
Course
Introduction to Data Engineering
4 hr
127.6K
Several techniques facilitate data ingestion. Each is designed to address different use cases and data processing needs.
The choice of technique you choose depends on 3 factors:
In this section, I will touch on three data ingestion techniques and when they are most effective.
ETL is a traditional and widely used data ingestion technique. In this approach, data is extracted from various source systems, transformed into a consistent and clean format, and finally loaded into a data storage system, such as a data warehouse.
This method is highly effective for use cases that require consistent, structured data for reporting, analytics, and decision-making.
When to use ETL:
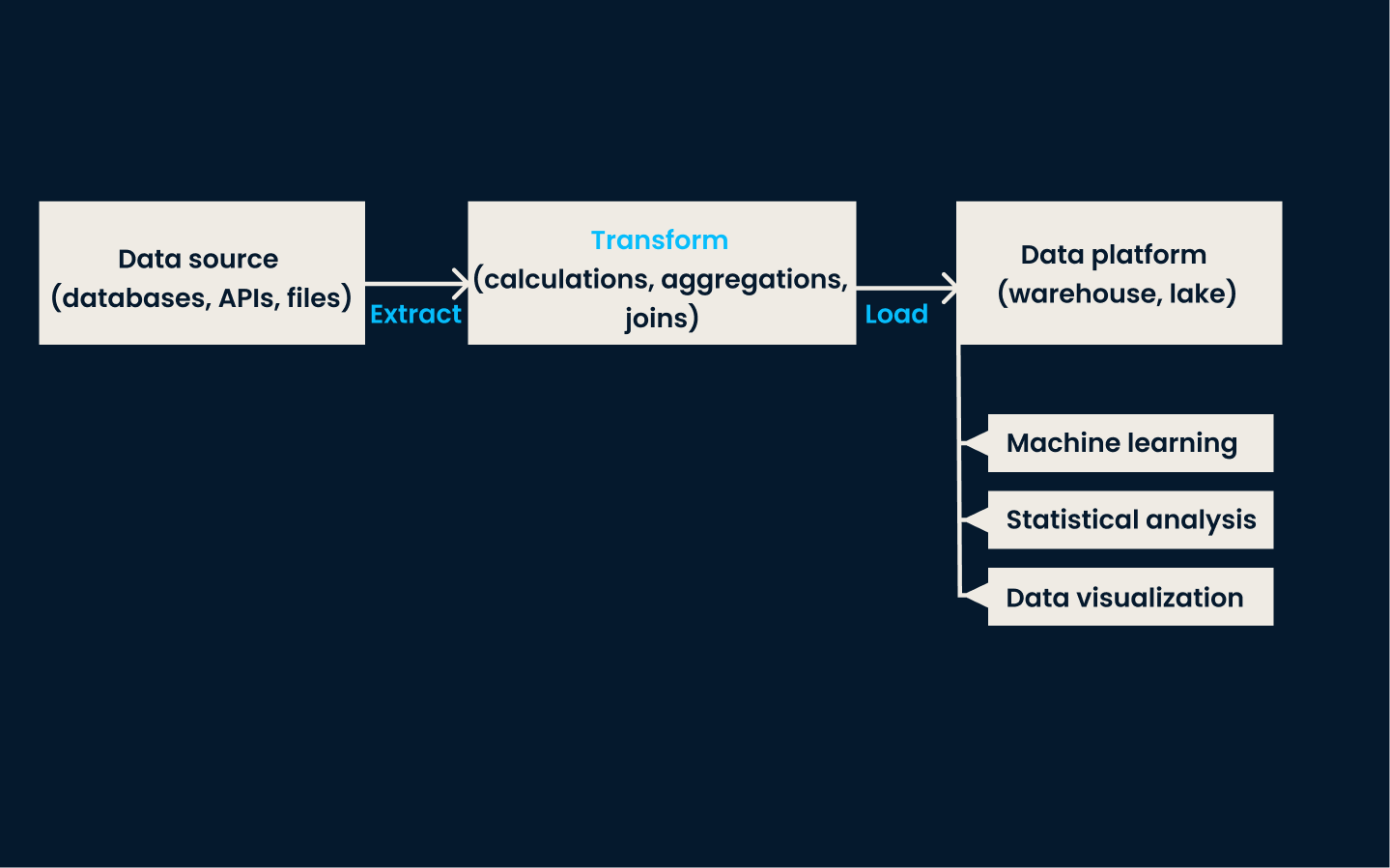
ETL pipeline architecture.
ELT reverses the order of operations compared to ETL. In this approach, data is extracted from source systems and loaded directly into the target system (usually a data lake or cloud-based platform). Once in the target storage system, the data is transformed as needed, often within the destination environment.
