções de armazenamento. Ele oferece conectores pré-construídos para centenas de fontes e destinos de dados e suporta a ingestão em lote e em tempo real.
O interessante do Airbyte é que ele é altamente personalizável, o que permite que os usuários estendam os conectores para atender às suas necessidades. A Airbyte é uma solução flexível para empresas que desejam gerenciar e otimizar os fluxos de trabalho de ingestão de dados. Além disso, ele oferece um serviço de nuvem gerenciado para aqueles que buscam uma solução sem intervenção.
Neste artigo, exploramos os fundamentos da ingestão de dados, seus tipos e as técnicas que a possibilitam. Você aprendeu sobre ingestão em lote e em tempo real e abordagens populares como ETL, ELT e Change Data Capture (CDC). Também abordamos as práticas recomendadas, as várias fontes de dados e os desafios que as organizações enfrentam durante a execução.
Para obter mais insights sobre ferramentas de gerenciamento e ingestão de dados, recomendo que você explore os seguintes recursos:
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Javier Canales Luna
14 min
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
12 min
blog
Christine Cepelak
15 min