The ELT approach is particularly effective when dealing with large volumes of unstructured or semi-structured data, where transformation can be deferred until analysis is required.
When to use ELT:
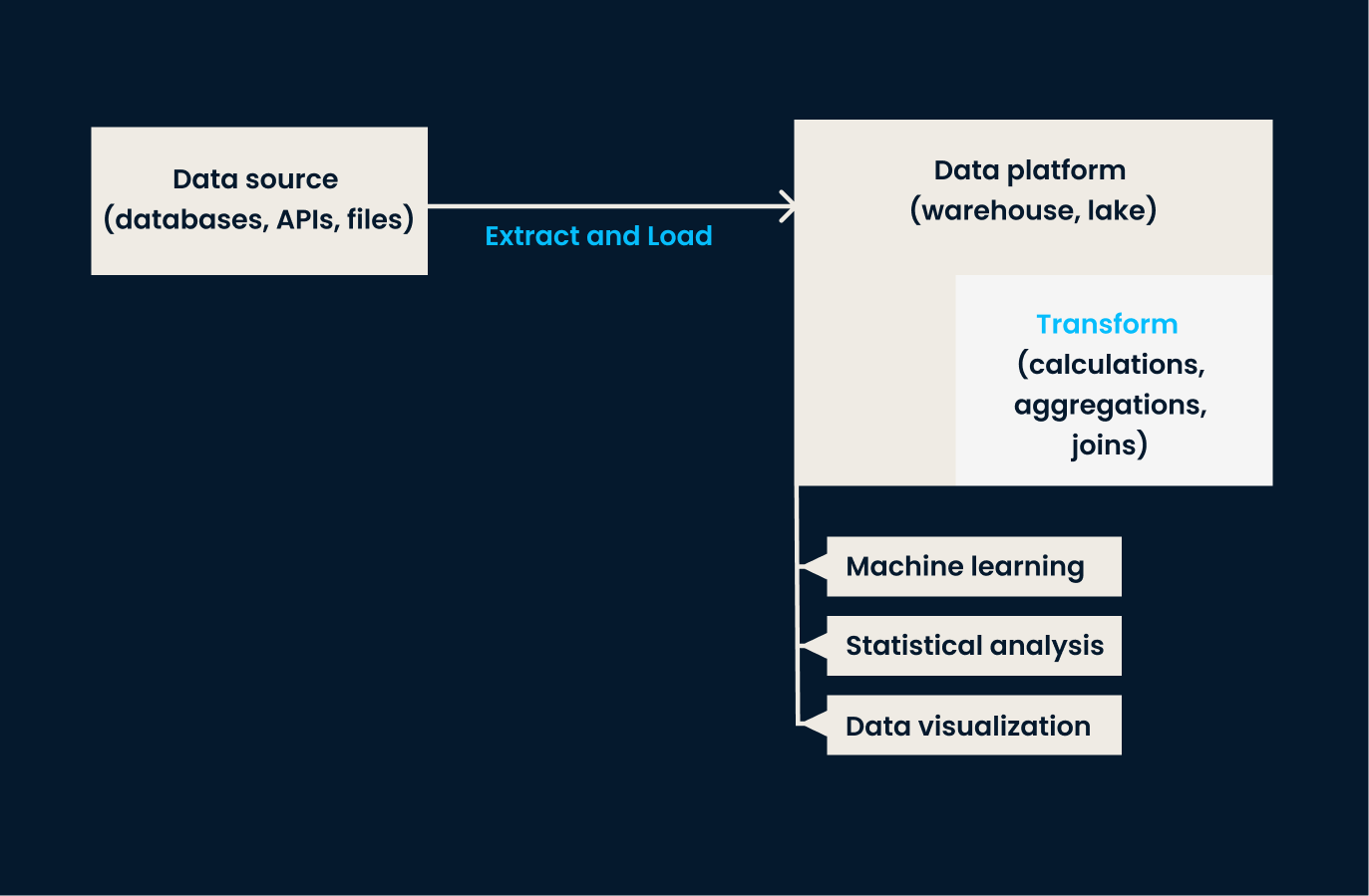
ELT pipeline architecture.
CDC is a technique for identifying and capturing changes (e.g., inserts, updates, deletes) made to data in source systems and then replicating those changes in real time to the destination systems.
This technique ensures that target systems are always up-to-date without reloading the entire dataset. CDC is highly effective for maintaining real-time synchronization between databases and ensuring consistency across systems.
When to use CDC:
We’ve established that data ingestion involves pulling information from various sources. But we haven’t discussed what those structures are — and that’s what we’ll do in this section.
The data sources for ingestion generally fit into 3 main types:
As you will learn when we examine the different sources, each requires different handling and processing techniques to be utilized effectively.
Structured data is highly organized and follows a predefined schema, making it easier to process and analyze. It is typically stored in relational databases, which store and provide access to related data points. The data is arranged into tables with clearly defined rows and columns.
Due to this organized nature, structured data is the most straightforward to ingest.
Traditional tools like MySQL and PostgreSQL are typically used to handle structured data. These SQL-based tools simplify the validation process during ingestion by enforcing strict schema rules. When data is ingested into these systems, they automatically ensure it adheres to the structure defined by the database tables.
For example, if a column is set to accept only integer values, MySQL or PostgreSQL will reject any data that doesn’t meet this requirement.
Other things to note about structured data are:
Semi-structured data, while still organized to some degree, does not conform to a rigid, predefined schema like structured data. Instead, it uses tags or markers to provide some organization, but the structure remains flexible.
This data type is typically found in formats like JSON files, CSV files, and NoSQL databases, and it is commonly used in web applications, APIs, and log systems.
Since the structure can vary, semi-structured data offers flexibility in storage and processing, making it suitable for systems that handle evolving or inconsistent data formats.
Handling semi-structured data requires tools to parse and extract meaningful information from the embedded tags or markers. For instance, a JSON file may contain a collection of key-value pairs, and the ingestion process would involve parsing these pairs and transforming them into a suitable format.
Semi-structured data is often ingested into flexible environments like data lakes or cloud platforms, where it can be stored in its raw form and processed later as needed.
Other things to note about semi-structured data include:
Unstructured data is the most complex type to manage because it lacks any specific format or organizational structure. This category includes data like:
Unlike structured or semi-structured data, unstructured data does not have clear rows, columns, or tags to define its content, making it more challenging to process and analyze.
Despite its complexity, unstructured data can hold valuable insights, particularly when analyzed using advanced technologies like machine learning or natural language processing.
Because unstructured data is not organized in a predefined way, specialized tools are required to handle the ingestion process. These tools can extract relevant information from raw, unstructured sources and transform it into formats that can be analyzed.
Lastly, unstructured data is typically stored in data lakes, where it can be processed as needed.
|
Feature |
Structured data |
Semi-structured data |
Unstructured data |
|
Definition |
Highly organized data with a predefined schema (e.g., rows and columns). |
Partially organized data with tags or markers for flexibility (e.g., JSON, CSV). |
Data without any predefined structure or organization (e.g., images, videos). |
|
Examples |
Relational databases like MySQL, PostgreSQL. |
JSON files, NoSQL databases, CSV logs. |
Images, videos, audio files, text documents. |
|
Ease of processing |
Easiest to process due to its strict schema. |
Moderate difficulty; requires parsing and transformation. |
Most challenging due to lack of structure. |
|
Storage |
Relational databases or data warehouses. |
Data lakes, NoSQL databases, cloud storage. |
Data lakes or specialized storage for raw files. |
|
Ingestion approach |
Typically ingested in batches. |
Flexible; can be ingested in real-time or batches. |
Primarily ingested in raw format for later processing. |
|
Tools used |
SQL-based tools like MySQL, PostgreSQL. |
Tools that handle flexible schemas, such as MongoDB, Google BigQuery. |
Advanced tools like Hadoop, Apache Spark, or AI/ML-based processing tools. |
|
Use case examples |
Generating reports, transactional systems. |
API responses, web application logs. |
Image recognition, speech analysis, sentiment analysis. |
Data ingestion comes with several challenges that you must address to ensure efficient and effective data management. In this section, we will discuss what these challenges are and solutions that can be employed to overcome them.
One of the primary challenges in data ingestion is the sheer volume of data that needs to be processed. As businesses grow, the amount of data they generate and collect can increase exponentially, particularly with the rise of real-time data streams from sources like IoT devices and social media platforms.
Scaling data ingestion processes to handle these growing volumes can be difficult, especially with streaming data that requires continuous ingestion.
Teams must ensure their infrastructure can support batch and real-time data ingestion at scale without degradation. The Streaming Concepts course is a great way to get started.
Data quality and consistency are another significant challenge, especially when data is ingested from multiple disparate sources. Each source may have different formats, levels of completeness, or even conflicting information.
Ingesting data without addressing these inconsistencies can lead to inaccurate or incomplete datasets, eventually impacting downstream analytics.
Data validation checks must be implemented during ingestion to ensure that only high-quality data enters the system. Additionally, teams need to maintain consistency across various sources to avoid data discrepancies.
I recommend deep diving into this topic with the excellent Introduction to Data Quality course.
When sensitive data is ingested, security and compliance become top priorities. Teams that handle personal information (e.g., customer names, addresses, payment details, etc.) must protect this data throughout the ingestion process.
For example, a financial services company must adhere to stringent regulations like GDPR or HIPAA when ingesting client data to avoid legal repercussions. Failure to secure data during ingestion could result in data breaches, compromising customer trust and leading to substantial financial penalties.
To address this, teams should implement encryption and secure access controls during the ingestion process. This ensures that sensitive data is protected from unauthorized access. Additionally, data must be ingested in a manner that complies with all relevant regulatory standards, with regular audits to verify ongoing compliance.
Discover how to keep data safe and secure with the beginner-friendly Data Security interactive course.
In scenarios where immediate insights are needed, delays in data ingestion can result in outdated or irrelevant information. Low-latency data ingestion requires the ability to process and make data available for analysis almost instantaneously, which can be challenging when dealing with large volumes of data.
Teams must carefully optimize their systems to reduce latency and ensure data is available when needed.
There are a few best practices to ensure efficient and effective data ingestion.
Ingested data will be used for analytics, reporting, and decision-making, so it must meet predefined standards of accuracy and completeness.
Implementing data validation checks during ingestion can help verify that data conforms to the expected formats and quality standards. I’ve written about this before in a Great Expectations tutorial.
For example, if data is expected to be in a certain range or meet specific criteria, use validation rules to automatically reject or flag any data that doesn’t meet these standards. This minimizes errors and ensures that only reliable data is processed downstream.
Another best practice is to ensure you select the appropriate ingestion approach for your business needs.
Batch ingestion is typically used for less time-sensitive data, such as historical or periodic reports. In contrast, real-time ingestion is used for applications that require instant access to the latest data, such as fraud detection or IoT monitoring.
Assess your needs based on the frequency and urgency of data updates.
Your data volume will grow over time. Thus, it’s important to select scalable tools and infrastructure to handle increasing amounts of data without compromising performance. This lets you expand your data pipelines and processing capabilities to accommodate future growth.
Less storage space required means lower infrastructure costs. Compression also speeds up data transfer, which means ingestion will be faster – mainly when dealing with large datasets or high-volume streams. This practice is especially beneficial when dealing with semi-structured or unstructured data, as they often come in large sizes.
As you can see, data ingestion is a simple concept but it can be quite difficult to implement on your own. What are the best tools to help you with data ingestion? I’ve curated a list of the most commonly used.
Apache Kafka is a distributed streaming platform that excels at real-time data ingestion.
The Introduction to Kafka course can teach you how to create, manage, and troubleshoot Kafka for real-world data streaming challenges.
Apache Nifi is a data ingestion tool known for its user-friendly visual interface.
Amazon Kinesis is a cloud-native service from AWS that specializes in ingesting, processing, and analyzing streaming data. It is designed for applications that require near real-time processing of high-throughput data streams, such as:
One of the benefits of Kinesis is its ability to integrate with other AWS services for storage, analytics, and machine learning.
This tool is particularly well-suited for organizations that leverage cloud infrastructure and seek a fully managed solution to handle their data ingestion requirements without concerning themselves with hardware or scalability issues.
Google Cloud Dataflow is a fully managed service provided by Google Cloud that supports both batch and real-time data processing.
Airbyte is an open-source data ingestion platform that simplifies data integration from various sources into storage solutions.
| Tool | Type | Best for | Key features | Deployment | Ease of use | Customization | Integration |
|---|---|---|---|---|---|---|---|
| Apache Kafka | Streaming Platform | Real-time data ingestion | High-throughput, low-latency, scalable | Cloud & On-Prem | Moderate | High | Broad ecosystem support |
| Apache Nifi | Data Flow Management | Automated data pipelines | Drag-and-drop UI, real-time processing | Cloud & On-Prem | High | High | Multiple protocols, big data tools |
| Amazon Kinesis | Cloud Streaming Service | AWS-native real-time analytics | Fully managed, scalable, AWS-integrated | Cloud (AWS) | High | Moderate | Deep AWS integration |
| Google Cloud Dataflow | Data Processing Service | Batch & streaming ETL | Auto-scaling, Apache Beam-based | Cloud (GCP) | High | Moderate | Strong GCP integration |
| Airbyte | Data Integration Platform | Pre-built & custom connectors | Open-source, real-time & batch support | Cloud & On-Prem | High | Very High | Hundreds of data sources |
In this article, we’ve explored the fundamentals of data ingestion, its types, and the techniques that enable it. You’ve learned about batch and real-time ingestion and popular approaches like ETL, ELT, and Change Data Capture (CDC). We’ve also covered best practices, the various data sources, and the challenges organizations face while performing.
For more insights into data management and ingestion tools, I recommend exploring the following resources:
Learn more about data engineering with these courses!
Course
Course
Course
blog
Srujana Maddula
14 min
blog
Kurtis Pykes
13 min
blog
Kurtis Pykes
15 min
blog
Abid Ali Awan
9 min
blog
Kurtis Pykes
15 min
Tutorial
Amberle McKee

